字符编码
了解更多猛戳这里
结论
1-ASCLL表
1-只支持英文字符串,与万国字符都有一一对应
2-采用8位二进制数(8bit=1bytes=1字节 )对应一个英文字符串
2-GBK
1-支持英文字符,支持中文字符
2-采用8位二进制数(8bit=1bytes=1字节)对应一个英文字符
3-采用16位二进制数(16bit=2bytes=2字节)对应一个中文字符
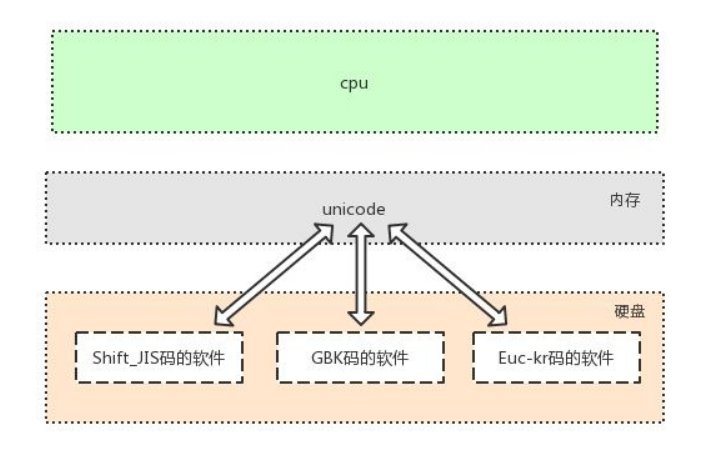
3-Unicode(内存中统一使用的字符表) 我们可以改变的是存入硬盘采用的格式
1-兼容万国字符
2-采用16位二进制数(16bit=2bytes=2字节)对应一个中文字符,个别生僻字采用4bytes或8bytes
3-老的字符都可以转化成Unicode,反之则不可以
4-utf-8
1-支持国际语言
2-是Unicode的升级,两者可以非常容易的互相转化,占用空间小,ascll表被utf-8包含
3-英文-->1bytes 中文-->3bytes
5-文本文件存取乱码问题
存乱了:编码格式应该设置成支持文件内字符串的格式
取乱了:文件以什么编码格式存入硬盘,就用什么编码格式读取文件
6-Python解释器默认读文件的编码
python2:ascll
python3:utf-8
指定文件头修改默认的编码,在py文件的首行写如:# coding:gbk
7-保证运行python程序前两个阶段不出现乱码的核心法则:
1-指定文件头
2- #coding:文件当初存入硬盘时所采用的编码格式
8-python解释器str类型详解
python3的str类型默认直接存成Unicode格式无论如何都不会乱码
python2中
x = u"hello" # 此行代码强制把 hello 以 Unicode的编码格式存入内存空间,所以不会出现乱码问题
