PHP常见面试题总结
1、include 和 require 都能把另外一个文件包含到当前文件中 他们有什么区别?include 和 include_once 又有什么区别?
二者区别只有一个,那就是对包含文件的需求程度
include 就是包含,如果被包含的文件不存在的话, 那么则会提示一个错误,但是程序会继续执行下去。
require 意思是需要,如果被包含文件不存在或者 无法打开的时候,则会提示错误,并且会终止程序的执行。
这两种结构除了在如何处理失败之外完全一样。
once 的意思是一次,那么 include_once 和 require_once 表示只包含一次,避免重复包含。
2、用最少的代码写一个求 3 值最大的函数
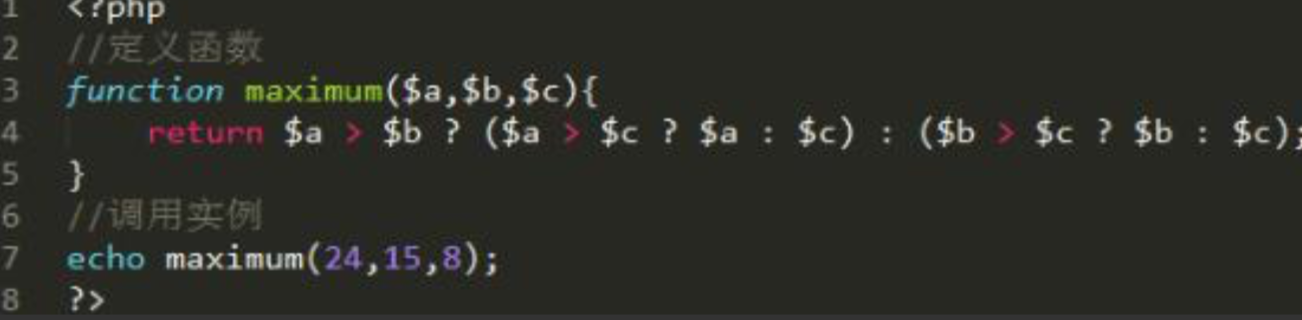
3、表单中 get 与 post 提交方法的区别?
3.1、GET 请求能够被 cache,GET 请求能够被保存在浏览器的浏览历史 里面(密码等重要数据 GET 提交,别人查看历史记录,就可以直接看 到这些私密数据)POST 不进行缓存。
3.2、GET 参数是带在 URL 后面,传统 IE 中 URL 的最大可用长度为 2053 字符,其他浏览器对 URL 长度限制实现上有所不同。POST 请求无长 度限制(目前理论上是这样的)。
3.4、全部用 POST 不是十分合理,最好先把请求按功能和场景分下类, 对数据请求频繁,数据不敏感且数据量在普通浏览器最小限定的 2k 范围内,这样的情况使用 GET。其他地方使用 POST。
3.5、GET 的本质是「得」,而 POST 的本质是「给」。而且,GET 是「幂 等」的,在这一点上,GET 被认为是「安全的」。但实际上 server 端 也可以用作资源更新,但是这种用法违反了约定,容易造成 CSRF(跨 站请求伪造)。
echo date('Y-m-d H:i:s',time()-24*3600);
或
echo date('Y-m-d H:i:s',strtotime('-1 day'));
5、假设现在有一个字符串 ww.baidu.com 如何使用 PHP 对他进行操作使字符串以 moc.udiab.输出?
$str='www.baidu.com';
//先替换,再反转
echo strrev('www','',$str);
客户端 IP:
$SERVER[“REMOTE_ADDR”]
或者
getenv('REMOTE_ADDR');
服务器 IP: $_SERVER[“SERVER_ADDR”]

'01' == '1'; 结果是 TRUEin_array('01',array('1'));结果是1
9、简述单引号和双引号的用法 双引号串中的内容可以被解释而且替换,
单引号串中的内容总被认为是普通字符。
10、计算某段字符串中某个字符出现的次数
(例如:gdfgfdgd59gmkblg 中 g 的次数) $text = 'gdfgfdgd59gmkblg';
echo substr_count ( $text,'g');
11、有一个楼梯n级台阶,每次可以上一级或两级台阶,有几种不同上法?
f(n) = f(n-1) + f(n-2).
