摘要:  @目录前言下载链接方法一方法二ps共勉博客 前言 IDM全称是Internet Download Manager,是一款流行的下载管理软件。它相较于市面上其他的下载软件来讲,比如迅雷,百度网盘,FDM等等,IDM的下载速度是最快的,而且它还支持浏览器插件,支持网页资源嗅探功能,几乎支持市面上所有的下 阅读全文
@目录前言下载链接方法一方法二ps共勉博客 前言 IDM全称是Internet Download Manager,是一款流行的下载管理软件。它相较于市面上其他的下载软件来讲,比如迅雷,百度网盘,FDM等等,IDM的下载速度是最快的,而且它还支持浏览器插件,支持网页资源嗅探功能,几乎支持市面上所有的下 阅读全文
@目录前言下载链接方法一方法二ps共勉博客 前言 IDM全称是Internet Download Manager,是一款流行的下载管理软件。它相较于市面上其他的下载软件来讲,比如迅雷,百度网盘,FDM等等,IDM的下载速度是最快的,而且它还支持浏览器插件,支持网页资源嗅探功能,几乎支持市面上所有的下 阅读全文
posted @ 2025-06-11 10:35
laity17
阅读(17270)
评论(0)
推荐(0)
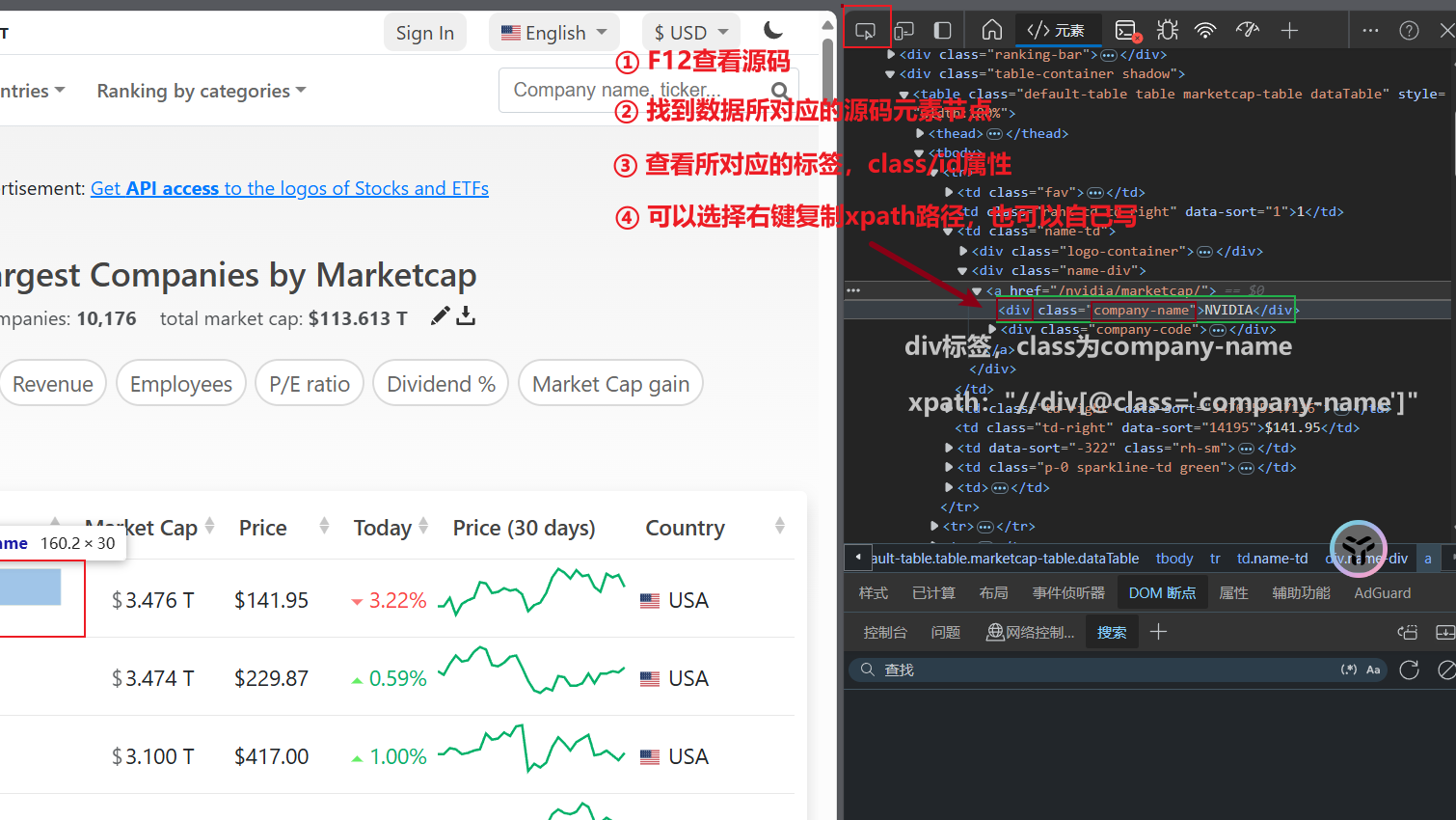 本文分享一个爬虫案例,通过使用parsel库中的xpath来爬取美国排名前一百名的公司,来详细解释下Xpath的使用。
本文分享一个爬虫案例,通过使用parsel库中的xpath来爬取美国排名前一百名的公司,来详细解释下Xpath的使用。 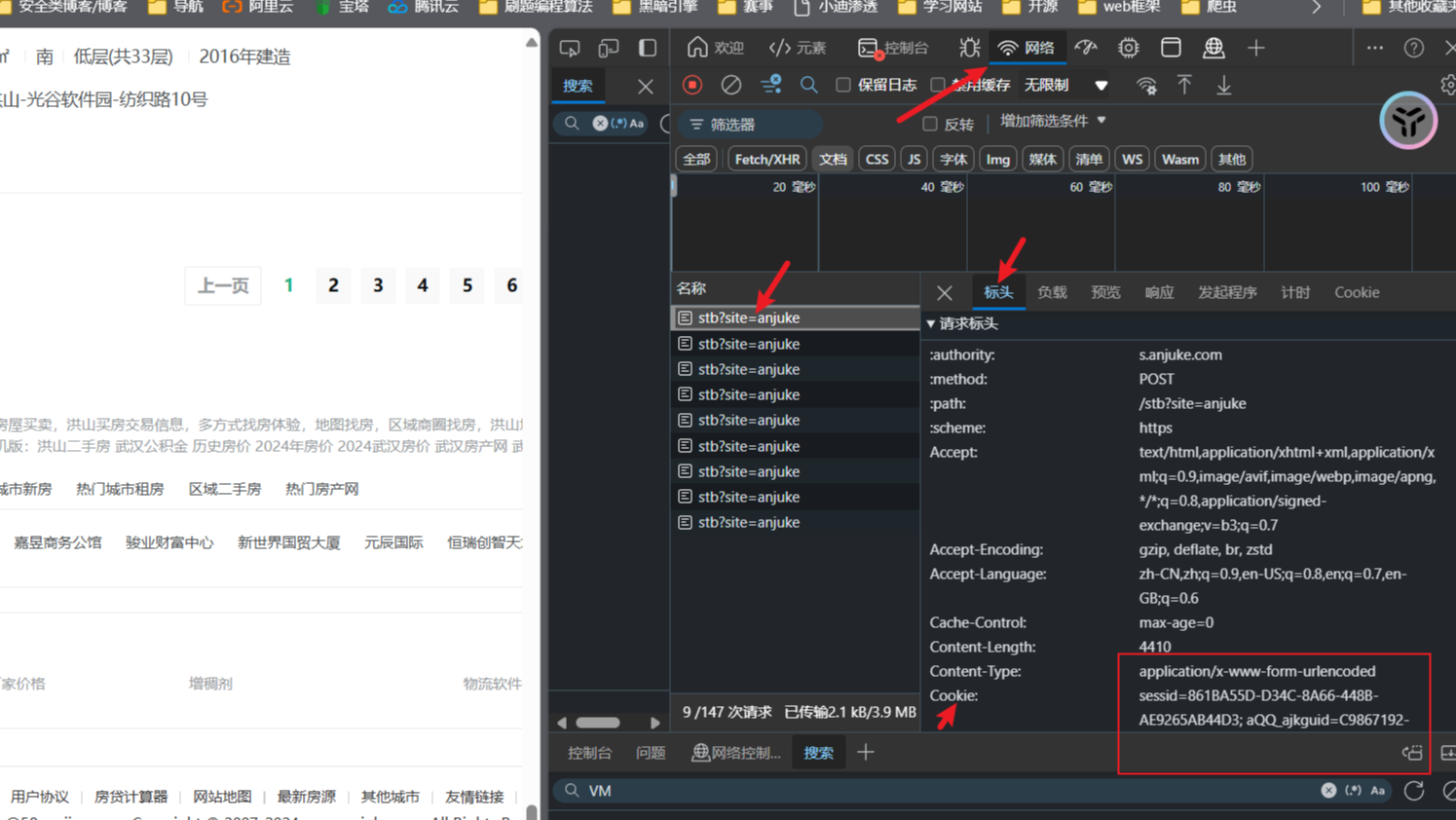 本文通过一个爬取二手房的案例,来分享另外一种解析数据的方式:解析神器python第三方库parsel库。之所以叫他解析神奇,是因为它支持三种解析方式。
可以通过Xpath,CSS选择器和正则表达式来提取HTML或XML文档中的数据。
本文通过一个爬取二手房的案例,来分享另外一种解析数据的方式:解析神器python第三方库parsel库。之所以叫他解析神奇,是因为它支持三种解析方式。
可以通过Xpath,CSS选择器和正则表达式来提取HTML或XML文档中的数据。 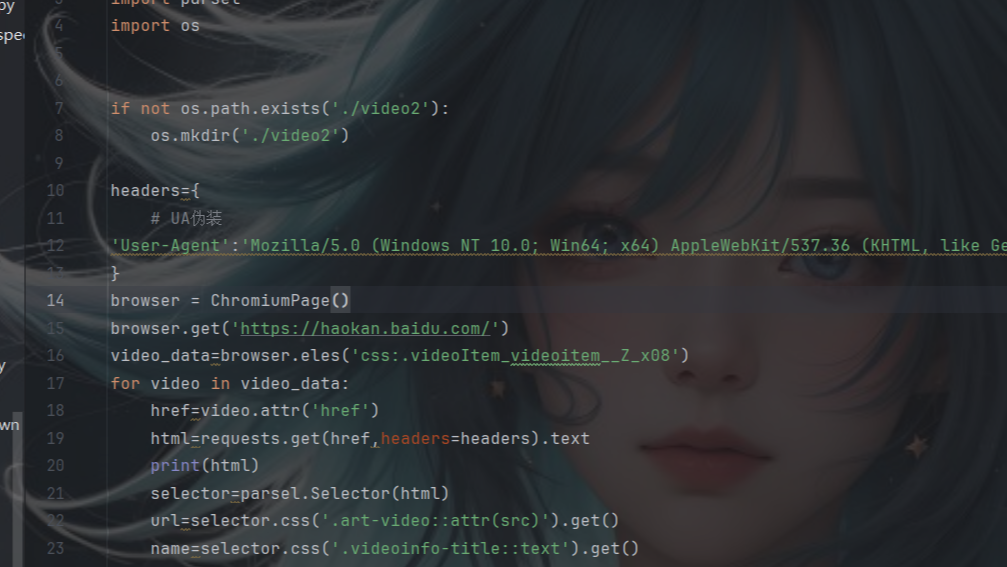 @目录前言导航DrissionPage介绍源码共勉博客 前言 继requests篇和selenium篇,我们今天用DrissionPage来进行图片的爬取。 导航 爬虫案例1-爬取图片的三种方式之一:requests篇(1) 爬虫案例1-爬取图片的三种方式之一:selenium篇(2) 爬虫案例1-
