


k8s 搭建报错集合
http://www.sunrisenan.com/docs/kubernetes/docker.html
1.启动 traefik 时报错:
2.启动flannel 后容器之间不通,flannel的 配置ip 总是变化;
3.启动kubelet 时报错:Failed to start ContainerManager Cannot set property TasksAccounting, or unknow property
问题原因:主要原因还是centos系统版本兼容性问题,如果将系统做更新升级,即可解决。
# yum -y update
4.安装完flannel 后容器之间 互相ping不通,重启 pod 后也出现 容器之间不通的情况
- 排查:查看 kubelet 日志发现有报错:
couldn't propagate object cache: timed out waiting for the condition"
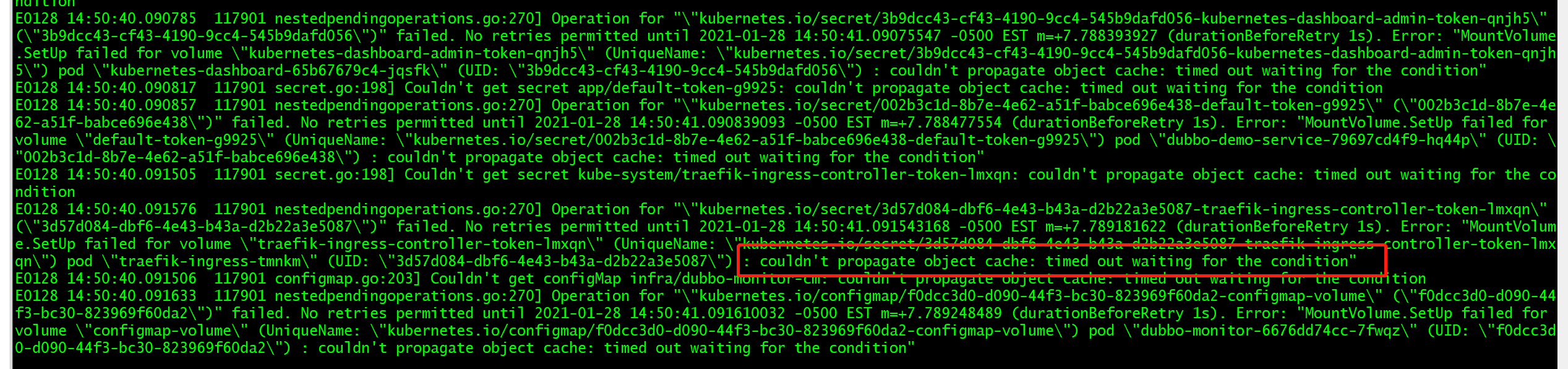
- 故障回溯:由于机器负载较高,曾经升级过机器的配置(cpu、mem)
解决:删除该节点上关于 CPU 的 CheckPoint 记录
~]# find / -name cpu_manager_state /data/kubelet/cpu_manager_state ~]# cat /data/kubelet/cpu_manager_state {"policyName":"none","defaultCpuSet":"","checksum":3242152201} ~]# rm -f /data/kubelet/cpu_manager_state
- 然后重启 docker 和 kubelet组件后 解决。
5.重启 pod 报错:
failed to collect filesystem stats - rootDiskErr: could not stat

暂未解决
5.安装 dubbo-monitor 启动pod 时报错 Back-off restarting failed container

解决:两台运算节点的 docker-images 不相同导致;
删除所有运算节点的 dubbo-monitor 的镜像,重启 pod 解决。
6. 无法拉取 私有项目代码报错

解决 :git@gitee.com:ssebank/dubbo-demo-web.git
8. 部署 apollo-portal 时 CI 错误,使用这个地址 https://toscode.gitee.com/liangshengqi/dubbo-demo-web/tree/apollo/
git@toscode.gitee.com:liangshengqi/dubbo-demo-web.git
9. 分环境后 pod 连接数据库报错

测试发现 只有一个node 节点可以正常连接(不能连接的node节点上的pod 不能解析数据库地址),短暂的解决办法是将无法连接的pod 在指定的node节点启动。
解决:先给node 节点打标签
# kubectl label node gmyf64-35.host.com disk=hdd --overwrite
( kubectl label nodes <node-name> <label-key>- #删除label语法
[root@k8s-node1 ~]# kubectl label node 192.168.29.182 disk- )
然后在 dp.yaml 中指定标签:
spec: nodeSelector: #node节点标签选择器
disk: ssd #node节点标签内容
启动 pod 后运行在指定 node 。


