SQL范围查询与hive学习(初级)
需要注意的是:如果插入数据不合法,系统会自动将对应的零值插入数据库中。
| 数据类型 | 字节数 | 数据格式 |
| year | 1 | YYYY |
| date | 4 | YYYY-MM-DD |
| time | 3 | HH:MM:SS |
| datetime | 8 |
YYYY-MM-DD HH:MM:SS |
| timestamp | 4 | YYYY-MM-DD HH:MM:SS |
查询表的结构(以 date类型 举例),如下

查询表的内容(无序)

between关键字查询时间、日期范围(升序排序)

where关键字比较查询范围(降序排序)

增
【插入单行】
insert into <表名> (列名) values (列值)
例:insert into Strdents (姓名,性别,出生日期) values ('开心朋朋','男','1980/6/15')
【将现有表数据添加到一个已有表】
insert into <已有的新表> (列名) select <原表列名> from <原表名>
例:insert into tongxunlu ('姓名','地址','电子邮件')
select name,address,email
from Strdents
【直接拿现有表数据创建一个新表并填充】
select <新建表列名> into <新建表名> from <源表名>
例:select name,address,email into tongxunlu from strdents
【使用union关键字合并数据进行插入多行】
insert <表名> <列名> select <列值> tnion select <列值>
例:insert Students (姓名,性别,出生日期)
select '开心朋朋','男','1980/6/15' union(union表示下一行)
select '蓝色小明','男','19**/**/**'
改:update <表名> set <字段名=值> [where <更新条件>]
删
delete from <表名> 删除条件整个表
truncate table <表名> 删除整个表的值,但表的结构、列、约束、索引等不会被删除;不能用语有外建约束引用的表
查
select <列名> from <表名> [where <查询条件表达试>] [order by <排序的字段名>[asc或desc]] #默认为asc升序
【查询空行】
例:select name from a where email is null
说明:查询表a中email为空的所有行,并显示name列;SQL语句中用is null或者is not null来判断是否为空行
【在查询中使用常量】
例:select name, '唐山' as 地址 from Student
说明:查询表a,显示name列,并添加地址列,其列值都为'唐山'
【查询返回限制行数(关键字:top percent)】
例1:select top 6 name from a
说明:查询表a,显示列name的前6行,top为关键字
例2:select top 60 percent name from a
说明:查询表a,显示列name的60%,percent为关键字
【使用like进行模糊查询】
注意:like运算副只用于字符串,所以仅与char和varchar数据类型联合使用
例:select * from a where name like '赵%'
说明:查询显示表a中,name字段第一个字为赵的记录
【使用between在某个范围内进行查询】
例:select * from a where nianling between 18 and 20
说明:查询显示表a中nianling在18到20之间的记录
【使用in在列举值内进行查询】
例:select name from a where address in ('北京','上海','唐山')
说明:查询表a中address值为北京或者上海或者唐山的记录,显示name字段
【使用group by进行分组查询】
例:select studentID as 学员编号,AVG(score) as 平均成绩 (注释:这里的score是列名)
from score (注释:这里的score是表名)
group by studentID
说明:在表score中查询,按strdentID字段分组,显示strdentID字段和score字段的平均值;select语句中只允许被分组的列和为每个分组返回的一个值的表达式,例如用一个列名作为参数的聚合函数
【使用having子句进行分组筛选】
例:select studentID as 学员编号,AVG(score) as 平均成绩 (注释:这里的score是列名)
from score (注释:这里的score是表名)
group by studentID
having count(score)>1
说明:接上面例子,显示分组后count(score)>1的行,由于where只能在没有分组时使用,分组后只能使用having来限制条件。
内联接
【在where子句中指定联接条件】
例:select a.name,b.chengji from a,b where a.name=b.name;
说明:查询表a和表b中name字段相等的记录,并显示表a中的name字段和表b中的chengji字段
【在from子句中使用join…on】
例:select a.name,b.chengji from a inner join b on (a.name=b.name);
说明:同上
外联接
【左外联接查询】
例:select s.name,c.courseID,c.score from strdents as s left outer join score as c on s.scode=c.strdentID;
说明:在strdents表和score表中查询满足on条件的行,条件为score表的strdentID与strdents表中的sconde相同
创建索引和删除索引
注:建立索引是为了避免全表扫描,从而提高 sql 语句执行效率。
1、在已经存在的表上创建索引
create [unique|fulltext|spatial] index 索引名 on 表名 (字段名 [(长度)] [asc|desc]);
或者
alter table 表名 add [unique|fulltext|spatial] index 索引名 (字段名 [(长度)] [asc|desc]);
2、创建表的时侯创建索引
create table 表名 (
字段名 数据类型 [完整性约束条件],
字段名 数据类型 [完整性约束条件],
......
