Redis之NoSql概述
Nosql概述
为什么要用Nosql
1.单机MySQL的年代!
90年代,一个基本的网站访问量一般不会太大,单个数据库完全足够!
那个时候,更多的去使用静态网页Html,服务器根本没有太大的压力!
思考一下这种情况下: 整个网站的瓶颈是什么?
1.数据量如果太大,一个机器放不下了!
2.数据超过300万条就需要建立数据的索引(mysql用的B+ Tree)来优化查询,一个机器内存也放不下很大的索引
3.访问量(读写混合),一个服务器承受不了!
只要出现以上三种情况之一,那么就必须要晋级!
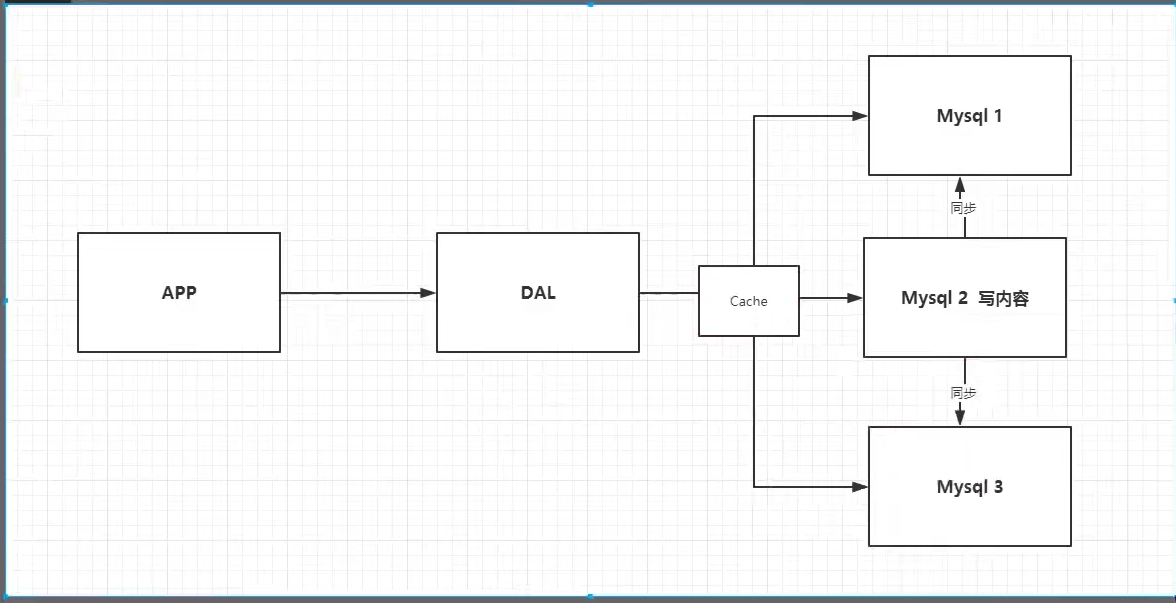
2.Memcached(缓存) + Mysql + 垂直拆分(读写分离)
这个我个人理解是解决访问并发量过高的情况
比如下面图中的2号mysql负责写数据,并同步到1号和3号mysql,1号和3号负责读数据,
虽然这样做了,但是网站80%的情况都是在读,每次都要去查询数据库的话就十分的麻烦:比如张三先去查1号商品,李四后来又去查1号商品,同一个sql执行了两次,这样并不高效,我们何不中间做一个缓存层,只要查询的商品不变,第二次就直接从缓存里面取。所以说我们希望减轻数据库的压力,我们可以使用缓存来保证效率!
发展过程:首先肯定想优化MySQL数据结构和索引--> 然后 文件缓存(IO) --> Memcached(当时最热门的技术!)
