敏感目录信息收集
简介
目录扫描可以让我们发现这个网站存在多少个目录,多少个页面,探索出网站的整体结构。通过目录扫描我们还能扫描敏感文件,后台文件,数据库文件,和信息泄漏文件等等
目录扫描有两种方式:
- 使用目录字典进行暴力才接存在该目录或文件返回200或者403;
- 使用爬虫爬行主页上的所有链接,对每个链接进行再次爬行,收集这个域名下的所有链接,然后总结出需要的信息。
常见敏感文件
1.robots.txt
2.crossdomin.xml
3.sitemap.xml
4.后台目录
5.网站安装包
6.网站上传目录
7.mysql管理页面
8.phpinfo
9.网站文本编辑器
10.测试文件
11.网站备份文件(.rar、.zip、.7z、.tar、.gz、.bak)
12.DS_Store 文件
13.vim编辑器备份文件(.swp)
14.WEB—INF/web.xml文件
robots.txt
robots.txt 是什么?
robots.txt是一个纯文本文件,在这个文件中网站管理者可以声明该网站中不想被搜索引擎访问的部分,或者指定搜索引擎只收录指定的内容。当一个搜索引擎(又称搜索机器人或蜘蛛程序)访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,那么搜索机器人就沿着链接抓取。
robots.txt 的作用
1、引导搜索引擎蜘蛛抓取指定栏目或内容;
2、网站改版或者URL重写优化时候屏蔽对搜索引擎不友好的链接;
3、屏蔽死链接、404错误页面;
4、屏蔽无内容、无价值页面;
5、屏蔽重复页面,如评论页、搜索结果页;
6、屏蔽任何不想被收录的页面;
7、引导蜘蛛抓取网站地图;
robots.txt 的语法
- User-agent:(定义搜索引擎)
示例:
User-agent: *(定义所有搜索引擎)
User-agent: Googlebot(定义谷歌,只允许谷歌蜘蛛爬取)
User-agent: Baiduspider(定义百度,只允许百度蜘蛛爬取)
不同的搜索引擎的搜索机器人有不同的名称,谷歌:Googlebot、百度:Baiduspider、MSN:MSNbot、Yahoo:Slurp。
- Disallow:(用来定义禁止蜘蛛爬取的页面或目录)
示例:
Disallow: /(禁止蜘蛛爬取网站的所有目录 "/" 表示根目录下)
Disallow: /admin (禁止蜘蛛爬取admin目录)
