百度2020校招Java研发工程师笔试卷(第一批)详解
第一题:关于内存管理,下面说法不正确的是?

答案:A、C
程序的内存不一定都是从0开始。 线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。
内存管理分段与分页:https://blog.csdn.net/weixin_44151739/article/details/108416656
第二题:下列关于图的说法正确的是()
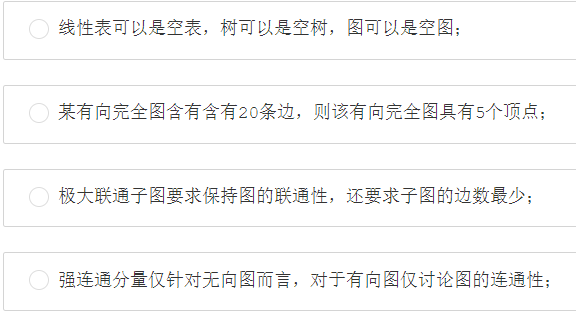
答案:B
图不可以是空图。
给定子图的边的结合E',定点的集合V',子图 G'=(V',E'),在上述条件基础之下 极小连通子图: 用最少的边使顶点连通 极大连通子图: 用最多的边使顶点连通
在有向图G中,如果两个顶点u,v间有一条从u到v的有向路径,同时还有一条从v到u的有向路径,则称两个顶点强连通。如果有向图G的每两个顶点都强连通,称G是一个强连通图。有向非强连通图的极大强连通子图,称为强连通分量。
第三题:设无向图G=(V,E),顶点集V={a,b,c,d,e,f,g,h},边集E={(a,b),(a,h),(a,e),(b,c),(b,d),(c,d),(c,h),(e,f),(e,g)},则下列选项中,不属于BFS序列的是()
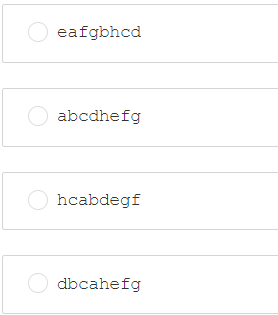
答案:B
BFS遍历
第四题:分页存储管理将进程的逻辑地址空间分成若干个页,并为各页加以编号,从0开始,若某一计算机主存按字节编址,逻辑地址和物理地址都是32位,页表项大小为4字节,若使用一级页表的分页存储管理方式,逻辑地址结构为页号(20位),页内偏移量(12位),则页的大小是( )字节?页表最大占用( )字节?
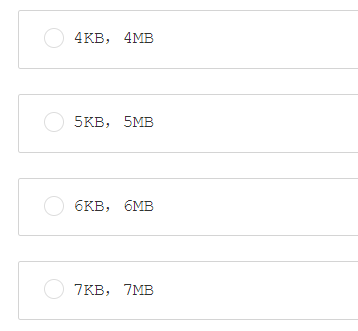
答案:A
参考博客:https://blog.csdn.net/syh666233/article/details/109295815
第五题:有以下程序段,下面正确的选项是
public static void main(String[] args) {
System.out.print(test1());
}
public static int test1() {
int a = 20;
try {
return a + 25;
} catch (Exception e) {
System.out.println("test catch exception");
} finally {
System.out.print(a + " ");
a = a + 10;
}
return a;
}

答案:D
finally语句在return之前执行。
参考博客:https://blog.csdn.net/congduan/article/details/48275473
第六题:下列选项中,关于HTTP与HTTPS的区别的描述中,正确的是( ):

答案:A、B、C
http:80;https:443
第七题:线程池在我们的项目中经常会被用到,线程池的选择基于我们的应用场景,那么现在有这样一个应用场景:需要周期性的执行任务,那么我们应该选择哪一个线程池()
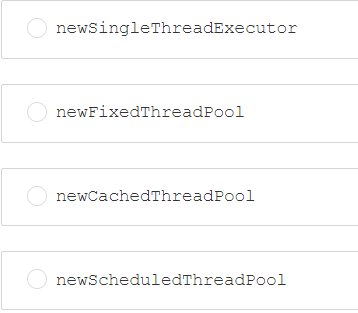
答案:D
第八题:小牛开发文件上传功能时,遇到了一些安全问题,那么对于文件上传漏洞,有效防御手段有哪些?

