Python3爬虫笔记(爬取豆瓣内地票房排行前100)
1.python2.0的版本
http://blog.csdn.net/rain_web/article/details/54946896
2.切换到3.0的一些问题
(1)
text = str.encode(''+'电影名:'+str(result[0])+' | 评分:'+str(result[1])+' | '+str(result[2])+'\t'+'\r\n')
python3需要添加str.encode不然会出现如图问题问题,

(2)按警告要求修改
soup = BeautifulSoup(html, "lxml")

(3)Python3没有urllib2需要修改
import urllib.request import time def get_html(url): #通过url获取网页内容 request = urllib.request.Request(url) response = urllib.request.urlopen(request) return response.read()
2.根据页面https://www.douban.com/doulist/1295618/?start=0&sort=seq&sub_type=
的html信息查看要爬取的数据信息
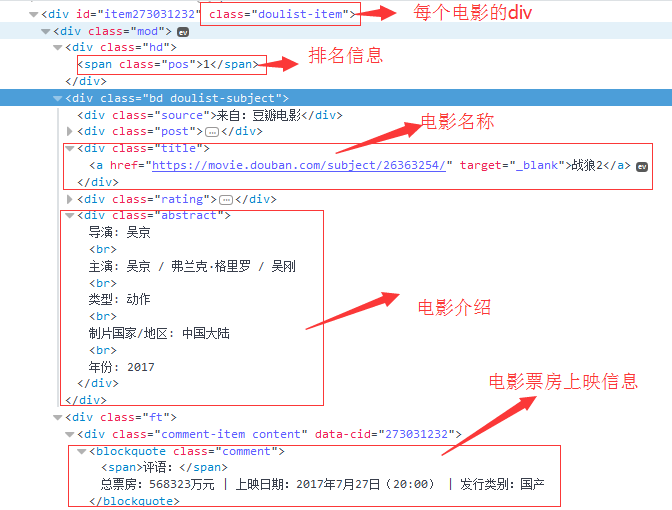
3、遇到的问题,中间有一个数据丢失,找不到,需要添加异常操作信息
完整的代码入下
# -*- coding: utf-8 -*- """ Created on Mon Jan 15 18:50:10 2018 @author: lanmeng """ from bs4 import BeautifulSoup import urllib.request import time def get_html(url): #通过url获取网页内容 request = urllib.request.Request(url) response = urllib.request.urlopen(request) return response.read() def save_file(text, filename,S): #保存网页到文件 f= open(filename,S) f.write(text) f.close() def read_file(filename): #读取文件 f = open(filename,'r') text = f.read() f.close() return text def get_movie_all(html): #通过soup提取到每个电影的全部信息,以list返回 soup = BeautifulSoup(html, "lxml") movie_list = soup.find_all('div', class_='doulist-item') return movie_list def get_movie_one(movie): result = [] # 用于存储提取出来的电影信息 soup_all = BeautifulSoup(str(movie), "lxml") try: rank = soup_all.find_all('div', class_='hd') soup_title = BeautifulSoup(str(rank[0]), "lxml") except IndexError: print ("写入文件失败") return result for ran in soup_title.stripped_strings: # 对获取到的排名进行提取 result.append(ran) try: title = soup_all.find_all('div', class_='title') soup_title = BeautifulSoup(str(title[0]), "lxml") except IndexError: print ("写入文件失败") return result for line in soup_title.stripped_strings: # 对获取到的电影标题<里的内容进行提取 result.append(line) try: num = soup_all.find_all('span',class_='rating_nums') soup_num = BeautifulSoup(str(num[0]), "lxml") except IndexError: print ("写入文件失败") return result for score in soup_num.stripped_strings: # 对获取到的<span>里的评分内容进行提取 result.append(score) try: info = soup_all.find_all('div', class_='abstract') soup_info = BeautifulSoup(str(info[0]), "lxml") except IndexError: print ("写入文件失败") return result result_str = "" for line in soup_info.stripped_strings: # 对获取到的<blockquote>里的内容进行提取 result_str = result_str + line result.append(result_str) try: info = soup_all.find_all('blockquote', class_='comment') soup_info = BeautifulSoup(str(info[0]), "lxml") except IndexError: print ("写入文件失败") return result result_str = "" for line in soup_info.stripped_strings: # 对获取到的<blockquote>里的内容进行提取 result_str = result_str + line result.append(result_str) return result #返回获取到的结果 if __name__=='__main__': title= str.encode('中国内地电影票房总排行'+'\r\n') save_file(title,'piaofang.txt','ab') for i in range(0,100,25): url = 'https://www.douban.com/doulist/1295618/?start='+str(i)+'&sort=seq&sub_type=' html = get_html(url) save_file(html,'piaofangH.txt','wb') movie_list = get_movie_all(html) #print(movie_list) for movie in movie_list: #将每一页中的每个电影信息放入函数中提取 result = get_movie_one(movie) try: text = str.encode('票房排名:'+str(result[0])+'\r\t'+'电影名:'+str(result[1])+' | 评分:'+str(result[2])+'\r\n'+' |介绍: '+str(result[3])+'\r\n'+' |票房信息: '+str(result[4])+'\t'+'\r\n') save_file(text,'piaofang.txt','ab') except IndexError: print ("写入文件失败") continue time.sleep(5) #每隔5秒抓取一页的信息
结果信息 


 浙公网安备 33010602011771号
浙公网安备 33010602011771号