

scrapy框架初识
什么是框架
其实就是一个具有很强通用性且集成了很多功能的项目模板
如何学习框架
掌握框架的功能,可以熟练使用每一种功能即可
爬虫框架--scrapy框架:
在爬虫中集成了异步,高性能的数据解析,高性能的持久化存储.....
scrapy环境的安装:

a. pip3 install wheel b. 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted c. 进入下载目录,执行 pip3 install Twisted‑17.1.0‑cp35‑cp35m‑win_amd64.whl d. pip3 install pywin32 e. pip3 install scrapy
测试:在终端中录入scrapy 如果没有报错就是安装的没有问题
a.打开cmd窗口 对a进行操作 安装wheel
b.下载twisted 链接:www.lfd.uci.edu/~gohlke/pythonlibs/#twisted

c.进入下载twisted的目录,点击shift+右键 打开powershell窗口 在powershell窗口里面输入 pip install .\Twisted-18.9.0-cp36-cp36m-win_amd64.whl

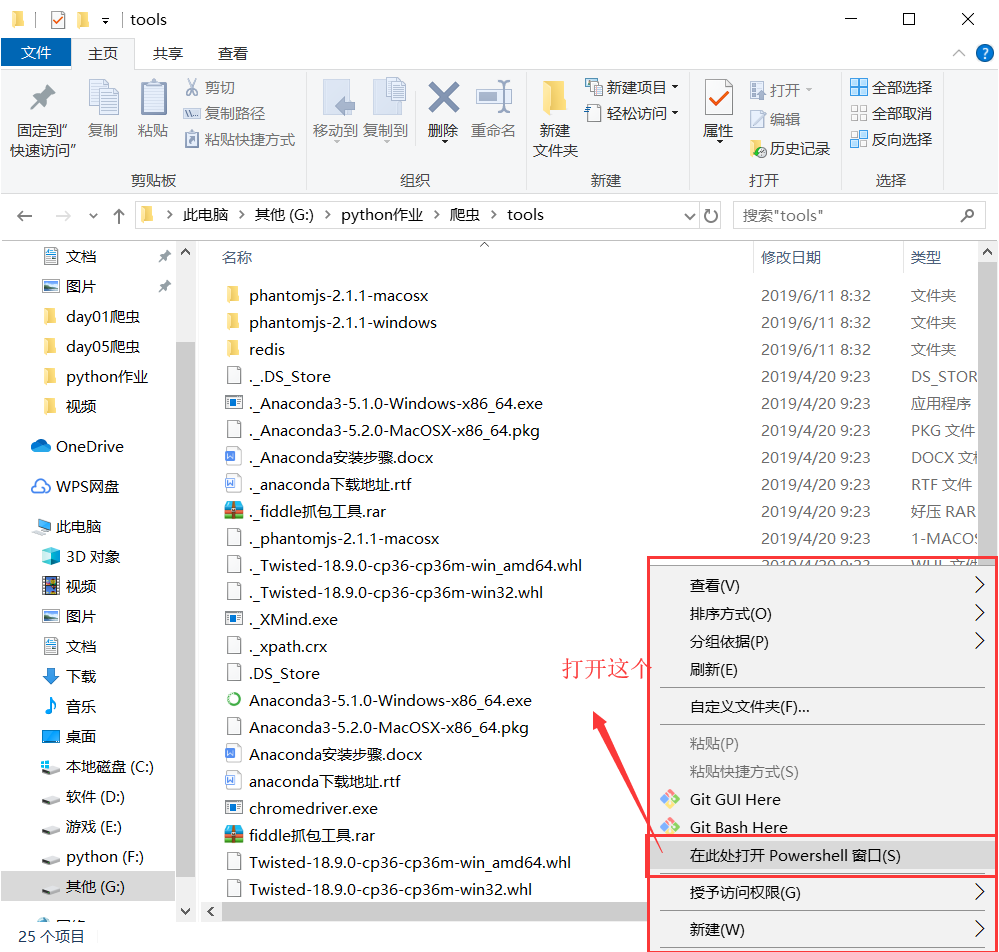

d.e.在powershell窗口输入 pip3 install pywin32 pip3 install scrapy 对着两个插件进行安装
a.b.c.d.e步骤都完成后 在窗口界面输入scrapy 如果没有报错 就是安装完成
scrapy的使用流程:
-1. 创建一个工程:scrapy startproject ProName -2.cd ProName
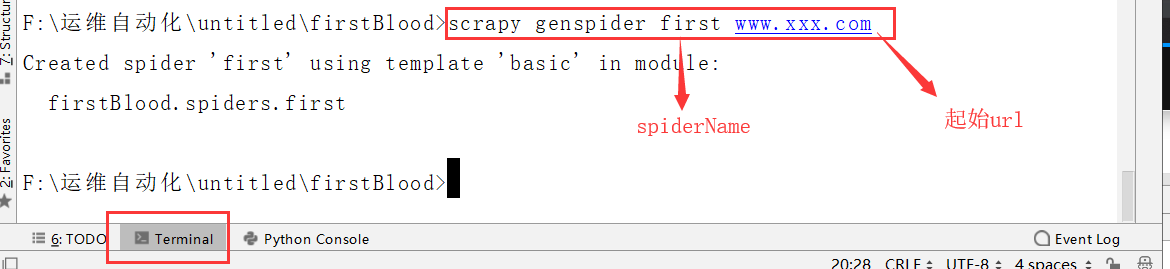
-3. 创建一个爬虫文件:scrapy genspider spiderName www.xxx.com
- settings.py里面设置ROBOTSTXT_OBEY = False
-4. 执行工程:scrapy crawl spiderName
-去除日志:scrapy crawl spidername --nolog