如果我们第一部选1个台阶,那么后面就会剩下n-1个台阶,也就是会有f(n-1)种走法.如果我们第一部选2个台阶,后面会有f(n-2)个台阶.因此,对于n个台阶来说,就会有f(n-1) + f(n-2)种走法.
因此,1个台阶f(1) = 1.
f(2) = 2,
f(3) = 3
f(4) = 5
f(5) = 8
f(6) = 13
f(7) = 21
f(8) = 34
f(9) = 55
f(10) = 89
f(11) = 89+55 = 144
f(12) = 144 + 89 = 233
.
2.
这类题可这样理解
假设走到第n阶有f(n)种走法,走到第n+1阶有f(n+1)种走法;
则走到第n+2阶,则可分成两种情况:
一,最后一步是从第n阶直接登两级到第n+2阶
二,最后一步是从第n+1阶直接登一级到第n+2阶
由于从地面到第n阶,和到第n+1阶的走法已经知道
故从地面到第n+2阶的走法:
f(n+2)=f(n)+f(n+1)
n=1时,1种走法
n=2时,2种走法
n=3时,1+2=3种走法
n=4时,2+3=5种走法
<?php
//普通传值
$param1=1;
$param2=2;
$param2 = $param1;
$param1 = 5; //变量1和变量2是两块内存,互不影响;
echo $param2; //所以此处还是显示为1
//引用传值 ↓↓
$param1=1;
$param2=2;
$param2 = &$param1; //把变量1的内存地址赋给变量2;此时的变量2和变量1全等;
echo $param2;// 1
$param1 = 5; //变量1和变量2是一处内存,改变其中一个,另外一个也被改变;
echo $param2; //显示为5
?>
$a = 1;
$b = &$a;
unset($a);
echo $b; //1
首先,要理解变量名存储在内存栈中,它是指向堆中具体内存的地址,通过变量名查找堆中的内存;
普通传值,传值以后,是不同的地址名称,指向不同的内存实体;
引用传值,传引用后,是不同的地址名称,但都指向同一个内存实体;改变其中一个,另外一个就也被改变;
unset并没有真正销毁变量的作用...仅仅是切断了变量与内存之间的关系,内存只要还被引用着就不会被释放; $b和$a同时指向1,切断其中$a的关系,$b还是指向1,所以上题不报错,照样输出1。
//--------------如何理解static静态变量-----------
/** 普通局部变量 */
function local() {
$loc = 0; //这样,如果直接不给初值0是错误的。
++$loc;
echo $loc . '<br>';
}
local(); //1
local(); //1
local(); //1
echo '===================================<br/>';
/** static静态局部变量 */
function static_local() {
static $local = 0 ; //此处可以不赋0值
$local++;
echo $local . '<br>';
}
static_local(); //1
static_local(); //2
static_local(); //3
//echo $local; 注意虽然静态变量,但是它仍然是局部的,在外不能直接访问的。
echo '=======================================<br>';
/** static静态全局变量(实际上:全局变量本身就是静态存储方式,所有的全局变量都是静态变量) */
function static_global() {
global $glo; //此处,可以不赋值0,当然赋值0,后每次调用时其值都为0,每次调用函数得到的值都会是1,但是不能想当然的写上"static"加以修饰,那样是错误的.
