
面试官:请你重构 Kafka...
经常有读者后台跟我说,希望我能够写一些系统设计相关的文章,最近我就在研究常用消息队列 kafka 和 pulsar 的架构设计,所以总结了这篇文章,希望在你做技术选型或阅读源码的时候起到一定的帮助。
我们从一个面试的场景开始好了。
面试官:了解 Kafka 吗?简单介绍下?
我张口就来:Kafka 嘛,作为一款比较成熟的消息队列,它必然 YYDS,什么削峰填谷,异步化,解耦,高性能,高可用……
面试官:嗯,那么 Kafka 有什么缺点呢?
我:啊这……
平时背的八股文都是夸 Kafka 的,这突如其来的这波反向操作可把我难住了。
面试官肯定一眼就看出来我在背八股文,对消息队列没有什么深入的研究,笑了笑,语重心长地教导我:
正所谓时势造英雄,任何新技术的出现都是时代的产物,不存在 YYDS 的技术,Kafka 是很好,但在目前云原生的趋势下它确实老了,不能满足目前很多业务发展的需要了。你回去好好研究下 Kafka 可能存在的问题,如果让你来重新设计 Kafka,你会如何做?
我陷入沉思:时势造英雄,确实是这样。
想当年刚进大学的时候看着别人的教程自己搭博客平台,要登录 Linux 服务器安装 python mysql nginx 等等一大堆东西,还要熟悉 Centos/Ubuntu 等系统的各种配置细节的差异;大二的时候我去一个云计算公司实习,拼命研究 OpenStack、Open vSwitch 什么的。现如今各种服务都是容器化一键部署,之前学的那套东西基本忘光了,脑子里只剩 docker + k8s 了。
类比过来,目前 Kafka 确实是主流消息队列,但这只能证明用它的人多,打的补丁多,并不能代表它是完美的,它的设计不可能跳出时代的局限,随着时代的发展,它必然也会被新的技术取代。
那我看看新一代的消息队列是如何设计的,不就可以学到 Kafka 的局限性以及改进思路了吗?
目前最新的消息队列是 Apache Pulsar,号称是下一代云原生分布式消息流平台:

这么牛逼,那我必须研究一波 Pulsar 的设计,看看下一代云原生的消息平台长啥样。
首先看看我们为什么需要消息队列。
如果两个服务之间需要通信,最简单的方案就是直接让它俩之间建立通信就行了。但试想一下,如果所有生产数据的服务和消费数据的服务都要彼此相连,那么系统多了之后,各个系统之间的依赖关系会极其复杂。如果其中的某个系统进行一点修改,那简直是噩梦,真可谓牵一发而动全身。
而在生产者和消费者之间引入中间件就是为了解决这个问题:消息的产生者不关心消费者是谁,它只需要把消息一股脑丢到消息队列里面,消费者会从消息队列里面消费数据。

这就是系统设计中一个最简单实用的技巧:加中间层。没有什么问题是加一个中间层服务解决不了的,如果真解决不了,那就加两层。
PS:这不是玩笑,确实有句名言如是说:计算机领域的任何问题都可以通过添加中间层来解决。
细分一下,消费模型又分两种:
1、点对点模式,也叫队列模式。即每条消息只会被一个消费者消费。
2、发布订阅(Pub/Sub)模式。发送到某个 Topic 的消息,会分发给所有订阅该 Topic 的消费者进行消费。
一个成熟的消息队列应该同时支持上述两种消费模型。
另外,你总不能让生产者的消息「阅后即焚」吧,所以消息队列应该有自己的持久化存储系统,能够把消息存储下来,方便后续的回溯、分析等操作。
综上,消息队列在整个系统中的主要作用就是:
1、解耦。使得服务之间的拓扑关系简单了很多。
2、削峰/异步化。消息队列可以把大量不需要实时处理的数据暂存下来,等待消费者慢慢消费。
当然,消息队列中间件看似消除了服务之间的互相依赖,但说到底其实是让所有服务都依赖消息队列了,如果消息队列突然坏掉,那就全完蛋了。
所以我们对这个消息队列本身的要求就非常高,具体来说有几方面:
1、高性能。消息队列作为整个系统的枢纽,它的性能必须足够高,否则很可能成为整个系统的性能瓶颈。
2、高可用。说白了就是要抗揍,如果消息队列集群中的少部分节点由于种种原因去世了,也不能影响整个集群的服务。
3、数据可靠性。在各种极端情况下(比如突然断网、突然断电),要保证已经收到的消息成功储存(一般是指落到磁盘中)。
4、可扩展。业务是发展的,如果消息队列集群快扛不住计算压力了,就需要更多的计算资源(扩容);如果消息队列集群压力很小,导致很多节点搁那打酱油,那么需要回收计算资源(缩容)。这就需要消息队列在设计时就考虑如何进行灵活的扩缩容。
Kafka 架构
就我的学习经历,学习新系统架构设计时的一大难点就是名词太多,很难把「逻辑概念」和「实体」对应起来。
记得我在第一次学习 Kafka 的时候,什么 broker、topic、partition、replica 全部混在一起,差点给我直接劝退。所以下面我除了画一些架构图之外,还会着重描述每个名词背后具体代表的实体。
首先说说 Kafka 的架构设计。
producer 和 customer 可以选定 Kafka 的某些 topic 中投递和消费消息,但 topic 其实只是个逻辑概念,topic 下面分为多个 partition,消息是真正存在 partition 中的:

