爬虫案例1-爬取图片的三种方式之一:requests篇(1)
 本文分享一个爬虫案例,使用requests库爬取彼岸网中的动物的图片,利用parsel库进行数据解析,并把这些照片保存到本地。后续也会接着分享使用第三方库selenium篇和DrissionPage篇爬取图片。
本文分享一个爬虫案例,使用requests库爬取彼岸网中的动物的图片,利用parsel库进行数据解析,并把这些照片保存到本地。后续也会接着分享使用第三方库selenium篇和DrissionPage篇爬取图片。
@
前言
本文分享一个爬虫案例,使用requests库爬取彼岸网中的动物的图片,利用parsel库进行数据解析,并把这些照片保存到本地。后续也会接着分享使用第三方库selenium篇和DrissionPage篇爬取图片。
导航
- 爬虫案例1-爬取图片的三种方式之一:requests篇(1)
- 爬虫案例1-爬取图片的三种方式之一:selenium篇(2)
- 爬虫案例1-爬取图片的三种方式之一:DrissionPage篇(3)
- 爬虫案例2-爬取视频的三种方式之一:requests篇(1)
- 爬虫案例2-爬取视频的三种方式之一:selenium篇(2)
- 爬虫案例2-爬取视频的三种方式之一:DrissionPage篇(3)
爬虫步骤
发起请求
确定要爬取的目标网站后要先发起请求,我们要发送请求需要依赖requests库,爬虫实质上是模拟浏览器的行为,所以还要加上模拟浏览器的标识,即下面headers中的Users-Agent。代码如下:
import requesets # 数据请求模块
# 请求url
url='https://pic.netbian.com/e/search/result/?searchid=147'
# 请求头 Users-Agent为浏览器的标识
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0'
}
获取数据
发送请求我们会的获得响应的数据,下面我们就要对数据内容进行分析。
获取到的数据常见的格式有json、text(HTML文本)和XML格式。
还有后面获取到的图片是二进制(content)格式的数据。
# 获取响应数据
response = requests.get(url, headers=headers).text
解析内容
解析数据有很多种方式,常用的包括但不限于xpath,正则表达式,lxml,Beautiful Soup等等,今天我们来用一下第三方库parsel。
使用parsel库首先需要创建一个Selector对象,然后利用css选择器来解析其中照片数据。
parsel库支持Xpath、css选择器以及正则表达式来提取数据。不了解parsel库的语法的同学可以先去了解下。
selector=parsel.Selector(response.text) # 创建一个个Selector对象
data_li=selector.css('.slist ul li') # 利用css选择器提取图片的数据
for li in data_li: # 遍历
img_src=li.css('a img::attr(src)').get() # 每个图片的网址
title=li.css('a b::text').get() # 图片的的名字
title=title.replace(' ','').replace("*",'-') # 把其中的空格和特殊字符*替换掉
de_src='https://pic.netbian.com'+img_src # 完整的图片地址
存储数据
利用第三方库parsel的css选择器获取到数据后,我们就需要存储数据了。可以存储到到excel表格中,也可以存储到数据库中,我们这次先存储到本地。