Disallow: /abc.html(禁止蜘蛛爬去abc.html页面)
Disallow: /help.html (禁止蜘蛛爬去help.html页面)
- Allow:(用来定义允许蜘蛛爬取的页面或子目录)
示例:
Allow: /admin/test/(允许蜘蛛爬取admin下的test目录)
Allow: /admin/abc.html(允许蜘蛛爬去admin目录中的abc.html页面)

crossdomin.xml
跨域,顾名思义就是需要的资源不在自己的域服务器上,需要访问其他域服务器。跨域策略文件是一个xml文档文件,主要是为web客户端(如Adobe Flash Player等)设置跨域处理数据的权限。打个比方说,公司A部门有一台公共的电脑,里面存放着一些资料文件,专门供A部门内成员自己使用,这样,A部门内的员工就可以访问该电脑,其他部门人员则不允许访问。如下图:
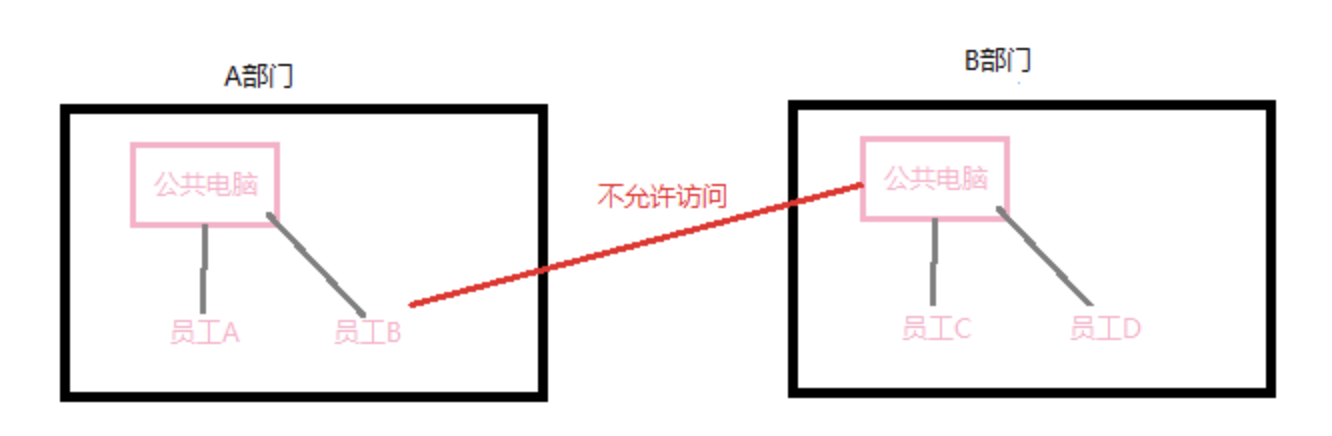
