ElasticSearch安装使用
简介
有了mysql,为什么还要用elasticsearch?
mysql更多是用来存储数据,在数据量过多的时候,使用ES来检索数据(快)。
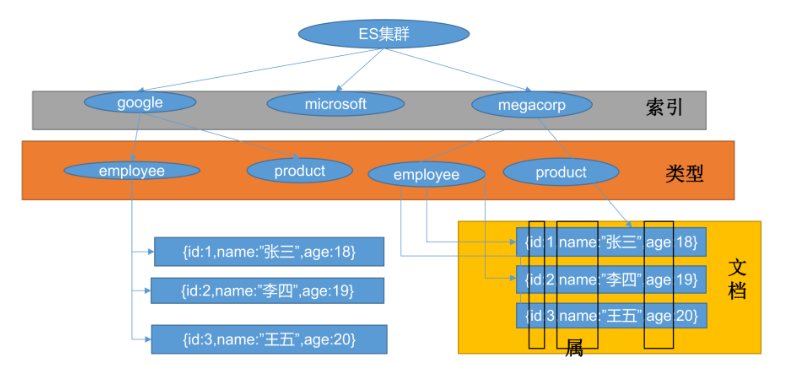
ES基本概念
Index(db库)——> type(table 表)——> document(一行数据)
ES检索数据为什么这么快
核心:倒排索引
如:保存记录
-
红海行动
-
探索红海行动
-
红海特别行动
-
红海记录片
-
特工红海特别探索
将内容分词记录到索引中
| 词 | 记录 |
|---|---|
| 红海 | 1,2,3,4,5 |
| 行动 | 1,2,3 |
| 探索 | 2,5 |
| 特别 | 3,5 |
| 纪录片 | 4, |
| 特工 | 5 |
查询红海特工行动:查出后计算相关性得分,3号记录命中了2次,且3号本身才有3个单词,2/3,所以3号最匹配。
ES安装
-
下载ES(数据存储与检索,相当于mysql),kibana(可视化检索,相当于navicat)
docker pull elasticsearch:7.17.6
docker pull kibana:7.17.6
版本要统一
-
容器配置
# 将docker里的目录挂载到linux的/mydata目录中
# 修改/mydata就可以改掉docker里的
mkdir -p /home/docker/elasticsearch/config
mkdir -p /home/docker/elasticsearch/data
# es可以被远程任何机器访问
echo "http.host: 0.0.0.0" >/home/docker/elasticsearch/config/elasticsearch.yml
# 递归更改权限,es需要访问
chmod -R 777 /home/docker/elasticsearch/
-
启动容器
# 9200是用户交互端口 9300是集群心跳端口
# -e指定是单阶段运行(单机)
# -e指定占用的内存大小,生产时可以设置32G
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /home/docker/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /home/docker/elasticsearch/data:/usr/share/elasticsearch/data \
-v /home/docker/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.17.6
# 设置开机启动elasticsearch
docker update elasticsearch --restart=always
# kibana指定了了ES交互端口9200 # 5600位kibana主页端口
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://ip:9200 -p 5601:5601 -d kibana:7.17.6
# 设置开机启动kibana
docker update kibana --restart=always
docker使用小技巧:
在启动docker容器的时候,如果容器运行不起来或者起来马上挂掉,可以查看启动日志
dockerlogs '容器id/容器name'
-
启动测试
# 查看ES是否正常启动
# 浏览器访问:http://ip:9200
{
"name": "66718a266132",
"cluster_name": "elasticsearch",
"cluster_uuid": "xhDnsLynQ3WyRdYmQk5xhQ",
"version": {
"number": "7.4.2",
"build_flavor": "default",
"build_type": "docker",
"build_hash": "2f90bbf7b93631e52bafb59b3b049cb44ec25e96",
"build_date": "2019-10-28T20:40:44.881551Z",
"build_snapshot": false,
"lucene_version": "8.2.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
# 查看kibana是否正常启动
# 浏览器访问: http://ip:5601/app/kibana
ES基础操作之批量操作——bulk
在kibana的dev tools里进行操作
POST /_bulk
{"delete":{"_index":"website","_type":"blog","_id":"123"}}
{"create":{"_index":"website","_type":"blog","_id":"123"}}
{"title":"my first blog post"}
{"index":{"_index":"website","_type":"blog"}}
{"title":"my second blog post"}
{"update":{"_index":"website","_type":"blog","_id":"123"}}
{"doc":{"title":"my updated blog post"}}
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{
"took" : 304,
"errors" : false,
"items" : [
{
"delete" : { 删除
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 1,
"result" : "not_found", 没有该记录
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 404 没有该
}
},
{
"create" : { 创建
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 2,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : { 保存
"_index" : "website",
"_type" : "blog",
