python变量与基本数据类型
1-变量与常量
1-变量:变量是用于在内存中存放程序数据的容器!计算机的最核心功能就是“计算”,CPU是负责计算的,计算需要数据源,数据源存在内存里,cpu调用数据时就可以通过变量和内存访问数据
2-定义变量(变量名=值)
# 定义变量 name = 'howie' age = 21 height = 169
3-调用变量
# 直接调用 变量名 就可以了 print(name) # 调用变量
4-变量的使用规则:必须先定义后调用
5-变量在内存中的本质
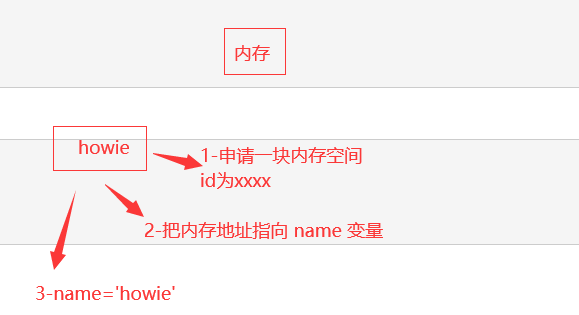
6-变量的三大特性
name = 'howie' #1、id 反应的是变量在内存中的唯一编号,内存地址不同id肯定不同 print(id(name)) # 查看变量内存地址 #2、type变 量值的类型 print(type(name)) # 查看变量类型 #3、value 变量值 print(name) # 调用变量
7-变量的命名规范
1. 变量名只能是 字母、数字或下划线的任意组合 2. 变量名的第一个字符不能是数字 3. 关键字不能声明为变量名,常用关键字如下 ['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from','global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']4.见名知意
8-变量命名风格
# 风格一:驼峰体 AgeOfTony = 56 NumberOfStudents = 80 # 风格二:纯小写下划线(在python中,变量名的命名推荐使用该风格) age_of_tony = 56 number_of_students = 80
9-常量:常量指在程序运行过程中不会改变的量,一种约定python中变量名全为大写的是常量
10-为什么要使用常量?答:在程序运行过程中,有些值是固定的、不应该被改变,比如圆周率 3.141592653...
11-python中使用常量:在Python中没有一个专门的语法定义常量,约定俗成是用全部大写的变量名表示常量。如:PI=3.14159。所以单从语法层面去讲,常量的使用与变量完全一致
2-程序交互-input
1-python3:input会将用户输入的所有内容都存成字符串类型
2-python2:raw_input与python3的input用法一样,而python2中的input要求用户必须输入明确的数据类型,输入什么类型,就存成什么类型
# python2 age = input('年龄:') print(type(age)) # <class 'int'>
name = input("Please enter your name:") # 执行这行代码时,会发现程序会等待你输入的姓名后,再继续往下执行 print("Welcome to the world of python %s"%name)
3-is 和 ==
is :判断 id 是否相等
== :判断值是否相等
a = 'welcome to the world of python' b = 'welcome to the world of python' print(a==b) # True print(id(a),id(b)) # 1932822117952 1932792517456 print(a is b) # False x = 123 y = 123 print(x==y) # True 值相等 print(x is y) # True id也相等,为什么呢?因为小整数池! # 小整数池介绍 """从python解释器启动的那一刻开始,就会在内存中事先申请好一系列内存空间存放好常用的整数""" print(id(x)) print(id(y)) sum = 100 + 23 print(id(sum)) # 以上输出都等于 140707989013136
5-Python内存管理之垃圾回收机制
1-垃圾:当一个变量值被绑定的变量名个数为0时,改变量值无法被访问到,称之为垃圾
2-垃圾回收机制分为三个步骤:
- 引用计数(直接引用和间接引用)
- 标记清除(针对引用计数出现的问题1:循环引用即容器对象之间相互引用也称交叉引用,造成内存泄漏,无法清除垃圾)
- 分代回收(针对引用计数出现的问题2:效率问题即每次回收内存,都需要把所有对象的引用计数都遍历一遍,这样消耗有点大)
3-引用计数:变量值被变量名关联的次数
3.1-引用计数增加:
x = 10 # 10的引用计数为1 y = x # 10的引用计数为2 z = x # 10的引用计数为3
3.2-引用计数减少:
del x # 解除变量名x与之10的绑定关系,10的引用计数变为2 del y # 解除变量名y与之10的绑定关系,10的引用计数变为1 z = 123 # 此时z重新赋值,解除了z与10的绑定关系,10的引用计数变为0,-->垃圾
注意:引用计数一旦变为0,其占用的内存地址就应该被解释器的垃圾回收机制回收
4-标记清除:当容器对象(比如:list,set,dict,class,instance)相互引用产生循环引用且没有栈区的变量名去引用它们时(此时无法访问到它们),标记清除算法就清除堆区里面“垃圾”。
