
tensorflow常见问题
1. sess.run() hangs when called / sess.run() get stuck / freeze that ctrl+c can't kill process
解决:
1 coord = tf.train.Coordinator() 2 threads = tf.train.start_queue_runners(sess=sess,coord=coord)
2. tf.name_scope中values参数的作用





3. 手写vgg遇到的loss不下降的问题
a. 如果使用SGD优化方法的话,注意batch_size和lr是linked的,取gpu内存中能运行的最大的batch_size,然后修改lr
b. 注意要对数据集进行shuffle,如果取一个batch,里面数据的标签全部一样就不好了
c. 修改bias, 把原本的1修改为0.7甚至是0.5 [但是我发现取0也行] 这个点暂时可以不管
d. 注意label的下标是从0开始还是从1开始
e. weight initialization: LSUV(All you need is a good init) > MSRA init(Delving into ... Kaiming He) > Xavier > Gaussian
f. 注意,对于VGG中的图片预处理,一定要减去均值做中心化,其他可有可无
以上为推测,以下是以及解决的方法
a. 一定减均值,暂时没有用scale
b. bias=0没改,使用的weight init是 msra init
c. 一块卡跑imagenet batch_size设置为64,不要用32
d. 传入label和计算的logits下标一定要对齐
e. 使用Adam优化方法 初始学习率设置为2e-4
f. 注意tf.loss.softmax_cross_entropy(logits,label)的返回值不是loss, 它只是把loss加入到tf.GraphKeys.LOSSES当中,要想得到loss,使用tf.losses.get_total_loss(),但是这个loss是包括了regurilazation_loss,大概是13左右,会大于6.91,如果只是计算loss,应该就是6.91左右。
4. tf.nn.conv2d(paddding="SAME") padding="VALID"


注意,SAME不是指一定输出和输入的大小相同,而是指如果stride=1,那么输出与输入大小一致
5. 设置global_step是发现它没有自动加一
如果想手动加一的话,需要如下写法:
1 global_step = tf.Variable(0,trainable=False) 2 increment_op = tf.assign_add(global_step,tf.constant(1)) 3 sess = tf.Session() 4 init = tf.global_variables_initializer() 5 sess.run(init) 6 for step in range(0,10): 7 .... 8 sess.run(increment_op)
但是在tf.train.Optimizer中Apply_gradient中,它会实现自动加一的操作,如果使用的是compute_gradient和apply_gradient操作,需要在apply_gradient(global_step=global_step)传入global_step的参数,如果使用的是minimize也需要手动传入global_step这个参数,使用方法如下:
1 global_step = tf.Variable(0,trainable=False,name='global_step') 2 opt = tf.train.AdamOptimizer(lr).minimize(loss,global_step)
6. 如果遇到以下问题

在使用代码如下的情况:
1 if __name__ == '__main__': 2 tf.app.run()
默认的tf.app.run()中是要带参数的,也就是入口函数,默认是main函数,如果没有定义main函数,需要手动将入口函数传入tf.app.run()中,如下:
1 tf.app.run(my_func)
1 def run(main=None, argv=None): 2 """Runs the program with an optional 'main' function and 'argv' list.""" 3 f = flags.FLAGS 4 5 # Extract the args from the optional `argv` list. 6 args = argv[1:] if argv else None 7 8 # Parse the known flags from that list, or from the command 9 # line otherwise. 10 # pylint: disable=protected-access 11 flags_passthrough = f._parse_flags(args=args) 12 # pylint: enable=protected-access 13 14 main = main or sys.modules['__main__'].main 15 16 # Call the main function, passing through any arguments 17 # to the final program. 18 sys.exit(main(sys.argv[:1] + flags_passthrough))
main = main or sys.modules['__main__'].main
等号右边的第一个main指 run(main=None, argv=None)传进来的参数,也就是指定的入口函数,sys.modules['__main__'] means current running file(e.g. my_model.py) 第二个就是指文件中的main函数
如果没有指定传入参数,那么它就是默认为文件中的main函数,如果没有的话就会报错
tf.app.run(my_main_running_function)
因为定义了很多flags,所以定义main函数时需要传入参数,写成如下形式即可
def main(_):
7. 对于test set大小如果除不尽batch_size,那么处理方式如下,tf.data.Dataset.batch()会自动地将最后一个batch的数据作为一个batch,所以不需要手动处理
1 dataset = tf.data.Dataset.range(200) 2 batched = dataset.apply(tf.contrib.data.batch_and_drop_remainder(128)) 3 print(batched.output_shapes) # ==> "(128,)" (the batch dimension is known)
tf.contrib.data.batch_and_drop_remainder(128)是将最后一个不满128的batch舍弃,所以输出的batch大小都是固定的128
By contrast, dataset.batch(128) would yield a two-element dataset with shapes (128,) and (72,), so the batch dimension would not be statically known.
