python文件处理
1-引子
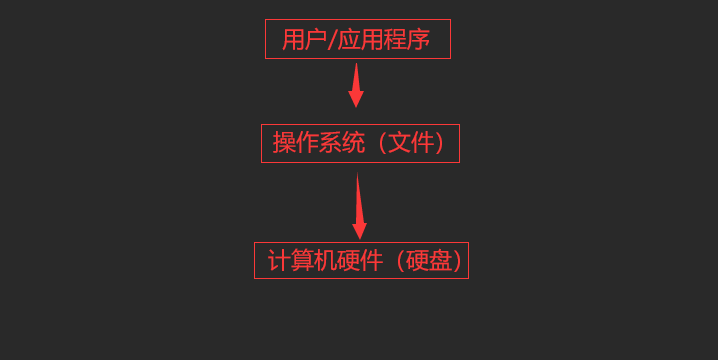
应用程序运行过程中产生的数据最先都是存放于内存中的,若想永久保存下来,必须要保存于硬盘中。应用程序若想操作硬件必须通过操作系统,而文件就是操作系统提供给应用程序来操作硬盘的虚拟概念,用户或应用程序对文件的操作,就是向操作系统发起调用,然后由操作系统完成对硬盘的具体操作
2-什么是文件?
文件就是操作系统提供给用户/应用程序操作硬盘的一种虚拟概念或接口
3-为何要用文件?
①用户/应用程序可以通过文件将数据永久保存在硬盘中即操作文件就是操作硬盘
②用户/应用程序直接操作的是文件,对文件进行的所有的操作,都是在向操作系统发送系统调用,然后再由操作系统将其转换成具体的硬盘操作
4-如何使用文件?open() 函数
大前提: tb模式均不能单独使用,必须与r/w/a之一结合使用
t(默认的):文本模式
1. 读写文件都是以字符串为单位的
2. 只能针对文本文件
3. 必须指定encoding参数
b:二进制模式:
1.读写文件都是以bytes/二进制为单位的
2. 可以针对所有文件
3. 一定不能指定encoding参数
5-文件操作的基本流程
# 假设磁盘中有 test.txt 文本文件 # 1. 打开文件,由应用程序向操作系统发起系统调用open(...),操作系统打开该文件,对应一块硬盘空间,并返回一个文件对象赋值给一个变量f f=open('test.txt','r',encoding='utf-8') #默认打开模式就为r # 2. 调用文件对象下的读/写方法,会被操作系统转换为读/写硬盘的操作 data=f.read() # 3. 向操作系统发起关闭文件的请求,回收系统资源 f.close()
1-路径分隔符,绝对路径与相对路径
# open('文件路径','文件处理模式','返回的数据采用何种编码')函数 有三个参数 """ 1-文件路径 绝对路径:E:\数据分析\练习\test.txt 相对路径:练习/test.txt 2-mode(文件处理模式) r w a 等 3-某种编码格式的字节类型 """ # test.txt 文件内容:a\nb\nc # Windows路径分隔符问题 f = open(r'E:\数据分析\练习\test.txt','r',encoding='utf-8') # 绝对路径写法 # f = open('E:\\数据分析\\练习\\test.txt','r',encoding='utf-8') # f = open('E:/数据分析/练习/test.txt','r',encoding='utf-8') """ open('test.txt','r',encoding='utf-8') #相对路径写法 相对路径也可以写成open('./test.txt') """ for i in f: print(i,end='') f.close() # 回收操作系统资源
6-with上下文管理
打开一个文件包含两部分资源:应用程序的变量f和操作系统打开的文件。在操作完毕一个文件时,必须把与该文件的这两部分资源全部回收,回收方法为
f.close() #回收操作系统打开的文件资源 el f #回收应用程序级的变量
其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件无法关闭,白白占用资源, 而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们,在操作完毕文件后,一定要记住f.close(),虽然我们如此强调,但是大多数还是会不由自主地忘记f.close(),考虑到这一点,python提供了with关键字来帮我们管理上下文
# 1、在执行完子代码块后,with 会自动执行f.close() with open('a.txt','w') as f: pass # 2、可用用with同时打开多个文件,用逗号分隔开即可 with open('a.txt','r') as read_f,open('b.txt','w') as write_f: data = read_f.read() write_f.write(data)
其他写法
# 文件对象又称文件句柄 # 一行写法 with open('test1.txt', mode='r') as f1,open('test2.txt', mode='r') as f2: # 两行写法 """ with open('test1.txt', mode='r') as f1,\ open('test2.txt', mode='r') as f2: """ res1,res2 = f1.read(),f2.read() print(res1) print(res2)
7-指定操作文本文件的字符编码
""" f = open(...)是由操作系统打开文件,如果打开的是文本文件,会涉及到字符编码问题,如果没有为open指定编码, 那么打开文本文件的默认编码很明显是操作系统说了算了,操作系统会用自己的默认编码去打开文件,在windows下是gbk, 在linux下是utf-8。若要保证不乱码,文件以什么方式存的,就要以什么方式打开。 """ f = open('a.txt','r',encoding='utf-8') # 内存:utf-8格式的二进制 -> 解码 -> Unicode # 硬盘a.txt的内容:utf-8的二进制
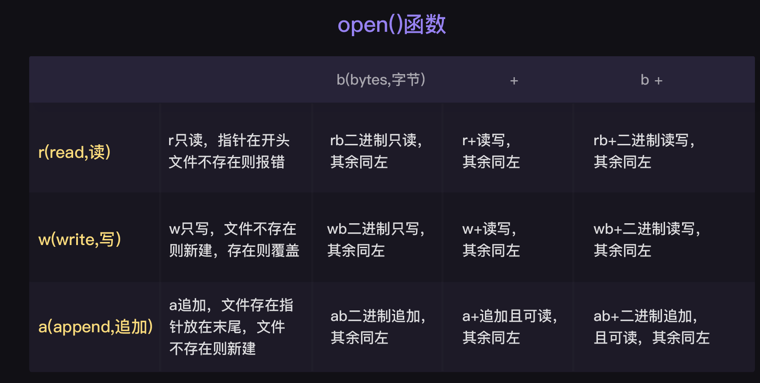
8-文件处理模式介绍