$glo++;
echo $glo . '<br>';
}
static_global(); //1
static_global(); //2
static_global(); //3
?>
函数内部定义的则是局部变量,二者是两个不同的变量,除非 在函数内使用 global 显式声明使用全局变量或直接用 $_GLOBALS 来引用。
echo implode(‘ , ’ , $arr);
$str = ‘jack, james, tom, symfony’;请将$str 用’ , ’分割,并把分割后的值放到$arr 数组中
$arr = explode(‘ , ’ , $str);
15、说出数组涉及到的常用函数
array-- 声明一个数组
count -- 计算数组中的单元数目或对象中的属性个数
foreach-- 遍历数组
list -- 遍历数组
explode-- 将字符串转成数组
implode-- 将数组转成一个新字符串
array_merge-- 合并一个或多个数组
is_array-- 检查是否是数组
print_r -- 输出数组
sort -- 数组排序
array_keys-- 返回数组中所有的键名
array_values-- 返回数组中所有的值
key-- 从关联数组中取得键名
trim()-- 去除字符串首尾处的空白字符(或者其他字符)
strlen()-- 字符串长度
substr()-- 截取字符串
str_replace()-- 替换字符串函数
substr_replace()-- 对指定字符串中的部分字符串进行替换
strstr()-- 检索字符串函数
explode()-- 分割字符串函数
implode()-- 将数组合并成字符串
str_repeat()-- 重复一个字符串
addslashes()-- 转义字符串
htmlspecialchars()--THML 实体转义
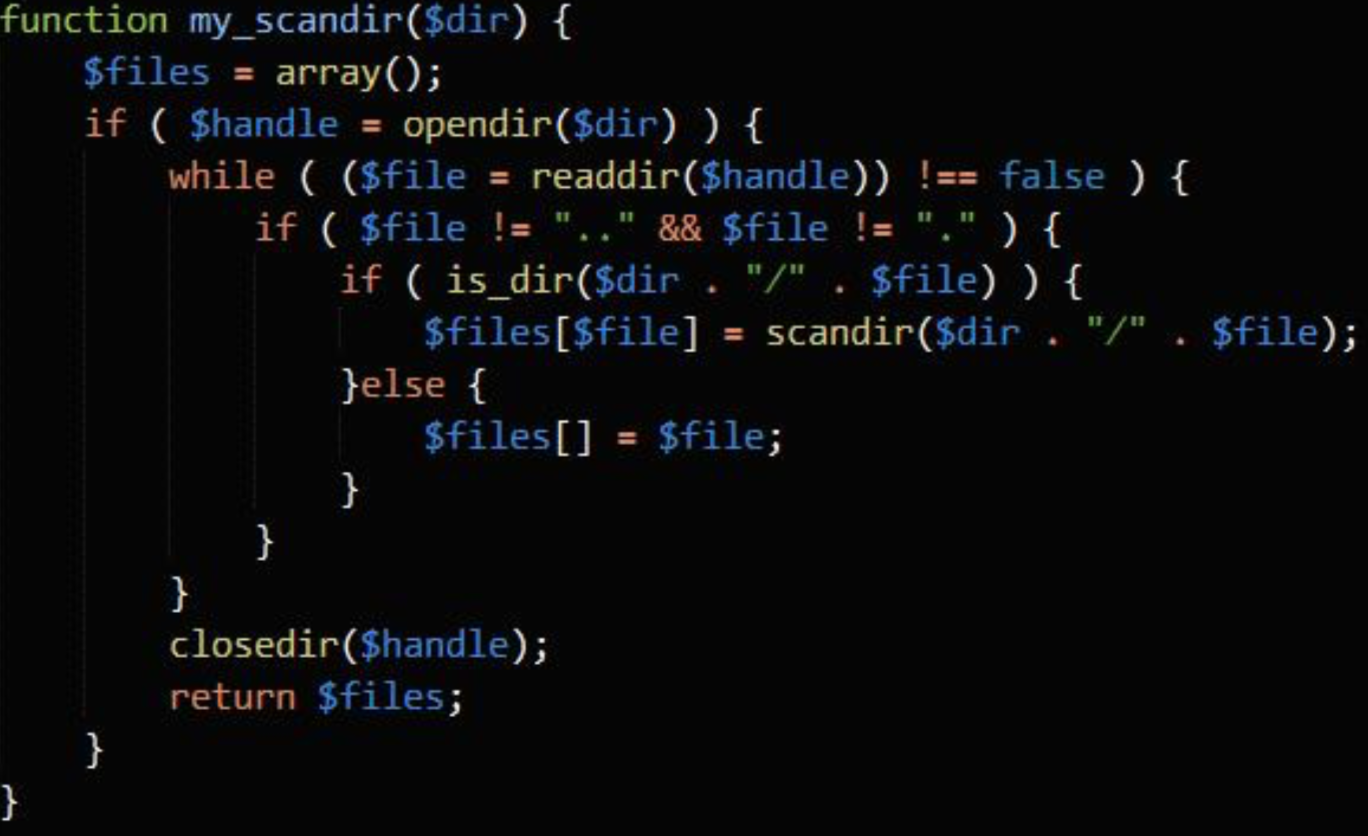

如果变量是 null 则返回 TRUE,否则返回 FALSE。
在下列情况下一个变量被认为是 NULL:
1) 被赋值为 NULL
2) 尚未被赋值
3) 被 unset()
$_ENV;
$_SERVER;
$_REQUEST
$_FILES
$_SESSION;
$_COOKIE;
$_GET;
COOKIE保存在客户端,而SESSION则保存在服务器端
从安全性来讲,SESSION的安全性更高
从保存内容的类型的角度来讲,COOKIE只保存字符串(及能够自动转换成字符串)
从保存内容的大小来看,COOKIE保存的内容是有限的,比较小,而SESSION基本上没有这个限制
从性能的角度来讲,用SESSION的话,对服务器的压力会更大一些
SEEION依赖于COOKIE,但如果禁用COOKIE,也可以通过url传递
protected: 继承,只能在本类或子类中访问,在其它地方不允许访问