@目录前言导航DrissionPage介绍源码共勉博客 前言 继requests篇和selenium篇,我们今天用DrissionPage来进行图片的爬取。 导航 爬虫案例1-爬取图片的三种方式之一:requests篇(1) 爬虫案例1-爬取图片的三种方式之一:selenium篇(2) 爬虫案例1- 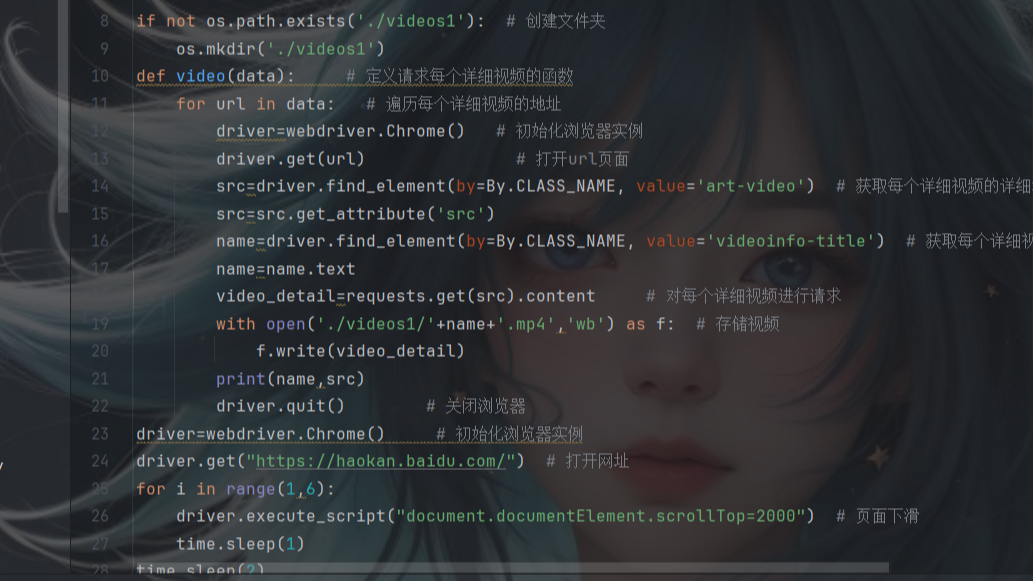 @目录前言导航selenium简介实战案例共勉博客 前言 继使用requests库爬取好看视频的文章后,本文分享使用python第三方库selenium库接着来爬取视频网站,后续也会接着分享使用第三方库DrissionPage爬取视频。 导航 爬虫案例1-爬取图片的三种方式之一:requests篇(
@目录前言导航selenium简介实战案例共勉博客 前言 继使用requests库爬取好看视频的文章后,本文分享使用python第三方库selenium库接着来爬取视频网站,后续也会接着分享使用第三方库DrissionPage爬取视频。 导航 爬虫案例1-爬取图片的三种方式之一:requests篇( 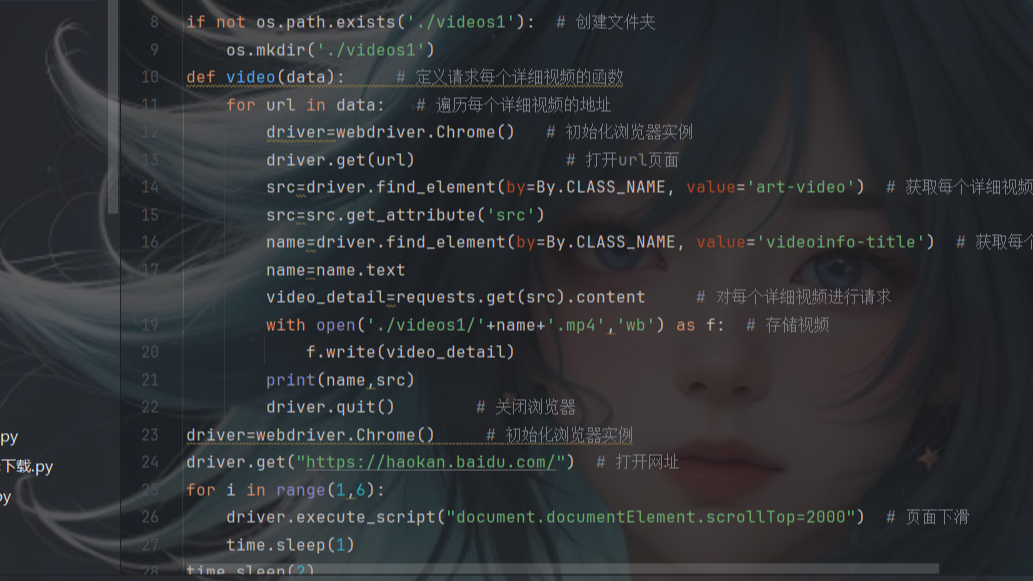 @目录前言导航爬虫步骤确定网址,发送请求获取响应数据对响应数据进行解析保存数据完整源码共勉博客 前言 本文写了一个爬取视频的案例,使用requests库爬取了好看视频的视频,并进行保存到本地。