笔记-Microsoft SQL Server 2008技术内幕:T-SQL语言基础-02 单表查询
SELECT子句中的别名
SELECT子句是在FROM、WHERE、GROUP BY,以及HAVING子句后处理的,这意味着对于SELECT子句之前处理的那些子句,在SELECT子句中为表达式分配的别名并不存在。例如:
SELECT orderid, YEAR(orderdate) AS orderyear FROM Sales.Orders WHERE orderyear > 2006;
这是错误的,WHERE子句中并不能识别orderyear别名,应该改为:
SELECT orderid, YEAR(orderdate) AS orderyear FROM Sales.Orders WHERE YEAR(orderdate) > 2006;
关于WITH TIES选项
先看下面这段代码:
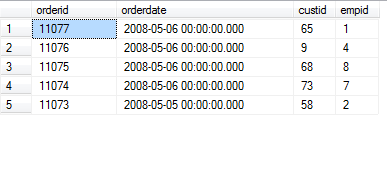
SELECT TOP (5) orderid, orderdate, custid, empid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC;
执行查询结果如图:
加上WITH TIES选项后:
SELECT TOP (5) WITH TIES orderid, orderdate, custid, empid FROM Sales.Orders ORDER BY orderdate DESC;
再看执行结果:
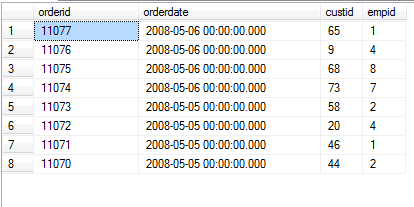
也就是说WITH TIES选项能够返回与TOP n 行中最后一行(在这个例子中式2008年5月5日)的排序值(在这个例子中是orderdate)相同的其他所有行。
OVER子句
先看下面这段代码:
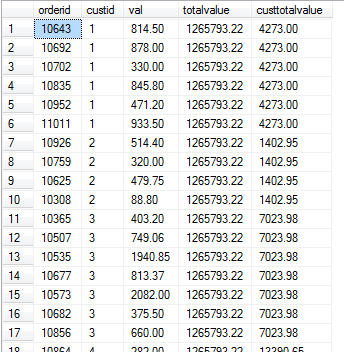
SELECT orderid, custid, val, SUM(val) OVER() AS totalvalue, SUM(val) OVER(PARTITION BY custid) AS custtotalvalue FROM Sales.OrderValues;
执行结果:
再看下面的代码:
SELECT SUM(val) AS totalvalue FROM Sales.OrderValues;
执行结果:
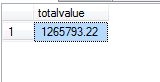
对比可知,使用OVER就不必对数据进行分组,还能够在同一行中同时返回基础行的列和聚合列。
再看一段代码:
SELECT orderid, custid, val, 100. * val / SUM(val) OVER() AS pctall, 100. * val / SUM(val) OVER(PARTITION BY custid) AS pctcust FROM Sales.OrderValues;
执行结果:

注意上面这段代码中的一个小细节,就是100后面加个点,而不是直接使用整数100,因为这样可以隐式将整数值val和SUM(val)转换成十进制实数值,否则表达式中的除法将是“整数除法”,会截去数值的小数部分。
OVER子句也支持四种排名函数:ROW_NUMBER(行号)、RANK(排名)、DENSE_RANK(密集排名)、NTILE,看下面的代码:
SELECT orderid, custid, val, ROW_NUMBER() OVER(ORDER BY val) AS rownum, RANK() OVER(ORDER BY val) AS rank, DENSE_RANK() OVER(ORDER BY val) AS dense_rank, NTILE(10) OVER(ORDER BY val) AS ntile FROM Sales.OrderValues ORDER BY val;
执行结果:
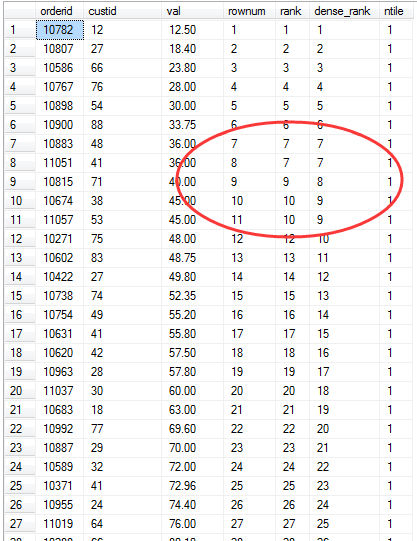
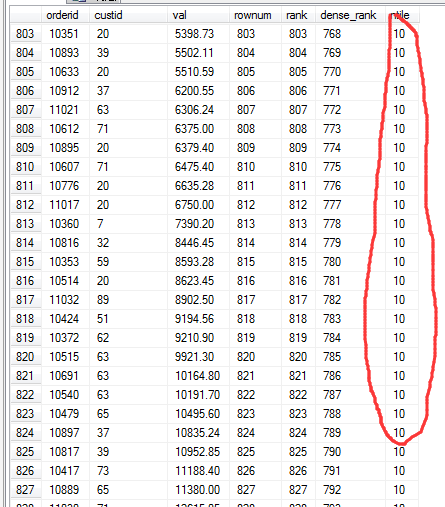