A部门的员工可以任意访问A部门的公共电脑,但是不能直接访问B部门的公共电脑。有一天,B部门领导觉得他们的资料非常有用,想要与A部门分享,于是就给A部门一个令牌,这样A部门的员工也可以访问B部门的公共电脑了。A部门可访问B部门设置访问权限,这个权限设置就是跨域策略文件crossdomain.xml存在的意义。
crossdomin.xml 示例文件如下,重点查看allow-access-from字段获取网站目录信息

sitmap.xml
sitmap是什么?
Sitemap 可方便网站管理员通知搜索引擎他们网站上有哪些可供抓取的网页。最简单的 Sitemap 形式,就是XML 文件,在其中列出网站中的网址以及关于每个网址的其他元数据(上次更新的时间、更改的频率以及相对于网站上其他网址的重要程度为何等),以便搜索引擎可以更加智能地抓取网站。
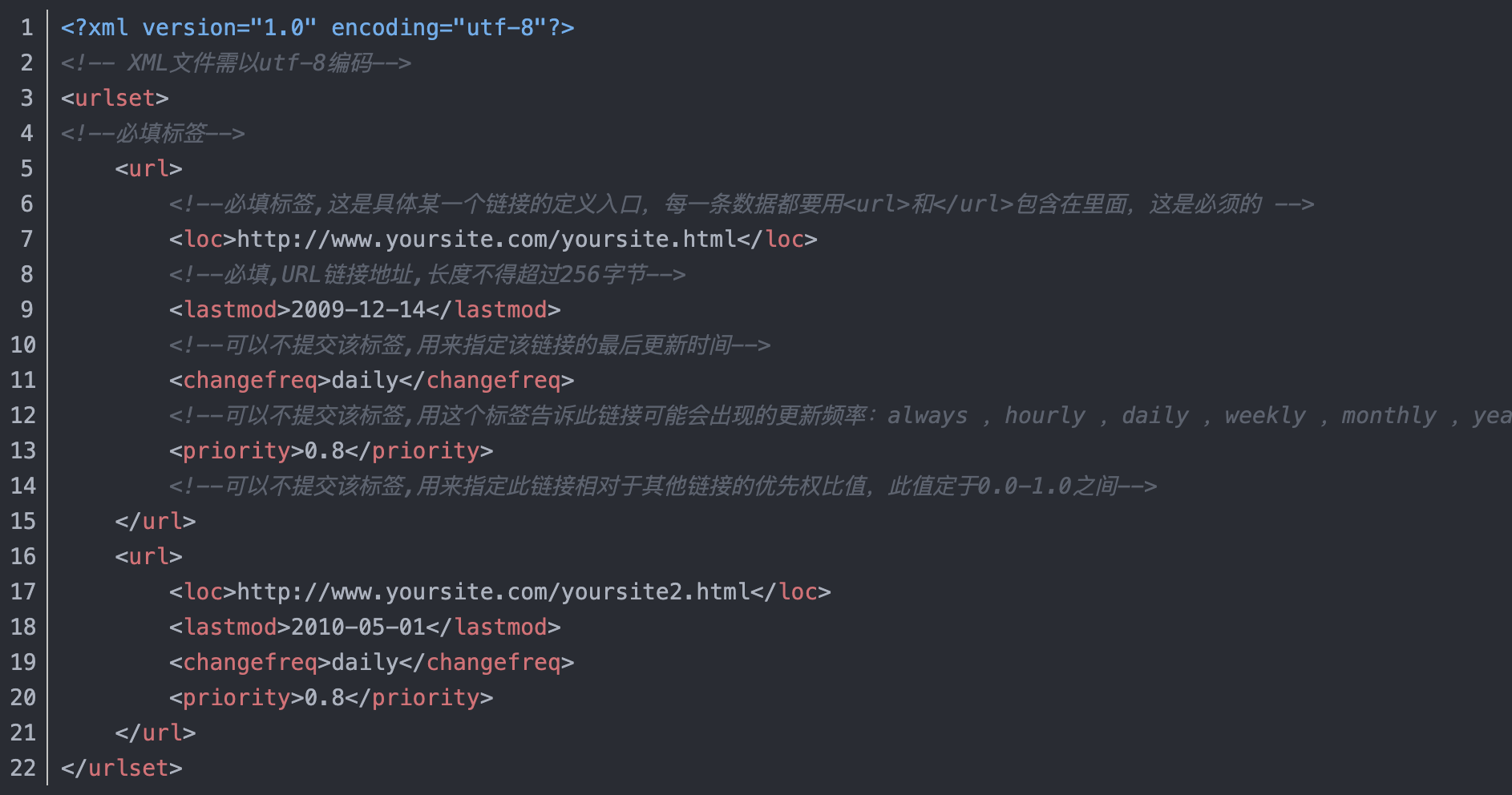
sitmap.xml 示例如下
源代码泄露
.git源代码泄露
Git是一个开源的分布式版本控制系统,在执行git init初始化目录的时候,会在当前目录下自动创建一个.git目录,用来记录代码的变更记录等。发布代码的时候,如果没有把.git这个目录删除,就直接发布到了服务器上,攻击者就可以通过它来恢复源代码。
利用工具GitHack:https://github.com/BugScanTeam/GitHack
扫描目录:
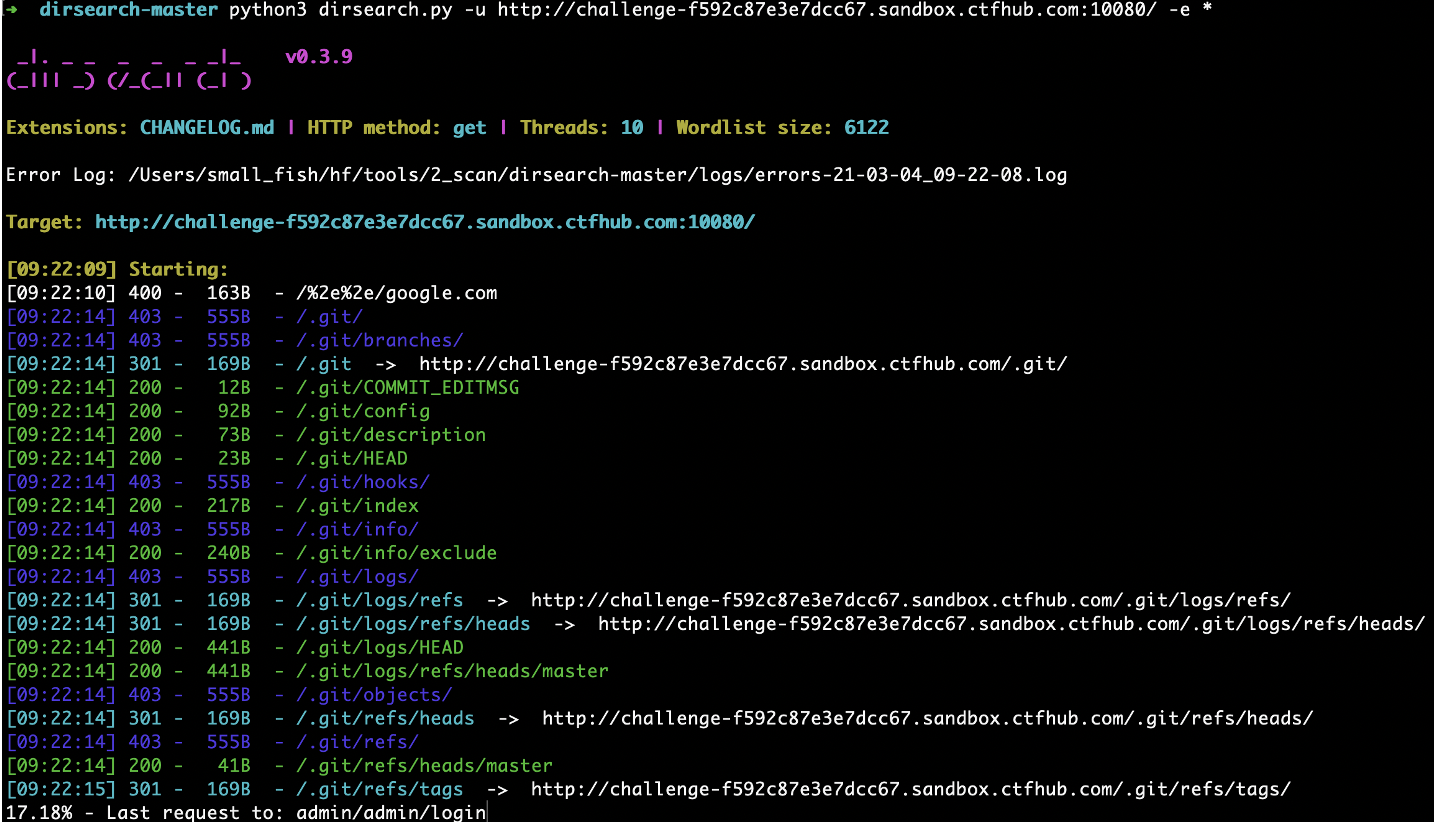
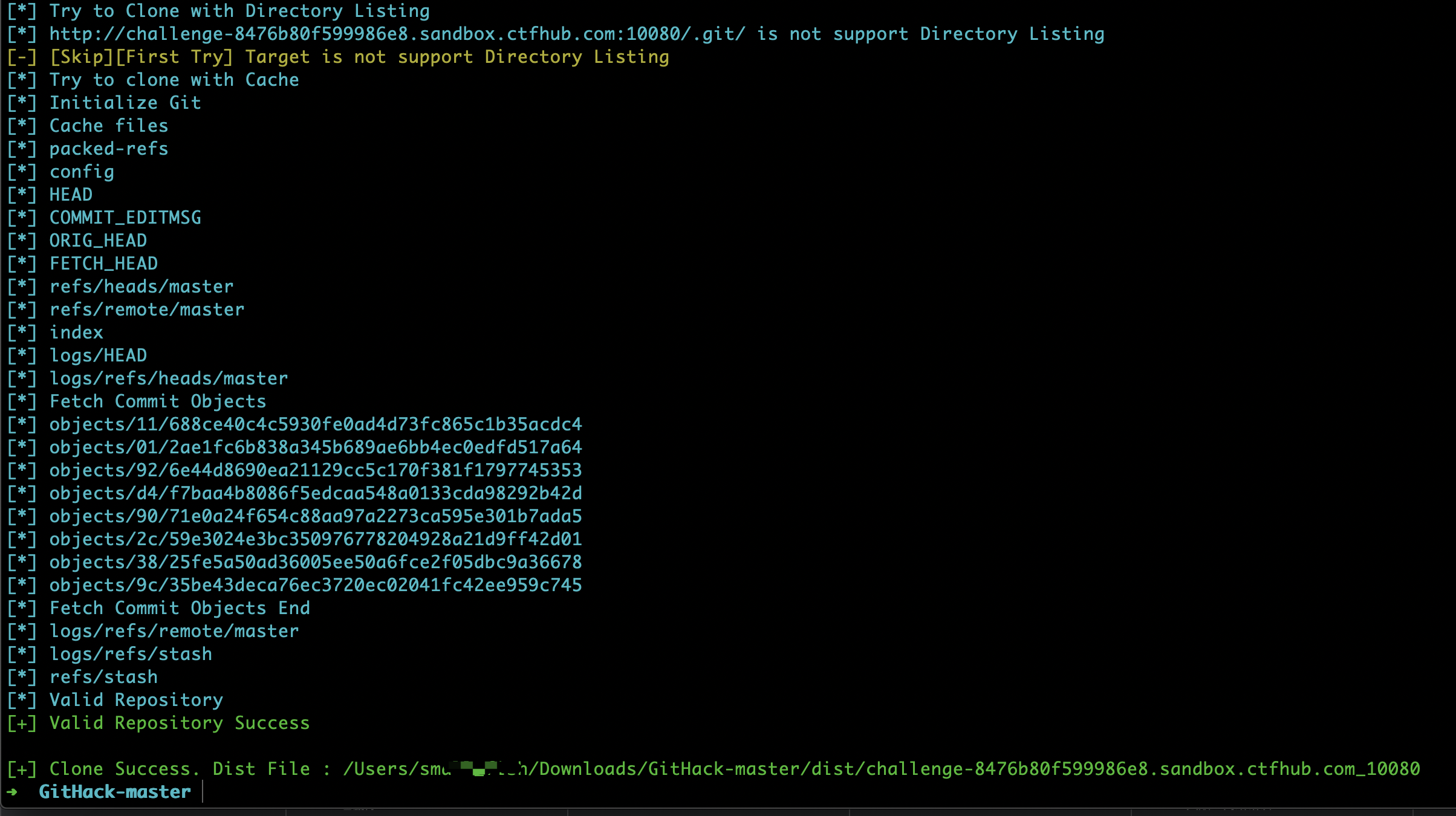
使用GitHack工具成功恢复代码
.cvs源代码泄露
CVS是一个C/S系统,多个开发人员通过一个中心版本控制系统来记录文件版本,从而达到保证文件同步的目的。主要是针对 CVS/Root以及CVS/Entries目录,直接就可以看到泄露的信息。
返回根信息:http://url/CVS/Root
返回所有文件的结构:http://url/CVS/Entries
漏洞利用工具:dvcs-ripper
github项目地址:https://github.com/kost/dvcs-ripper.git
运行示例:rip-cvs.pl -v -u http://www.example.com/CVS
.svn源代码泄露
SVN是一个开放源代码的版本控制系统。在使用SVN管理本地代码过程中,会自动生成一个名为.svn的隐藏文件夹,其中包含重要的源代码信息。网站管理员在发布代码时,没有使用‘导出’功能,而是直接复制代码文件夹到WEB服务器上,这就使.svn隐藏文件夹被暴露于外网环境,可以利用.svn/entries文件,获取到服务器源码。
漏洞利用工具:Seay SVN漏洞利用工具
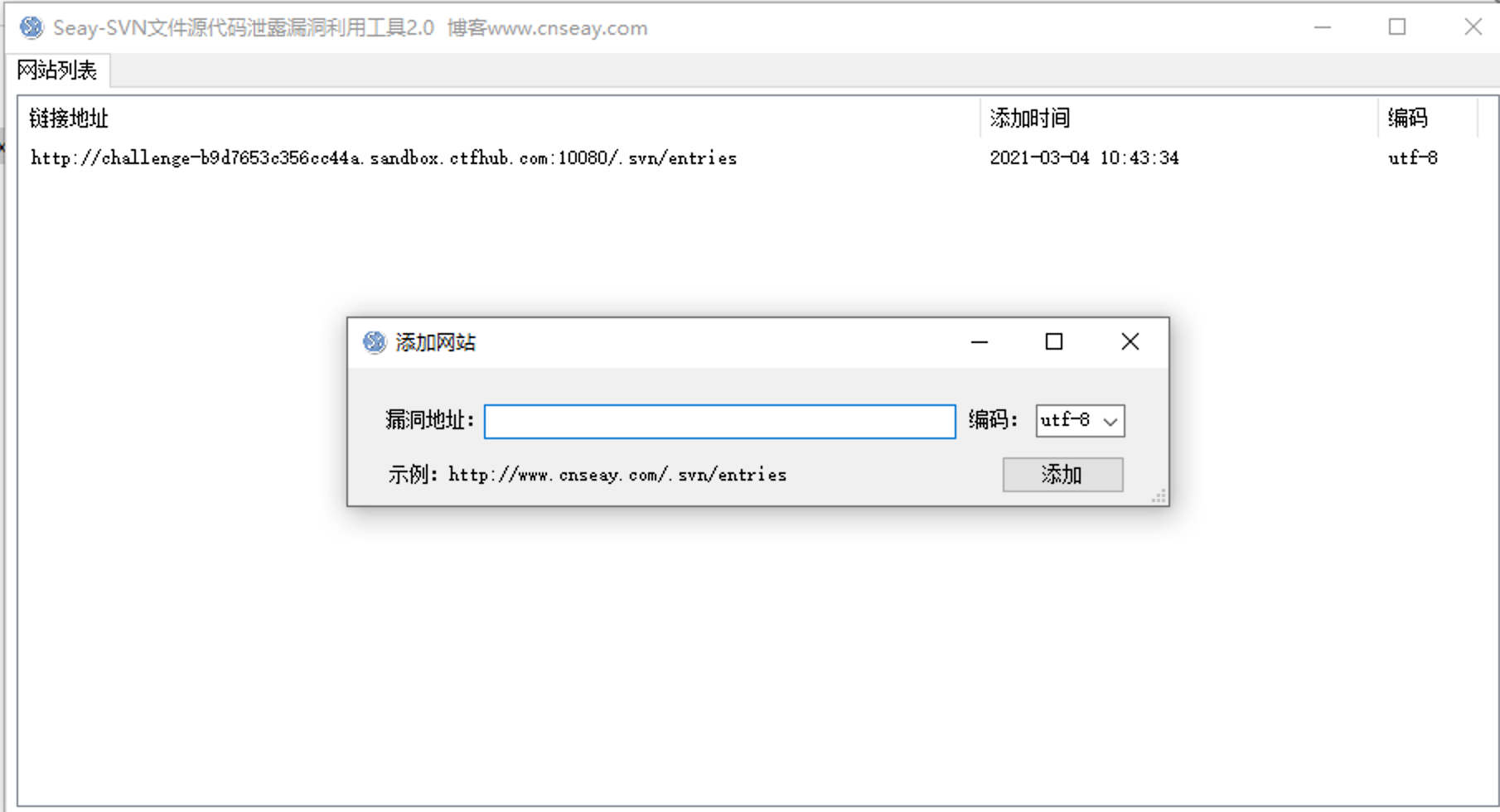
扫描站点存在/.svn/entries目录
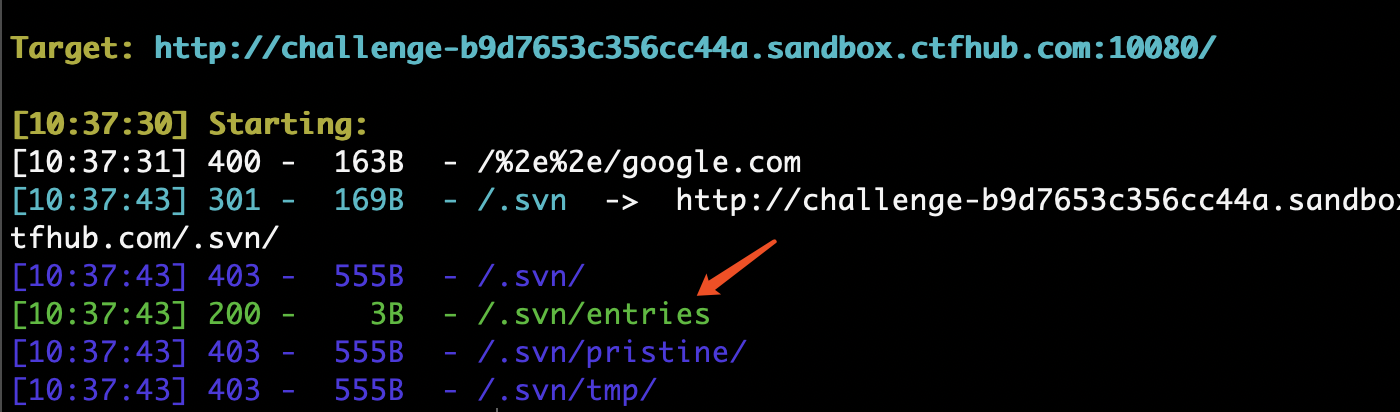
python svnExploit-master 成功恢复代码
.hg源代码泄露
Mercurial 是一种轻量级分布式版本控制系统,使用 hg init的时候会生成.hg。
漏洞利用工具: dvcs-ripper
github项目地址: https://github.com/kost/dvcs-ripper
用法示例:rip-hg.pl -v -u http://www.example.com/.hg/
.DS_store文件泄露
.DS_Store是Mac下Finder用来保存如何展示 文件/文件夹 的数据文件,每个文件夹下对应一个。如果将.DS_Store上传部署到服务器,可能造成文件目录结构泄漏,特别是备份文件、源代码文件。
漏洞利用工具:
github项目地址: https://github.com/lijiejie/ds_store_exp
用法示例:ds_store_exp.py http://xxx.com/.DS_Store
网站备份文件泄露rar、zip、tar.gz、7z、bak、tar
管理员将网站源代码备份在Web目录下,攻击者通过猜解文件路径,下载备份文件,导致源代码泄露。
常见的备份文件后缀:.rar、.zip、.7z、.tar.gz、.bak、.txt、.old、.temp
SWP 文件泄露
swp即swap文件,在编辑文件时产生的临时文件,它是隐藏文件,如果程序正常退出,临时文件自动删除,如果意外退出就会保留,文件名为 .filename.swp。
漏洞利用:直接访问.swp文件,下载回来后删掉末尾的.swp,获得源码文件。
WEB-INF/web.xml 泄露
WEB-INF是Java的WEB应用的安全目录,如果想在页面中直接访问其中的文件,必须通过web.xml文件对要访问的文件进行相应映射才能访问。
WEB-INF 主要包含一下文件或目录:
WEB-INF/web.xml : Web应用程序配置文件, 描述了servlet和其他的应用组件配置及命名规则.
WEB-INF/database.properties : 数据库配置文件
WEB-INF/classes/ : 一般用来存放Java类文件(.class)
WEB-INF/lib/ : 用来存放打包好的库(.jar)
WEB-INF/src/ : 用来放源代码(.asp和.php等)
通过找到 web.xml 文件,推断 class 文件的路径,最后直接 class 文件,再通过反编译 class 文件,得到网站源码。
敏感目录收集方式
网页中寻找
- 在robots.txt中看能否发现敏感目录
- F12源代码链接处
- 通过查看一些图片的属性路径,运气好会发现很多隐藏的目录
结合域名+目录,用御剑进行扫描,当然也可以手动输入一些常见的后台管理地址进行访问。
其他端口中寻找
有时候网站的不同端口中有一些便是专门的后台管理地址。根据经验总结,很多网站8080、8081端口是网站的管理地址。
eg:http://www.xxx.com:8080
网站分目录下寻找
有的时候网站会把管理地址放在一个分目录下,有的时候一个网站比较大,后台管理页面也比较多,就要分目录的去找,
eg:http://www.xxx.com/test/admin/manage.php
你可以通过一些方式获取到网站的目录,然后在这个目录下进行扫描。当一个网站你扫描根目录没有任何收获时,这个时候通过分析网站的目录结构,然后扫描域名+目录,就能找出它的后台管理地址。
子域名下寻找
有的时候网站的管理地址会放在子域名下,所以主站什么都找不到的情况下,如果发现子域名,就通过这些方法去子域名下找一下吧。
eg: http://admin.xxx.com/login
google hacker
网站爬虫
通过awvs,burpsuite的爬行功能,可以拓扑出网站的目录结构,有的时候运气好能在网页的目录结构中找到好东西,不过爬行一般会结合工具扫描,比如你构造域名+目录,然后扫描这个。
burp spider爬行
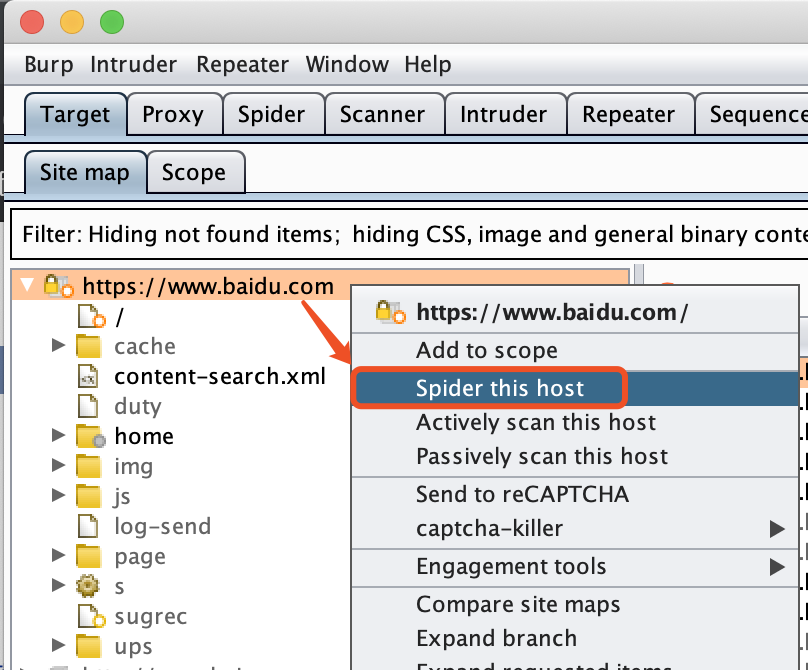
扫描工具
御剑
dirsearch
python3 dirsearch -u url -e *
Weakfilescan

burp插件path_shadow_scanner
自动化扫描website js中的目录信息,成功列出敏感目录信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号