后续也会更新selenium篇和DrissionPage篇。当然,爬取图片肯定不止这三种方法,还有基于pyt
@目录前言导航爬虫步骤确定网址,发送请求获取响应数据对响应数据进行解析保存数据完整源码共勉博客 前言 本文写了一个爬取视频的案例,使用requests库爬取了好看视频的视频,并进行保存到本地。后续也会更新selenium篇和DrissionPage篇。当然,爬取图片肯定不止这三种方法,还有基于pyt 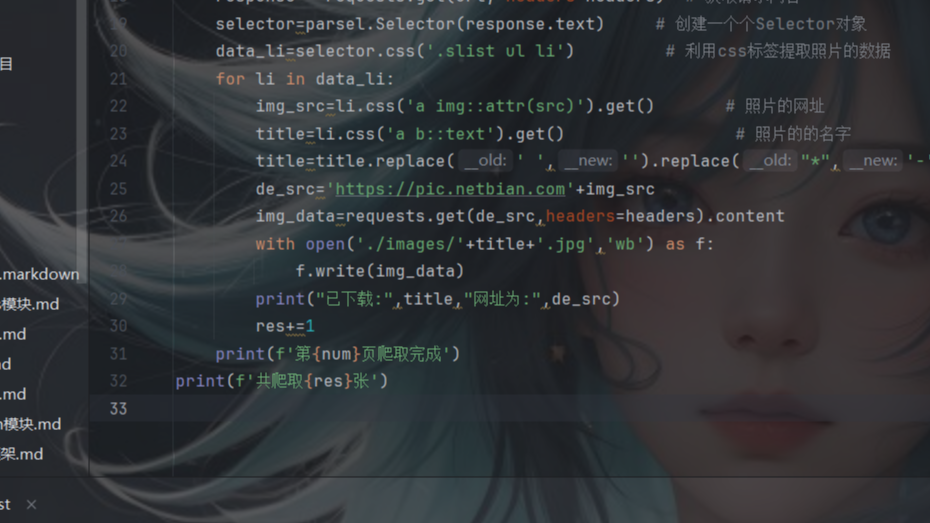 继requests篇和selenium篇,本文是爬取图片的最后一个案例,利用了python第三方库DrissionPage来自动化爬取图片。当然,爬取图片肯定不止这三种方法,还有基于python的scrapy框架,基于node.js的express框架以及基于Java的webmagic框架等等。
DrissionPage和selenium相似,都是基于python的网页自动化工具。不过Drission库的结合了requests和Selenium的优势,既能控制浏览器交互,又能高效地收发数据包。它的主要特点是可以监听网络数据,它可以拦截并解析请求和响应数据包,方便用户进行调试和分析。