每个 partition 会分配给一个 broker 节点管理:

所谓 broker 节点,就是一个服务进程。简单来说,你把一个 broker 节点理解为一台服务器,把 partition 理解为这台服务器上的一个文件就行了。
发到 topic 的消息实际上是发给了某个 broker 服务器,然后被持久化存储到一个文件里,我们一般称这个文件是 log file。
那么为什么要给一个 topic 分配多个 partition 呢?
很显然,如果一个 topic 只有一个 partition,那么也就只能有一台 broker 服务器处理这个 topic 上的消息,如果划分成很多 partition,就可以把这个 topic 上的消息分配到多台 broker 的 partition 上,每个 broker 处理消息并将消息持久化存储到 log file 中,从而提高单 topic 的数据处理能力。
但问题是怎么保证高可用?如果某个 broker 节点挂了,对应的 partition 上的数据不就就无法访问了吗?
一般都是通过「数据冗余」和「故障自动恢复」来保证高可用,Kafka 会对每个 partition 维护若干冗余副本:

若干个 partition 副本中,有一个 leader 副本(图中红色的),其余都是 follower 副本(也可称为 replica,图中橙色的)。
leader 副本负责向生产者和消费者提供订阅发布服务,负责持久化存储消息,同时还要把最新的消息同步给所有 follower,让 follower 小弟们和自己存储的数据尽可能相同。
这样的话,如果 leader 副本挂了,就能从 follower 中选取一个副本作为新的 leader,继续对外提供服务。
这就是 Kafka 的设计,一切看起来很完美,是吧?实际上并不完美。
Kafka 架构的缺陷
1、Kafka 把 broker 和 partition 的数据存储牢牢绑定在一起,会产生很多问题。