答案:B、C
第九题:用下面哪些SQL语句可以从table中得到每门课都大于80分的学生姓名,下面说法正确的的?

答案:A、D
第十题:以下代码运行的结果是什么
public class TestGC {
private static TestGC TEST_GC = null;
private void isAlive() {
System.out.print("Yes,I'm Alive!" + "、");
}
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.print("finalize mehtod executed!" + "、");
TestGC.TEST_GC = this;
}
public static void main(String[] args) throws Throwable {
TEST_GC = new TestGC();
TEST_GC = null;
System.gc();
Thread.sleep(500);
if (TEST_GC != null) {
TEST_GC.isAlive();
} else {
System.out.print("NO,I'm dead!" + "、");
}
TEST_GC = null;
System.gc();
Thread.sleep(500);
if (TEST_GC != null) {
TEST_GC.isAlive();
} else {
System.out.print("NO,I'm dead!");
}
}
}

答案:A
finalize()只会在对象内存回收前被调用一次
参考博客:https://blog.csdn.net/a4171175/article/details/90749839
第十一题:对于java集合HashMap中的containsKey()方法,最好情况和最坏情况下的时间复杂度是
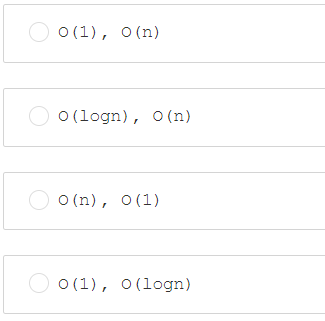
答案:A(JAVA1.8之前最坏情况是O(n),之后是O(logn))
在JDK1.7及之前,是用数组加链表的方式存储的。
但是,众所周知,当链表的长度特别长的时候,查询效率将直线下降,查询的时间复杂度为 O(n)。因此,JDK1.8 把它设计为达到一个特定的阈值之后,就将链表转化为红黑树。
参考博客:https://zhuanlan.zhihu.com/p/129724004
第十二题:以下代码运行后会打印哪些内容
public class Test implements Runnable {
@Override
public void run() {
while (!Thread.currentThread().isInterrupted()) {
synchronized (this) {
try {
wait();
} catch (InterruptedException e) {
System.out.println("InterruptedException");
}
}
}
System.out.println("Final");
}
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new Test());
thread.start();
new Thread(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
thread.interrupt();
System.out.println("interrupt");
}).start();
thread.join();
System.out.println("exit");
}
}

答案:A
参考博客:https://www.jianshu.com/p/d901b25e0d4a
第十三题:假设存在学生信息表student,选修课表course,如果想查询所有学生的选修课以及成绩,下面正确的sql语句是:
create table `student`(
`id` int(11) not null auto_increment,
`name` char(50) not null comment '学生姓名',
`sid` int(11) not null comment '学号',
primary key(`id`),
unique key `sid`(`sid`)
)engine = innodb;
create table `course`(
`id` int(11) not null auto_increment,
`name` char(50) not null comment '课程名称',
`score` int(11) not null comment '成绩',
`sid` int(11) not null comment '学号',
primary key(`id`)
)engine = innodb;

答案:C、D
mysql cross join为笛卡尔全连接,inner join即为join
- JOIN: 如果表中有至少一个匹配,则返回行
- LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN: 只要其中一个表中存在匹配,就返回行
参考博客:https://www.cnblogs.com/poloyy/p/12881918.html
第十四题:假如公司机房现在有n个服务器,为了方便用户会在服务器上缓存数据,因此用户每次访问的时候最好能保持同一台服务器,现有的做法是根据服务器的ip%n计算得到请求的服务器,如果现在一台服务器挂掉了,采用以下哪种做法(),能够保证不会造成大面积的访问错误;原有的访问基本还是停留在同一台服务器上;尽量考虑负载均衡。

