

高并发
1 Sychronized 和 ReentrantLock区别

2 线程池

上图中的任务拒绝策略描述有误,上图是拒绝机制。拒绝策略有下面这4种
拒绝策略提供顶级接口 RejectedExecutionHandler ,其中方法 rejectedExecution 即定制具体的拒绝策略的执行逻辑。jdk默认提供了四种拒绝策略:
1. AbortPolicy - 抛出异常,中止任务。抛出拒绝执行 RejectedExecutionException 异常信息。线程池默认的拒绝策略。必须处理好抛出的异常,否则会打断当前的执行流程,影响后续的任务执行
2. CallerRunsPolicy
当有新任务提交后,如果线程池没被关闭且没有能力执行,则把这个任务交于提交任务的线程执行,也就是谁提交任务,谁就负责执行任务。这样做主要有两点好处。
第一点新提交的任务不会被丢弃,这样也就不会造成业务损失。
第二点好处是,由于谁提交任务谁就要负责执行任务,这样提交任务的线程就得负责执行任务,而执行任务又是比较耗时的,在这段期间,提交任务的线程被占用,也就不会再提交新的任务,减缓了任务提交的速度,相当于是一个负反馈。在此期间,线程池中的线程也可以充分利用这段时间来执行掉一部分任务,腾出一定的空间,相当于是给了线程池一定的缓冲期
3. DiscardPolicy - 直接丢弃,其他啥都没有
当新任务被提交后直接被丢弃掉,也不会给你任何的通知,相对而言存在一定的风险
,因为我们提交的时候根本不知道这个任务会被丢弃,可能造成数据丢失。
4. DiscardOldestPolicy - 丢弃队列最老任务,添加新任务。当触发拒绝策略,只要线程池没有关闭的话,丢弃阻塞队列 workQueue 中最老的一个任务,并将新任务加入