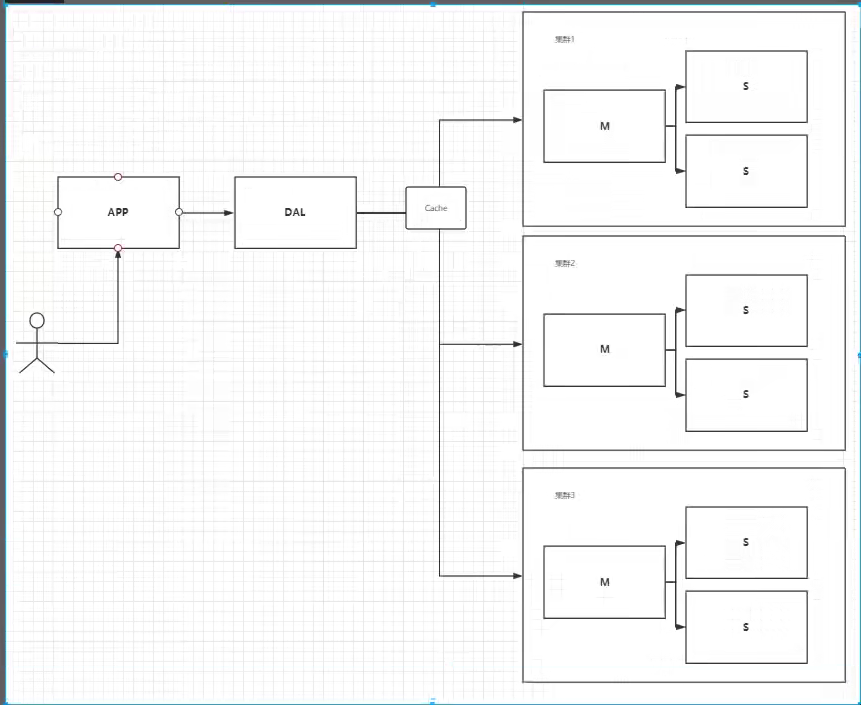
3.分库分表 + 水平拆分 + MySQL集群
这个我个人理解是解决数据量太大并附带解决访问并发量的问题
就如下图:由于数据量太大我们需要分库分表,做了3个MySQL集群,每个集群里边是主从复制(master-slave),读写分离的结构.
由于分库分表每个集群商品信息表最大量都是整的3分之一,3个集群就分摊了数据量
现在比如我们想查一个商品的信息,先去cache查,没有再去3个集群中查并汇总可得到商品信息!
本质:数据库 (读,写)
早些年MyISAM: 表锁(比如说一张表有100万条数据,我去查张三的密码信息,他会把整个表锁了,其他进程就只能阻塞,就十分影响效率),高并发下就会出现严重的锁问题!
转战Innodb: 行锁,每次查数据只锁这一行而,已这是解决读的压力!
后面慢慢的就开始使用分库分表来解决写的压力! Mysql在那个年代推出了表分区! 这个并没有多少公司使用!
MySQL也推出了MySQL的集群,有了集群之后很好的满足了那个年代的所有需求!
4.如今最近的年代
2010--2020十年之间,世界已经发生了翻天覆地的变化;
MySQL等关系型数据库就不够用了,因为数据量很大,而且变化很快(比如说定位,还有音乐热榜,排行榜等)!
比如说: 浏览量(一下子到10w+)做法肯定不会是直接来一个用户mysql就存一次吧,肯定是先把浏览量放到缓存里面,然后固定的时间(一个小时两个小时)再把它持久化一下,来保证效率跟安全!
还有比如MySQL来存储一些比较大的文件,比如博客,图片等, 会导致数据库表很大,那效率就会很低了!如果有一种数据库专门来处理这种数据,那MySQL的压力就会变得小很多了。
那我们如何来处理这些问题呢?
