全卷积网络:从图像级理解到像素级理解
深度学习大讲堂致力于推送人工智能,深度学习方面的最新技术,产品以及活动。请关注我们的知乎专栏!
卷积神经网络(CNN):图像级语义理解的利器
自2012年AlexNet提出并刷新了当年ImageNet物体分类竞赛的世界纪录以来,CNN在物体分类、人脸识别、图像检索等方面已经取得了令人瞩目的成就。通常CNN网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。
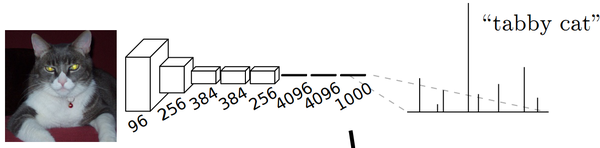
以AlexNet为代表的经典CNN结构适合于图像级的分类和回归任务,因为它们最后都期望得到整个输入图像的一个数值描述, 比如AlexNet的ImageNet模型输出一个1000维的向量表示输入图像属于每一类的概率。例如,下图中的猫, 输入AlexNet, 得到一个长为1000的输出向量, 表示输入图像属于每一类的概率, 其中在“tabby cat”这一类上响应最高。
全卷积网络:从图像级理解到像素级理解
与物体分类要建立图像级理解任务不同的是,有些应用场景下要得到图像像素级别的分类结果,例如:
1)语义级别图像分割(semantic image segmentation), 最终要得到对应位置每个像素的分类结果。
2) 边缘检测, 相当于对每个像素做一次二分类(是边缘或不是边缘)。以语义图像分割为例,其目的是将图像分割为若干个区域, 使得语义相同的像素被分割在同意区域内。下图是一个语义图像分割的例子, 输入图像, 输出的不同颜色的分割区域表示不同的语义:背景、人和马。

针对语义分割和边缘检测问题,经典的做法就是以某个像素点为中心取一个图像块, 然后取图像块的特征作为样本去训练分类器。在测试阶段, 同样的在测试图片上以每个像素点为中心采一个图像块进行分类, 分类结果作为该像素点的预测值。沈为等在CVPR2015上发表的DeepContour就采用这一思路检测图像边缘。
然而,这种逐像素取图像块进行分类的方法非常耗时, 另外一个不足是受到图像块的限制, 无法建模较大的上下文信息(context), 从而影响算法的性能。以语义图像分割(semantic image segmentation)为例, 数据集图像中的物体有时候非常大, 比如上图中马的分割例子, 如果不取比较大的图像块,难以抽取到有效的特征区分该像素块是否属于一匹马。
Lonjong等发表在CVPR2015的论文提出了全卷积网络(FCN)进行像素级的分类从而高效的解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时也保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。论文中逐像素计算softmax分类的损失, 相当于每一个像素对应一个训练样本。
由于步长(stride)不为一的卷积层和池化层产生的特征图(feature map)大小会有一些向下取整操作, 导致最后的feature map大小与原图不是严格的倍数关系。例如对如下的一个pooling层,
{
name:"pool1"
type: "Pooling"
bottom: "conv1_2"
top: "pool1"
pooling_param {
kernel_size: 2
stride: 2
}
}