线程池参数及设置原则
CPU 密集型任务,线程需要大量计算,因此需要足够多的 CPU 资源,而处理器核心数加 1 或者 2 的数量可以充分利用 CPU 资源,避免线程之间的竞争和阻塞;
而对于 I/O 密集型任务,由于线程大部分时间都处于等待 I/O 操作的状态,因此可以适当增加核心线程数以利用空闲的 CPU 时间,从而提高系统效率
CPU密集型应用:通常将核心线程数设置为CPU核心数的1.5倍到2倍之间。
IO密集型应用:通常将核心线程数设置为CPU核心数的2倍以上,因为IO操作会导致线程阻塞,这样可以让CPU在等待IO的过程中处理其他任务。
(并发编程书)
CPU 密集型核心线程数设置为处理器核心数加 1 或者 2;
I/O 密集型任务,设置在 2 x N 左右,其中 N 是可用 CPU 核心数
maximumPoolSize: 线程池中能够容纳的最多线程数。
CPU密集型应用:通常将最大线程数设置为CPU核心数的2倍到4倍之间
IO密集型应用:通常将最大线程数设置为CPU核心数的2倍以上,因为IO操作会导致线程阻塞,这样可以让CPU在等待IO的过程中处理其他任务。
2N+1 (并发编程书推荐)
keepAliveTime: 保持存活的时间
unit :保持存活的时间单位 ,一般为秒为单位 TimeUnit.SECONDS
- CPU密集型应用:可以将该参数设置为0,防止创建过多的线程占用CPU资源。
- IO密集型应用:建议将该参数设置为1分钟以上,因为IO操作会导致线程阻塞,这样可以避免线程频繁启动和销毁造成的性能开销。
(并发编程书籍)
- 对于 CPU 密集型任务,因为线程需要大量计算,所以不宜让空闲线程持续存在,以避免浪费系统资源。因此,建议将 keepAliveTime 设置得较短(例如 10 秒),以便及时回收空闲线程。
- 对于 I/O 密集型任务,由于线程大部分时间都处于等待 I/O 操作的状态,因此可以适当增加 keepAliveTime,以利用空闲的 CPU 时间,提高系统效率。建议 keepAliveTime 的值在数十秒或者数分钟之间。
BlockingQueue<Runnable>(workQueue) 等待队列 ,可以设置等待队列得长度。
用于存储未被执行的任务的队列,可以是有界队列或无界队列。
CPU密集型应用:建议使用有界队列,以避免任务过多导致OOM问题。
IO密集型应用:建议使用无界队列,以便能够尽可能地缓存所有任务。
ThreadFactory 线程工厂: 通过线程工厂创建线程对象,一般使用Executors.defaultThreadFactory() 默认创建线程对象。
RejectedExecutionHandler 拒绝策略:new ThreadPoolExecutor.AbortPolicy()
RejectedExecutionHandler
- CallerRunsPolicy:将任务回退到调用者线程执行。这种策略可以避免任务丢失,并且不会导致队列溢出,但可能会影响调用线程的性能。
- AbortPolicy:直接抛出 RejectedExecutionException 异常,以拒绝新的任务提交。这种策略可以保证系统稳定性,但会导致部分任务无法完成,因此需要根据实际情况做好异常处理和日志记录。
- DiscardPolicy:直接丢弃新的任务,不予处理。这种策略适用于那些对任务结果要求不高的场景,但也可能会导致任务丢失,因此需要慎重使用。
- DiscardOldestPolicy:丢弃队列中等待时间最长的任务,并尝试重新提交新的任务。这种策略可以保证队列不会溢出,但可能会导致一些任务被丢失或延迟执行。
以上策略都是针对有界队列的情况下,如果使用无界队列,则只有 CallerRunsPolicy 策略和 AbortPolicy 策略是有效的,而 DiscardPolicy 和 DiscardOldestPolicy 策略则没有意义
3 线程状态或生命周期
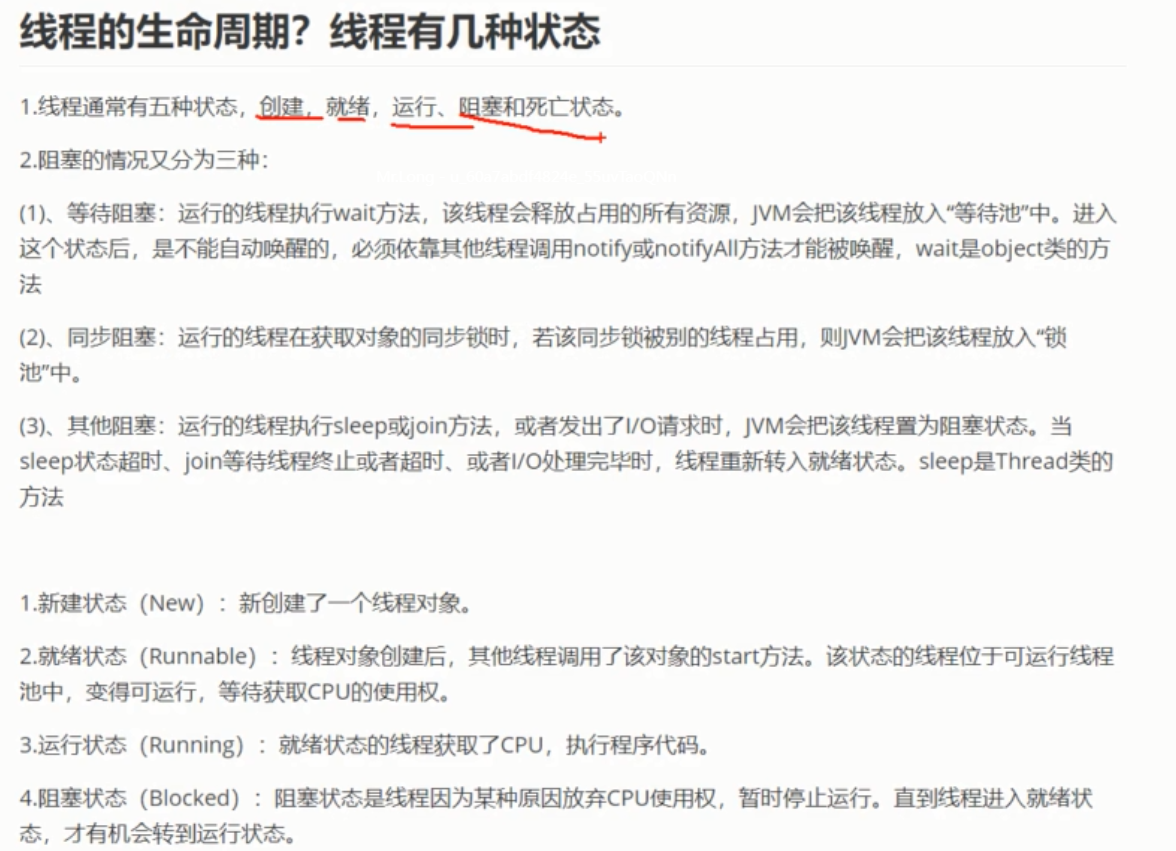
![]()
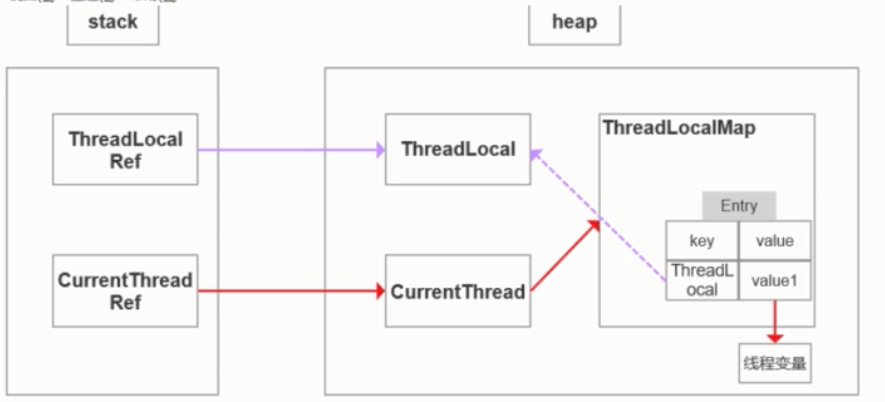
4 ThreadLocal