目前一个基本的互联网项目如下图:
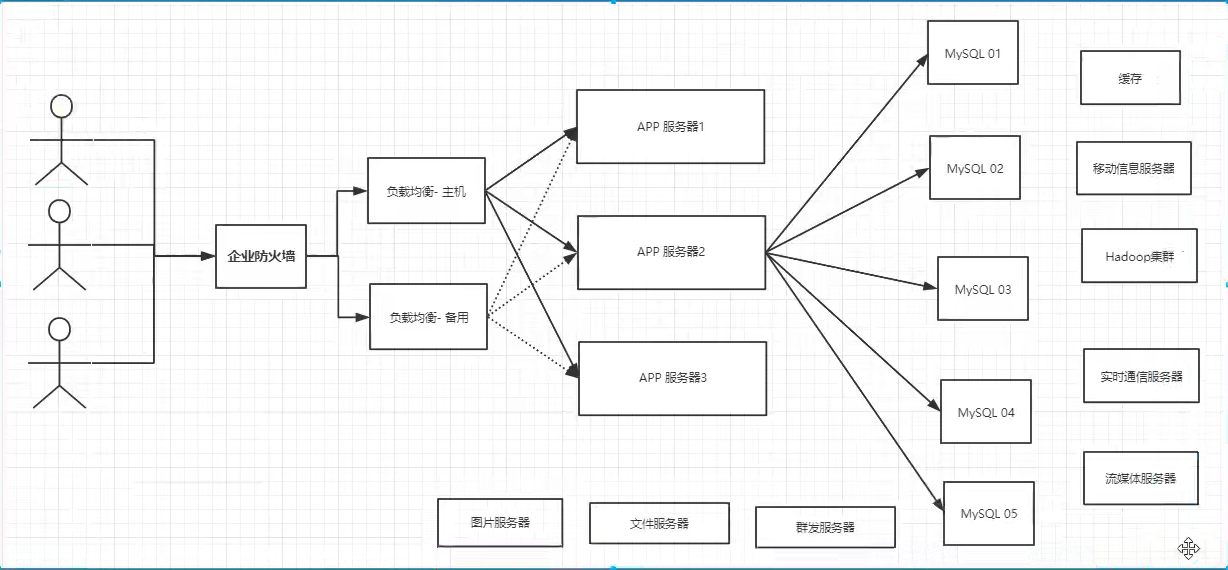
为什么要用NoSQL?
用户的个人信息,社交网络,地理位置,用户自己产生的数据,用户的日志等等爆发式增长,这些我们就没有办法使用关系型数据库去做
这时候我们就需要使用NoSQL数据库了,nosql数据库可以很好的处理以上情况!
什么是NoSQL
NoSQL
NoSQL = Not Only SQL (不仅仅是SQL)
关系型数据库:表格,行,列
泛指非关系型数据库,随着web2.0互联网的诞生,传统的关系型数据库很难对付web2.0时代! 尤其是超大规模的高并发的社区!
使用关系型数据库就暴露出来很多难以克服的问题,Nosql在当今大数据环境下发展的十分迅速,Redis是发展最快的,而且是我们当下必须要掌握的一个技术!
很多的数据类型比如用户的个人信息,社交网络,地理位置。这些数据类的存储不需要一个固定的格式(就像关系型数据库的行跟列),不需要多余的操作就可以横向扩展的! Map<String,Object> 使用键值对来控制!
NoSQL特点
1.方便扩展(数据之间没有关系,很好扩展!)
2.大数据量高性能(Redis一秒可以写8万次,可以读11万次),而且NOSQL的缓存是记录级别的,是一种细粒度的缓存,性能会比较高!
3.数据类型是多样型的! (不需要事先设计数据库!随取随用!使用MySQL等关系型数据库如果是数据量十分大的表,很多人就无法设计的很好了!)
4.传统的RDBMS和NoSQL的区别如下:
传统的RDBMS
- 结构化组织
- SQL
- 数据和关系都存在单独的表中 row和col
- 数据操作语言,数据定义语言
- 严格的一致性
- 基础的事务
- ......
NoSQL
- 不仅仅是数据
- 没有固定的查询语言
- 键值对存储,列存储,文档存储,图形数据库(做社交关系那种系统)
- 最终一致性
- CAP定理 和 BASE理论(异地多活!)
- 保证 高性能,高可用,高可扩
- .......
了解:3V+3高
大数据时代的3V: 主要是来描述问题的
1.海量Volume
2.多样Variety
3.实时Velocity
大数据时代的3高: 主要是来对程序的要求
1.高并发
2.高可扩(随时水平拆分,比如说:机器不够了可以扩展机器来解决这是最简单的一种方式)
3.高性能(保证用户体验和性能!)
真正在公司中的实践:Nosql + RDBMS 一起使用才是最强的,
我们下面来看下阿里巴巴的架构演进!
