ImageNet Classification with Deep Convolutional Neural Networks
2012年Alex等人在ImageNet大赛上以远超第二名的成绩夺冠,CNN重新受到了人们的重视
论文链接:http://www.cs.toronto.edu/~fritz/absps/imagenet.pdf
1 Introduction
相比于前向神经网络CNN拥有相似的层大小,并且拥有更少的层数和参数,所以CNN的训练更为容易,理论最优值可能会稍差一点
我们的神经网络包含了一些新的特征去提高性能并且可以减少训练时间,这些特性会在第三部分进行说明。一些过拟合的方法在第四节说明。该AlexNet模型中包含了5层卷积层和3层全连接层,去掉任何一层,每层的参数超过总数的1%,后都会使最终的性能下降。
2 The Dataset
3 The Architecture
3.1 ReLU:f(x) = max(0, x)
在深度卷积神经网络中ReLU比tanh训练时间更快
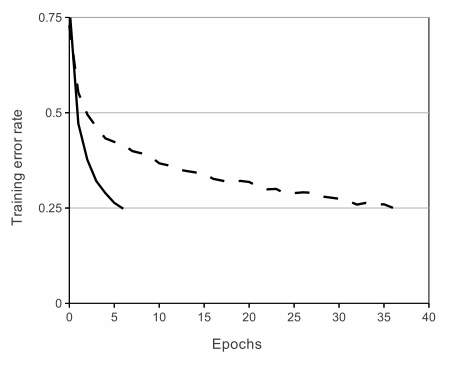
Figure 1: A four-layer convolutional neural network with ReLUs (solid line) reaches a 25% training error rate on CIFAR-10 six times faster than an equivalent network with tanh neurons (dashed line).
3.2 Training on Multiple GPUs
采用了两块GPU,每块GPU上分布着一半的神经元,并且上一层神经元的输出只能作为同一块GPU上下一层神经元的输入
3.3 Local Response Normalization
ReLU可以不进行归一化(PS:归一化可以加速训练),但论文中采用下列归一化公式
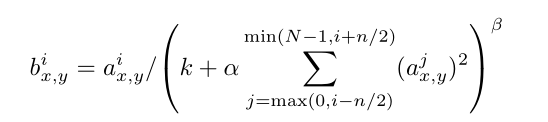
其中k, n, α,β为超参数,N为这一层神经网络中核(感受野)的数量
3.4 Overlapping Pooling
传统方法上的池化中没有重叠,当有重叠时,我们得到的是重叠池(overlapping pooling),使用重叠池的时候可以稍微防止过拟合的发生
3.5 Overall Architecture
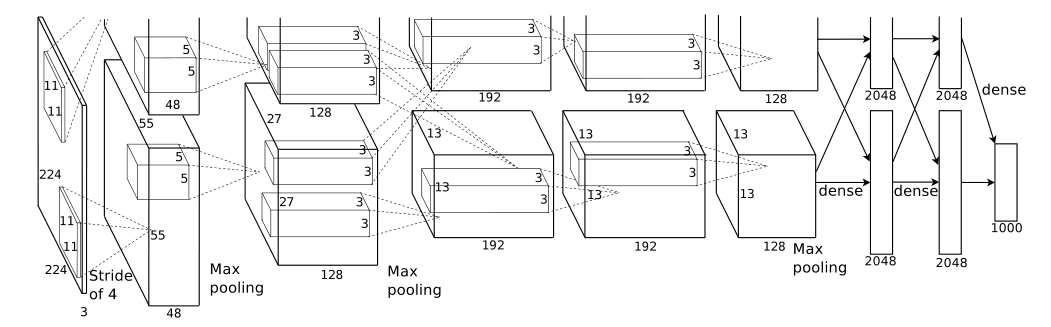
第一层:卷积层 卷积 --> ReLU --> 池化 --> 归一化
第二层:卷积层 卷积 --> ReLU --> 池化 --> 归一化
第三层:卷积层 卷积 --> ReLU
第四层:卷积层 卷积 --> ReLU
第五层:卷积层 卷积 --> ReLU --> 池化
第六层:全连接层 全连接 --> ReLU --> Dropoout
第七层:全连接层 全连接 --> ReLU --> Dropoout
第八层:全连接层 全连接

4 Reducing Overfitting
4.1 Data Augmentation
扩大数据集可以降低过拟合,一种扩充数据的方法是对图像进行平移和镜像翻转。在256*256大小的图片随机采取224*224大小的图片,这可以将我们的数据集扩大为2048倍,如果没有这个方法神经网络会存在严重的过拟合。
第二种方法是改变图片中RGB通道的强度,对RGB像素值进行PCA操作。
4.2 Dropout
将每个神经元输出的值设置为0,概率为0.5。在前两个FC层使用了dropout。使用dropout会增加一倍的迭代次数,可以降低过拟合的风险。
5 Details of learning
讲述了CNN中关于卷积层和全连接层中一些超参数的初始化问题。当验证错误率不在随着当前的学习率提高时,将学习率除以10。学习率初始化为0.01。