继requests篇和selenium篇,本文是爬取图片的最后一个案例,利用了python第三方库DrissionPage来自动化爬取图片。当然,爬取图片肯定不止这三种方法,还有基于python的scrapy框架,基于node.js的express框架以及基于Java的webmagic框架等等。
DrissionPage和selenium相似,都是基于python的网页自动化工具。不过Drission库的结合了requests和Selenium的优势,既能控制浏览器交互,又能高效地收发数据包。它的主要特点是可以监听网络数据,它可以拦截并解析请求和响应数据包,方便用户进行调试和分析。 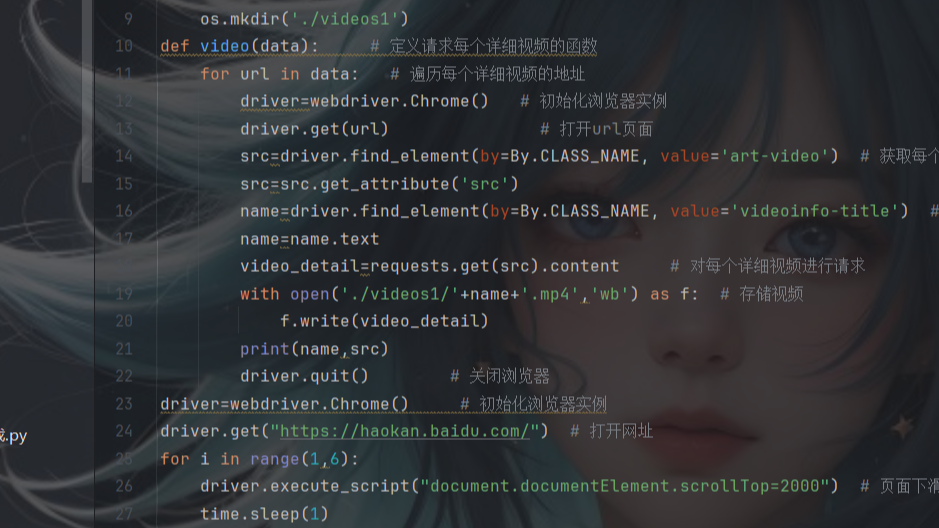 继使用requests库爬取图片后,本文使用python第三方库selenium来进行图片的爬取,后续也会使用同样是自动化测试工具DrissionPage篇来进行图片的爬取。
selenium是一个用于web应用测试的工具集,它可以直接运行在浏览器中,就像真正的用户在操作一样。它主要应用在自动化测试,web爬虫和自动化任务中。selenium提供了很多编程语言的接口,如java,python,c#等。这让开发者可以自己编写脚本来自动化web应用的测试。本文主要介绍selenium在web爬爬取图片的案例。