t 模式
①t 模式:如果我们指定的文件打开模式为r/w/a,其实默认就是rt/wt/at
②t 模式只能用于操作文本文件,无论读写,都应该以字符串为单位,而存取硬盘本质都是二进制的形式,当指定 t 模式时,内部帮我们做了编码与解码


# 文件处理模式介绍 # ① r (默认的文件处理模式) 只读模式,当文件不存在时报错,当文件存在时,文件指针跳到最开始位置 with open('test.txt',mode='rt',encoding='utf-8') as f: res = f.read() # 从文件开始位置,一次性从硬盘读入内存,赋值给res,当文件过大时会沾满内存,不推荐使用 print(res) # 推荐以循环的方式读取文件:for i in f:... # 登录小练习 # test2.txt 文件里存了 alex:123 is_flag = True with open('test2.txt',encoding='utf-8') as f: data = f.read().strip('\n') data = data.split(':') # 返回列表 user_name,pass_word = data while is_flag: userName = input("user_name:") pwd = input("pass_word:") if userName == user_name and pwd == pass_word: print("欢迎登录!") is_flag = False else: print("密码或用户名错误,请重新输入!") # ② w 只写模式:当文件不存在时会创建空文件,当文件存在时会清空文件,这时指针位于开始位置 with open('d.txt',mode='wt',encoding='utf-8') as f: # f.read() 不可读 f.write("hello world\n") # 说明1:在以w模式打开文件没有关闭的情况下,连续的写,新的内容总是跟在旧的内容之后 # 说明2:如果重新以w模式打开文件,则会清空文件内容 # 案例:文件的copy工具 with open("e.txt",mode="rt",encding="utf-8") as f1,\ open("f.txt",mode="wt",encoding="utf-8") as f2: res = f1.read() f2.write(res) # ③ a 只追加写,在文件不存在时会创建空文件,在文件存在时文件指针会直接跳到末尾 with open("a.txt",mode="a",encoding="utf-8") as f: # f.read() 报错 不能读 f.write("welcome to the world\n") # 追加在末尾 #强调 w 模式与 a 模式的异同: # 1 相同点:在打开的文件不关闭的情况下,连续的写入,新写的内容总会跟在前写的内容之后 # 2 不同点:以 a 模式重新打开文件,不会清空原文件内容,会将文件指针直接移动到文件末尾,新写的内容永远写在最后 # 案例:a模式用来在原有的文件内容的基础之上写入新的内容,比如记录日志、注册
b 模式
①读写都是以二进制位单位
with open('1.mp4',mode='rb') as f: data=f.read() print(type(data)) # 输出结果为:<class 'bytes'> with open('a.txt',mode='wb') as f: msg="你好" res=msg.encode('utf-8') # res为bytes类型 f.write(res) # 在b模式下写入文件的只能是bytes类型 #强调:b模式对比t模式 1、在操作纯文本文件方面t模式帮我们省去了编码与解码的环节,b模式则需要手动编码与解码,所以此时t模式更为方便 2、针对非文本文件(如图片、视频、音频等)只能使用b模式
9-操作文件的方法
# 读操作 f.read() # 读取所有内容,执行完该操作后,文件指针会移动到文件末尾 f.readline() # 读取一行内容,光标移动到第二行首部 f.readlines() # 读取每一行内容,存放于列表中 # 强调: # f.read()与f.readlines()都是将内容一次性读入内容,如果内容过大会导致内存溢出,若还想将内容全读入内存,则必须分多次读入,有两种实现方式: # 方式一 with open('a.txt',mode='rt',encoding='utf-8') as f: for line in f: print(line) # 同一时刻只读入一行内容到内存中 # 方式二 with open('1.mp4',mode='rb') as f: while True: data=f.read(1024) # 同一时刻只读入1024个Bytes到内存中 if len(data) == 0: break print(data) # 写操作 f.write('1111\n222\n') # 针对文本模式的写,需要自己写换行符 f.write('1111\n222\n'.encode('utf-8')) # 针对b模式的写,需要自己写换行符 f.writelines(['333\n','444\n']) # 文件模式 f.writelines([bytes('333\n',encoding='utf-8'),'444\n'.encode('utf-8')]) #b模式
学习没有捷径,需要日积月累的积淀及对技术的热爱。