但是dataset.batch(128)输出维度不固定,对于最后一个不满128的batch也是作为一个batch输出
但是到数据末尾时,再想取下一个batch就会报错,所以建议都写成如下方式:
1 dataset = tf.data.Dataset.range(200) 2 next_elements = dataset.batch(128) 3 While True: 4 try: 5 next_batch = sess.run(next_elements) 6 except tf.errors.OutOfRangeError: 7 print("finish") 8 break
以上代码会取出两个batch 一个是128一个是72,当想取第三个batch时,就会到except
8. variable_averages = tf.train.ExponentialMovingAverage() 滑动平均模型, 是对每个变量都维护一个影子变量,就是说模型中的参数变量变化剧烈的话你,你就不知道保存的哪个模型效果会更好,对模型中参数都做滑动平均,就可以提高测试时的稳
zhihu:芯尚刃
参考: https://www.zybuluo.com/irving512/note/957702
官网说法:
When training a model, it is often beneficial to maintain moving averages of the trained parameters. Evaluations that use averaged parameters sometimes produce significantly better results than the final trained values.
They help use the moving averages in place of the last trained values for evaluations. 用在evaluation时使结果更加稳定

Reasonable values for decay are close to 1.0, typically in the multiple-nines range: 0.999, 0.9999, etc.
The apply() method adds shadow copies of trained variables and add ops that maintain a moving average of the trained variables in their shadow copies. It is used when building the training model. The ops that maintain moving averages are typically run after each training step. The average() and average_name() methods give access to the shadow variables and their names. They are useful when building an evaluation model, or when restoring a model from a checkpoint file. They help use the moving averages in place of the last trained values for evaluations.
apply()方法对每个训练变量增加影子变量并增加op结点用于维持滑动平均的计算,这在training过程中建立,这个op是在每次的训练后运行
apply方法会为每个变量(也可以指定特定变量)创建各自的shadow variable, 即影子变量。之所以叫影子变量,是因为它会全程跟随训练中的模型变量。影子变量会被初始化为模型变量的值,然后,每训练一个step,就更新一次。更新的方式为:
shadow_variable = decay * shadow_variable + (1 - decay) * updated_model_variable
average()方法可以获取影子变量的值, average_name()可以获取影子变量的名字, 这是在evaluation过程中常常使用。
使用例子:
1 # Create variables. 2 var0 = tf.Variable(...) 3 var1 = tf.Variable(...) 4 # ... use the variables to build a training model... 5 ... 6 # Create an op that applies the optimizer. This is what we usually 7 # would use as a training op. 8 opt_op = opt.minimize(my_loss, [var0, var1]) 9 10 # Create an ExponentialMovingAverage object 11 ema = tf.train.ExponentialMovingAverage(decay=0.9999) 12 13 # Create the shadow variables, and add ops to maintain moving averages 14 # of var0 and var1. 15 maintain_averages_op = ema.apply([var0, var1]) 16 17 # Create an op that will update the moving averages after each training 18 # step. This is what we will use in place of the usual training op. 19 with tf.control_dependencies([opt_op]): 20 training_op = tf.group(maintain_averages_op) 21 22 ...train the model by running training_op...