继使用requests库爬取图片后,本文使用python第三方库selenium来进行图片的爬取,后续也会使用同样是自动化测试工具DrissionPage篇来进行图片的爬取。
selenium是一个用于web应用测试的工具集,它可以直接运行在浏览器中,就像真正的用户在操作一样。它主要应用在自动化测试,web爬虫和自动化任务中。selenium提供了很多编程语言的接口,如java,python,c#等。这让开发者可以自己编写脚本来自动化web应用的测试。本文主要介绍selenium在web爬爬取图片的案例。 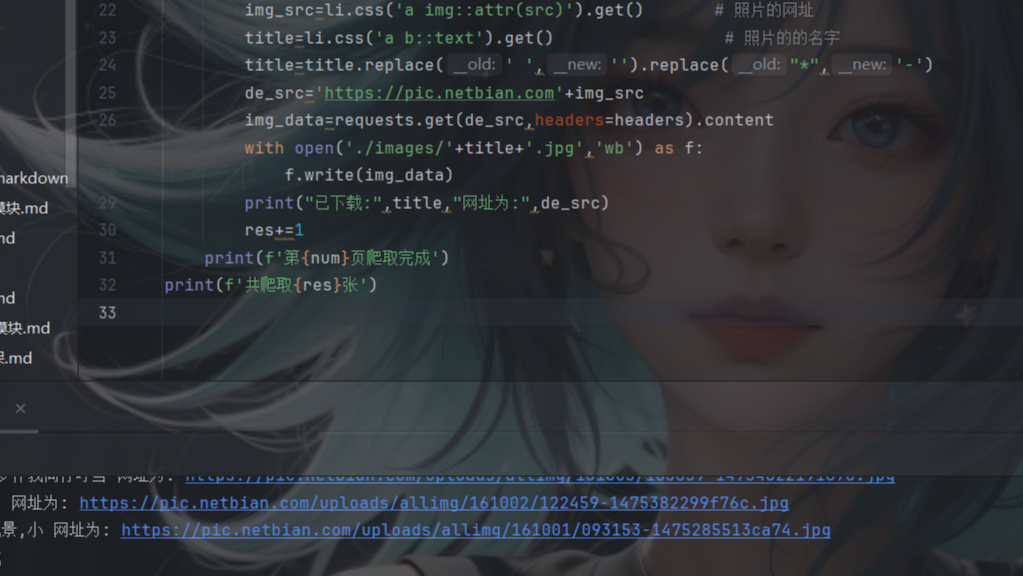 本文分享一个爬虫案例,使用requests库爬取彼岸网中的动物的图片,利用parsel库进行数据解析,并把这些照片保存到本地。后续也会接着分享使用第三方库selenium篇和DrissionPage篇爬取图片。
本文分享一个爬虫案例,使用requests库爬取彼岸网中的动物的图片,利用parsel库进行数据解析,并把这些照片保存到本地。后续也会接着分享使用第三方库selenium篇和DrissionPage篇爬取图片。  浙公网安备 33010602011771号
浙公网安备 33010602011771号