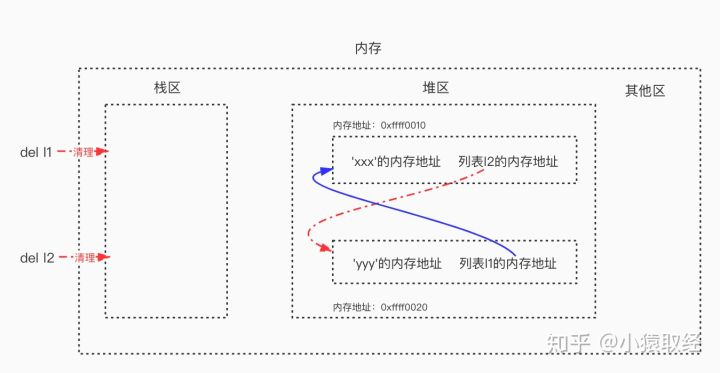
这样就解决了循环引用带来的内存泄漏问题
5-分代回收:
""" 分代回收的核心思想是:在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是常用变量,gc对其扫描的频率会降低 """ # 具体原理 # 分代指的是根据存活时间来为变量划分不同等级(也就是不同的代) """ 新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一,当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,青春代的gc扫描的频率低于新生代(扫描时间间隔更长),假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,接下来,青春代中的对象,也会以同样的方式被移动到老年代中。也就是等级(代)越高,被垃圾回收机制扫描的频率越低 """
6-基本数据类型
1-数字类型
1.1-整型int
作用:用来记录人的年龄,出生年份,学生人数等整数相关的状态
定义:
height = 170 age = 21 weight = 55 print(type(height),type(age),type(weight))
1.2-浮点型float
作用:用来记录人的身高,体重,薪资等小数相关的状态
定义:
heigh t= 170.1 weight = 110.5 salary = 1000.6 print(type(height),type(weight),type(salary)) # <class 'float'>
1.3-使用
# 1-数学运算 a,b = 0.1,2 print(a+b) # 2.1 # 2-比较大小 x,y = 0.1,0.2 print(x>y) # False
2-字符串str
1-作用:用来记录人的名字,家庭住址,性别等描述性质的状态
2-定义:
# 用引号('',"",''' ''',""" """),包含的一串字符 name = '字符串' ang = "18" content = " I don't love you !" poem = ''' 蝶恋花·槛菊愁烟兰泣露 作者:晏殊 宋代 赏析 槛菊愁烟兰泣露,罗幕轻寒,燕子双飞去。明月不谙离恨苦,斜光到晓穿朱户。 昨夜西风凋碧树,独上高楼,望尽天涯路。欲寄彩笺兼尺素,山长水阔知何处? ''' birth = "2020 \ 5.50" # 以上都是字符串
3-列表list
作用:记录多个值,并且可以按照索引取指定位置的值(索引从零开始)
定义:
# 在[]内用逗号分隔开多个任意类型的值,一个值为一个元素 lis = [1,0.5,'hello',[3,4]] print(lis[2]) # hello
4-字典dict
作用:字典类型是用key(可哈希):value形式来存储数据(通常为字符串),其中key可以对value有描述性的功能
定义:
# 在{}内用逗号分隔开多个key:value,一个组键值对称之为一个元素 user_info = {'name':'howie','age':22,'salary':11202,} print(user_info['name']) # howie # 字典可以嵌套,嵌套取值如下 students = [ {'name':'tony','age':38,'hobbies':['play','sleep']}, {'name':'jack','age':18,'hobbies':['read','sleep']}, {'name':'rose','age':58,'hobbies':['music','read','sleep']}, ] print(students[0]['hobbies'][0]) # play
5-布尔类型
作用:用来记录真假这两种状态,通常用来当作判断的条件
True --> 真
False -->假
# 可用bool()函数查看 print(bool(1)) # True print(bool(0)) # False bool('任意类型')
python布尔值分类
# 1-显示布尔值 # 条件可以是 比较运算符 如 print(1>2) # False 条件判断之后会的得到一个布尔值 # 也可以是 True,False while True: # 业务逻辑 pass # 2-隐式布尔值 # 所有值否都可以当成条件去用 # 其中 0 None 空(空字符串,空列表,空字典)代表的布尔值都是False # 其余的都是True
7-基本数据类型分类
