浅谈树分治
目录
内容大概有
- 点分治
- 边分治
- 动态点分治
- 动态边分治
- 长链剖分
点分治
两年前好像写过一篇关于点分治的文章(但是菜得很):https://blog.csdn.net/qq_38944163/article/details/81544134
用处:用于解决某类树上路径的问题的高效算法
暴力做树上路径问题的一般就是直接枚举两个点,再求出lca来计算这条路径,但这么做太不优美了。一般只能做
n
<
=
1
0
3
n<=10^3
n<=103的问题
点分治就是考虑枚举那个lca,然后计算经过这个点的路径,再把这个点删掉,剩下的若干个连通块(树)就是子问题。可以发现这和选点的顺序无关,所以每次贪心选点要使得删掉点后剩下的连通块最大的最小(那个点就是重心),这样就可以保证复杂度了。于是就有了点分治
算法核心思想: 每次钦定一个点作为根,统计经过这个点的路径的贡献(两端都在子树内),然后这个点各个儿子子树之前不再有贡献,一路分治下去即可(儿子树的互相独立)。
在树上钦定的点要保证删掉这个点后最大的连通块节点个数最小,这个点就是树的重心。
找重心:
- 首先随便找一个点为根dfs,统计出每个子树的大小
- 假设把 u u u删掉后最大的连通块节点个数是 m a x { s i z e [ v 1 ] , s i z e [ v 2 ] , . . . s i z e [ v k ] , n − s i z e [ u ] } max{\{size[v_1], size[v_2],...size[v_k],n-size[u] }\} max{size[v1],size[v2],...size[vk],n−size[u]}, v 1... k v_{1...k} v1...k是 u u u的儿子节点,n使当前连通块的大小
- 最后一个for找到一个u使得删掉后连通块节点个数最大的最小就好了( m a x { s i z e [ v 1 ] , s i z e [ v 2 ] , . . . . , s i z e [ v k ] } max {\{size[v_1],size[v_2],....,size[v_k]}\} max{size[v1],size[v2],....,size[vk]}可以在dfs的时候就求出来)
- 然后就没了
这么做一次的大小是 O ( 当 前 树 的 总 节 点 个 数 ) O(当前树的总节点个数) O(当前树的总节点个数)
复杂度证明
一定存在一个点使得以它为根它的每个儿子的子树(删掉后的连通块)大小都不大于
总
节
点
2
\frac{总节点}{2}
2总节点
时间复杂度可以用主定理证明,可以推推式子证明
T
(
n
)
=
2
∗
T
(
n
/
2
)
+
n
=
2
∗
(
2
∗
T
(
n
/
4
)
+
n
/
2
)
+
n
T(n) = 2*T(n / 2) + n \\ \ \ \ \ \ \ \ \ \ = 2*(2*T(n/4)+n/2)+n
T(n)=2∗T(n/2)+n =2∗(2∗T(n/4)+n/2)+n
=
4
∗
T
(
n
/
4
)
+
2
∗
n
\ \ \ \ \ \ \ \ \ = 4*T(n/4) +2*n
=4∗T(n/4)+2∗n
=
4
∗
(
2
∗
T
(
n
/
8
)
+
n
/
4
)
+
2
∗
n
\ \ \ \ \ \ \ \ \ = 4*(2*T(n/8)+n/4) +2*n
=4∗(2∗T(n/8)+n/4)+2∗n
=
8
∗
T
(
n
/
8
)
+
3
∗
n
\ \ \ \ \ \ \ \ \ = 8*T(n/8) +3*n
=8∗T(n/8)+3∗n
=
n
l
o
g
2
n
\ \ \ \ \ \ \ \ \ = nlog_2n
=nlog2n
也可以简单考虑,每个儿子子树大小都不大于 总 节 点 2 \frac{总节点}{2} 2总节点,所以每次分治下去,当前树的节点数/2,最多分治log层,每层都是n个,所以时间复杂度 O ( n l o g 2 n ) O(nlog_2n) O(nlog2n)
算法实现
int solve(int u) { //处理以u为根的子树
dfs(u);
for 找重心 u
calc(u);//处理通过u的路径
vis[u] = 1;
for v : son[u]
if(!vis[v]) solve(v);
}
练习
luogu P3806 【模板】点分治1
板子题不解释,直接上,不过要注意数据范围