首先一个问题就是,Kafka 的很多操作都涉及 partition 数据的全量复制。
比方说典型的扩容场景,假设有broker1, broker2两个节点,它们分别负责若干个 partition,现在我想新加入一个broker3节点分摊broker1的部分负载,那你得让broker1拿一些 partition 给到broker3对吧?
那不好意思,得复制 partition 的全量数据,什么时候复制完,broker3才能上线提供服务。且不说消耗 IO 以及网络资源,如果复制数据的速度小于 partition 的写入速度,那永远都别想复制完了。
再比方说,我想给某个 partition 新增一个 follower 副本,那么这个新增的 follower 副本必须要跟 leader 副本同步全量数据。毕竟 follower 存在的目的就是随时替代 leader,所以复制 leader 的全量数据是必须的。
除此之外,因为 broker 要负责存储,所以整个集群的容量可能局限于存储能力最差的那个 broker 节点。而且如果某些 partition 中的数据特别多(数据倾斜),那么对应 broker 的磁盘可能很快被写满,这又要涉及到 partition 的迁移,数据复制在所难免。
虽然 Kafka 提供了现成的脚本来做这些事情,但实际需要考虑的问题比较多,操作也比较复杂,数据迁移也很耗时,远远做不到集群的「平滑扩容」。
2、Kafka 底层依赖操作系统的 Page Cache,会产生很多问题。
之前说了,只有数据被写到磁盘里才能保证万无一失,否则的话都不能保证数据不会丢。所以首先一个问题就是 Kafka 消息持久化并不可靠,可能丢消息。
我们知道 Linux 文件系统会利用 Page Cache 机制优化性能。Page Cache 说白了就是读写缓存,Linux 告诉你写入成功,但实际上数据并没有真的写进磁盘里,而是写到了 Page Cache 缓存里,可能要过一会儿才会被真正写入磁盘。
那么这里面就有一个时间差,当数据还在 Page Cache 缓存没有落盘的时候机器突然断电,缓存中的数据就会永远丢失。
而 Kafka 底层完全依赖 Page Cache,并没有要求 Linux 强制刷盘,所以突然断电的情况是有可能导致数据丢失的。对于大部分场景来说,可以容忍偶尔丢点数据,但对于金融支付这类服务场景,是绝对不能接受丢数据的。
另外,虽然我看到很多博客都把 Kafka 依赖 page cache 这个特性看做是 Kafka 的优点,理由是可以提升性能,但实际上 Page Cache 也是有可能出现性能问题的。
我们来分析下消费者消费数据的情况,主要有两种可能:一种叫追尾读(Tailing Reads),一种叫追赶读(Catch-up Reads)。
所谓追尾读,顾名思义,就是消费者的消费速度比较快,生产者刚生产一条消息,消费者立刻就把它消费了。我们可以想象一下这种情况 broker 底层是如何处理的:
生产者写入消息,broker 把消息写入 Page Cache 写缓存,然后消费者马上就来读消息,那么 broker 就可以快速地从 Page Cache 里面读取这条消息发给消费者,这挺好,没毛病。
所谓追赶读的场景,就是消费者的消费速度比较慢,生产者已经生产了很多新消息了,但消费者还在读取比较旧的数据。
这种情况下,Page Cache 缓存里没有消费者想读的老数据,那么 broker 就不得不从磁盘中读取数据并存储在 Page Cache 读缓存。
注意此时读写都依赖 Page Cache,所以读写操作可能会互相影响,对一个 partition 的大量读可能影响到写入性能,大量写也会影响读取性能,而且读写缓存会互相争用内存资源,可能造成 IO 性能抖动。
再进一步分析,因为每个 partition 都可以理解为 broker 节点上的一个文件,那么如果 partition 的数量特别多,一个 broker 就需要同时对很多文件进行大量读写操作,这性能可就……
那么,Pulsar 是如何解决 Kafka 的这些问题的呢?
存算分离架构
首先,Kafka broker 的扩容都会涉及 partition 数据的迁移,这是因为 Kafka 使用的是传统的单层架构,broker 需要同时进行计算(向生产者和消费者提供服务)和存储(消息的持久化)。
怎么解决?很简单,多叠几层呗。
Pulsar 改用多层的存算分离架构,broker 节点只负责计算,把存储的任务交给专业的存储引擎 Bookkeeper 来做:

有了存算分离架构,Pulsar 的 partition 在 broker 之间的迁移完全不会涉及数据复制,所以可以迅速完成。
为什么呢?你想想「文件」和「文件描述符」的区别就明白了。文件,对应磁盘上的一大块数据,移动起来比较费劲;而文件描述符可以理解为指向文件的一个指针,传递文件描述符显然要比移动文件简单得多。
在 Kafka 中,我们可以把每个 partition 理解成一个存储消息的大文件,所以在 broker 间转移 partition 需要复制数据,异常麻烦。
而在 Pulsar 中,我们可以把每个 partition 理解成一个文件描述符,broker 只需持有这个文件描述符即可,把对数据的处理全部甩给存储引擎 Bookkeeper 去做。
如果 Pulsar 的某个 broker 节点的压力特别大,那你增加 broker 节点去分担一些 partition 就行;类似的,如果某个 broker 节点突然坏了,那你直接把这个 broker 节点管理的 partition 转移到别的 broker 就行了,这些操作完全不涉及数据复制。
进一步,由于 Pulsar 中的 broker 是无状态的,所以很容易借助 k8s 这样的基础设施实现弹性扩缩容。
经过这一波操作,broker 把数据存储的关键任务甩给了存储层,那么 Bookkeeper 是如何提供高可用、数据可靠性、高性能、可扩展的特性呢?
节点对等架构
Bookkeeper 本身就是一个分布式日志存储系统,先说说它是如何实现高可用的。
Kafka 使用主从复制的方式实现高可用;而 Bookkeeper 采用 Quorum 机制实现高可用。
Bookkeeper 集群是由若干 bookie 节点(运行着 bookie 进程的服务器)组成的,不过和 Kafka 的主从复制机制不同,这些 bookie 节点都是对等的,没有主从的关系。
当 broker 要求 Bookkeeper 集群存储一条消息(entry)时,这条消息会被并发地同时写入多个 bookie 节点进行存储:

还没完,之后的消息会以滚动的方式选取不同的 bookie 节点进行写入:

这种写入方式称为「条带化写入」,既实现了数据的冗余存储,又使得数据能够均匀分布在多个 bookie 存储节点上,从而避免数据倾斜某个存储节点压力过大。
因为节点对等,所以 bookie 节点可以进行快速故障恢复和扩容。
比方说entry0 ~ entry99都成功写入到了bookie1, bookie2, bookie3中,写entry100时bookie2突然坏掉了,那么直接加入一个新的bookie4节点接替bookie2的工作就行了。
那肯定有读者疑惑,新增进来的bookie4难道不需要先复制bookie2的数据吗(像 Kafka broker 节点那样)?
主从复制的架构才需要数据复制,因为从节点必须保证和主节点完全相同,以便随时接替主节点。而节点对等的架构是不需要数据复制的。
Bookkeeper 中维护了类似这样的一组元数据:
[bookie1, bookie2, bookie3], 0
[bookie1, bookie3, bookie4], 100
这组元数据的含义是:entry0 ~ entry99都写到了bookie1, bookie2, bookie3中,entry100及之后的消息都写到了bookie1, bookie3, bookie4中。
有了这组元数据,我们就能知道每条 entry 具体存在那些 bookie 节点里面,即便bookie2节点坏了,这不是还有bookie1, bookie3节点可以读取嘛。
扩容也是类似的,可以直接添加新的 bookie 节点增加存储能力,完全不需要数据复制。
对比来看,Kafka 是以 partition 为单位存储在 broker 中的:
Bookkeeper 这边压根没有 partition 的概念,而是以 entry(消息)为单位进行存储,某个 partition 中的数据会被打散在多个 bookie 节点中:

PS:不用担心,每个 entry 中会存储 partition 的信息,所以我们能够筛选出属于某个 partition 的所有消息。
一个叫 Jack Vanlightly 的技术大佬画了张图形象对比了 Kafka 和 Bookkeeper 进行扩容的场景:

接下来看看 Bookkeeper 如何保证高性能和数据可靠性。
读写隔离
bookie 节点实现读写隔离,自己维护缓存,不再依赖操作系统的 Page Cache,保证了数据可靠性和高性能。
之前说到 Kafka 完全依赖 Page Cache 产生的一些问题,而 Bookkeeper 集群中的 bookie 存储节点采用了读写隔离的架构:
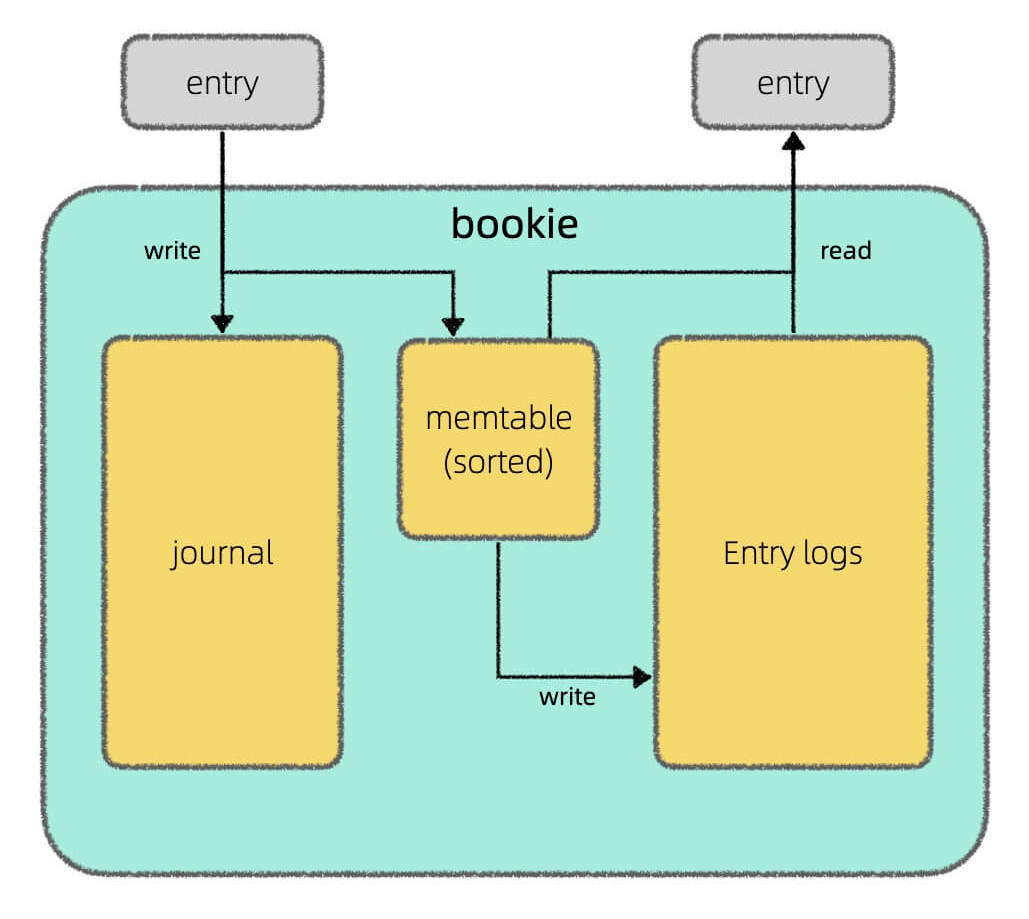
每个 bookie 节点都拥有两块磁盘,其中 Journal 磁盘专门用于写入数据,Entry Log 磁盘专门用于读取数据,而 memtable 是 bookie 节点自行维护的读写缓存。
其中 Journal 盘的写入不依赖 Page Cache,直接强制刷盘(可配置),写入完成后 bookie 节点就会返回 ACK 写入成功。
写 Journal 盘的同时,数据还会在 memotable 缓存中写一份,memotable 会对数据进行排序,一段时间后刷入 Entry Log 盘。
这样不仅多了一层缓存,而且 Entry Log 盘中的数据有一定的有序性,在读取数据时可以一定程度上提高性能。
这样设计的缺点是一份数据要存两次,消耗磁盘空间,但优势也很明显:
1、保证可靠性,不会丢数据。因为 Journal 落盘后才判定为写入成功,那么即使机器断电,数据也不会丢失。
2、数据读写不依赖操作系统的 Page Cache,即便读写压力较大,也可以保证稳定的性能。
3、可以灵活配置。因为 Journal 盘的数据可以定时迁出,所以可以采用存储空间较小但写入速度快的存储设备来提高写入性能。
总结
以上介绍了 Kafka 的架构及痛点,并介绍了 Pulsar 是如何在架构层面解决 Kafka 的不足的。当然,以上只是 Pulsar 的大体设计,具体到实现必然有很多细节和难点,不是一篇文章能讲完的,后续我还会分享我的学习经验。
哦,我才想起本文的标题是重构 Kafka,都写到这里了还重构个什么劲,直接用 Pulsar 吧。Pulsar 官网提供了 Kafka 的迁移方案,能够最小化改动代码完成迁移。
Pulsar 还有很多优秀特性,比如多租户、跨地域复制等企业级特性,比如更灵活的消费模型,比如批流融合的尝试等等,这些特性可以查看 Pulsar 的官网:
更多硬核内容和工程实践参见 Pulsar 的官方公众号「Apache Pulsar」。
更多高质量干货文章,请关注我的微信公众号:labuladong