答案:A
参考博客:https://blog.csdn.net/caigen1988/article/details/7708806?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.base&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.base
第十五题:将一个整数序列整理为降序,两趟处理后序列变为{36, 31, 29, 14, 18, 19, 32}则采用的排序算法可能是________。
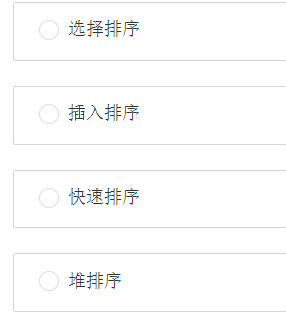
答案:B
冒泡:i*j 两两比较,小的放前
选择:i*j两两比较,遍历j后,找到最小的放前面
插入:默认第一个排好序(只有一个,也没得比较),第一步:第二个与第一个比较排序;第二步:第三个插入前面排好序的序列;第三步,第四个插入前面的序列,以此类推
希尔:类似插入排序,但第一步:分i//2堆(随机分配)同步进行插入排序(第一堆排完,再第二堆,再第三堆…);第二步:分i//4堆依次排;…最后一步:一整堆进行插入排序,耗时i;
归并:分而治之,dynamic programming
快排:定义分区函数,主函数递归排序
堆排:建立二叉树,树内排序,找到最大值取出,更新树,再取出第二大的数…以此类推
计数:不用比较,牺牲空间换时间,开辟key为min到max的数组,遍历原序列,统计数的个数;再对key按顺序输出即可。
桶排:计数排序的升级,计数用了max-min+1个桶,桶排序用k个桶(数量更少),桶内排好序(用传统方法,或递归用桶排),再对桶按顺序输出即可。
基数:同样基于计数排序,先按个位数入列(0-9个列),排好第一步;再按十位数入列,排好第二步;…依次到最大位数入列,排好输出即可。
分析
插入排序:第n趟前n+1个有序
选择排序:第n趟前n个位置正确
快速排序:第n趟有n个元素位置正确
堆排序:第n趟前或后n个位置正确
参考博客:https://blog.csdn.net/xxxxl0908/article/details/104702991/
第十六题:
数据结构中,二分法的查找主要应用于数据量较大情况下的查找,但是数据需要先排好顺序,在顺序表(2,5,7,10,14,15,18,23,35,41,52)中,用二分法查找12,所需的关键码比较的次数为多少( )?
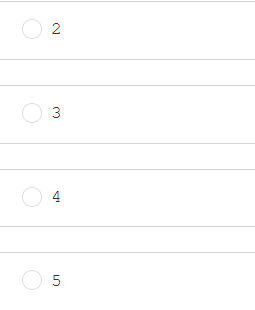
答案:C
二分比较次数
第十七题:设a数组的长度为N,那么下面程序循环内交换数组元素的代码执行的时间复杂度最坏为?
for (int i = N - 1; i > 1; i--)
{
for (int j = 1; j < i; j++)
{
if (a[j] > a[j + 1])
{
temp = a[j + 1];
a[j + 1] = a[j];
a[j] = temp;
}
}
}
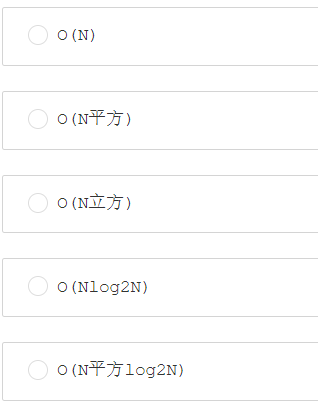
答案:B
选择排序时间复杂度
第十八题:
如果存储结构由数组变为链表,那么下列哪些算法的时间复杂度量级会升高
答案:B、C
希尔排序、堆排序使用数组存储的话,方便获取指定位置的数据。这两个排序都需取指定位置的数据,而使用链表增加了获取指定位置的时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号