[unique|fulltext|spatial] index|key [索引名] (字段名 [(长度)][asc|desc])
) engine=myisam;
以上参数详解:
unique:唯一索引,该索引所在字段的值必须是唯一的。
fulltext:全文索引,它只能创建在 char、varchar、text 类型的字段上,而且,现在只有 myisam 引擎支持全文索引。
spatial:空间索引,它只能创建在 geometry、point、linestring、polygon 类型字段上,而且必须声明 not null ,储存引擎为 myisam 引擎。
长度:表示索引的长度。
asc和desc:asc 表示升序排序,desc 表示降序排序。
删除索引
alter table 表名 drop index 索引名;
或者
drop index 索引名 on 表名;
聚集索引(clustered index)
innodb引擎,优势:根据主键查询条目比较少时,不用回行。
劣势:如果碰到不规则数据插入时,造成频繁页分裂。
注意:innodb来说
1、如果没有主键(primary key),则会 Unique key 做主键。
2、如果没有 unique ,则系统生成一个内部的 rowid 做主键。
3、像 innodb 中,主键的索引结构中,既存储了主键值,又存储了行数据,这种结构称为“聚簇索引”。
非聚集索引(non-clustered index)
myisam引擎:主索引和次索引,都指向物理行(磁盘位置)。
explain用法
explain是用来查看mysql是如何计划执行sql语句的。可以帮助选择更适合的索引和更适合的sql语句。
explain结果参数详解:
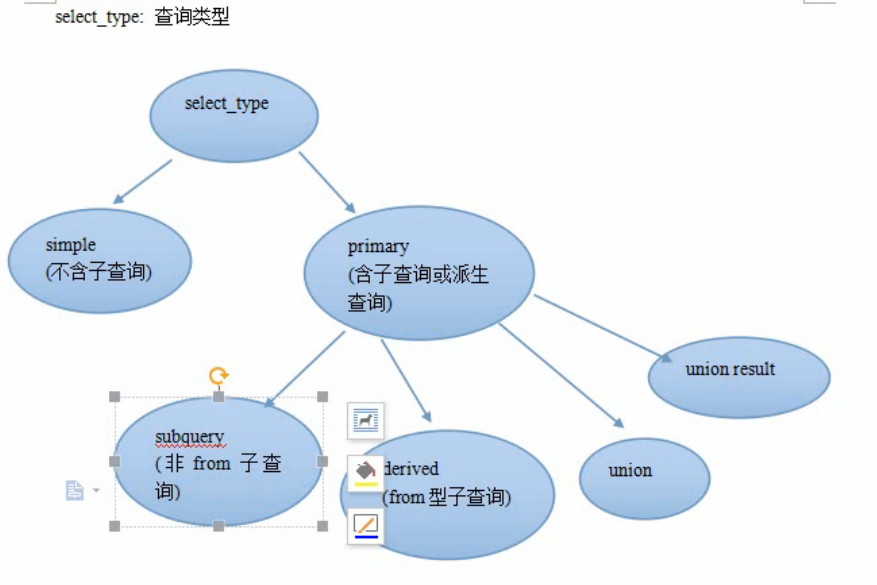
select_type 查询类型
table 查询针对的表
type
possible_keys 可能用到的索引 (分析的是索引用于查找的过程)
key 最终用到的索引(可能是被用于查找、排序或索引覆盖)
key_len 使用索引的最大长度
ref
rows 扫描了多少行数据,找到了需要数据。
extra
optimal 索引
条件因素:
1、查询频繁。
2、区分度高(数据的不相似度,至少为 0.1)。
3、索引的长度(用于区分度的长度):直接影响索引文件的大小,影响增删改的速度,并间接影响查询速度(或占用内存多)。
通过计算区分度的值,来获得区分度和长度取衡:
select ((select count(distinct left(字段名,长度))from 表名)/(select count(*) from 表名));
分解查询(不允许三表以上的连接查询)
union
1、union 的子句条件要尽量具体,即--查询更少的行。
2、子句的结果在内存里并成结果集,需要先排序再去重复。如果不需要去重,尽量加 all 之后。
group by
注意:1、分组用于统计,而不用于筛选重复数据。
2、group by 的列要有索引,可以避免临时表及文件排序。
3、order by 的列要和 group by 的一致,否则也会引起临时表。
count()
myisam 的 count() 的“所有行”很快,因为 myisam 对行数进行了储存。一旦有条件的查询,速度就不再快,尤其是 where 条件的列上没有索引。
hive的起源与应用
1、起源:由Facebook开源用于解决海量结构化日志的数据统计。
2、结构:Hive是基于hadoop的数据仓库,可以将结构化的数据文件映射成一张表(数据库和表都是路径,适合离线处理),并提供类SQL功能;使用HDFS存储,MapReduce计算。
3、schema(模式,元信息存放到数据库中)
4、hive在写操作是不校验,读时校验。
hive数据类型
tinyint
smallint
int
bigint
String //''|""
varchar //1-65535
char //255
timestamp //format "YYYY-MM-DD HH:MM:SS.fffffffff"
Date //form{{YYYY-MM-DD}}
decimal
UNIONTYPE //联合类型
NULL
hive的基本操作
create database if not exists 库名; #创建库
alter database dbname set dbproperties('edited-by'='joe'); #修改库(不能删除或“重置”数据库属性)