重点部分
void calc() {
for(int i = l; i <= r; i ++) {
int u = a[i];
for(int j = 1; j <= m; j ++)
if(dis[u] <= q[j]) {
if(ok[q[j] - dis[u]]) ANS[j] = 1;
}
}
for(int i = l; i <= r; i ++) {
int u = a[i];
if(dis[u] <= 10000000) ok[dis[u]] = 1;
}
}
for(int i = p[u]; i + 1; i = e[i].nxt) {
int v = e[i].v;
if(vis[v]) continue;
dfss(v, u);
calc();
l = r + 1;
}
上面那个就是简单那个桶记一下前面的子树中是否有长度为x的路径,然后一颗一颗子树丢进去算,然后再更新进去就可以了
可以理解为算前面的子树对当前子树答案的贡献
评测记录
luogu P4149 [IOI2011]Race
套路题
看代码能懂 (以前的代码,很丑)
好像就是上一题把桶里的改成记最小值
评测记录
luogu P4178 Tree
和第一题一样,唯一的不同就是计算的是<=的,算的时候用树状数组维护前缀和就好了
重点部分
void calc() {
for(int i = l; i <= r; i ++) {
int u = a[i];
int x = query(k - dis[u]);
ans += x;
}
for(int i = l; i <= r; i ++) {
int u = a[i];
update(dis[u], 1);
}
}
就是计算的时候用树状数组维护前缀和
评测记录
SP1825 FTOUR2 - Free tour II
上一题改成维护前缀最大值就好了
评测记录
来个细节题
P3714 [BJOI2017]树的难题
把相同颜色的和不同颜色的分开计算就可以了
同样思维难度不大,只是细节多了点
评测记录
上面的都是一棵一棵子树加进去,算当前子树和前面子树贡献的,但有时候这种东西并不是很好算,就可以考虑把所有点互相贡献的值算出来,再减去子树内的点互相贡献的情况(不经过根,自己贡献自己)
来几道题康康吧
P5351 Ruri Loves Maschera
这题和Tree差不多,考虑做个边权最大值前缀和,计算的时候把子树的所有节点的这个值排个序,然后算贡献就好了 ,由于要排序,会把子树内自己到自己的计算进去,容斥一下减掉就好了
关键部分代码
int calc() {
int ret = 0;
sort(q + l, q + r + 1, cmp);
for(int i = l; i <= r; i ++) {
ret += q[i].ma * (query(R - q[i].dis) - query(L - q[i].dis - 1));
update(q[i].dis, 1);
}
for(int i = l; i <= r; i ++) {
sett(q[i].dis); //清空
}
return ret;
}
for(int i = p[u]; i + 1; i = e[i].nxt) {
int v = e[i].v, c = e[i].c;
if(vis[v]) continue;
dfss(v, u, c, 1);
ans -= calc();
l = r + 1;
}
l = 1;
ans += calc();
for(int i = l; i <= r; i ++)
if(L <= q[i].dis && q[i].dis <= R) ans += q[i].ma;
这题和前面不同的是直接算前面的子树对后面子树的贡献不好算,所以可以把整棵树先排个序,然后减去子树自己内互连的答案(保证路径过重心)
评测记录
CF293E Close Vertices
这题和上一题又差不多,计算的时候是个二维偏序,用树状数组即可
我计算的时候排了个序然后用两个指针扫了扫
int calc() {
int ret = 0;
sort(q + l, q + r + 1, cmp);
for(int i = l; i <= r; i ++) update(q[i].dep, 1);
int ll = l, rr = r;
while(ll < rr) {
if(q[ll].dis + q[rr].dis <= R) {