img_data=requests.get(de_src,headers=headers).content # 获取图片的二进制数据
with open('./images/'+title+'.jpg','wb') as f: # 存储到本地
f.write(img_data)
完整源码
import requests # 数据请求模块
import parsel # 数据解析模块
import os # 文件管理模块
import re # 正则表达式模块
# 请求头
url='https://pic.netbian.com/e/search/result/?searchid=147'
# 请求体
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0'
}
# 使用os库创建目录images
if not os.path.exists('./images'):
os.mkdir('./images')
res=0 # 计算爬取到的总的照片数
for num in range(0,15): # 多页爬取 爬取15页
url=f'https://pic.netbian.com/e/search/result/index.php?page={num}&searchid=147'
response = requests.get(url, headers=headers) # 获取请求内容
selector=parsel.Selector(response.text) # 创建一个个Selector对象
data_li=selector.css('.slist ul li') # 利用css标签提取照片的数据
for li in data_li:
img_src=li.css('a img::attr(src)').get() # 照片的网址
title=li.css('a b::text').get() # 照片的的名字
title=title.replace(' ','').replace("*",'-') # 把其中的空格和特殊字符*替换掉
de_src='https://pic.netbian.com'+img_src
img_data=requests.get(de_src,headers=headers).content # 获取图片的二进制数据
with open('./images/'+title+'.jpg','wb') as f: # 保存到本地
f.write(img_data)
print("已下载:",title,"网址为:",de_src)
res+=1
print(f'第{num}页爬取完成')
print(f'共爬取{res}张')
运行截图
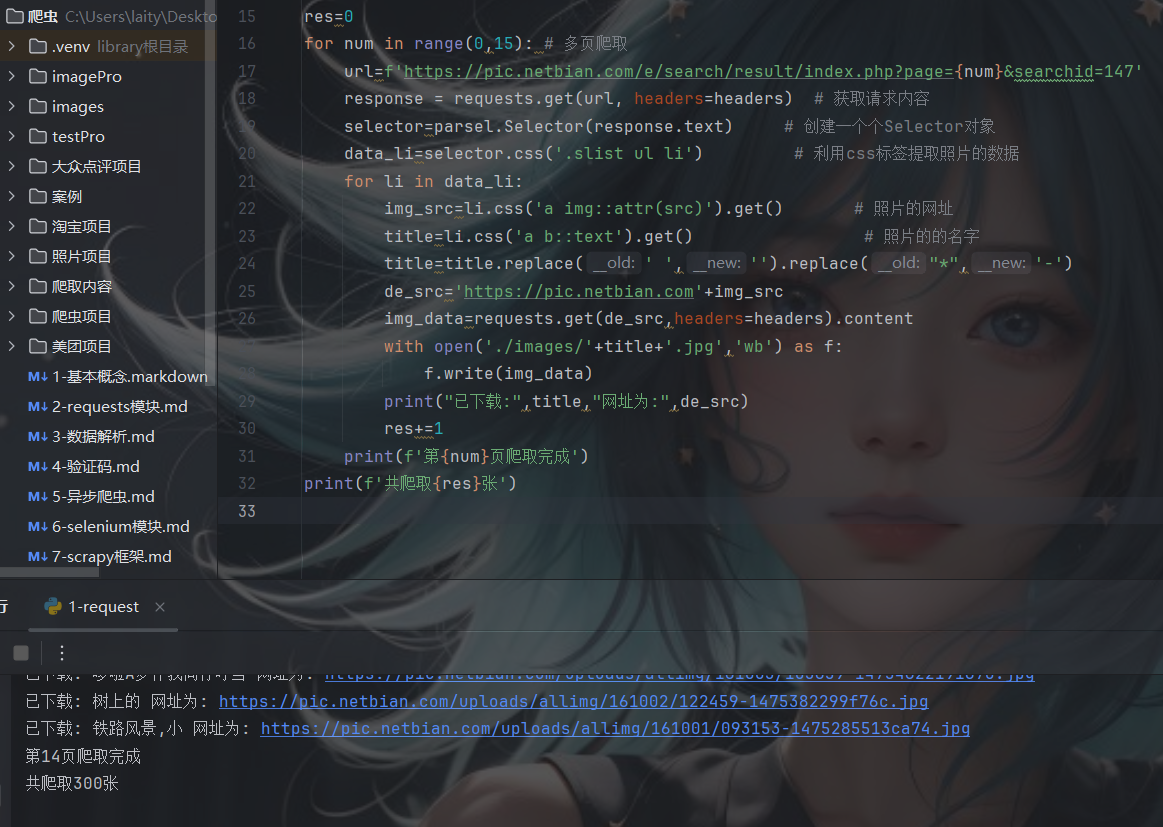
成果
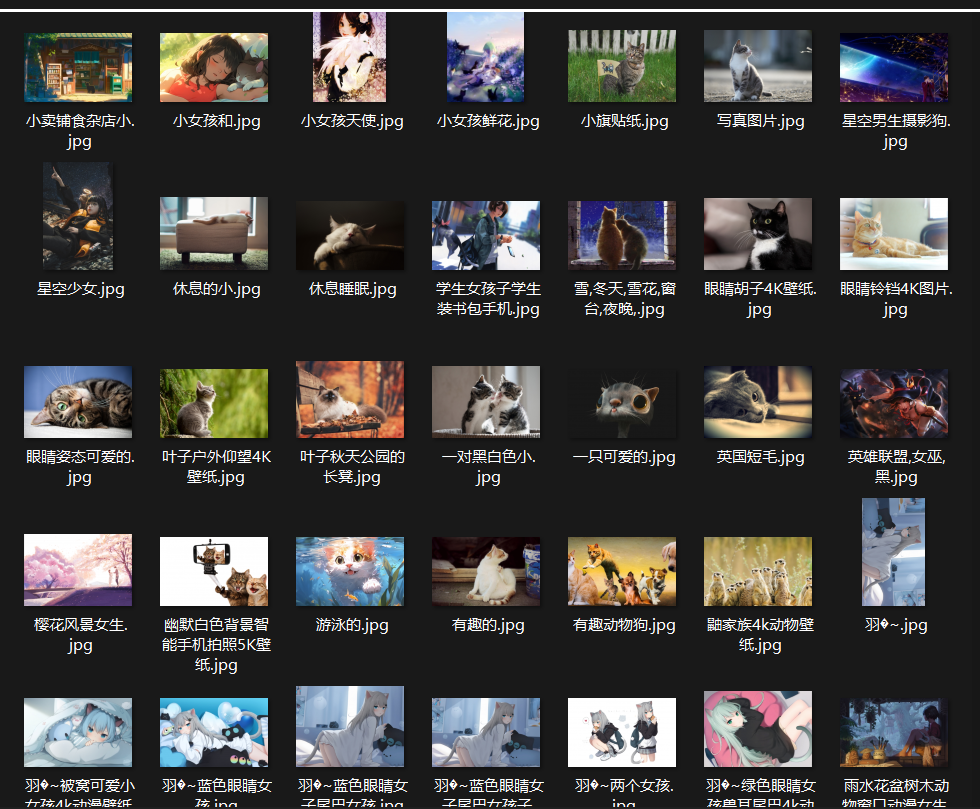
共勉
如果你赶不上凌晨五点的日出,不妨去看看傍晚六点的夕阳!
ps
- 当爬取到的数据过多的时候,可能面临着封ip的可能,这时候就得需要代理。需要带代理的源码私信d我一下。
- 保存图片的时候,可能会因为特殊字符的原因报错,记得替换掉。
- 最后:爬虫有风险,希望大家遵守robots协议。
博客
- 本人是一个渗透爱好者,不时会在微信公众号(laity的渗透测试之路)更新一些实战渗透的实战案例,感兴趣的同学可以关注一下,大家一起进步。
- 之前在公众号发布了一个kali破解WiFi的文章,感兴趣的同学可以去看一下,在b站(up主:laity1717)也发布了相应的教学视频。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号