# 基本数据类型分类 # 1-可变类型:值改变,id不变,证明改的是原值,证明原值是可以改变的,如list dict # 2-不可变类型:值改变,id也改变了,证明是产生新的值,压根没改变原值 如int float str bool # 整型int --> 不可变类型 a = 10 print(id(a)) # 140723145913456 a = 11 # 重新开辟内存空间,并且把内存地址指向a,即值改变,id也改变了 print(id(a)) # 140723145913488 # 浮点型float --> 不可变类型 x = 1.5 print(id(x)) # 2037827678952 x = 2.5 # 同理,重新开辟内存空间 print(id(x)) # 2037827678568 # 字符串 --> 不可变类型 s = "123" print(id(s)) # 2037859859680 s = "456" # 同理,重新开辟内存空间 print(id(s)) # 2037859859736 # 小结:在python中int float str 设计成了不可分割的整体,不能够被改变 # 列表list --> 可变类型 l = [1,2,3] print(id(l)) # 2037827986056 l[0] = 5 # 改变列表第一个值 print(l) # [5,2,3] print(id(l)) # 2037827986056 # 字典dict --> 可变类型 d = {'a':1,'b':2} print(id(d)) # 2037827945672 d['a'] = 1000 print(d) # {'a':1000,'b':2} print(id(d)) # 2037827945672
8-格式化输出
1-占位符%
name = input("Please enter your name:") msg = "Hello %s ! welcome to the world of Python"%name # 这里%s就是一个占位符 print(msg) # Hello howie ! welcome to the world of Python
%s是在字符串里的占位符和字符串外%号后面括号里的数据是一一对应的
占位符有三种:
- %s 是代表字符串占位符
- %d 是数字占位符
- %f 是浮点数占位符
# 注意%s也可以接受其他值,不只是字符串 message = "my name is %s , my age is %s" %('howie','21') # 字符串占位符普通用法 # my name is howie ,my age is 21 message = "my name is %(name)s ,my age is %(age)s" %{'age':'22','name':'howie'} # 以字典的形式传值,打破位置的限制 # my name is howie ,my age is 22 message = "my age is %d" %22 # %d 只可以接受整型int message = "my weight is %f" % 111.5 # %d 只可以接受浮点型float
# 补充 # 1-输出%号 # 打印今年收入增加了25% income = "今年收入增加了%s%%" %25 # 两个%才能输出 print(income) # 2-f的用法 name = 'howie' age = 22 msg = f'my name is {name} my age is {age}' print(msg) # my name is howie my age is 22 # 还可以计算表达式如 res1 = f"1+2" print(res) # 1+2 res2 = f"{1+2}" print(res2) # 3
2-格式化函数format
1-Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能,并且兼容性好。
2-基本语法是通过 {} 和 : 来代替以前的 % 。
3-format 函数可以接受不限个参数,位置可以不按顺序
message = "{} {}".format("hello", "world") # 不设置指定位置,按默认顺序 print(message) # hello world message = "{0} {1}".format("hello", "world") # 设置指定位置 print(message) # hello world message = "{1} {0} {1}".format("hello", "world") # 设置指定位置 print(message) # world hello world # 按照key=value传值,打破位置限制 message = "my name is {name},my age is {age}".format(age=22,name='howie') print(message) # my name is howie,my age is 22
# 补充-填充 与 对齐方式 # 1-左对齐 填充10个元素 不够的用'='填充 print("hello{:=<10}".format('A')) # helloA======= # 2-右对齐 填充4个元素 不够的用'+'填充 print("hello{:+>4}".format("A")) # hello+++A # 3-居中 填充5个元素 不够的用'+'填充 print("hello{:+^5}".format('A')) # hello++A++ # 注意看 A 的位置 # 4-精确小数(保留3位小数为例) salary = "{:0.3f}".format(22222.4545) print(salary) # 22222.454 # 5-千位分隔符 salary = "{:,}".format(11212121) print(salary) # 11,212,121