private: 私有,只能在本类中访问,在其他地方不允许访问
<?php namespace Test; class Database { //私有化内部实例化的对象 private static $instance = null; //私有化构造方法,禁止外部实例化 private function __construct(){} //私有化__clone,防止被克隆 private function __clone(){} // 公有静态实例方法 public static function getInstance(){ if(!empty(self::$instance)){ return self::$instance; }else{ self::$instance=new Database(); return self::$instance; } } } $obj1=Database::getInstance(); $obj2=Database::getInstance(); $obj3=Database::getInstance(); var_dump($obj1,$obj2,$obj3); echo $obj1==$obj2?1:0; echo "<br>"; echo $obj1==$obj3?1:0;
有些类只需要实例化一次,像数据库连接类,实例化多次的话会浪费资源,这时候就会用到单例模式
简单的来说是“三私一公”:
构造方法私有化后就不能从外部实例化类了,但是怎么实例化呢?
就要用到静态方法了,将其公有化,便可在外部实例化类了,
在方法里判断对象是否为空,如果为空就实例化,存在就直接将它返回,这样便实现了只实例化一次了
23、接口和抽象类的区别是什么?
抽象类是一种不能被实例化的类,只能作为其他类的父类来使用。 抽象类是通过关键字 abstract 来声明的。
抽象类与普通类相似,都包含成员变量和成员方法,两者的区别 在于,抽象类中至少要包含一个抽象方法,
抽象方法没有方法体,该方法天生就是要被子类重写的。 抽象方法的格式为:abstract function abstractMethod();
接口是通过 interface 关键字来声明的,接口中的成员常量和方法都是 public 的,方法可以不写关键字 public, 接口中的方法也是没有方法体。接口中的方法也天生就是要被子类实现的。
抽象类和接口实现的功能十分相似,最大的不同是接口能实现多继承。在应用中选择抽象类还是接口要看具体实现。 子类继承抽象类使用 extends,子类实现接口使用 implements。
类中的常量也就是成员常量,常量就是不会改变的量,是一个恒 值。定义常量使用关键字 const,例如:const PI = 3.1415326;
无论是类内还是类外,常量的访问和变量是不一样的,常量不需 要实例化对象,
访问常量的格式都是类名加作用域操作符号(双冒号)来调用, 即:类名:: 类常量名。
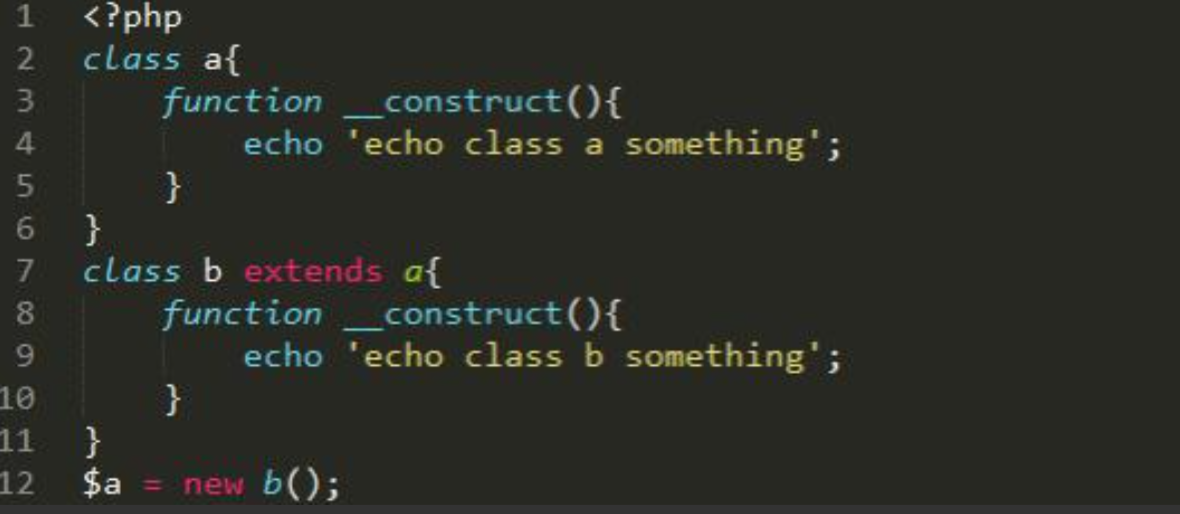