update(q[ll].dep, - 1);
ret += query(L - q[ll].dep);
ll ++;
} else {
update(q[rr].dep, - 1);
rr --;
}
}
for(int i = l; i <= r; i ++) {
sett(q[i].dep);
}
return ret;
}
luogu P5306 [COCI2019] Transport
这题和前面的不同,路径存在方向,可以考虑分向上和向下的路径讨论
记录所有向上到根的路径,最多余下多少油
向下dfs维护路径最多负多少
然后排个序用双指针扫一下就好了,和上一题差不多
可见得点分治板子本身不难,主要还是看里面路径的计算,即calc里的东西。
前面的都是比较基础的题目,下面看看稍微有点难度的题
P4886 快递员
首先考虑随便找一个点做根,算出最长的距离,可以发现如果这个点再任意一个最长距离的路径上,那么这个最长距离就不能再小了,如果不是,那最长距离的那两个点一定在同一棵子树,就往那个子树走就好了。
可以发现每次就是随便找一个点计算,然后往一棵子树走,再做重复的操作,记个最小值
随便找个点显然找重心,最多移动
l
o
g
n
logn
logn次然后这题就没了
评测记录
首先有个显然的结论,对于一般图的MST(最小生成树),我们可以把边集分为两部分分别做最小生成树,然后再把两部分最小生成树的边拿出来再做一次最小生成树,得到的就是原图的最小生成树
证明很显然
直接算两个点的距离要用
l
c
a
lca
lca,我们可以发现
l
c
a
lca
lca一定在它们之间的路径上
于是我们就可以愉快地搞路径啦
对于经过重心的两个点的路径
u
,
v
u,v
u,v,它们的边长就是
(
w
[
u
]
+
d
i
s
[
u
]
)
+
(
w
[
v
]
+
d
i
s
[
v
]
)
(w[u] + dis[u]) + (w[v]+dis[v])
(w[u]+dis[u])+(w[v]+dis[v]),就是两个点到根(重心)的路径长+点的权值
然后发现
每个点
x
x
x都是要加上自己的点权和到根的路径长
w
[
x
]
+
d
i
s
[
x
]
w[x]+dis[x]
w[x]+dis[x],另外一边肯定是选最小的
w
[
y
]
+
d
i
s
[
y
]
w[y]+dis[y]
w[y]+dis[y],所以这题直接找到子树中最小的
w
[
y
]
+
d
i
s
[
y
]
w[y]+dis[y]
w[y]+dis[y]再和其它点连边就好了
把这些边存下来,最后再跑一次kruskal 就好了
一共nlogn条边,O (n log^2n)
评测记录
有一个log的做法
把kruskal的排序改成基排
想了解的可以看这题的题解(与点分治关系不大)。
边分治
点分治是计算经过一个点的路径,那我们可以不可以类比点分治,计算经过一条边的路径呢?
于是就有了边分治。
算法核心思想:在树中选取一条边,将原树分成两棵不相交的树,计算第一个棵树对第二棵的贡献,,把边断开分成两棵树,然后递归处理。
同点分治,在树上钦定的边要保证删掉这个后最大的连通块节点个数最小,就是边两边的连通块大小尽量接近,选边也和点分治十分类似。
但是有个重要的问题,会被一个菊花图卡掉,这时可以考虑三度化。
三度化
三度化就是添加一些不会影响答案的虚点和虚边,使得每个点的度数不超过3,也可以理解为多叉树转二叉树。
一般有两种rebuild的方法

变成

灰色的是虚点和虚边,一般边权值为0
还有一种是像线段树一样rebuild

个人感觉第一种好写一点。
void rebuild(int u, int fa) {
int ff = 0, f = 0;
for(int i = 0; i < g[u].size(); i ++) {
int v = g[u][i], c = gg[u][i];
if(v == fa) continue;
if(!f) { f = 1;
insert(u, v, c, 1);
insert(v, u, c, 1);
ff = u;
} else {
++ tot;
insert(tot, ff, 0, 0), insert(ff, tot, 0, 0);
insert(tot, v, c, 1), insert(v, tot, c, 1);
ff = tot;
}
rebuild(v, u);
}
}
很容易理解吧
边分治的用途:每次会把原来的点集合分成两半,会带来一些好的性质,讨论也减少了很多,感觉思想和CDQ分治有点像,每次把树分成大小尽量接近的两部分,然后考虑前面部分对后面的贡献。
时间复杂度:
注意!!!时间复杂度虽然是
n
l
o
g
n
nlogn
nlogn,但是
l
o
g
log
log的底数不是
2
2
2,而是
3
2
\large \frac{3}{2}
23
大佬证明法:神仙command_block是对的就是对的

好吧其实是可以构造的
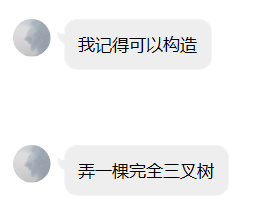

就是弄成这样子,然后每棵子树也是长这样,每次大小乘
2
3
\large \frac{2}{3}
32,所以边分治是
O
(
n
l
o
g
1.5
n
)
\large O(nlog_{1.5}n)
O(nlog1.5n)
做题的开内存要注意
先用luogu P4149 [IOI2011]Race来熟悉一下吧
主要部分
dfs(u, u);
int sz = size[u];
for(int i = 1; i <= r; i ++) {
int v = a[i];
if(max(size[v], sz - size[v]) < max(size[u], sz - size[u])) u = v;
}//找分治边
int uu = u, ed = -1;
for(int i = p[u]; i + 1; i = e[i].nxt) {//找边,断开的是u,和fa[u]这条边
int v = e[i].v;
if(v == 0) continue;
if(size[v] > size[u]) {
uu = v; ed = i; break;
}
}
e[ed].v = e[ed ^ 1].v = 0;//断开边
if(ed == -1) return;//分治结束条件就是找不到边(只剩下一个点)
l = 1, r = 0;
dfss(u, u, 0, 0);
for(int i = l; i <= r; i ++) {
if(q[i].u <= n) {
if(q[i].c <= k) bian[q[i].c] = min(bian[q[i].c], q[i].dep);
}
}
l = r + 1;
dfss(uu, uu, e[ed].c, e[ed].cc);
for(int i = l; i <= r; i ++) {
if(q[i].u <= n) {
if(q[i].c <= k) ans = min(bian[k - q[i].c] + q[i].dep, ans);
}
}
for(int i = 1; i <= r; i ++) if(q[i].u <= n && q[i].c <= k) bian[q[i].c] = INF;
solve(u), solve(uu);
计算不用脑子,直接把前面那棵树丢进桶里,计算对后面那棵树的贡献,再加上一端再根上的
然后分治下去
评测记录
可以发现边分治写起来好像比点分治还简单, 这是错觉
计算的时候不用脑子,思维复杂度极低.复杂度被加在了奇怪的地方,如代码复杂度
边分治还是一个非常容易掌握的算法 我才不会告诉你我第一次写调了3h
点分树(动态点分治)
算法核心思想 : 就是把点分治时的重心抽出来建一棵树就好了,每次修改的时候只会对在这棵点分树(重心树)上到根的路径有影响,点分树(重心树)最多logn,所以暴力跳就好了
建树就是找重心的时候加个
Fa[重心] = 上一个重心
不难发现原树上的两点lca肯定再它们的简单路径上。
给道简单的入门题
SP2939 QTREE5 - Query on a tree V
思路很明显,建好点分树之后在每个节点上拿一个可删(小根)堆维护一下以当前点为子树的根每个点的深度
询问的时候就一路往上跳,把堆顶取出来和当前点的深度相加,再取个min就是答案
关于可删堆的写法
就是拿两个小根堆,一个维护原来的,一个维护要删的 (枪毙名单), 如果两个堆的堆顶相同就弹出 (枪毙)
struct Hp{
priority_queue<int>s,t;int c;
void del(int x){t.push(-x);--c;}
void push(int x){s.push(-x);++c;}
void upd(){while(t.size()&&s.top()==t.top()){s.pop();t.pop();}}
int top(){upd();return c ? -s.top() : INF;}
}h[N];