"_id" : "5sKNvncBKdY1wAQmeQNo",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
},
{
"update" : { 更新
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1,
"status" : 200
}
}
]
}
ES进阶检索
es支持两种基本方式检索
-
通过
uri + 检索参数检索文档 -
通过
uri + 请求体检索文档
通过uri + 检索参数检索文档
请求示例:
GET bank/_search?q=*&sort=account_number:asc
# 参数说明
q*: 查询所有
sort: 排序字段
asc: 升序
# 检索bank下所有信息,包括type和docs
GET bank/_search
通过uri + 请求体检索文档
GET /bank/_search
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" },
{ "balance":"desc"}
]
}
查询返回内容
-
took – 花费多少ms搜索
-
timed_out – 是否超时
-
shards – 多少分片被搜索了,以及多少成功/失败的搜索分片
-
max_score –文档相关性最高得分
-
hits.total.value - 多少匹配文档被找到
-
hits.sort - 结果的排序key(列),没有的话按照score排序
-
hits._score - 相关得分 (not applicable when using match_all)
ES特定查询语言DSL
es提供的一个可以执行查询Json风格的DSL(domain-specific language)。
基本语法格式
典型查询结构
{
QUERY_NAME:{ #使用的功能
FIELD_NAME:{ #功能参数
ARGUMENT:VALUE,
ARGUMENT:VALUE,
示例:
GET bank/_search
{
"query" : { #查询的字段
"match_all":{}
},
"from":0, #从第几条文档开始查
"size":5,
"_source":["balabce"], #要返回的字段
"sort":[
{
"account_number":{ #返回结果按哪个列排序
"order":"desc"
}
}
]
}
参数说明:
-
match_all:查询类型【代表查询所有的索引】,es中可以在query中组合非常多的查询类型完成复杂查询。 -
除了
query参数外,可以传递其它参数过滤查询结果。 -
from + size限定,完成分页功能。 -
sort排序,多字段排序,会在前序字段相等时后续字段内部排序,否则以前序为准。
查询结果:
{
"took" : 18, # 花了18ms
"timed_out" : false, # 没有超时
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000, # 命令1000条
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "999", # 第一条数据id是999
"_score" : null, # 得分信息
"_source" : {
"firstname" : "Dorothy",
"balance" : 6087
},
"sort" : [ # 排序字段的值
999
]
},
省略
query/match匹配查询
如果是非字符串,会进行精确匹配。如果是字符串,会进行全文检索。
-
基本类型(非字符串),精确匹配
GET bank/_search
{
"query":{
"match":{
"account_number":"20"
}
}
}
查询结果:返回account_number=20的数据
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1, // 得到一条
"relation" : "eq"
},
"max_score" : 1.0, # 最大得分
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "20",
"_score" : 1.0,
"_source" : { # 该条文档信息
"account_number" : 20,
"balance" : 16418,
"firstname" : "Elinor",
"lastname" : "Ratliff",
"age" : 36,
"gender" : "M",
"address" : "282 Kings Place",
"employer" : "Scentric",
"email" : "elinorratliff@scentric.com",
"city" : "Ribera",
"state" : "WA"
}
}
]
}
}
-
字符串,全文检索
GET bank/_search
{
"query": {
"match": {
"address":"kings"
}
}
}
查询结果:最终会按照评分进行排序,会对检索条件进行分词匹配
{
"took" : 30,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 5.990829,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "20",
"_score" : 5.990829,
"_source" : {
"account_number" : 20,
"balance" : 16418,
"firstname" : "Elinor",
"lastname" : "Ratliff",
"age" : 36,
"gender" : "M",
"address" : "282 Kings Place",
"employer" : "Scentric",
"email" : "elinorratliff@scentric.com",
"city" : "Ribera",
"state" : "WA"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "722",
"_score" : 5.990829,
"_source" : {
"account_number" : 722,
"balance" : 27256,
"firstname" : "Roberts",