前层输入大小为 11x11 的特征图, 其输出的特征图大小为(11 - 2) / 2 + 1 = 5, 并不是输入大小11的整数倍。上采样不能完全保证最后的perpixel prediction 结果与原图大小严格相同, 因此在上采样(Deconvlution)之后会有一个crop层, 将上采样的结果进行裁剪, 使之大小与输入图像严格相等。
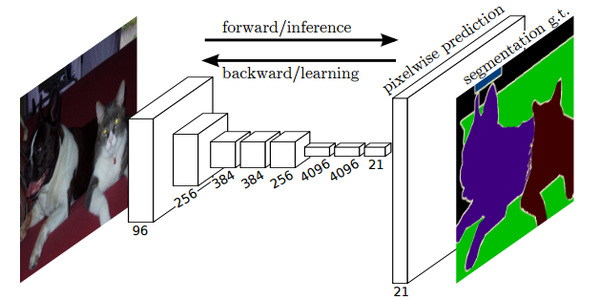
下图是Longjon用于语义分割所采用的全卷积网络(FCN)的结构示意图, 在Alexnet基础上, 最后的channel=4096的feature map经过一个1x1的卷积层, 变为channel=21的feature map, 然后经过上采样和crop, 变为与输入图像同样大小的channel=21的feature map, 也就是图中的pixel-wise prediction。 在Longjon的试验中一共有20个语义类别, 加上背景类别每个像素应该有21个softmax预测类, 因此pixel-wise prediction中channel=21。
FCN能够端到端(end to end)得到每个像素的预测结果, 目前也涌现了一大批基于FCN的算法, 例如边缘检测(edge detection), 视觉跟踪(visual tracking)等。同时FCN也可以省去传统识别中复杂的逐patch计算过程, 我们曾经在一个燃气表数字识别的项目中使用FCN直接得到如下图所示燃气表图片中的数字识别结果, 如果使用经典的用于数字识别的LeNet-5网络, 就需要对下图进行字符检测然后取patch归一化后进行分类。
在训练阶段, 我们标定燃气表数字中心一块区域的像素点为该类数字的正样本, 如下图所示, 不同数字的中心区域的像素被标定为不同的类别, 十种数字加上背景一共十一类, 不同颜色表示不同类别的标注, 其他的都是背景类。最后对每个像素计算softmax loss。
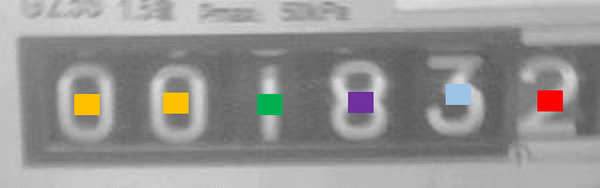
测试阶段通过全卷积网络得到输入燃气表图像每一个像素的分类结果, 接着进行非极大值抑制, 形态学变换等后续操作, 可直接得到上图的识别结果"001832", 整个系统十分高效。
我们开源了基于Caffe的实现,代码链接 GitHub - SHUCV/digit: digital meter numbers detection.
HED: FCN用于边缘检测
上一节讲到FCN适用于需要像素级预测的场景, 下面就介绍一个基于FCN的边缘检测的工作HED, 来自于屠卓文老师组, 发表在ICCV2015并且获得了Marr奖提名。
HED提出了side-output的概念, 在网络的中间的卷积层也对其输出上采样得到一个与原图一样的map, 并与ground-truth计算loss, 这些中间的卷积层输出的map称为side-output。 多个side-output产生的loss直接反向传导到对应的卷积层, 一定程度避免了梯度消失, 同时也在不同的卷积层(不同的感受野)学到了不同尺度的feature, 在edge-detection这个计算机视觉中古老的问题上取得了state-of-art的效果。
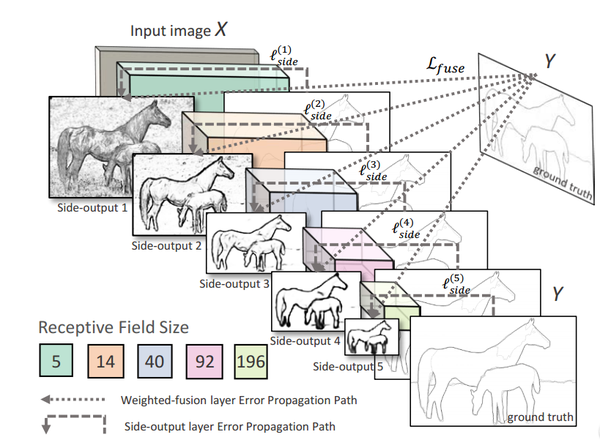
上图所示为HED的网络结构, 多个side-output产生的loss直接反向传到对应的卷积层。
FSDS:我们发表于CVPR16的骨架检测方法
在HED的基础上, 我们进一步提出了“尺度相关的边输出”(scale-associated side-output)的概念, 根据卷积层感受野的不同, 给予不同的监督, 使得最终的side-output具有尺度信息。
