缓存穿透、雪崩、击穿、一致性
- 缓存穿透
- 对一个不存在的数据进行请求,该请求会直接穿透缓存,到数据库查询,数据库中也没有。当并发查不存在的数据时,大量请求到达数据库,给数据库造成很大压力。
- 解决方案:
- 过滤请求: 接口层增加校验 如id校验 若id<=0 直接拦截
-
布隆过滤器
布隆过滤器可以判断某个数据不存在 或 可能存在
方法:k个hash函数将key散列成k个整数;设置长度为n的比特数组 初始时都为0;对已存在的数据 也就是已有的key 用k个hash函数计算出k个散列值,比特数组中对应的位置置1;查询是否存在时,若k个散列值有一个为0则不存在,全为1则可能存在
将可能查询的key 存入布隆过滤器,用户查询时 发现不存在 则直接丢弃 不对持久层查询
问题: 布隆过滤器不支持删除
-
缓存空对象
-
持久层不命中时,将空对象缓存起来,并设置短过期时间(避免占用资源)
2. 问题:缓冲空值占用空间,因为要缓存具有空值的键;即使设置过期时间,也存在缓存层与持久化层时间窗口不一致,影响保持一致性的业务
-
- 缓存雪崩
- 大量请求到达数据库,由于1数据未被加载到缓存;2缓存在同一时间大面积失效;3缓存服务器宕机
- 解决方案
- 进行缓存预热(提前将数据加载到缓存,避免在请求时先查询数据库),避免系统刚启动不久还未将大量数据进行缓存时导致的雪崩
- 观察用户行为,合理设置缓存过期时间;在默认的缓存时间上加随机1-5分钟;避免同一时间大面积过期导致的雪崩
- 分布式缓存,每个节点只缓存部分数据,某节点宕机后其他节点的缓存仍可用;避免缓存服务器宕机造成的雪崩
- 缓冲击穿
- 请求未缓冲但数据库中存在的数据,由于高并发,同时在缓存中未读到数据,又同时去数据库取数据,引起数据库压力瞬间增大
- 与缓冲雪崩的区别:击穿指的是并发到数据库查同一条数据;雪崩是指并发到服务器查许多条数据
- 解决方案:
- 使用互斥锁 mutex key
- 使用Redis中的SETNX( set if not exists):若缓存失效,不立即冲数据库查找,而是设置一个互斥锁,设置成功再去数据库查找,否则延迟一小段时间再重新尝试从缓存中获取
- Memcache的add
- 提前使用互斥锁
- 在value内部设置一个超时值t2,t2比实际的超时值小,当从缓存中读到该数据,发现t2已经过期时,加互斥锁,延长t2并重新读入缓存。
- 使用互斥锁 mutex key
3. 永不过期
-
-
-
- 不设置过期时间,不会出现热点key过期问题
- 不过期就成静态的了,所以将过期时间存再key对应的value里,发现快过期时,使用后台的异步线程进行缓存的构建
-
-
4. 资源保护:资源隔离组件 hystrix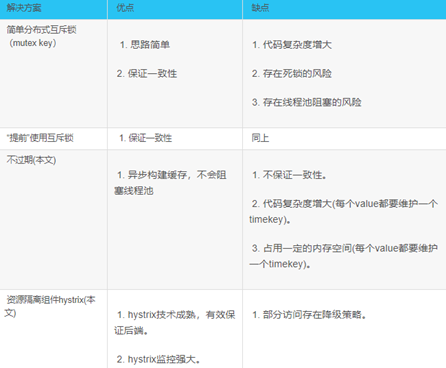
- 缓存一致性
- 数据更新的同时 缓存也能实时更新
- 方案:
- 数据更新的同时立即更新缓存
- 读缓存时 判断缓存是否最新
- 最好缓存对一致性要求不高的数据 且允许缓存存在脏数据
- 缓存更新策略:https://blog.csdn.net/W_317/article/details/114261969
- Cache aside: 先更新数据库 再删除缓存;设置缓存时间 保证数据一致性
- Read/write through :Cache Provider对外提供读写操作 应用程序不用感知操作的是缓存还是数据
- Write behind: 延迟写入 Cache Provider 每隔一段时间 批量写入数据库,写入快 适用于频繁写,但缓冲和数据库不是强一致性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号