阿里巴巴演进分析
思考一个问题:阿里巴巴网站上这么多的东西难道都是在一个数据库中的吗?
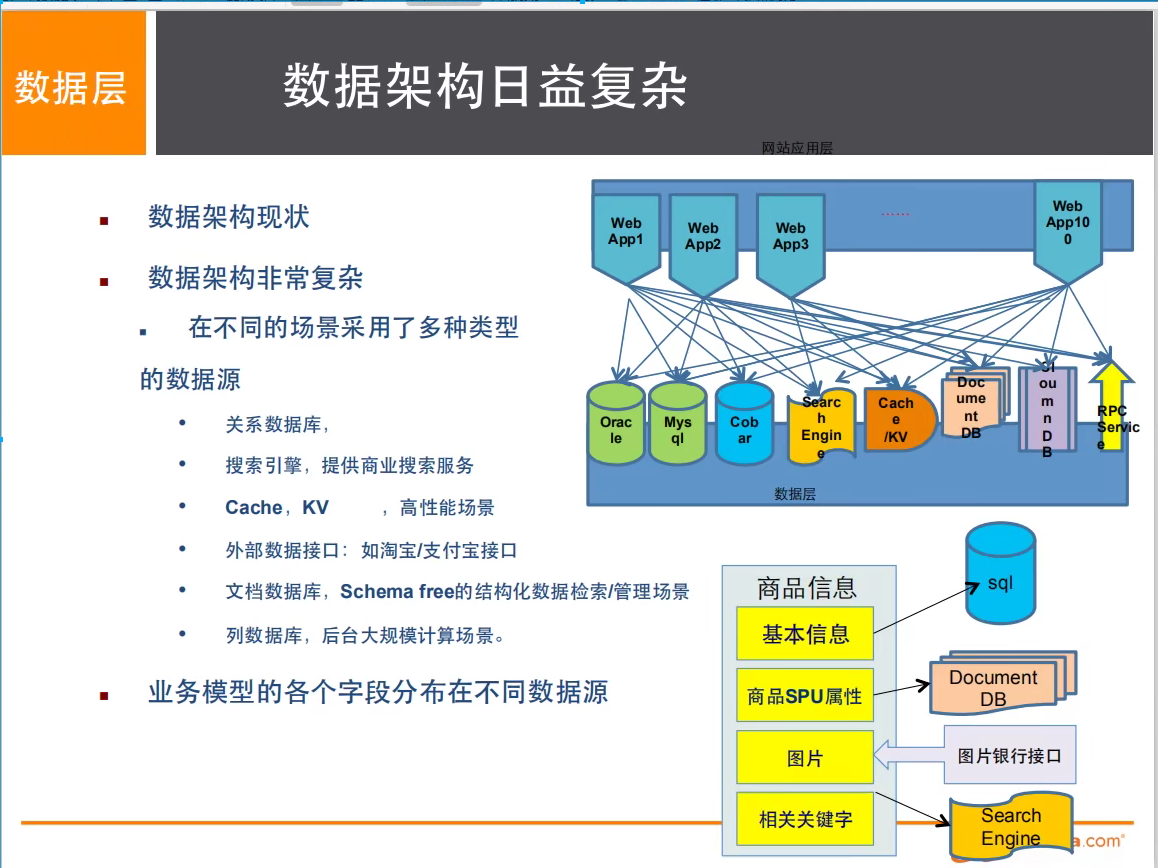
如果你未来想当一个架构师: 没有什么是加一层解决不了的!
# 1.商品的基本信息
名称、价格、商家信息;
关系型数据库就可以解决了! MySQL/oracle (淘宝早年就去IOE了!,王坚:推荐文章:阿里云的这群疯子)
淘宝内部的MySQL 不是大家用的MySQL
# 2.商品的描述信息、评论(文字比较多)
放在文档型数据库中,MongoDB
# 3.图片
放在分布式文件系统中,FastDFS
分布式文件系统很多:
- 淘宝自己的 TFS
- Google的 GFS
- Hadoop的 HDFS
- 阿里云的 oss云存储
# 4.商品的关键字(搜索)
- 搜索引擎 solr elasticsearch
- 淘宝用的是 ISearch: 阿里的多隆开发的
# 5.商品热门的波段信息(比如:秒杀等)
- 内存数据库 Redis Tair Memacached...