There are two ways to use the moving averages for evaluations:
- Build a model that uses the shadow variables instead of the variables. For this, use the
average()method which returns the shadow variable for a given variable. - Build a model normally but load the checkpoint files to evaluate by using the shadow variable names. For this use the
average_name()method. See thetf.train.Saverfor more information on restoring saved variables.
在测试阶段有两种方法获取滑动平均值:
1. 用average()获取每个变量的滑动平均值
2. 从ckpt用滑动平均值的名字载入滑动平均值
Restore from checkpoint:
训练时若使用了ExponentialMovingAverage,在保存checkpoint时,不仅仅会保存模型参数,优化器参数(如Momentum), 还会保存ExponentialMovingAverage的shadow variable。
之前,我们可以直接使用以下代码restore模型参数, 但不会利用ExponentialMovingAverage的结果:
saver = tf.Saver()
saver.restore(sess, save_path)
若要使用ExponentialMovingAverage保存的参数:
variables_to_restore = ema.variables_to_restore() saver = tf.train.Saver(variables_to_restore) saver.restore(sess, save_path)
- 训练时,维护模型参数的滑动平均数。
- 评价时,取出滑动平均数作为模型参数。
实例
variables in checkpoint: bias/ExponentialMovingAverage 0.664593 bias/Momentum 4.12663 weight [[ 0.01567289] [ 0.17180483]] weight/ExponentialMovingAverage [[ 0.10421171] [ 0.26470858]] weight/Momentum [[ 5.95625305] [ 6.24084663]] bias 0.602739 ============================================== variables restored not from ExponentialMovingAverage: weight:0 [[ 0.01567289] [ 0.17180483]] bias:0 0.602739 ============================================== variables restored from ExponentialMovingAverage: weight:0 [[ 0.10421171] [ 0.26470858]] bias:0 0.664593
by default ema.variables_to_restore() uses tf.moving_average_variables() + tf.trainable_variables().
tf.moving_average_variables
If an ExponentialMovingAverage object is created and the apply() method is called on a list of variables, these variables will be added to the GraphKeys.MOVING_AVERAGE_VARIABLES collection. This convenience function returns the contents of that collection.
训练代码中使用方式如下:
1 variable_averages = tf.train.ExponentialMovingAverage(decay, global_step) 2 3 variables_to_average = (tf.trainable_variables() + tf.moving_average_variables()) 4 variables_averages_op = variable_averages.apply(variables_to_average) 5 6 train_op = tf.group(opt, variables_averages_op)
为什么要加上tf.moving_average_variables()?(##todo 写个代码验证下之前tf.moving_average_variables()里的变量是什么)
为什么说对bn的参数做了double-average 因为 batch_norm(trainable=True) 就会add variables to the GraphKeys.TRAINABLE_VARIABLES

只是为了和之前的代码兼容,这里不需要对bn的参数进行操作
9. 对于batch_norm的update_op问题
参考: http://www.cnblogs.com/hrlnw/p/7227447.html

y和b是可有可无的,如果有就是可训练的,u和o在训练时使用的是batch内的统计值, 在测试时就是在训练过程中累计的滑动平均值
训练过程中:
(1) 输入参数training=True
(2)计算loss时,要添加以下代码:添加update_ops到最后的train_op中,这样才能计算u和o的滑动平均
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(loss)
可是如果这里计算了滑动平均,那么8.中的计算为什么还要加入batch_norm的变量
测试过程:
training=False 在batch_norm的代码中有if else的分流,如果是True的话就使用mini_batch 否则用全局统计值
注意: bn的滑动平均是加入到tf.GraphKeys.UPDATE_OPS 其他的变量滑动平均加入到tf.GraphKeys.MOVING_AVERAGE_VARIABLES
http://www.aiboy.pub/2017/11/26/TensorFlow_BN_Layer/

http://ruishu.io/2016/12/27/batchnorm/ 这个介绍的相当详细 非常非常重要
10. tensorflow中变量的使用
注意,我们tensorflow代码本质上还是在写python代码,所以如果你只是想建立一个普通的变量,不是图中的变量,就用python的规则就好了,对于使用tf.Variable,如果要取它的值,还必须sess.run,不能直接赋值也够恶心,唯一的好处就是如果你要对它进行summary的记录时可以的,所以有些简单的变量直接使用python变量就好了
11. 对于在training过程中要做validation
参考: More than one Graph – Code Reuse in TensorFlow
Typically a model will be used in at least three ways:
- Training – finding the correct weights or parameters for the model given some training data. Often done periodically as new data arrives.
