


elastic search(以下简称es)
参考博客园https://www.cnblogs.com/Neeo/p/10304892.html#more
如何学好elasticsearch
除了万能的百度和Google 之外,我们还有一些其他的学习途径:
- elasticsearch官方文档:这个比较好点,可以多多参考
- elasticsearch博客:这个吧,看看就行
- elasticsearch社区:社区还是很好的
- elasticsearch视频:包括入门视频什么的
- elasticsearch实战:该书籍的质量还是不错的。
- elasticsearch权威指南:同样的,这个也不错。
正式开始学习elasticsearch之前,需要先打开软件elaction search和kibana,然后在浏览器上输入网址127.0.0.1:5601,就进入kibana,点击Dev Tools就可以进去对elasticsearch进行操作了

1.elastic search(以下简称es)是什么?
es是基于Apache Lucene的开源分布式(全文)搜索引擎,,提供简单的RESTful API来隐藏Lucene的复杂性。
es除了全文搜索引擎之外,还可以这样描述它:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 分布式的实时分析搜索引擎
- 可以扩展到成百上千台服务器,处理PB级结构化或非结构化数据。
-elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档
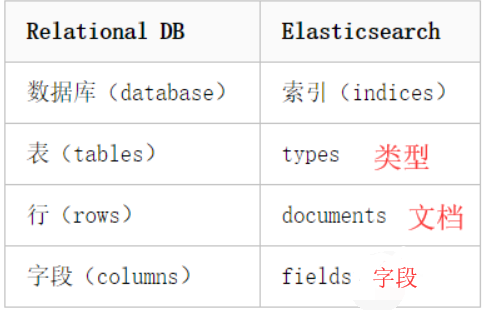
2.es的数据结构 1.索引 2.类型 3.文档 4.字段
和mysql比较如下
3.索引
elasticsearch使用的是一种称为倒排索引的结构,采用Lucene倒排索作为底层。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。
倒排索引实例如下:
| 原始数据 | 索引列表(倒排索引) | ||
| id | 标签 | 标签 | 索引结果 |
| 1 | python | python | 1,2,3 |
| 2 | python | linux | 3,4 |
| 3 | linux,python | ||
| 4 | linux | ||
4.es的增删改查
改(覆盖)/增:PUT(不存在就创建,存在就更新)
改:POST (按指定字段更改)
删:DELETE
查:GET
示例如下:

#增/改 PUT s/doc/1 { "name":"大刀" } #查 GET s/doc/1 { "name":"大刀" } #删除指定文档 DELETE s/doc/1 { "name":"大刀" }
#删除索引
DELETE S
查询的几种方法
GET s/doc/1 # 查看指定文档 GET s/doc/_search # 查看索引中的所有文档 GET s/doc/_search?q=name:大刀 # 按条件查询
GET s/_mapping # 查看索引的映射类型
GET s/_settings # 查看索引的设置信息
GET s # 查看索引的详情
以下操作按下表进行操作
PUT s/doc/1 { "name":"1x", "age":18, "sex":"男", "decs":"篮球" } PUT s/doc/2 { "name":"2x", "age":"22", "sex":"女", "decs":"足球" } PUT s/doc/3 { "name":"3x", "age":"35", "sex":"男", "decs":"排球" } PUT s/doc/4 { "name":"4x", "age":"48", "sex":"男", "decs":"乒乓球" } PUT s/doc/5 { "name":"5x", "age":"65", "sex":"男", "decs":"羽毛球" }
一.查询
1.查询索引的所有文档 GET s/doc/_search
2.按字段查询 GET s/doc/_search?q=name:1x
3.修改指定字段使用POST
POST s/doc/5/_update
{
"doc":{
"age":75
}
}
4.查询字符串
GET s/doc/_search
{
"query": {
"match": {
"age": "18"
}
}
}
5.多个字段一起查询
GET s/doc/_search
{
"query": {
"match": {
"decs": "篮球 足球" #这里不能用[]扩起来,只能用一个" "将要查询的字段都扩起来,否则会报错
}
}
}
6.查询所有
GET s/doc/_search
{
"query": {
"match_all": {}
}
}
二.排序 sort 不是所有的字段都能排序
1.降序 desc
#降序
GET s/doc/_search #sort和query平级
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
2.升序 asc
#升序
GET s/doc/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "asc"
}
}
]
}
三.分页查询 from/size
GET s/doc/_search
{
"query": {
"match_all": {}
}
, "sort": [
{
"age": {
"order": "asc"
}
}
],
"from": 2,
"size": 2
}
#s索引按升序排列后,发布为1x,2x,3x,4x,5x,分别对应的索引为0,1,2,3,4,from:2就是从索引2 开始,size:2就是两个单位
#from表示从哪开始查询,size表示返回几条结果,
#如果超出了数据本身大小,会返回数据,不会报错
四.布尔查询 bool 1.must(and) 2.should (or) 3.must_not(not) 4.filter
