XCTF robots
一.进入实验环境
二.根据题目的提示,可以猜测这道题和robots协议有关。
1.什么是robots协议?
robots协议也叫robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络蜘蛛),此网站中的哪些内容是不应 被搜索引擎的漫游器获取的,哪些是可以被漫游器获取的。因为一些系统中的URL是大小写敏感的,所以robots.txt的文件名应统一为小写。robots.txt应放置于网站的根目录下。 如果想单独定义搜索引擎的漫游器访问子目录时的行为,那么可以将自定的设置合并到根目录下的robots.txt,或者使用robots元数据(Metadata,又称元数据)。
robots协议并不是一个规范,而只是约定俗成的,所以并不能保证网站的隐私。
2.文件的写法。
User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符
Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录
Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录
Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录
Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。
Disallow: /*?* 禁止访问网站中所有包含问号 (?) 的网址
Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片
Disallow:/ab/adc.html 禁止爬取ab文件夹下面的adc.html文件。
Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录
Allow: /tmp 这里定义是允许爬寻tmp的整个目录
Allow: .htm$ 仅允许访问以".htm"为后缀的URL。
Allow: .gif$ 允许抓取网页和gif格式图片
Sitemap: 网站地图 告诉爬虫这个页面是网站地图
3.位置。
robots.txt文件应该放置在网站根目录下。举例来说,当spider访问一个网站时,首先会检查该网站中是否存在robots.txt这个文件,如果 Spider找到这个文件,它就会根据这个文 件的内容,来确定它访问权限的范围。
三.实验步骤
做法一:
访问robots.txt文件
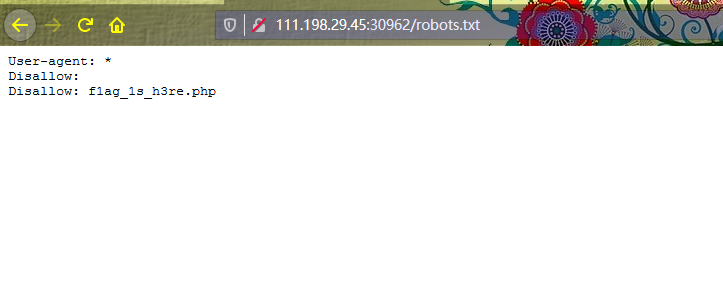
根据robots.txt里的内容我们发现有一个为f1ag_1s_h3re.php的文件,这个可能和我们要找的flag有关,我们尝试访问一下。
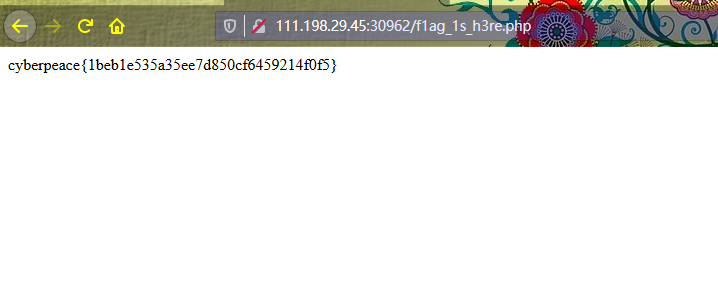
获得flag。
做法二:
使用dirsearch工具(一个基于python的命令行工具,旨在暴力扫描页面结构,包括网页中的目录和文件。)
在cmd里进入dirsearch目录中 使用命令 python dirsearch.py -u http://10.10.10.175:32793/ -e *,扫描结束后发现robots.txt
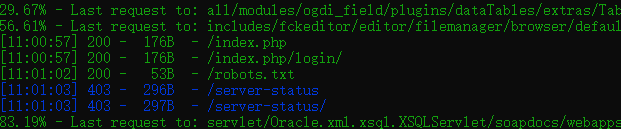
后面的步骤和做法一一致。
趁着年轻,多学些

 浙公网安备 33010602011771号
浙公网安备 33010602011771号