- Evaluation – calculating various metrics during training on a different data set to evaluate training quality or for cross validation.
- Serving – on-demand prediction for new data
不同的目的要使用不同的图,有时在一个模型中需要构建多个图
在tensorflow的建图过程中只支持增加,不支持删除计算节点,甚至overwrite也不行
1 with tf.Session() as sess: 2 my_sqrt = tf.sqrt(4.0, name='my_sqrt') 3 # override 4 my_sqrt = tf.sqrt(2.0, name='my_sqrt') 5 #print all nodes 6 print sess.graph._nodes_by_name.keys()
[u'my_sqrt_1/x', u'my_sqrt_1', u'my_sqrt/x', u'my_sqrt']
所以想要改写一个计算图是不可能的,那么就只能多建一个图
tensorflow甚至都特意提供了tf.variable_scope函数使得更为容易地建不同图,用这种方式有个很大的缺点就是,即使是很小的改变也需要知道原始建图的方法,这样太麻烦了,每次都得重新改代码建完整图

如果我们只是需要一张图能同时进行training和evaluation,我们可以使用条件逻辑:
TensorFlow does have a way to encode different behaviors into a single graph – the tf.cond operation.
tf.cond只保护它内部的东西
以下代码是正确的:
1 # Good - dropout inside the conditional 2 is_train = tf.placeholder(tf.bool) 3 activations = tf.cond(is_train, 4 lambda: tf.nn.dropout(activations, 0.7), 5 lambda: activations)
以下代码是不正确的,即使is_train == False 也仍然会运行 dropout
1 # Bad - droupout outside the conditional evaluated every time! 2 is_train = tf.placeholder(tf.bool) 3 do_activations = tf.nn.dropout(activations, 0.7) 4 activations = tf.cond(is_train, 5 lambda: do_activations, 6 lambda: activations)
Queues and the condiional operator
1 tf.cond(is_eval, 2 lambda: tf.train.shuffle_batch(eval_tensors, 1024,100000,10000), 3 lambda: tf.train.shuffle_batch(train_tensors,1024,100000,10000))
以上代码报错了:operation has been marked as not fetchable and crash.
Tensorflow是不允许enqueue conditionally, 所以要避免这个问题,我们需要将这个操作划分成两部分,一个是conditional part that creates the queue, and conditional part that pulls from the correct queue.
以下是一个例子:
1 def create_queue(tensors, capacity, ...): 2 ... 3 queue = data_flow_ops.RandomShuffleQueue( 4 capacity=capacity, min_after_dequeue=min_after_dequeue, seed=seed, 5 dtypes=types, shapes=shapes, shared_name=shared_name) 6 return queue 7 8 def create_dequeue(queue, ...): 9 ... 10 dequeued = queue.dequeue_up_to(batch_size, name=name) 11 ... 12 return dequeued 13 14 def merge_queues(self, is_train_tensor, train_tensors, test_tensors, ...): 15 train_queue = self.create_queue(tensors=train_tensors, 16 capacity=... 17 ) 18 test_queue = self.create_queue(tensors=test_tensors 19 capacity=... 20 ) 21 22 input_values = tf.cond(is_train_tensor, 23 lambda: self.create_dequeue(train_queue, ...), 24 lambda: self.create_dequeue(test_queue, ...)
Working with saved graphs
这个太复杂了,不用
其实我们常用的不高效的方法是用placeholder, 用tf.data.dataset来读取不同的训练数据和验证数据,在跑数据的时候用sess.run取出数据,用feed_dict放在图中的placeholder中
说使用feed_dict可能会损失时间性能,但是却是最为简便的方法,In evaluation, I want to use the same graph and the same session. I can use tf.cond to read from another separate queue instead of the RandomShuffleQueue. Or I could use feed_dict in evaluation.