#must(and)的使用
GET s/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"sex": "男"
}
}
]
}
}
}
#注意结构
GET s/doc/_search
{
"query": {
"bool": {
"must": [ #中括号,括号里面分两组,全部用{}扩起来
{
"match": {
"sex": "男"
}
},
{
"match": {
"name": "4x"
}
}
]
}
}
}
filter过滤 1.gte 大于等于 2.lte 小于等于
3.gt 大于 4.lt 小于
- filter工作于bool查询中
GET s/doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"sex": "男"
}
}
],
"filter": { #filter和must是同一级的都在bool的下一级
"range": { #filter中尽量用must,避免脏数据
"age": {
"gte": 30
}
}
}
}
}
}
五.高亮查询 highlight
改变高亮的样式
GET s/doc/_search
{
"query": {
"match": {
"name": "2x" #查询
}
},
"highlight": { #高亮highlight
"fields": { #fields
"name":{ #查询的字段
}
}
}
}
- 高亮时自定义标签
GET s/doc/_search {
"query": { "match": { "name": "2x" #查询 } },
"highlight": { #高亮highlight "pre_tags": "<b style='color:red;font-size:20px' class='xxx'>", 改变样式pre_tags 自定义标签 "post_tags": "</b>", #改变样式结束符 "fields": { "name":{} } }
} #pre_tags,post_tags,fields在同一级
对字段的某部分进行改变样式
GET s/doc/_search { "query": { "match": { "decs": "篮" } }, "highlight": { "pre_tags": "<b style='color:red;font-size:20px' class='xxx'>", "post_tags": "</b>", "fields": { "decs":{} } } }
六.查询结果过滤 _source
- 可以单独过滤出想要的字段信息,不会将符合字段的全部信息都过滤出来
#过滤结果的单个字段
GET s/doc/_search
{
"query": {
"match": {
"name": "1x"
}
},
"_source": ["name","age","decs"] #单个字段 _sourc和query同一级
}
#查询过滤结果的多个字段
GET s/doc/_search
{
"query": {
"match": {
"name": "1x"
}
},
"_source": ["name","age","decs"] #多个字段 _sourc和query同一级
}
七.聚合查询 平均值 - avg 最小值 - min 最大值 - max 求和 - sum
# sum,查询所有男生的年龄总和
GET s/doc/_search
{
"query": {
"match": {
"sex": "男"
}
},
"aggs": { #和query是同一级 必须是aggs
"my_sum": { #需要取一个名字
"sum": { #求和
"field": "age" #过滤
}
}
}
}
#注意格式
八:分组查询
GET s/doc/_search
{
"query": {
"match": {
"sex": "男"
}
},
"aggs": { #aggs
"age_group":{ #group或者group的别名age_group
"range": { #range
"field": "age", #field的参数为字段名
"ranges": [
{
"from": 10,
"to": 30
},
{
"from": 30,
"to": 50
}
]
}
}
}
}
九. 映射 mappings 自定义数据类型
参考博客:https://www.cnblogs.com/Neeo/articles/10585039.html
字段的数据类型 文本 - text 关键字 - keyword 日期 - data 整形 - long 双精度 - double 布尔 - boolean或ip
#一个low版的mappings,自定义数据结构
PUT s3
{
"mappings": {
"doc":{ 必须有类型doc
"properties":{ #properties
"name":{"type":"text"}, #自定义name的类型
"age":{"type":"long"} #自定义age的类型
}
}
}
}
#low版mappings里面加入数据
PUT s3/doc/1
{
"name":"xx",
"age":18
}
#这里还可以加入其它字段,这里的mappings的synamic的默认值是true
#正式版
PUT s3
{
"mappings" : {
"doc" : {
"properties" : {
"age" : {
"type" : "long"
},
"b" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"desc" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"sex" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"tags" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
mappings的synamic的三种状态