# 6.商品的交易,外部的支付接口
- 三方应用(支付宝接口)或者说银行的接口
要知道,一个简单的网页,背后的技术一定不是大家所想的那么简单!
大型互联网应用问题:
- 数据类型太多了
- 数据源繁多,经常重构!
- 数据要改造,大面积改造
解决问题:

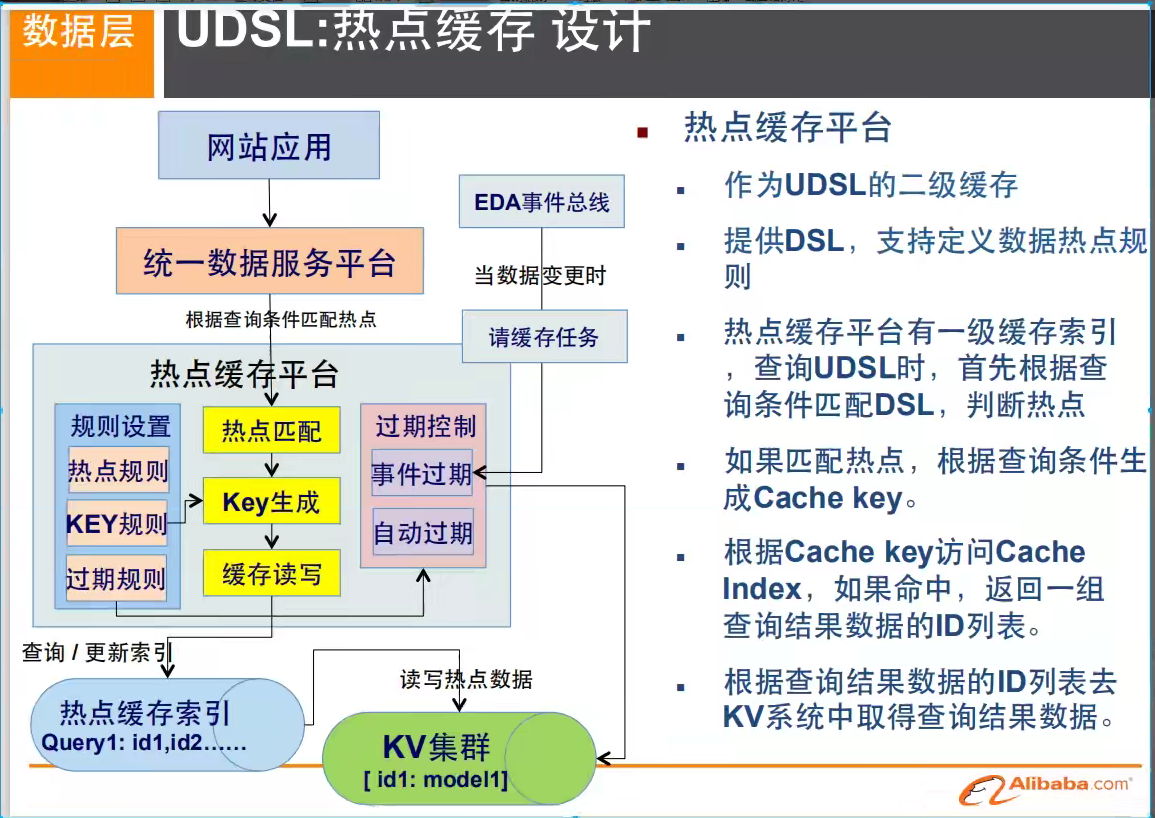
这里以上都是Nosql入门概述,不仅能够提高大家的知识,还可以帮助大家了解大厂的工作内容!