ThreadLocal类是java提供的线程存储机制, 可以将数据存储在ThreadLocal中,如果是同一个线程中, 可以在任意方法中获取存储的数据
ThreadLocal底层是通过ThreadLocalMap来实现存储的, 每一个线程Thread中都有一个ThreadLocalMap,
是key-value形式,key存储ThreadLocal对象,value存储的是实际值
例子:
ThreadLocal<String> t = new ThreadLocal();
t.set("xx”);
t.get();
t..remove(); // 执行完成后,清除ThreadLocal中数据; 防止在线程池情况下一直保留未回收会产生内存泄漏问题
ThreadLocal类中的set方法源码
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}



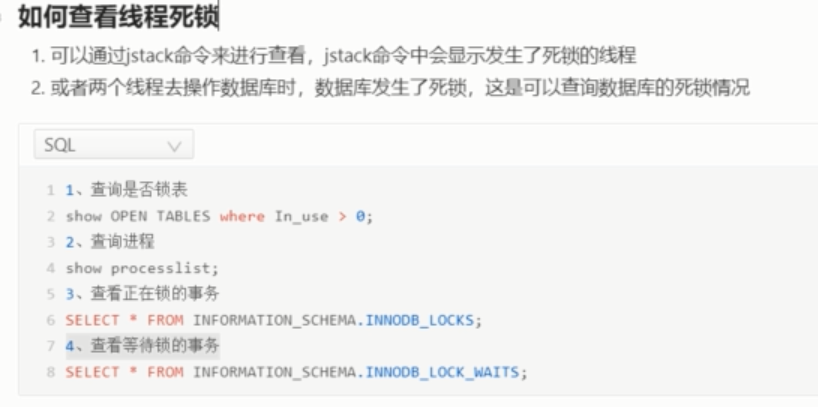
5 查看线程死锁
一些java程序或者java开发的中间件,可以通过jstack命令来查看发生死锁的进程
6 volatile关键字
volatile底层是通过操作系统内存屏障来实现的, 由于使用了内存屏障,会紧张指令重排, 所以保证了有序性
读取操作:
当一个变量用volatile修饰时,如果是读取这个变量值则会直接从主内存中读取;
如果未加此关键字修饰,则会从CPU高速缓存中读取数据;
修改操作:
当使用volatile修饰时,如果是修改操作,则在修改属性时将cpu高速缓存中数据修改完后会直接同步到主内存
当未使用此修饰时,则只修改CPU高速缓存中读取数据; 再由其它机制同步数据到主内存

7 线程池创建
1. Executors.newFixedThreadPool:创建⼀个固定⼤⼩的线程池,可控制并发的线程数,超出的线程会在队列中等待;
2. Executors.newCachedThreadPool:创建⼀个可缓存的线程池,若线程数超过处理所需,缓存⼀段时间后会回收,若线程数不够,则新建线程;
3. Executors.newSingleThreadExecutor:创建单个线程数的线程池,它可以保证先进先出的执⾏顺序;
4. Executors.newScheduledThreadPool:创建⼀个可以执⾏延迟任务的线程池;
5. Executors.newSingleThreadScheduledExecutor:创建⼀个单线程的可以执⾏延迟任务的线程池;
6. Executors.newWorkStealingPool:创建⼀个抢占式执⾏的线程池(任务执⾏顺序不确定)【JDK1.8 添加】。
7. ThreadPoolExecutor:最原始的创建线程池的方式,它包含了 7 个参数可供设置,后⾯会详细讲。
public class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
String value="test";
System.out.println("Ready to work");
Thread.currentThread().sleep(5000);
System.out.println("task done");
return value;
}
}
public class ThreadPoolDemo {
public static void main(String[] args) {
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
Future<String> task = newCachedThreadPool.submit(new MyCallable());
if (!task.isDone()) {
System.out.println("task has not finished ,please wait");
}
try {
System.out.println("task return =" + task.get());
} catch (ExecutionException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
newCachedThreadPool.shutdown();
}
}
}
ThreadPoolExecutor t = Executors.newFixedThreadPool(.)
FutureTask.summit(线程对象) 提交请求
FutureTask.get() 获取执行结果
FutureTask.cancel() 取消请求

import java.util.concurrent.Callable; public class CallableDemo implements Callable<Integer> { private int sum; @Override public Integer call() throws Exception { System.out.println("Callable子线程开始计算啦!"); Thread.sleep(2000); for(int i=0 ;i<5000;i++){ sum=sum+i; } System.out.println("Callable子线程计算结束!"); return sum; } ExecutorService es = Executors.newSingleThreadExecutor(); //创建Callable对象任务 CallableDemo calTask=new CallableDemo(); //创建FutureTask FutureTask<Integer> futureTask=new FutureTask<>(calTask); //执行任务 es.submit(futureTask);
8



9

10.

11.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix