

《深入理解RocketMQ》- MQ消息的投递机制(转)
转自 https://blog.csdn.net/luanlouis/article/details/91368332
0. 前言
RocketMQ的消息投递分分为两种:一种是生产者往MQ Broker中投递;另外一种则是MQ broker 往消费者 投递(这种投递的说法是从消息传递的角度阐述的,实际上底层是消费者从MQ broker 中Pull拉取的)。本文将从模型的角度来阐述这两种机制。
1. RocketMQ的消息模型
RocketMQ 的消息模型整体并不复杂,如下图所示:

一个Topic(消息主题)可能对应多个实际的消息队列(MessgeQueue)
在底层实现上,为了提高MQ的可用性和灵活性,一个Topic在实际存储的过程中,采用了多队列的方式,具体形式如上图所示。每个消息队列在使用中应当保证先入先出(FIFO,First In First Out)的方式进行消费。
那么,基于这种模型,就会引申出两个问题:
- 生产者 在发送相同Topic的消息时,消息体应当被放置到哪一个消息队列(MessageQueue)中?
- 消费者 在消费消息时,应当从哪些消息队列中拉取消息?
消息的系统间传递时,会跨越不同的网络载体,这会导致消息的传播无法保证其有序请
2. 生产者(Producer)投递消息的策略
2.1 默认投递方式:基于Queue队列轮询算法投递
默认情况下,采用了最简单的轮询算法,这种算法有个很好的特性就是,保证每一个Queue队列的消息投递数量尽可能均匀,算法如下图所示:
/**
* 根据 TopicPublishInfo Topic发布信息对象中维护的index,每次选择队列时,都会递增
* 然后根据 index % queueSize 进行取余,达到轮询的效果
*
*/
public MessageQueue selectOneMessageQueue(final TopicPublishInfo tpInfo, final String lastBrokerName) {
return tpInfo.selectOneMessageQueue(lastBrokerName);
}
/**
* TopicPublishInfo Topic发布信息对象中
*/
public class TopicPublishInfo {
//基于线程上下文的计数递增,用于轮询目的
private volatile ThreadLocalIndex sendWhichQueue = new ThreadLocalIndex();
public MessageQueue selectOneMessageQueue(final String lastBrokerName) {
if (lastBrokerName == null) {
return selectOneMessageQueue();
} else {
int index = this.sendWhichQueue.getAndIncrement();
for (int i = 0; i < this.messageQueueList.size(); i++) {
//轮询计算
int pos = Math.abs(index++) % this.messageQueueList.size();
if (pos < 0)
pos = 0;
MessageQueue mq = this.messageQueueList.get(pos);
if (!mq.getBrokerName().equals(lastBrokerName)) {
return mq;
}
}
return selectOneMessageQueue();
}
}
public MessageQueue selectOneMessageQueue() {
int index = this.sendWhichQueue.getAndIncrement();
int pos = Math.abs(index) % this.messageQueueList.size();
if (pos < 0)
pos = 0;
return this.messageQueueList.get(pos);
}
}
2.2 默认投递方式的增强:基于Queue队列轮询算法和消息投递延迟最小的策略投递
默认的投递方式比较简单,但是也暴露了一个问题,就是有些Queue队列可能由于自身数量积压等原因,可能在投递的过程比较长,对于这样的Queue队列会影响后续投递的效果。
基于这种现象,RocketMQ在每发送一个MQ消息后,都会统计一下消息投递的时间延迟,根据这个时间延迟,可以知道往哪些Queue队列投递的速度快。
在这种场景下,会优先使用消息投递延迟最小的策略,如果没有生效,再使用Queue队列轮询的方式。
public class MQFaultStrategy {
/**
* 根据 TopicPublishInfo 内部维护的index,在每次操作时,都会递增,
* 然后根据 index % queueList.size(),使用了轮询的基础算法
*
*/
public MessageQueue selectOneMessageQueue(final TopicPublishInfo tpInfo, final String lastBrokerName) {
if (this.sendLatencyFaultEnable) {
try {
// 从queueid 为 0 开始,依次验证broker 是否有效,如果有效
int index = tpInfo.getSendWhichQueue().getAndIncrement();
for (int i = 0; i < tpInfo.getMessageQueueList().size(); i++) {
//基于index和队列数量取余,确定位置
int pos = Math.abs(index++) % tpInfo.getMessageQueueList().size();
if (pos < 0)
pos = 0;
MessageQueue mq = tpInfo.getMessageQueueList().get(pos);
if (latencyFaultTolerance.isAvailable(mq.getBrokerName())) {
if (null == lastBrokerName || mq.getBrokerName().equals(lastBrokerName))
return mq;
}
}
// 从延迟容错broker列表中挑选一个容错性最好的一个 broker
final String notBestBroker = latencyFaultTolerance.pickOneAtLeast();
int writeQueueNums = tpInfo.getQueueIdByBroker(notBestBroker);
if (writeQueueNums > 0) {
// 取余挑选其中一个队列
final MessageQueue mq = tpInfo.selectOneMessageQueue();
if (notBestBroker != null) {
mq.setBrokerName(notBestBroker);
mq.setQueueId(tpInfo.getSendWhichQueue().getAndIncrement() % writeQueueNums);
}
return mq;
} else {
latencyFaultTolerance.remove(notBestBroker);
}
} catch (Exception e) {
log.error("Error occurred when selecting message queue", e);
}
// 取余挑选其中一个队列
return tpInfo.selectOneMessageQueue();
}
return tpInfo.selectOneMessageQueue(lastBrokerName);
}
}
2.3 顺序消息的投递方式
上述两种投递方式属于对消息投递的时序性没有要求的场景,这种投递的速度和效率比较高。而在有些场景下,需要保证同类型消息投递和消费的顺序性。
例如,假设现在有TOPIC TOPIC_SALE_ORDER,该 Topic下有4个Queue队列,该Topic用于传递订单的状态变迁,假设订单有状态:未支付、已支付、发货中(处理中)、发货成功、发货失败。
在时序上,生产者从时序上可以生成如下几个消息:
订单T0000001:未支付 --> 订单T0000001:已支付 --> 订单T0000001:发货中(处理中) --> 订单T0000001:发货失败
消息发送到MQ中之后,可能由于轮询投递的原因,消息在MQ的存储可能如下:

这种情况下,我们希望消费者消费消息的顺序和我们发送是一致的,然而,有上述MQ的投递和消费机制,我们无法保证顺序是正确的,对于顺序异常的消息,消费者 即使有一定的状态容错,也不能完全处理好这么多种随机出现组合情况。
基于上述的情况,RockeMQ采用了这种实现方案:对于相同订单号的消息,通过一定的策略,将其放置在一个 queue队列中,然后消费者再采用一定的策略(一个线程独立处理一个queue,保证处理消息的顺序性),能够保证消费的顺序性

至于消费者是如何保证消费的顺序行的,后续再详细展开,我们先看生产者是如何能将相同订单号的消息发送到同一个queue队列的:
生产者在消息投递的过程中,使用了 MessageQueueSelector 作为队列选择的策略接口,其定义如下:
package org.apache.rocketmq.client.producer;
import java.util.List;
import org.apache.rocketmq.common.message.Message;
import org.apache.rocketmq.common.message.MessageQueue;
public interface MessageQueueSelector {
/**
* 根据消息体和参数,从一批消息队列中挑选出一个合适的消息队列
* @param mqs 待选择的MQ队列选择列表
* @param msg 待发送的消息体
* @param arg 附加参数
* @return 选择后的队列
*/
MessageQueue select(final List<MessageQueue> mqs, final Message msg, final Object arg);
}
相应地,目前RocketMQ提供了如下几种实现:
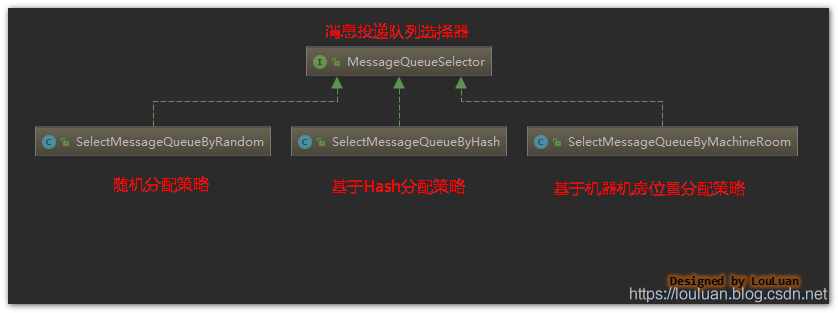
默认实现:
| 投递策略 | 策略实现类 | 说明 |
|---|---|---|
| 随机分配策略 | SelectMessageQueueByRandom | 使用了简单的随机数选择算法 |
| 基于Hash分配策略 | SelectMessageQueueByHash | 根据附加参数的Hash值,按照消息队列列表的大小取余数,得到消息队列的index |
| 基于机器机房位置分配策略 | SelectMessageQueueByMachineRoom | 开源的版本没有具体的实现,基本的目的应该是机器的就近原则分配 |
现在大概看下策略的代码实现:
public class SelectMessageQueueByHash implements MessageQueueSelector {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
int value = arg.hashCode();
if (value < 0) {
value = Math.abs(value);
}
value = value % mqs.size();
return mqs.get(value);
}
}
实际的操作代码样例如下,通过订单号作为hash运算对象,就能保证相同订单号的消息能够落在相同的queue队列上。
rocketMQTemplate.asyncSendOrderly(saleOrderTopic + ":" + tag, msg,saleOrderId /*传入订单号作为hash运算对象*/, new SendCallback() {
@Override
public void onSuccess(SendResult sendResult) {
log.info("SALE ORDER NOTIFICATION SUCCESS:{}",sendResult.getMsgId());
}
@Override
public void onException(Throwable throwable) {
//exception happens
}
});
3. 如何为消费者分配queue队列?
RocketMQ对于消费者消费消息有两种形式:
BROADCASTING:广播式消费,这种模式下,一个消息会被通知到每一个消费者CLUSTERING: 集群式消费,这种模式下,一个消息最多只会被投递到一个消费者上进行消费
模式如下:

广播式的消息模式比较简单,下面我们介绍下集群式。对于使用了消费模式为MessageModel.CLUSTERING进行消费时,需要保证一个消息在整个集群中只需要被消费一次。实际上,在RoketMQ底层,消息指定分配给消费者的实现,是通过queue队列分配给消费者的方式完成的:也就是说,消息分配的单位是消息所在的queue队列。即:
将
queue队列指定给特定的消费者后,queue队列内的所有消息将会被指定到消费者进行消费。
RocketMQ定义了策略接口AllocateMessageQueueStrategy,对于给定的消费者分组,和消息队列列表、消费者列表,当前消费者应当被分配到哪些queue队列,定义如下:
/**
* 为消费者分配queue的策略算法接口
*/
public interface AllocateMessageQueueStrategy {
/**
* Allocating by consumer id
*
* @param consumerGroup 当前 consumer群组
* @param currentCID 当前consumer id
* @param mqAll 当前topic的所有queue实例引用
* @param cidAll 当前 consumer群组下所有的consumer id set集合
* @return 根据策略给当前consumer分配的queue列表
*/
List<MessageQueue> allocate(
final String consumerGroup,
final String currentCID,
final List<MessageQueue> mqAll,
final List<String> cidAll
);
/**
* 算法名称
*
* @return The strategy name
*/
String getName();
}
相应地,RocketMQ提供了如下几种实现:

| 算法名称 | 含义 |
|---|---|
AllocateMessageQueueAveragely |
平均分配算法 |
AllocateMessageQueueAveragelyByCircle |
基于环形平均分配算法 |
AllocateMachineRoomNearby |
基于机房临近原则算法 |
AllocateMessageQueueByMachineRoom |
基于机房分配算法 |
AllocateMessageQueueConsistentHash |
基于一致性hash算法 |
AllocateMessageQueueByConfig |
基于配置分配算法 |
为了讲述清楚上述算法的基本原理,我们先假设一个例子,下面所有的算法将基于这个例子讲解。
假设当前同一个topic下有queue队列
10个,消费者共有4个,如下图所示:

下面依次介绍其原理:
3.1. AllocateMessageQueueAveragely- 平均分配算法
这里所谓的平均分配算法,并不是指的严格意义上的完全平均,如上面的例子中,10个queue,而消费者只有4个,无法是整除关系,除了整除之外的多出来的queue,将依次根据消费者的顺序均摊。
按照上述例子来看,10/4=2,即表示每个消费者平均均摊2个queue;而10%4=2,即除了均摊之外,多出来2个queue还没有分配,那么,根据消费者的顺序consumer-1、consumer-2、consumer-3、consumer-4,则多出来的2个queue将分别给consumer-1和consumer-2。最终,分摊关系如下:
consumer-1:3个;consumer-2:3个;consumer-3:2个;consumer-4:2个,如下图所示:

其代码实现非常简单:
public class AllocateMessageQueueAveragely implements AllocateMessageQueueStrategy {
private final InternalLogger log = ClientLogger.getLog();
@Override
public List<MessageQueue> allocate(String consumerGroup, String currentCID, List<MessageQueue> mqAll,
List<String> cidAll) {
if (currentCID == null || currentCID.length() < 1) {
throw new IllegalArgumentException("currentCID is empty");
}
if (mqAll == null || mqAll.isEmpty()) {
throw new IllegalArgumentException("mqAll is null or mqAll empty");
}
if (cidAll == null || cidAll.isEmpty()) {
throw new IllegalArgumentException("cidAll is null or cidAll empty");
}
List<MessageQueue> result = new ArrayList<MessageQueue>();
if (!cidAll.contains(currentCID)) {
log.info("[BUG] ConsumerGroup: {} The consumerId: {} not in cidAll: {}",
consumerGroup,
currentCID,
cidAll);
return result;
}
int index = cidAll.indexOf(currentCID);
int mod = mqAll.size() % cidAll.size();
int averageSize =
mqAll.size() <= cidAll.size() ? 1 : (mod > 0 && index < mod ? mqAll.size() / cidAll.size()
+ 1 : mqAll.size() / cidAll.size());
int startIndex = (mod > 0 && index < mod) ? index * averageSize : index * averageSize + mod;
int range = Math.min(averageSize, mqAll.size() - startIndex);
for (int i = 0; i < range; i++) {
result.add(mqAll.get((startIndex + i) % mqAll.size()));
}
return result;
}
@Override
public String getName() {