"lastname" : "Beasley",
"age" : 34,
"gender" : "F",
"address" : "305 Kings Hwy",
"employer" : "Quintity",
"email" : "robertsbeasley@quintity.com",
"city" : "Hayden",
"state" : "PA"
}
}
]
}
}
query/match_phrase[不拆分匹配]
将需要匹配的值当成一整个单词(不分词)进行检索
-
match_phrase:不拆分字符串进行检索
-
字段.keyword:必须全匹配上才检索成功
两者区别:
使用keyword,匹配的条件就是要显示字段的全部值,精确匹配。
match_phrase是做短语匹配,只要文本中包含匹配条件,就能匹配到。
使用示例:
GET bank/_search
{
"query": {
"match_phrase": {
"address": "mill road" # 就是说不要匹配只有mill或只有road的,要匹配mill road一整个子串
}
}
}
{
"took" : 32,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 8.926605,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "970",
"_score" : 8.926605,
"_source" : {
"account_number" : 970,
"balance" : 19648,
"firstname" : "Forbes",
"lastname" : "Wallace",
"age" : 28,
"gender" : "M",
"address" : "990 Mill Road", # "mill road"
"employer" : "Pheast",
"email" : "forbeswallace@pheast.com",
"city" : "Lopezo",
"state" : "AK"
}
}
]
}
}
GET bank/_search
{
"query": {
"match": {
"address.keyword": "990 Mill" # 字段后面加上 .keyword
}
}
}
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0, # 因为要求完全equal,所以匹配不到
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}
query/multi_math[多字段匹配]
如:state或address中包含mill(查询过程中,会对查询条件进行分词)
GET bank/_search
{
"query": {
"multi_match": { # 前面的match仅指定了一个字段。
"query": "mill",
"fields": [ # state和address有mill子串 不要求都有
"state",
"address"
]
}
}
}
{
"took" : 28,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 5.4032025,
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "970",
"_score" : 5.4032025,
"_source" : {
"account_number" : 970,
"balance" : 19648,
"firstname" : "Forbes",
"lastname" : "Wallace",
"age" : 28,
"gender" : "M",
"address" : "990 Mill Road", # 有mill
"employer" : "Pheast",
"email" : "forbeswallace@pheast.com",
"city" : "Lopezo",
"state" : "AK" # 没有mill
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "136",
"_score" : 5.4032025,
"_source" : {
"account_number" : 136,
"balance" : 45801,
"firstname" : "Winnie",
"lastname" : "Holland",
"age" : 38,
"gender" : "M",
"address" : "198 Mill Lane", # mill
"employer" : "Neteria",
"email" : "winnieholland@neteria.com",
"city" : "Urie",
"state" : "IL" # 没有mill
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "345",
"_score" : 5.4032025,
"_source" : {
"account_number" : 345,
"balance" : 9812,
"firstname" : "Parker",
"lastname" : "Hines",
"age" : 38,
"gender" : "M",
"address" : "715 Mill Avenue", #
"employer" : "Baluba",
"email" : "parkerhines@baluba.com",
"city" : "Blackgum",
"state" : "KY" # 没有mill
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "472",
"_score" : 5.4032025,
"_source" : {
"account_number" : 472,
"balance" : 25571,
"firstname" : "Lee",
"lastname" : "Long",
"age" : 32,
"gender" : "F",
"address" : "288 Mill Street", #
"employer" : "Comverges",
"email" : "leelong@comverges.com",
"city" : "Movico",
"state" : "MT" # 没有mill