NIPS2017_PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
Author
和PointNet是同一批作者,这是对PointNet的一个改进版本
Abstract
PointNet不能很好的捕捉由度量空间引入的局部结构,也就限制了它识别细粒度类别的能力以及对复杂场景的泛化能力
本文提出一个层级的神经网络递归地应用在嵌套划分的输入点云集。
通过探索度量空间的距离,本文设计的网络结构随着上下文尺度的增加可以学习到局部特征
更深的观察发现,点云集的密度一般都是不均匀的,但PointNet是在均匀采样密度的点集上训练的,这会造成很大的性能下降,我们提出新型的点集学习方法可以适应性的组合不同尺度的特征。
Introduction
在这种距离尺度空间中,局部领域可能会展现出不同的性质,比如说不同的部分它的点云密度不同
PointNet的基本思想是是学习每个点的空间编码然后聚合所有的点的特征到全局特征中,但是这种结构捕捉不到测度引入的局部结构。然而探究局部结构在CNN中被证明非常重要,传统2D CNN中接受规则输入,并且不断的在不同层捕获不同尺度的特征,通过层级结构不断地抽象特征能更好地泛化到unseen cases.
本文提出了一个层级的神经网络,去处理层级采样的点云。
类似于CNN结构,我们先从小的领域提取局部特征,然后group去产生更高层的特征,这个过程不断的重复直到获取整个点云集合的全局特征
要解决两个问题:
- 怎么划分这个点云集合
- 怎么组合点云集的局部特征
这两个问题是紧密联系的,因为划分点集是要让他们有共同的结构,所以local feature learner的权重就可以共享,类似于CNN, 本文使用PointNet作为局部特征学习器
作为一个基础的结构部件,PointNet要在局部点集中抽取特征,或者把特征组合成更高层表示,所以PointNet++递归地使用PointNet在一个嵌套划分的输入点云集合上
一个问题是如何划分输入:
每个局部划分都是一个邻域球,参数包括中心点的位置和尺度,为了更加均匀地覆盖整个数据集,中心点是使用farthest point sampling(FPS)算法进行采样的
FPS: 先随机选择一个点,然后再选择离这个点最远的点作为起点,再继续迭代,知道选出需要的个数为止
相比体素CNN使用的fixed stride, 本文的局部感受野只依赖于输入数据和尺度,所以更高效和有用
因为特征多尺度的融合以及输入点云的不均匀性,对邻域球的尺度的确定是项非常有挑战性但是很有趣的任务。
我们认为输入点云在不同的区域有不同的密度(现实生活中常见),这对应于CNN中不同尺度的kernel。
一个有意义的贡献是:PointNet++利用不同尺度的邻居来实现robustness和捕获的细节
PointNet缺乏捕获在不同尺度上的局部内容的能力,所以引入一个层级的特征学习框架来解决这个局限性
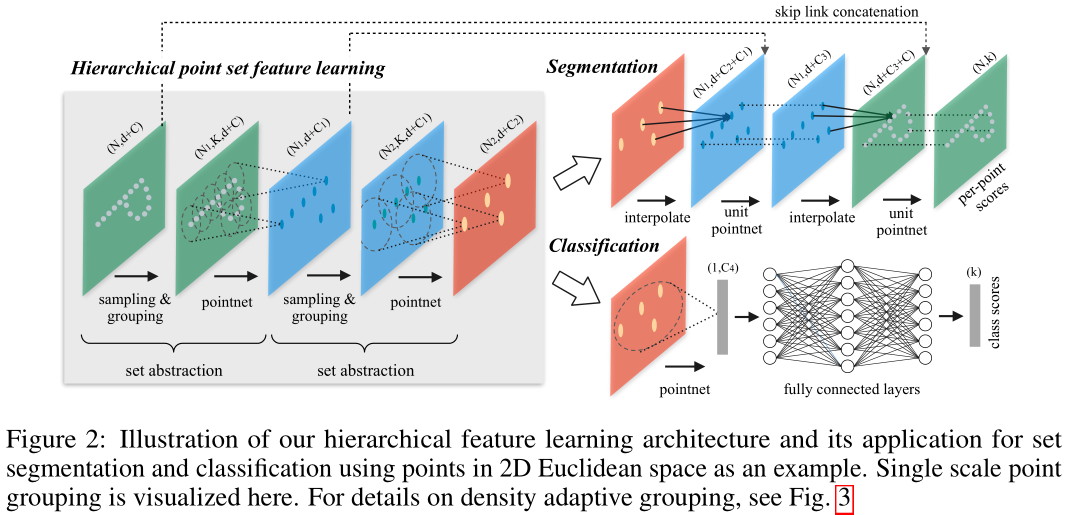
这个层级结构由很多个set abstraction leels构成,每个level中: a set of points is processed and abstracted to produce a new set with fewer elements
set abstraction level由三个层组成: Sampling layer, Grouping layer 和PointNet layer
Sampling layer主要是选出一些点作为局部区域的中心点,Grouping layer就是通过找中心点的邻居来构造局部区域,PointNet使用mini-PointNet来把局部区域编码层feature vectors
(N,d+C) N个点, d维坐标, C维额外特征
分组后每个组的点的个数不一定相同,但是PointNet把它们都统一到同一个长度的特征向量
分组算法用的是ball query,就是给定中点,把给定半径内的点都包括进来,同时是要给定点个数。相比KNN,ball query's保证了一个固定的区域尺寸,所以比KNN更加geralizable across space,更适合于需要局部特征的任务。
local region中的坐标首先被转换到相对于中点的坐标系中,使用相对坐标系,我们可以捕获到局部区域中点到点的关系。
不均匀的密度: Features learned in dense data may not generalize to sparsely sampled regions.