-只显示错误日志 在settings.便宜文件中增加 LOG_LEVEL = 'ERROR' 这句话后就只显示错误日志,其他日志不显示
-settings.py文件中的USER_AGENTE 可以做UA伪装
数据解析在paras下 response.xpath() 通过scrapy封装的xpath来解析
1.打开pycham,创建一个工程
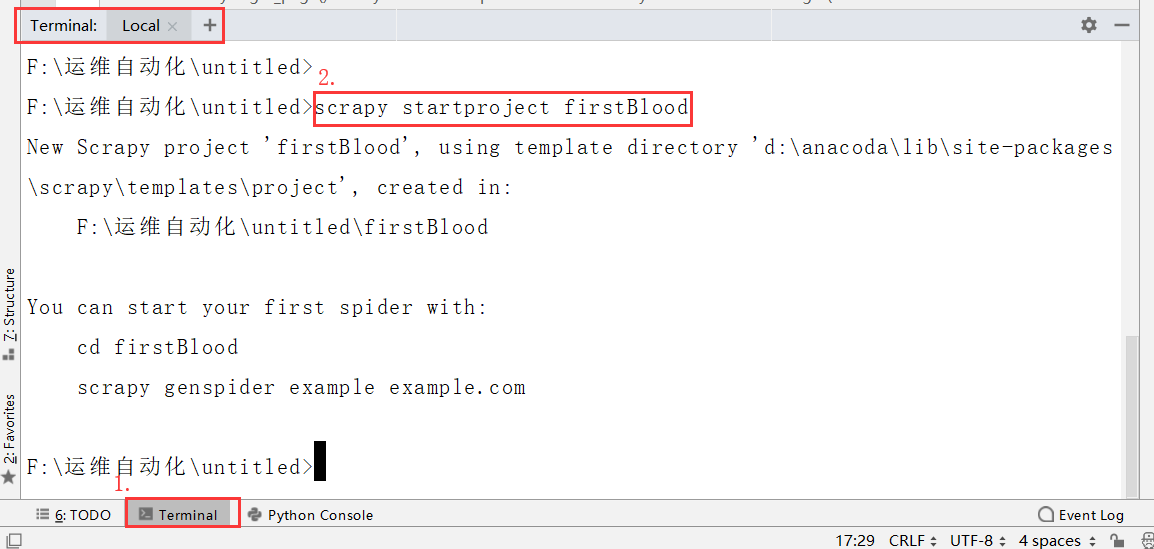
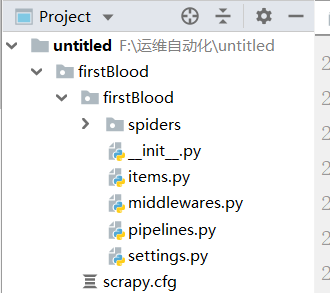
2.cd到工程目录下面
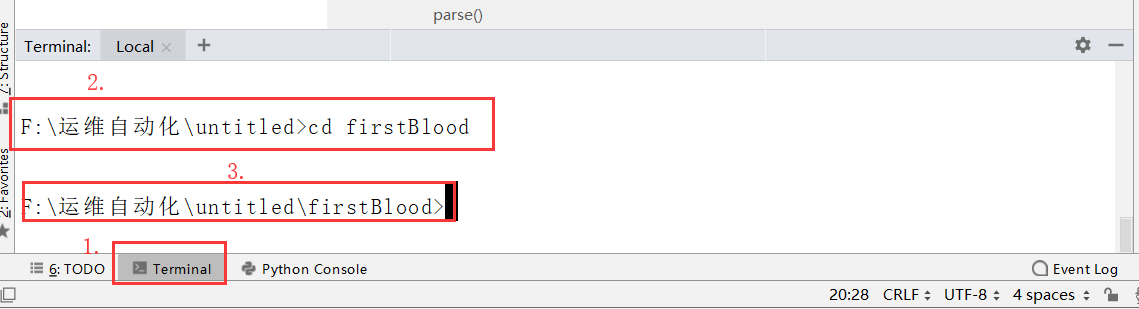
3.创建一个爬虫文件
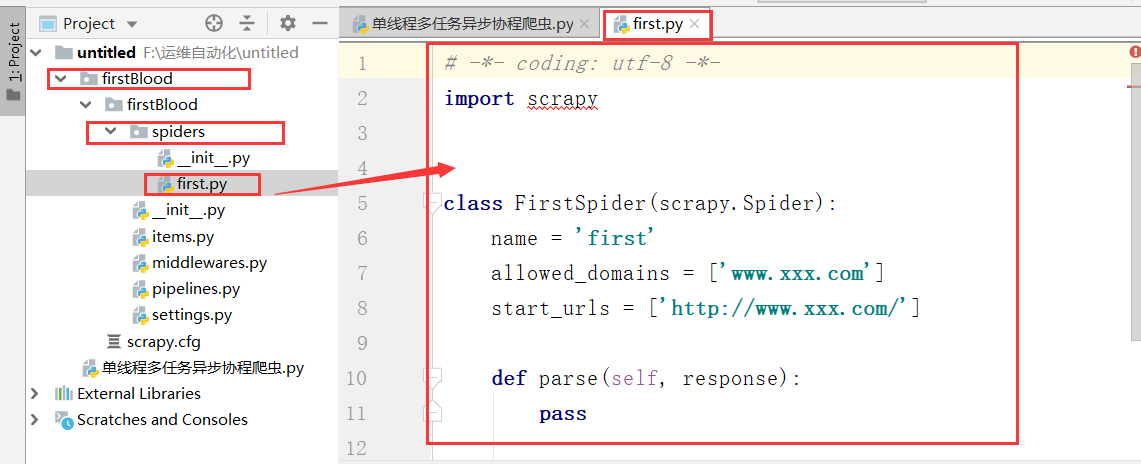
# -*- coding: utf-8 -*- import scrapy class FirstSpider(scrapy.Spider): #爬虫文件的名称:爬虫文件的唯一标识 name = 'first' #允许的域名,这里会限定起始url列表的url,这里一般都会注释掉: # allowed_domains = ['www.baidu.com'] #起始的url列表:列表中存放的url都会被scrapy进行自动的请求发送 start_urls = ['https://www.baidu.com/','https://www.xxfgfhfghfg.com'] #是用来解析起始的url列表返回的响应数据 def parse(self, response): print(response.text) response.xpath('fdsfds')
4.执行工程:scrapy crawl spiderName
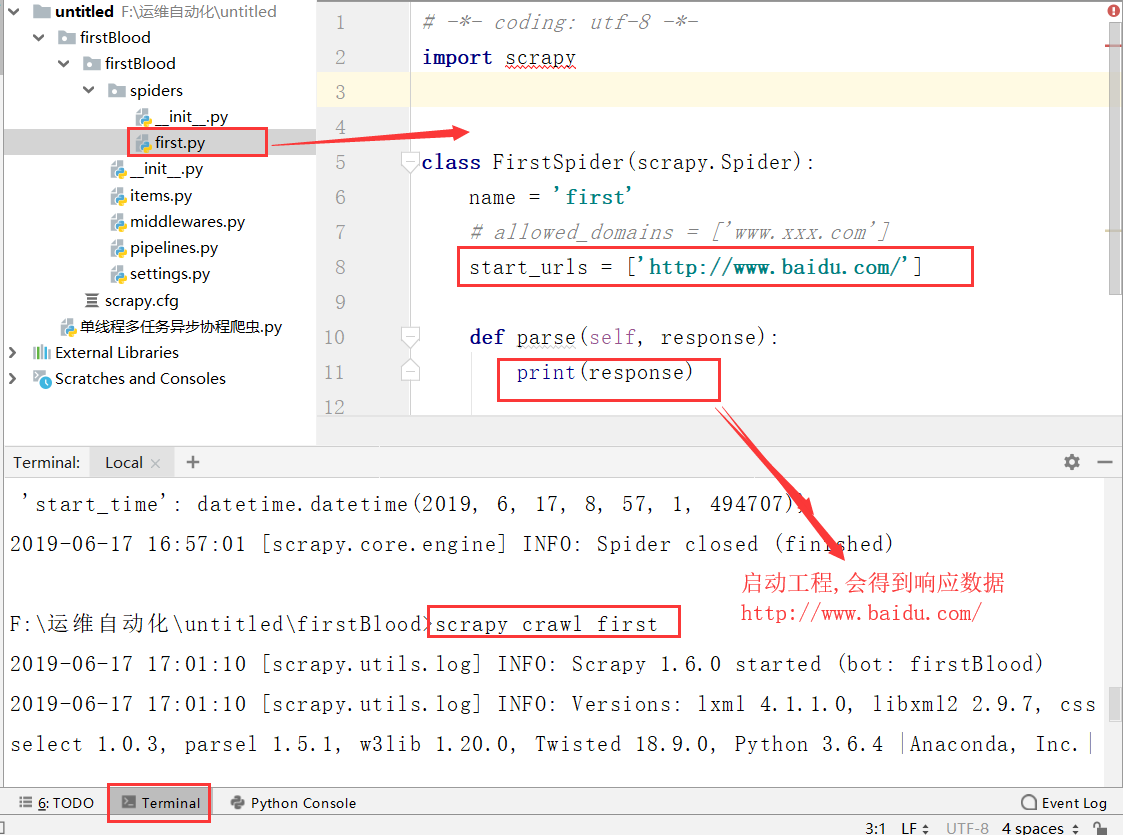
settings里面的设置
#只显示错误日志 - LOG_LEVEL = 'ERROR' #item的管道设置 - ITEM_PIPELINES = { 'qiubaiByPages.pipelines.QiubaibypagesPipeline': 300, } #反爬机制 - ROBOTSTXT_OBEY = False #UA检测 - USER_AGENT = 'Mozil'

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步