所以子类中的构造函数覆盖了父类的构造函数,要想子类对象实例化时也执行父类的构造函数,需要在子类构造函数中使用parent::__construct()来显示调用父类构造函数。
最小权限原则,特别是不要用 root 账户,为不同的类型的动作或 者组建使用不同的账户。
当 sql 运行出错时,不要把数据库返回的错误信息全部显示给用 户,以防止泄露服务器和数据库相关信息。
mysqldump -u 用户名 -p 密码 库名 表名 > 文件名(如 D:/a.sql)
(2). 导出多张表
mysqldump-u用户名-p密码 库名 表名1表名2表名3>文件名(如 D:/a.sql)
(3). 导出所有表
mysqldump -u 用户名 -p 密码 库名 > 文件名(如 D:/a.sql)
(4). 导出一个库
mysqldump -u 用户名 -p 密码 -B 库名 > 文件名(如 D:/a.sql)
28、MySQL 数据库中的字段类型 varchar 和 char 的主要区别? 那种字段的查找效率要高,为什么?
区别一,定长和变长
char 表示定长,长度固定,varchar 表示变长,即长度可变
当所插入的字符串超出它们的长度时,视情况来处理,如果是严格模式,则会拒绝插入并提示错误信息,如果是宽松模式,则会截取
然后插入。如果插入的字符串长度小于定义长度时,则会以不同的方
式来处理,如char(10) ,表示存储的是10个字符,无论你插入的
是多少,都是 10 个,如果少于 10 个,则用空格填满。而 varchar(10) ,
小于 10 个的话,则插入多少个字符就存多少个。
varchar 怎么知道所 存储字符串的长度呢?实际上,对于 varchar 字段来说,需要使用一 个(如果字符串长度小于 255)或两个字节(长度大于 255)来存储字符串的长度。
区别之二,存储的容量不同
对 char 来说,最多能存放的字符个数 255,和编码无关。
而 varchar 呢,最多能存放 65,532 个字符。
varchar 的最大有效长度由最大行大小和使用的字符集确定,整体最大长度是 65,532 字节,最大有效长度是 65532 字节,在 varchar 存字符串的时候,第一个字节是空的,不存任何的数据,然后还需要两个字节来存放字符串的长度。所以有效长度就是 65535 - 1 - 2= 65532
由字符集来确定,字符集分单字节和多字节
Latin1 一个字符占一个字节,最多能存放 65532 个字符
GBK 一个字符占两个字节, 最多能存 32766 个字符
UTF8 一个字符占三个字节, 最多能存 21844 个字符
注意,char 和 varchar 后面的长度表示的是字符的个数,而不是字节数。
两相比较,char 的效率高,没有碎片,尤其更新比较频繁的时候,方便数据文件指针的操作。但不够灵活,在实际使用时,应根据实际需求来选用合适的数据类型。
29、IP 该如何存储?