describe database extended dbname; #查询库
drop database [if exists] dbname; #删除库
desc database extended 库; #显示库的扩展信息
hive>create external table dat0204(filmname string ,filmdate date ,filmscore string)
>comment '别名'
>row format delimited
>fields terminated by '\t'
>lines terminated by '\n'
>stored as textfile; #创建外部表,外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
hive>create table if not exists dat0204(id int , name string , age int)
>comment '别名'
>row format delimited
>fields terminated by '\t'
>lines terminated by '\n'
>stored as textfile; #创建内部表
desc 表; #表的描述
desc formatted 表; #查询表的结构
desc extended 表; #显示表的扩展信息
select * from 表; #查询表的信息
create table 库名1.表名1 like 库名2.表名2; #复制表(表结构+数据)
alter table hive1.test2 add partition(province='hebei',city='baoding') #添加分区
show partitions hive1; #查看表的分区
insert overwrite table test2 partition(provice='hebei',city='shijiazhuang') select id , name , age from test1; #增加数据
drop table 表; #删除空表
drop table 表 cascade; #删除非空表
show tables like '*name*'; #模糊搜索表
插入数据(加载到HDFS)
hive>load data local inpath 'path/filename' overwrite into table 表名; #从本地数据导入Hive表
hive>load data inpath 'path/filename' into table 表名; #HDFS上导入数据到Hive表
hive> insert overwrite directory "hodoop目录" select user, login_time from user_login; #将查询数据输出hdfs目录
$ hive -e "sql语句" > /tmp/out.txt #保存sql语句查询信息到本地文件
hive命令模型
hive>dfs -lsr / //显示dfs下文件:路径/库/表/文件
hive>dfs -rmr /目录 //dfs命令,删除目录
hive>!clear ; //hive中执行shell命令
hive>!dfs -lsr / ; //hive中执行hdfs命令
元数据都储存在mysql
use hive用户库;
select * from VERSION; #查看hive版本
select * from TBLS \G; #查看有哪些表,易区分各表。
select * from SDS \G; #查看表对应的hdfs目录的metedata
select * from PARTITIONS where TBL_ID=1 \G; #查看某个表的partitions:
select * from COLUMNS_V2; #查看某个表的列:
select * from PARTITION_KEYS; #查看某个表的partition
select * from DBS; #查看数据仓库信息
调优
1.explain———解释执行计划
explain select sum(*) from test2 ;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号