
1:指定输入段
#if defined(__HIGHTEC__)
#pragma section
#pragma section ".start" x /* hightec 编译器下声明函数 fun() 放入名为 .start 的指定输入段中,除了 .start 外全是关键字,.start 可以随意命名 */
#endif
#if defined(__TASKING__)
#pragma protect on
#pragma section code "start" /* tasking 编译器下声明函数 fun() 放入名为 .code.start 的指定输入段中,段名会自动添加 .code. ,除了 start 外全是关键字,start 可以随意命名 */
#endif
#if defined(__DCC__)
#pragma section CODE ".start" X /* 类似上面 */
#endif
#if defined(__ghs__)
#pragma ghs section text=".startup" /* ghs 编译器下声明函数 fun() 放入名为 .text.startup 的指定输入段中,除了 .startup 外全是关键字,.startup 可以随意命名 */
#endif
void fun(void)
{
}
if defined(__HIGHTEC__)
#pragma section /* hightec 编译器下声明结尾,必须和开头的声明成对存在,全是关键字无须修改 */
#endif
#if defined(__TASKING__)
#pragma protect restore
#pragma section code restore /* tasking 编译器下声明结尾,必须和开头的声明成对存在,全是关键字无须修改 */
#endif
#if defined(__DCC__)
#pragma section CODE /* dcc 编译器下声明结尾,必须和开头的声明成对存在,全是关键字无须修改 */
#endif
#if defined(__ghs__)
#pragma ghs section text=default /* ghs 编译器下声明结尾,必须和开头的声明成对存在,全是关键字无须修改 */
#endif
2:在AURIX中每个核心都有自己的DSPR和PSPR,每个区域都可以使用以下两个地址访问;1:全局地址:无论代码在哪个内核上执行,这个地址范围都指向同一个内存;2:本地地址:此地址将引用特定于核心的ram,并将根据执行代码的核心而更改。例如 : CPU0 DSPR从0x70000000开始,CPU1 DSPR从0x60000000开始。在代码中,如果您使用0x70000000,它将引用CPU0 DSPR,而不管访问是来自CPU0还是CPU1,这叫做全局地址;相反,如果您在代码中使用0xD0000000,如果代码从CPU0执行,它将访问0x70000000,如果它从CPU1执行,它将访问0x60000000,这叫做本地地址。提供这种功能是为了使代码相对于cpu具有可移植性。对于DSPR,本地地址从0xD0000000开始,对于PSPR,本地地址从0xC0000000开始
REGION_MAP( CPU0 , ORIGIN(dsram0_local), LENGTH(dsram0_local), ORIGIN(dsram0)) 定义dsram0的全局访问和本地访问地址
3:CORE_ID = CPU5; + CORE_SEC(.text) => 名为 .CPU5.text 的输出段; 而 CORE_ID = GLOBAL; + CORE_SEC(.text) => 名为 .text 的输出段
4:"output\objs\asw\ASW_IoHwAb\SensorActuator_ADC.o(.text.ADC_Get_func)"
"output\objs\asw\ASW_IoHwAb\SensorActuator_DIO.o(.text.DIO_Set_func)"
"output\objs\asw\ASW_IoHwAb\SensorActuator_DIO.o(.text.DIO_Get_func)"
通配符查找命令为 ("out*.*text) 其中()和 *.* 是主要关键字,("out*.*)是替换一整行, (^\n) 替换所有空行
5:单步可以而全速运行不行的情况一般出现在时序上,通过加入一小段延时,问题得以解决。而 printf 往往是一个需要阻塞运行很久的一个函数
6:提示警告 cast increase required alignment of target type,解决方法为类型强转前加 (void*) 比如 udp_fakehead = (struct udp_fakehead *)(void *)ptr;
7: trace32软件 Var下的show stack可以显示栈嵌套调用的深度,图中只看黑色的标识(-000 -001 -002)不看那个灰色的标识,标识数最大到002因此嵌套2层,因此当前csa的值为base值70EEC+2。LCX表示csa的上限值,FCX表示csa的当前值,每嵌套调用一层函数该值加1,FCX的最大值是LCX-1,不能等于LCX;本例中FCX的base值是70EEC;PCXI = FCX-1 表示上一层的csa栈值。PCXI中的bit20表示 上文1/下文0 的context;csa值与真实ram的换算:ram = FCX & 0x000F0000 << 12 + FCX & 0xFFFF << 6;
trace32软件 Var下的show stack可以显示栈嵌套调用的深度,图中只看黑色的标识(-000 -001 -002)不看那个灰色的标识,标识数最大到002因此嵌套2层,因此当前csa的值为base值70EEC+2。LCX表示csa的上限值,FCX表示csa的当前值,每嵌套调用一层函数该值加1,FCX的最大值是LCX-1,不能等于LCX;本例中FCX的base值是70EEC;PCXI = FCX-1 表示上一层的csa栈值。PCXI中的bit20表示 上文1/下文0 的context;csa值与真实ram的换算:ram = FCX & 0x000F0000 << 12 + FCX & 0xFFFF << 6;
8:一个context是64B,一个task的上文+下文=128B,因此1K可以保存128个context或64个task的信息
9:PSW寄存器的bit[6:0]表示调用深度,因此最深128级,因此最多需要128个csa,因此csa最大为8KB
10:指令 MFCR 读 核心寄存器值;指令 MTCR 写 核心寄存器值;
11:硬复位和软复位的区别是:硬复位会将cpu寄存器的值重置为复位值,同时将ram置为0;软复位则只会将cpu寄存器的值重置为复位值,ram中的值保持复位前的值不变
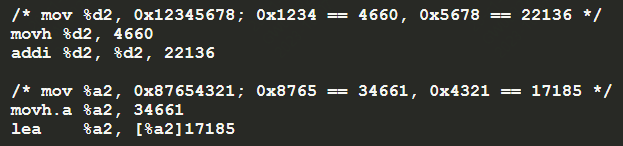
12:tc397下 分别将一个u32的数放入数据和地址寄存器2中的汇编代码
13:tricore 机器码与汇编代码的转换;
这里证明了即使没有编译,汇编,链接器,直接将汇编代码人工翻译为指令机器码,再通过烧录器存入rom中机器也能执行,即纸带代码。这也是代码套娃中从无到有的实现思想。
机器码在rom | 指令机器码 | 人能书写和理解
中的起始地址 | 字节序排列 | 的机器汇编代码


机器码 JA 后跟 disp24(B) 形式,且机器码 JA 用 9D 表示,因此 disp24[23:16] == 88; disp24[15:0] == 00 80(不是80 00) ;
但是我们要跳转的地址是80100000,应该是 9D 80 10 01 00 才对呀?原因在于特定于硬件架构的硬件操作,上图粉色标记表示此硬件架构会硬件自动
将24位的数据按上图的格式转为32位数据。类似 x86 下将16位的地址硬件右移4位变为20位的段基地址。
因此 disp[24:0] = 1000 1000 0000 0000 1000 0000 b;
PC = 1000 0000000 1000 0000 0000 1000 00000 b -> 1000 | 0000 | 0001 | 0000 | 0000 | 0001 | 0000 | 0000 b == 0x80100100
14:
Infineon-AURIX_TC3xx_Arch1.pdf






















Infineon-AURIX_TC3xx_Arch2.pdf












Infineon-AURIX_TC3xx_UM1.pdf






















 浙公网安备 33010602011771号
浙公网安备 33010602011771号