关于tf.cond的使用
tf.cond is evaluated at the runtime
https://stackoverflow.com/questions/45517940/whats-the-difference-between-tf-cond-and-if-else
说是只有placeholder能改变条件的流向
tf.cond is evaluated at the runtime, whereas if-else is evaluated at the graph construction time.
If you want to evaluate your condition depending on the value of the tensor at the runtime, tf.condis the best option.
Do you mean if-condition depends at graph construction time, if at the runtime the condition changes, but it don't have effect on if block, because it is determined at graph construction time
The graph has been fixed after you finished drawing the graph and the if-else condition would not affect the graph while excuting the graph. 如果条件也是在图中,比如说placeholder就有用
如果想在training过程中validation,用tf.cond基本不可能实现,会报一个OurOfRangeError: End of sequence 看github上说这个是tensorflow的bug: https://github.com/tensorflow/tensorflow/issues/12414
然而我自己实现的时候遇到的问题是: 当validation时 image_batch, label_batch是需要reset的,也就是batch要移到第一位上,这个还不能实现
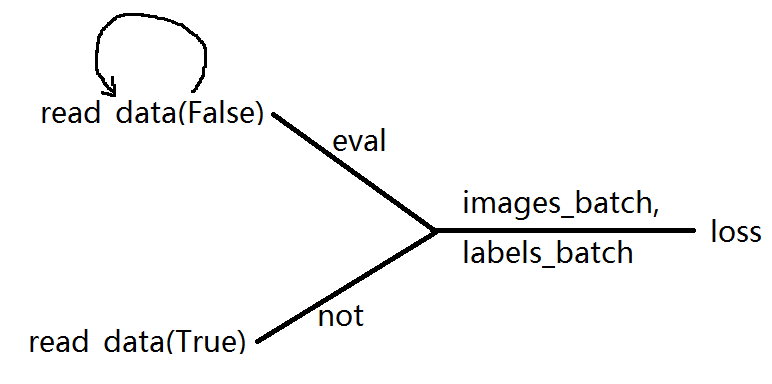
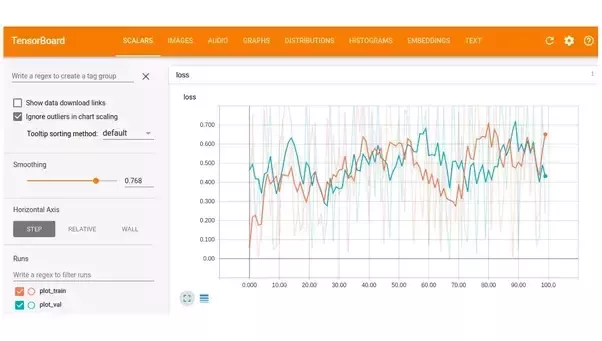
12. 想在tensorboard中把两个指标画在同一个图中
比如把training loss和validation loss画在同一个图中显示
By using two FileWriters with a single tf.summary.scalar you can plot two scalars on a single graph.
1 import tensorflow as tf 2 from numpy import random 3 4 """ 5 Plotting multiple scalars on the same graph 6 """ 7 8 writer_val = tf.summary.FileWriter('./logs/plot_val') 9 writer_train = tf.summary.FileWriter('./logs/plot_train') 10 loss_var = tf.Variable(0.0) 11 tf.summary.scalar("loss", loss_var) 12 write_op = tf.summary.merge_all() 13 session = tf.InteractiveSession() 14 session.run(tf.global_variables_initializer()) 15 for i in range(100): 16 # loss validation 17 summary = session.run(write_op, {loss_var: random.rand()}) 18 writer_val.add_summary(summary, i) 19 writer_val.flush() 20 # loss train 21 summary = session.run(write_op, {loss_var: random.rand()}) 22 writer_train.add_summary(summary, i) 23 writer_train.flush()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号