简单解释一下上面的各个函数。
ROW_NUMBER用于为查询的结果集中的各行分配递增的序列号,其逻辑顺序通过OVER子句中的ORDER BY语句进行指定。ROW_NUMBER生成的是唯一的行号值。RANK和DENSE_RANK的区别是:RANK表示之前有多少行具有更低的排序值,而DENSE_RANK则表示之前有多少个更低的排序值。NTILE函数可以把结果中的行关联到组,并为每一行分配一个所属的组的编号。NTILE函数接受一个表示组数量的输入参数,并要在OVER子句中指定逻辑顺序。上面代码例子中是分为10组。
在OVER子句中使用PARTITION BY语句:
SELECT orderid, custid, val, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY val) AS rownum FROM Sales.OrderValues ORDER BY custid, val;
执行结果:
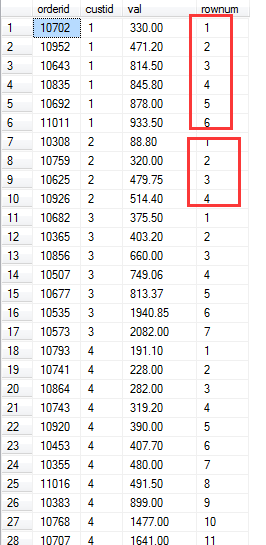
从结果中可以看出,行号是为每一个客户独立计算的。
注意一点,如果在SELECT处理阶段指定了开窗函数,开窗计算会在DISTINCT子句(如果有)之前进行处理。
谓词和运算符
常见的谓词有:IN、BETWEEN、LIKE等。
CASE表达式
先看一个简单的:
SELECT productid, productname, categoryid, CASE categoryid WHEN 1 THEN 'Beverages' WHEN 2 THEN 'Condiments' WHEN 3 THEN 'Confections' WHEN 4 THEN 'Dairy Products' WHEN 5 THEN 'Grains/Cereals' WHEN 6 THEN 'Meat/Poultry' WHEN 7 THEN 'Produce' WHEN 8 THEN 'Seafood' ELSE 'Unknown Category' END AS categoryname FROM Production.Products;
执行结果:

如果CASE表达式中没有ELSE子句,则默认将其视为ELSE NULL。
看一个复杂一点的:
SELECT orderid, custid, val, CASE NTILE(3) OVER(ORDER BY val) WHEN 1 THEN 'Low' WHEN 2 THEN 'Medium' WHEN 3 THEN 'High' ELSE 'Unknown' END AS titledesc FROM Sales.OrderValues ORDER BY val;
执行结果:
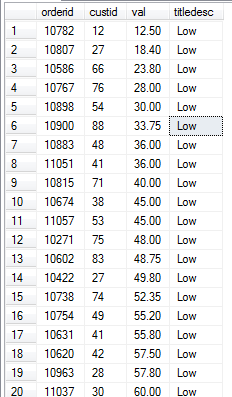
CASE搜索表达式:
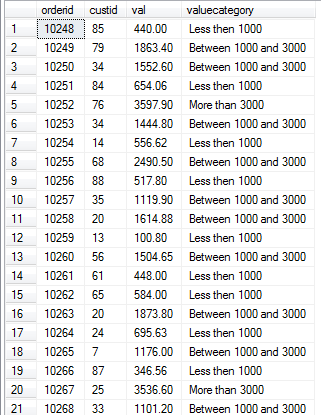
SELECT orderid, custid, val, CASE WHEN val < 1000.00 THEN 'Less then 1000' WHEN val BETWEEN 1000.00 AND 3000.00 THEN 'Between 1000 and 3000' WHEN val > 3000.00 THEN 'More than 3000' ELSE 'Unknown' END AS valuecategory FROM Sales.OrderValues;
执行结果:
排序规则
如果想在列的排序规则是不区分大小写的前提下,让过滤条件是区分大小写的,则可以按如下方法修改表达式的排序规则:
SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname COLLATE Latin1_General_CS_AS = N'davis';
日期和时间
先看下面代码:
SELECT GETDATE() SELECT CURRENT_TIMESTAMP
上面两句代码返回的日期是一样的,但是CURRENT_TIMESTAMP是标准SQL,所以优先推荐使用CURRENT_TIMESTAMP。