在低密度的地方可能会丢失局部信息,所以还需要增大尺度,所以提出了 density adaptive PointNet layers

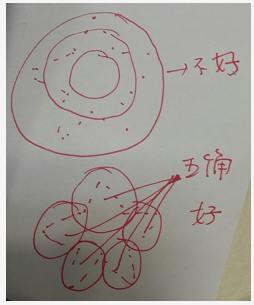
上面有个例子进行解释,想要捕捉一个五角星的样子
当输入采样密度变化时,学习对于不同尺度的区域特征的组合
根据点密度进行组合局部特征,
MSG: 分组的时候分不同scale
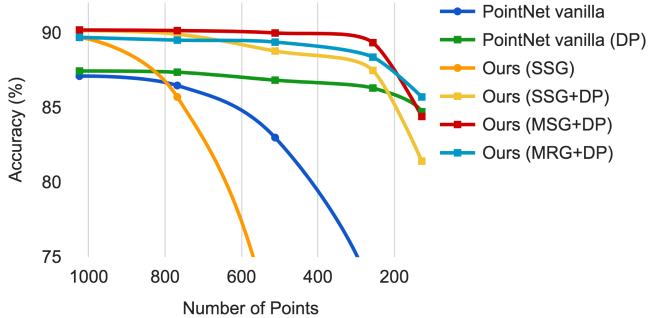
训练时会随机dropout一些input points,测试的时候不会dropout,这样训练集就有various sparsity
MRG: MSG计算消耗比较大,所以提出了一个替代的方法来避免大的计算消耗
计算如上图,一部分是直接对原始点提取特征,一部分是abstraction level后的点提取特征
左右两部分的权重不相同,当局部区域的密度很低时,左边的向量应该更不可信,因为它suffer more from sampling deficiency. 所以这时右边的vector权重要更大,如果密度大时,情况相反
For Set Segmentation
在set abstraction layer中,点进行了子采样,但是segmentation任务中对于点标记需要所有的原始点。一种方法是对所有的点都sample成中心点,但是计算复杂度太高。
另一种方式是子采样点的特征传导回原始数据点
采纳了一种层级的传播方式,如图二的skip link,
同时进行逆向连接,之前的输入作为输出,之前的输出大小作为输入,进行插值(feature values)进行插值。
插值方式采用的是: inverse distance weighted average based on k nearest neighbors
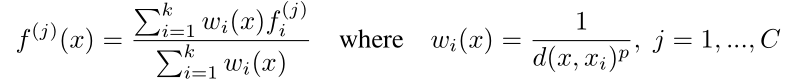
“unit pointnet”: 类似于CNN中的1x1卷积
这个过程直到传播特征到原始的数据点
SSG: single scale groupint
MSG: multi scale grouping
MRG: multi resolution grouping
DP: random input dropout during training

参考:
https://www.cnblogs.com/li-yao7758258/p/8182846.html
它本质上是PointNet的分层版本。每个图层都有三个子阶段:采样,分组和PointNeting。在第一阶段,选择质心,在第二阶段,把他们周围的邻近点(在给定的半径内)创建多个子点云。然后他们将它们给到一个PointNet网络,并获得这些子点云的更高维表示。然后,他们重复这个过程(样本质心,找到他们的邻居和Pointnet的更高阶的表示,以获得更高维表示)。使用这些网络层中的3个。还测试了不同层级的一些不同聚合方法,以克服采样密度的差异(对于大多数传感器来说这是一个大问题,当物体接近时密集样本,远处时稀疏)。他们在原型PointNet上进行了改进,在ModelNet40上的准确率达到了90.7%。
参考:http://blog.csdn.net/yongxiebin9947/article/details/78706591
所以这篇PointNet++主要内容为: 1.以何种方式将点云数据划分为多个区域(例如直接将点云分块进行体素化也是一种区域划分方法); 2.如何在一个块内,提取块内点云的“局部结构”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号