最简单的办法是使用字符串(varchar)来保存,如果从效率考虑 的话,可以将 ip 保存为整型(unsignedint) ,使用 php 或 mysql 提供的函数将 ip 转换为整型,然后存储即可。
PHP 函数:long2ip()和 ip2long()
MySQL 函数:inet_aton()和 inet_ntoa
30、请简述项目中优化 sql 语句执行效率的方法,从哪些方面,sql语句性能如何分析?
1) 尽量选择较小的列
2) 将where中用的比较频繁的字段建立索引
3) select 子句中避免使用‘*’
4) 避免在索引列上使用计算、not in 和<>等操作
5) 当只需要一行数据的时候使用limit1
5) 保证单表数据不超过200W,适时分割表。
6)选取最适用的字段属性,尽可能减少定义字段长度,尽量把字段 设置 not null 例如'省份,性别',最好设置为 enum
针对查询较慢的语句,可以使用explain 来分析该语句具体的执 行情况。
31、今有鸡翁一,值钱五;鸡母一,值钱三;鸡雏三,值钱一; 百钱买鸡百只,问鸡翁,母,雏个几何?
问:在这 100 只鸡中,公鸡,母鸡和小鸡是多少只?(设每种至少一只)




$order_array=array( 5,4,3,6,7,1,2,10,8,9 ); function bubble_order($arr){ //得到长度 $count_num=count($arr); for($k=1;$k<$count_num;$k++){ //对长度越来越少的一组数据 找出最大让其浮到最后 for($i=0;$i<$count_num-$k;$i++){ if($arr[$i]>$arr[$i+1]){//相邻比较 $tem=$arr[$i]; $arr[$i]=$arr[$i+1]; $arr[$i+1]=$tem; } } } return $arr; } $new_order_arr=bubble_order($order_array);
区别主要有以下几个:
构成上,MyISAM 的表在磁盘中有三个文件组成,分别是表定义文 件(.frm) 、数据文件(.MYD) 、索引文件(.MYI),而 InnoDB 的 表由表定义文件(.frm)、表空间数据和日志文件组成。
安全方面,MyISAM 强调的是性能,其查询效率较高,但不支持事 务和外键等安全性方面的功能,而 InnoDB 支持事务和外键等高级功 能,查询效率稍低。
/** * 反转数组 * @param array $arr * @return array */ function reverse($arr) { $n = count($arr); $left = 0; $right = $n - 1; while ($left < $right) { $temp = $arr[$left]; $arr[$left++] = $arr[$right]; $arr[$right--] = $temp; } return $arr; }
37、打乱数组
/** * 打乱数组 * @param array $arr * @return array */ function custom_shuffle($arr) { $n = count($arr); for ($i = 0; $i < $n; $i++) { $rand_pos = mt_rand(0, $n - 1); if ($rand_pos != $i) { $temp = $arr[$i]; $arr[$i] = $arr[$rand_pos]; $arr[$rand_pos] = $temp; } } return $arr; }
Memcache
- 该产品本身特别是数据在内存里边的存储,如果服务器突然断电,则全部数据就会丢失
- 单个key(变量)存放的数据有1M的限制
- 存储数据的类型都是String字符串类型
- 本身没有持久化功能
- 可以使用多核(多线程)
Redis
- 数据类型比较丰富:String、List、Set、Sortedset、Hash
- 有持久化功能,可以把数据随时存储在磁盘上
- 本身有一定的计算功能
- 单个key(变量)存放的数据有1GB的限制
INDEX(`a`, `b`, `c`)| 使用方式 | 能否用上索引 |
|---|---|
| select * from users where a = 1 and b = 2 | 能用上a、b |
| select * from users where b = 2 and a = 1 | 能用上a、b(有MySQL查询优化器) |
| select * from users where a = 2 and c = 1 | 能用上a |
| select * from users where b = 2 and c = 1 | 不能 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号