


5 ByteBuf

Netty 的数据处理API 通过两个组件暴露——abstract class ByteBuf 和interface ByteBufHolder。
下面是一些ByteBuf API 的优点:
它可以被用户自定义的缓冲区类型扩展;
通过内置的复合缓冲区类型实现了透明的零拷贝;
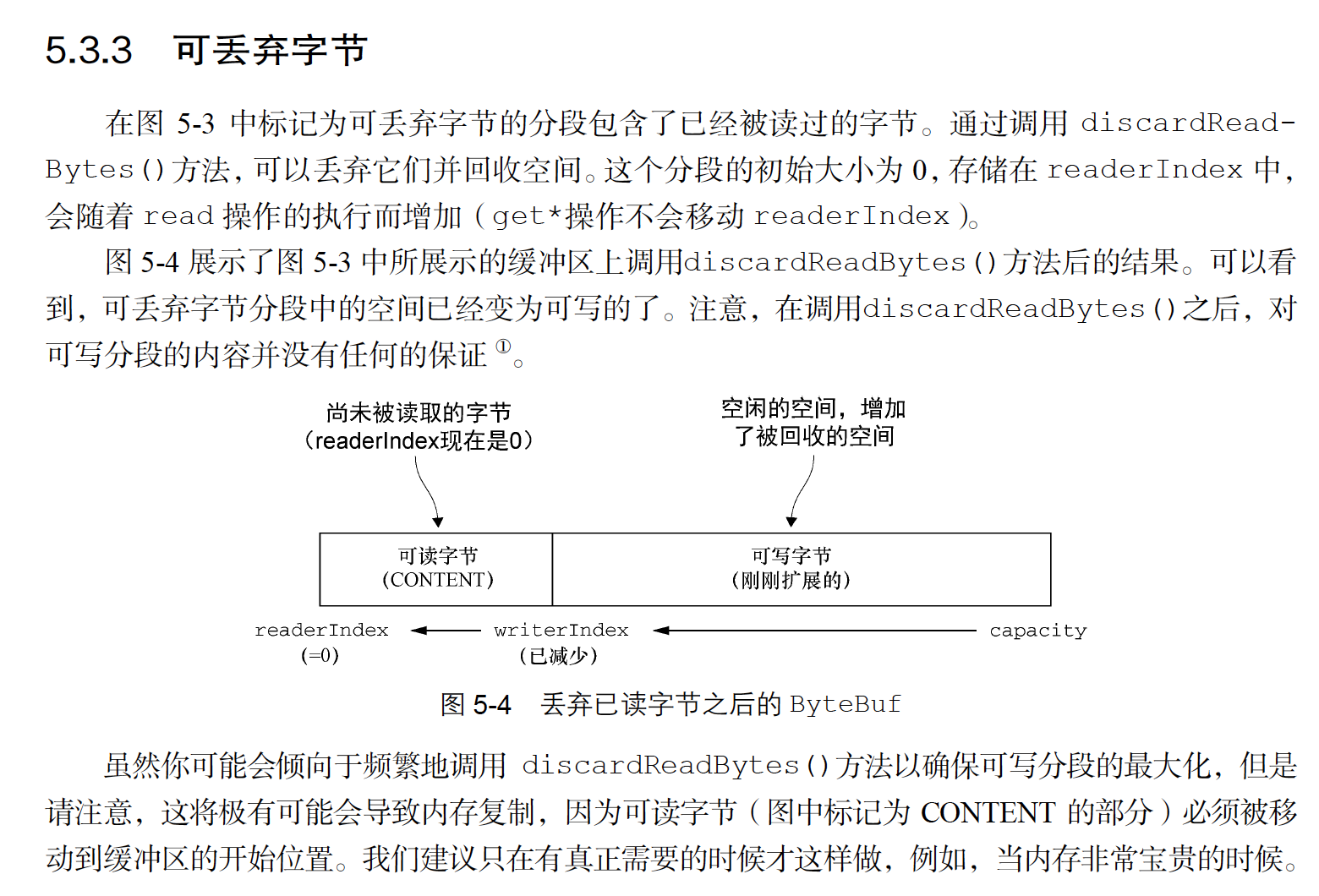
容量可以按需增长(类似于JDK 的StringBuilder);
在读和写这两种模式之间切换不需要调用ByteBuffer 的flip()方法;
读和写使用了不同的索引;
支持方法的链式调用;
支持引用计数;
支持池化。
其他类可用于管理ByteBuf 实例的分配,以及执行各种针对于数据容器本身和它所持有的
数据的操作。我们将在仔细研究ByteBuf 和ByteBufHolder 时探讨这些特性。
下面是一些ByteBuf API 的优点:
它可以被用户自定义的缓冲区类型扩展;
通过内置的复合缓冲区类型实现了透明的零拷贝;
容量可以按需增长(类似于JDK 的StringBuilder);
在读和写这两种模式之间切换不需要调用ByteBuffer 的flip()方法;
读和写使用了不同的索引;
支持方法的链式调用;
支持引用计数;
支持池化。
其他类可用于管理ByteBuf 实例的分配,以及执行各种针对于数据容器本身和它所持有的
数据的操作。我们将在仔细研究ByteBuf 和ByteBufHolder 时探讨这些特性。



5.3.8 派生缓冲区
每个这些方法都将返回一个新的ByteBuf 实例,它具有自己的读索引、写索引和标记
索引。其内部存储和JDK 的ByteBuffer 一样也是共享的。这使得派生缓冲区的创建成本
是很低廉的,但是这也意味着,如果你修改了它的内容,也同时修改了其对应的源实例,所
以要小心。
ByteBuf 复制 如果需要一个现有缓冲区的真实副本,请使用copy()或者copy(int, int)方
法。不同于派生缓冲区,由这个调用所返回的ByteBuf 拥有独立的数据副本。

5.3.9 读/写操作
正如我们所提到过的,有两种类别的读/写操作:
get()和set()操作,从给定的索引开始,并且保持索引不变;
read()和write()操作,从给定的索引开始,并且会根据已经访问过的字节数对索
引进行调整。
现在,让我们研究一下read()操作,其作用于当前的readerIndex 或writerIndex。
这些方法将用于从ByteBuf 中读取数据,如同它是一个流。表5-3 展示了最常用的方法



5.5.3 ByteBufUtil 类 ByteBufUtil 提供了用于操作ByteBuf 的静态的辅助方法。因为这个API 是通用的,并 且和池化无关,所以这些方法已然在分配类的外部实现。 这些静态方法中最有价值的可能就是hexdump()方法,它以十六进制的表示形式打印 ByteBuf 的内容。这在各种情况下都很有用,例如,出于调试的目的记录ByteBuf 的内容。十 六进制的表示通常会提供一个比字节值的直接表示形式更加有用的日志条目,此外,十六进制的 版本还可以很容易地转换回实际的字节表示。 另一个有用的方法是boolean equals(ByteBuf, ByteBuf),它被用来判断两个ByteBuf 实例的相等性。如果你实现自己的ByteBuf 子类,你可能会发现ByteBufUtil 的其他有用方法。
5.6 引用计数
引用计数是一种通过在某个对象所持有的资源不再被其他对象引用时释放该对象所持有的
资源来优化内存使用和性能的技术。Netty 在第4 版中为ByteBuf 和ByteBufHolder 引入了
引用计数技术,它们都实现了interface ReferenceCounted。