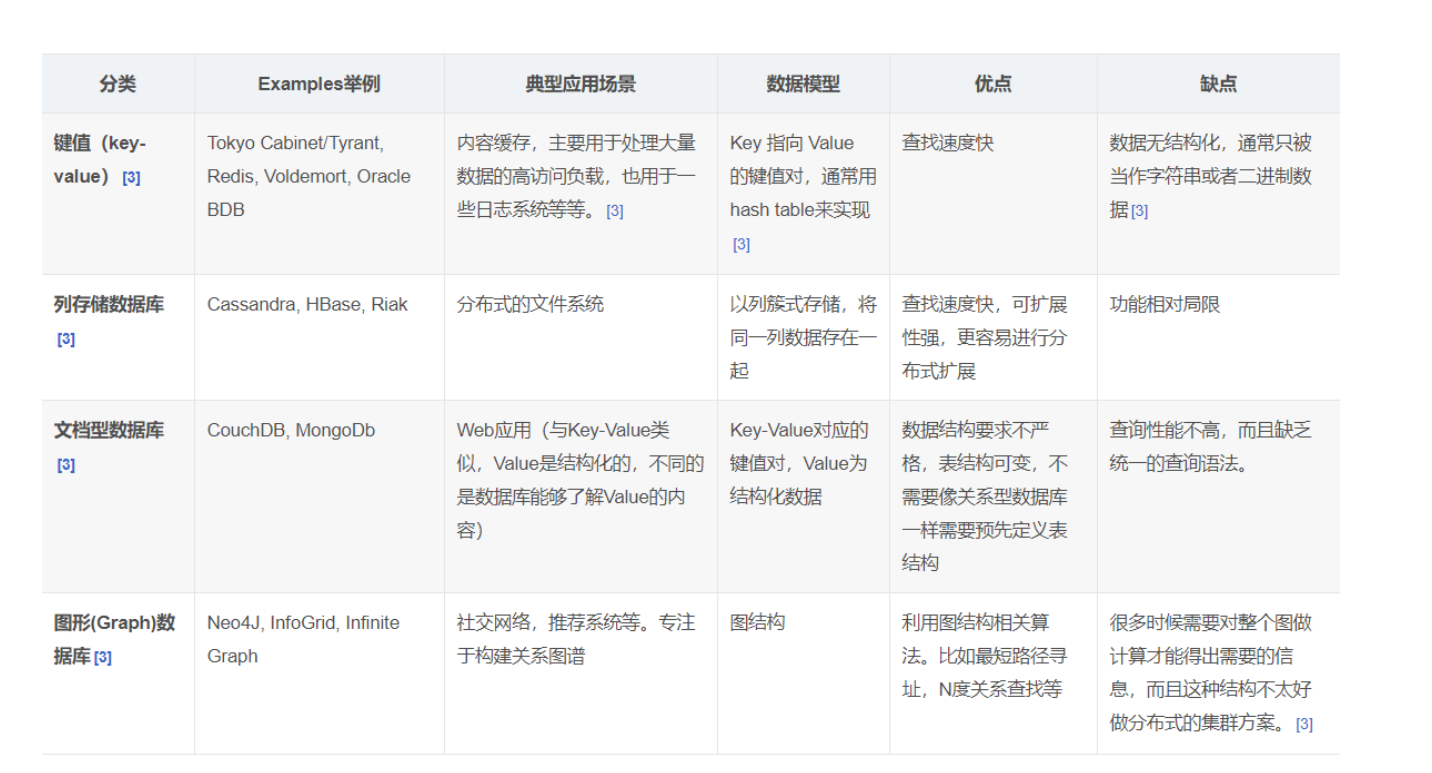
NoSql的四大分类
KV键值对:
- 新浪: Redis
- 美团:Redis + Tair
- 阿里、百度: Redis + Memacache
文档型数据库(用的BSON格式,它和json一样):
- MongoDB (一般必须要掌握)
- MongoDB是一个基于分布式文件存储的数据库,它是由C++编写的,主要用来处理大量的文档!
- MongoDB是一个介于关系型数据库和非关系型数据库中中间的产品! MongoDB是非关系型数据库中功能最丰富,最像关系型数据库的!
- ConthDB
列存储数据库
- HBase
- 分布式文件系统
图关系数据库
- 他不是存图形的,放的是关系,比如: 朋友圈社交网络,广告推荐!
- 代表的有:Neo4j, infoGrid;
四者对比!