爬虫案例1-爬取图片的三种方式之一:selenium篇(2)
 继使用requests库爬取图片后,本文使用python第三方库selenium来进行图片的爬取,后续也会使用同样是自动化测试工具DrissionPage篇来进行图片的爬取。
selenium是一个用于web应用测试的工具集,它可以直接运行在浏览器中,就像真正的用户在操作一样。它主要应用在自动化测试,web爬虫和自动化任务中。selenium提供了很多编程语言的接口,如java,python,c#等。这让开发者可以自己编写脚本来自动化web应用的测试。本文主要介绍selenium在web爬爬取图片的案例。
继使用requests库爬取图片后,本文使用python第三方库selenium来进行图片的爬取,后续也会使用同样是自动化测试工具DrissionPage篇来进行图片的爬取。
selenium是一个用于web应用测试的工具集,它可以直接运行在浏览器中,就像真正的用户在操作一样。它主要应用在自动化测试,web爬虫和自动化任务中。selenium提供了很多编程语言的接口,如java,python,c#等。这让开发者可以自己编写脚本来自动化web应用的测试。本文主要介绍selenium在web爬爬取图片的案例。
@
前言
继使用requests库爬取图片后,本文使用python第三方库selenium来进行图片的爬取,后续也会使用同样是自动化测试工具DrissionPage篇来进行图片的爬取。
导航
- 爬虫案例1-爬取图片的三种方式之一:requests篇(1)
- 爬虫案例1-爬取图片的三种方式之一:selenium篇(2)
- 爬虫案例1-爬取图片的三种方式之一:DrissionPage篇(3)
- 爬虫案例2-爬取视频的三种方式之一:requests篇(1)
- 爬虫案例2-爬取视频的三种方式之一:selenium篇(2)
- 爬虫案例2-爬取视频的三种方式之一:DrissionPage篇(3)
selenium简介
selenium是一个用于web应用测试的工具集,它可以直接运行在浏览器中,就像真正的用户在操作一样。它主要应用在自动化测试,web爬虫和自动化任务中。selenium提供了很多编程语言的接口,如java,python,c#等。这让开发者可以自己编写脚本来自动化web应用的测试。本文主要介绍selenium在web爬爬取图片的案例。
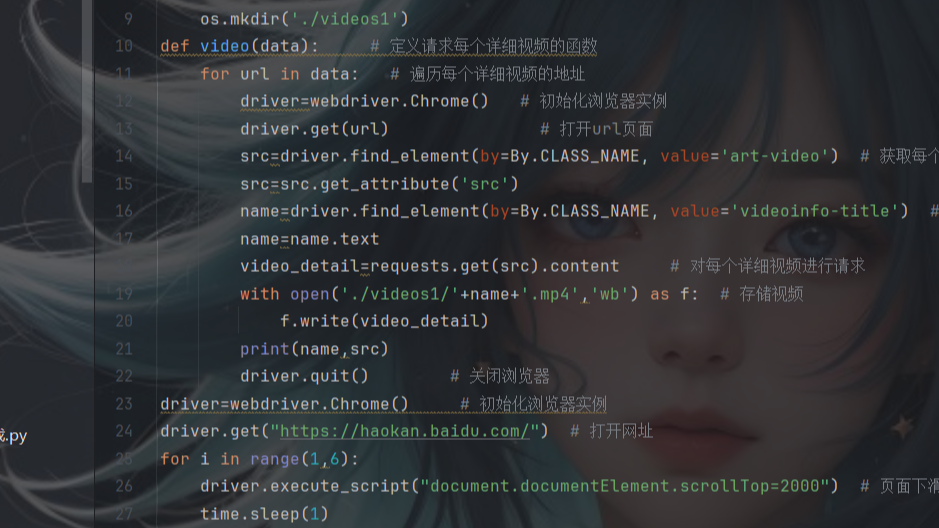
实战
- 话不多说,直接上源码
import requests # 数据请求模块
from selenium import webdriver # 浏览器驱动
from selenium.webdriver.common.by import By # 用来定位web页面上的元素
from time import sleep # 时间函数
import os # 文件管理模块
if not os.path.exists('./images'):
os.mkdir('./images')
driver = webdriver.Chrome() # 初始化webdriver实例
driver.get('https://pic.netbian.com/e/search/result/?searchid=147') # 打开网页
for num in range(0,14): # 多页爬取
data_img=driver.find_elements(by=By.XPATH, value='//div[@class="slist"]/ul/li/a/img') # 使用xpath定位到图片资源
for img in data_img: # 遍历
img_url=img.get_attribute('src') # 图片地址
response=requests.get(img_url) # 对图片地址进行请求
img_data=response.content # 获取到图片的二进制数据
with open('./images/'+img_url.split('/')[-1], 'wb') as f: # 持久化存储
f.write(img_data)
print("下载成功;",img_url.split('/')[-1])
print(f"第{num}页下载完成")
sleep(2) # 等待两秒
driver.find_element(by=By.XPATH, value='//*[@id="main"]/div[3]/a[11]').click() # 点击下一页
共勉
- 忙碌是治愈焦虑的良药
ps
- 有时候会报错可能会有以下几个原因
- 因为页面采用的懒加载技术,所以定位的时候要让元素在页面中显示出来才行,可以自己采用鼠标滚动事件
- 可以采用时间模块让页面中的元素全部加载后再去定位元素
博客
- 本人是一个渗透爱好者,不时会在微信公众号(laity的渗透测试之路)更新一些实战渗透的实战案例,感兴趣的同学可以关注一下,大家一起进步。
- 之前在公众号发布了一个kali破解WiFi的文章,感兴趣的同学可以去看一下,在b站(up主:laity1717)也发布了相应的教学视频。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号