由于HED解决的是边缘检测问题, 对于一个边缘点即使很小的感受野也能捕捉到边缘信息, 所以HED在多个side-output上进行优化的时候使用的是同一个ground-truth, 不同的side-output(具有不同的感受野)用同一个ground-truth监督是合理的。但是在骨架检测(skeleton detection)的问题中,骨架尺度有很大的变化, 不同感受野的卷积单元能感受到的骨架信息是不同的。
正如下图, 只有卷积核(图中绿色方框)正好略大于骨架尺度(对应下图第1,第3个卷积核), 卷积核提取的特征才能有效检测出骨架。

基于以上的分析, 我们提出了FSDS(fusing scale-associated deep side-output),不同side-output是尺度相关的。 首先将骨架点根据其尺度从小到大分为离散的五类, 然后根据不同的side-output感受野的不同, 使用不同的ground-truth去监督side-output。 在这里, 物体骨架的尺度定义为骨架点到最近的轮廓点的距离的两倍。
具体的, 在浅层的side-output(更小的感受野), groundtruth只标注第一类(尺度最小的)为正样本,其它所有点为负样本进行二分类; 由浅到深随着side-output感受野的增加, 逐渐增加监督的类别, 进行三分类、四分类等等。
另外, 在HED中多个side-output的结果最后是平均累加的。 在我们的结构中, 由于浅层side-output产生的小尺度骨架的map置信度更高, 而深层side-output产生的大尺度骨架map的置信度高, 设计了带有权重的side-output融合策略, 多个由多个side-output产生的不同的尺度的分类结果使用不同的权重进行融合, 该权重在优化过程中自动学到。
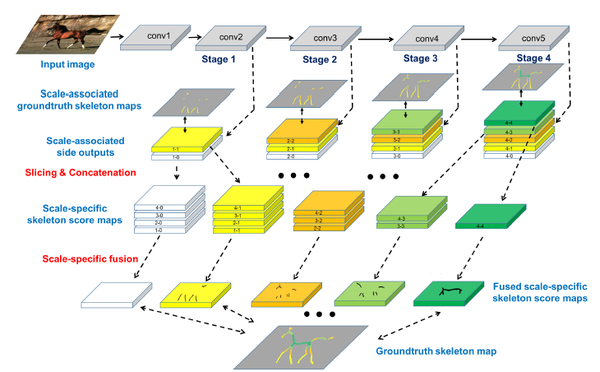
上图是我们方法(FSDS)的网络结构, 多个side-output使用不同尺度的监督, 最后使用不同的权重进行融合。
- 最上一排表示卷积;
- 第二排灰色背景表示不同side-output不同的groundtruth;
- 第三排表示side-output, 网络由浅到深, side-output产生的分类类别逐渐增多;
- 第四排将不同side-output上产生的同一尺度的骨架点的概率图连接到一起,骨架尺度用颜色区分, 数据流向为箭头指向。
我们已经开源了该方法基于Caffe的实现, 源代码链接GitHub - zeakey/DeepSkeleton: code for cvpr2016 paper "Object Skeleton Extraction in Natural Images by Fusing Scale-associated Deep Side Outputs"
致谢:感谢中科院计算所博士生所刘昕, 在撰本文期间本文与他进行了深入讨论并对本文提出了建设性的修改意见。
作者:赵凯上海大学研二学生, 导师沈为博士,研究方向为深度学习和机器视觉, 在CCF A类会议CVPR2016上发表论文一篇,个人主页: Zhao.Kai 。目前正在寻求攻读博士学位的机会,如果您有合适的机会推荐欢迎联系,邮箱是zhaok.ai@outlook.com。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号