- true
如果dynamic的值为true,可以往索引里面添加字段,不受mappings映射的控制,可以match查到插入的数据,可以作为主字段 - false
如果dynamic的值为false,不可以往索引里面添加字段,不受mappings映射的控制,match查不到插入的数据,额外添加的字段智能作为伴随,不能作为主字段
- strict
插入数据的时候严格按照自定义的字段添加,不能额外添加,否则报错
PUT s4
{
"mappings": {
"doc":{
"dynamic": true, #dynamic必须放在properties上面
"properties":{
"name":{
"type":"text"
}
}
}
}
}
#如果dynamic的值为true,可以往索引里面添加字段,不受mappings映射的控制,可以match查到插入的数据,可以作为主字段
PUT s5
{
"mappings": {
"doc":{
"dynamic": false,
"properties":{
"name":{
"type":"text"
}
}
}
}
}
#如果dynamic的值为false,不可以往索引里面添加字段,不受mappings映射的控制,match查不到插入的数据,额外添加的字段智能作为伴随,不能作为主字段
PUT s6
{
"mappings": {
"doc":{
"dynamic":"strict",
"properties":{
"name":{
"type":"text"
}
}
}
}
}
#插入数据的时候严格按照自定义的字段添加,不能额外添加,否则报错
mappings的参数
- ignore_above
ignore_above决定添加字段的长度,如果字段的长度超过ignore_above定义的长度,在查询的时候不会被查询
PUT s7
{
"mappings": {
"doc":{
"properties":{
"title":{
"type":"keyword",
"ignore_above": 10
}
}
}
}
}
#ignore_above决定添加字段的长度
mappings的参数
- index
index为true时,插入的数据可以查询,为false时,不会为该属性创建索引,也就是说无法当做主查询条件
{
"mappings": {
"doc":{
"properties":{
"t1":{
"type":"text",
"index": true
},
"t2":{
"type":"text",
"index": false
}
}
}
}
}
#index为true时,插入的数据可以查询,为false时,不会为该属性创建索引,也就是说无法当做主查询条件
mappings的参数
- copy_to
PUT s9
{
"mappings": {
"doc":{
"properties":{
"t1":{
"type":"text",
"copy_to":"full_name"
},
"t2":{
"type":"text",
"copy_to":"full_name"
},
"full_name":{
"type":"text"
}
}
}
}
}
#添加数据时,字段的值会通过copy_to给full_name
#t1,t2的值传给了full_name,查询的时候使用full_name,节省一次循环步骤,速度快
#s9插入数据 PUT s9/doc/1 { "t1":"xxx", "t2":"ooo" } #通过t1查询数据 GET s9/doc/_search { "query": { "match": { "t1": "xxx" } } } #通过full_name查询数据 GET s9/doc/_search { "query": { "match": { "full_name": "ooo" } } }
PUT s10 { "mappings": { #mappings "doc":{ #类型必须有 "properties":{ #properties "t1":{ "type":"text", "copy_to":["f1", "f2"] }, "t2":{ "type":"text", "copy_to":["f1", "f2"] #将t1,t2的值copy_to给f1,f2 }, "f1":{ #自定义f1的数据类型,必须有 "type":"text" }, "f2":{ #自定义f2的数据类型,必须有 "type":"keyword" } } } } }
十.嵌套类型
#嵌套自定义类型
PUT w1 { "mappings": { "doc":{ #第一层类型doc "properties":{ #properties "name":{ "type":"text" }, "age":{ "type":"long" }, "info":{ #第二次类型info "properties":{ #properties "addr":{ "type":"text" }, "tel":{ "type":"long" } } } } } } } #查询w1的mappings GET w1/_mapping PUT w1/doc/1 { "name":"tom", "age":18, #给w1增加数据 "info":{ "addr":"北京", "tel":"10010" } } PUT w1/doc/2 { "name":"tom", "age":"18", #给w1增加数据 "info":{ "addr":"北京", "tel":"10010" } } GET w1/doc/2 #查询w1 GET w1/doc/_search { "query": { #查询嵌套info的值 "match": { "info.tel": "10010" } } } GET w1/doc/_search { "query": { #查询w1的值 "match": { "age": "18" } } }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· DeepSeek在M芯片Mac上本地化部署