Mybatis全解-02-CRUD操作及配置文件解析
CRUD
查询select
根据用户id查询对应的用户
先编写UserMapper接口
public interface UserMapper { //查询全部用户 List<User> selectUser(); //根据id查询用户 User selectUserById(int id); }
编写完UserMapper接口后,就是编写对应的UserMapper.xml文件
id:对应接口里的方法
resultType:返回值类型
里面写你需要的sql
<select id="selectUserById" resultType="com.li.pojo.User"> select * from user where id = #{id} </select>
在测试类中测试
@Test public void tsetSelectUserById() { SqlSession session = MybatisUtils.getSession(); //获取SqlSession连接 UserMapper mapper = session.getMapper(UserMapper.class); User user = mapper.selectUserById(1); System.out.println(user); session.close(); }
根据用户名和密码查询用户
建议在接口方法的参数前加上@Param属性,这样的话,你在编写sql的时候,直接取@Param中的值就可以了,不需要单独设置参数的类型,避免了出现映射名字不同的问题。
//通过密码和名字查询用户 User selectUserByNP(@Param("username") String username,@Param("pwd") Stringpwd); <select id="selectUserByNP" resultType="com.li.pojo.User"> select * from user where name = #{username} and pwd = #{pwd} </select>
思考:这里只是根据用户名和密码两个参数来查询用户,如果参数有很多个呢,那么也需要一个一个加上参数吗?
解决方法:使用Map进行参数传递。
首先在接口的方法中不要一个一个地加上参数,直接在里面传入Map。
User selectUserByNP2(Map<String,Object> map);
然后再将xml里的参数类型设置为map。
parameterType="map"
<select id="selectUserByNP2" parameterType="map" resultType="com.li.pojo.User"> select * from user where name = #{username} and pwd = #{pwd} </select>
在使用的时候,把sql中的值作为map的key即可,最后直接将map放入方法中。
Map<String, Object> map = new HashMap<String, Object>(); map.put("username","小明"); map.put("pwd","123456"); User user = mapper.selectUserByNP2(map);
插入insert
//添加一个用户 int addUser(User user);
<insert id="addUser" parameterType="com.li.pojo.User"> insert into user (id,name,pwd) values (#{id},#{name},#{pwd}) </insert>
@Test public void testAddUser() { SqlSession session = MybatisUtils.getSession(); UserMapper mapper = session.getMapper(UserMapper.class); User user = new User(5,"王五","zxcvbn"); int i = mapper.addUser(user); System.out.println(i); session.commit(); //提交事务,重点!不写的话不会提交到数据库 session.close(); }
千万要注意:除了查询,增删改都要手动提交事务。
修改update
//修改一个用户 int updateUser(User user);
<update id="updateUser" parameterType="com.li.pojo.User"> update user set name=#{name},pwd=#{pwd} where id = #{id} </update>
@Test public void testUpdateUser() { SqlSession session = MybatisUtils.getSession(); UserMapper mapper = session.getMapper(UserMapper.class); User user = mapper.selectUserById(1); user.setPwd("asdfgh"); int i = mapper.updateUser(user); System.out.println(i); session.commit(); //提交事务,重点!不写的话不会提交到数据库 session.close(); }
删除delete
//根据id删除用户 int deleteUser(int id);
<delete id="deleteUser" parameterType="int"> delete from user where id = #{id} </delete>
@Test public void testDeleteUser() { SqlSession session = MybatisUtils.getSession(); UserMapper mapper = session.getMapper(UserMapper.class); int i = mapper.deleteUser(5); System.out.println(i); session.commit(); //提交事务,重点!不写的话不会提交到数据库 session.close(); }
注意点总结:
除了查询,增删改都需要手动提交事务。
Mapper接口中的所有普通参数,尽量都写上@Param参数。
有时候考虑到业务需要,可以考虑使用map传递参数。
模糊查询的两种实现方法 关键词:like
1.在sql语句中进行拼接,不建议使用这种,有可能引起sql注入问题。
string wildcardname = “smi”; list<name> names = mapper.selectlike(wildcardname); <select id=”selectlike”> select * from foo where bar like "%"#{value}"%" </select>
2.在java代码中添加sql通配符。
string wildcardname = “%smi%”; list<name> names = mapper.selectlike(wildcardname); <select id=”selectlike”> select * from foo where bar like #{value} </select>
mybatis核心配置文件解析
configuration(配置) properties(属性) settings(设置) typeAliases(类型别名) typeHandlers(类型处理器) objectFactory(对象工厂) plugins(插件) environments(环境配置) environment(环境变量) transactionManager(事务管理器) dataSource(数据源) databaseIdProvider(数据库厂商标识) mappers(映射器) <!-- 注意元素节点的顺序!顺序不对会报错 -->
注意:在配置的时候,需要注意里面的顺序,否则会报错。
environments元素
<environments default="development"> <environment id="development"> <transactionManager type="JDBC"> <property name="..." value="..."/> </transactionManager> <dataSource type="POOLED"> <property name="driver" value="${driver}"/> <property name="url" value="${url}"/> <property name="username" value="${username}"/> <property name="password" value="${password}"/> </dataSource> </environment> </environments>
后面是复数结尾,可知这是可以配置多套环境,通过default可指定默认使用环境。
有三种内建的数据源类型:
type="[UNPOOLED|POOLED|JNDI]")
unpooled:每次被请求时打开和关闭连接。
pooled:池的概念,一种快速响应请求的流行模式。
jndi:为了能够在spring等容器中使用,容器集中或在外部配置数据源,然后放置一个jdni上下文的引用。
当然,数据源也有很多第三方的实现,在后面的框架整合中会用到。
Mappers
映射器:用来定义映射sql的xml文件。
推荐使用两种常用的:
1.使用相对于类路径的资源引用 关键词:resource,斜杠分隔,准确到xml文件
<mappers> <mapper resource="org/mybatis/builder/PostMapper.xml"/> </mappers>
2.使用映射器接口实现类的完全限定类名,注意:xml文件名和mapper接口名称一致,并且位于同一目录下
<mappers> <mapper class="org.mybatis.builder.AuthorMapper"/> </mappers>
mapper.xml文件
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.li.mapper.UserMapper"> </mapper>
namespace:命名空间,绑定接口。绑定规则:包名+类名
优化问题
Properties优化
1.在资源目录下新建一个db.properties文件
driver=com.mysql.jdbc.Driver url=jdbc:mysql://localhost:3306/mybatis?useSSL=true&useUnicode=true&characterEncoding=utf8 username=root password=123456
2.使用properties 属性导入配置文件
<configuration> <!--导入properties文件--> <properties resource="db.properties"/> <environments default="development"> <environment id="development"> <transactionManager type="JDBC"/> <dataSource type="POOLED"> <property name="driver" value="${driver}"/> <property name="url" value="${url}"/> <property name="username" value="${username}"/> <property name="password" value="${password}"/> </dataSource> </environment> </environments> <mappers> <mapper resource="mapper/UserMapper.xml"/> </mappers> </configuration>
typeAliases优化 关键字 alias
1.单个类设置别名
<typeAliases> <typeAlias type="com.li.pojo.User" alias="User"/> </typeAliases>
2.指定一个包名,所有的类别名都使用类首字母小写
<typeAliases> <package name="com.li.pojo"/> </typeAliases>
3.使用注解
@Alias("user")
public class User {
...
}
这里讲的是常用的属性,其他的相关属性可以查看官方文档。
作用域与生命周期的理解
Mybatis执行流程
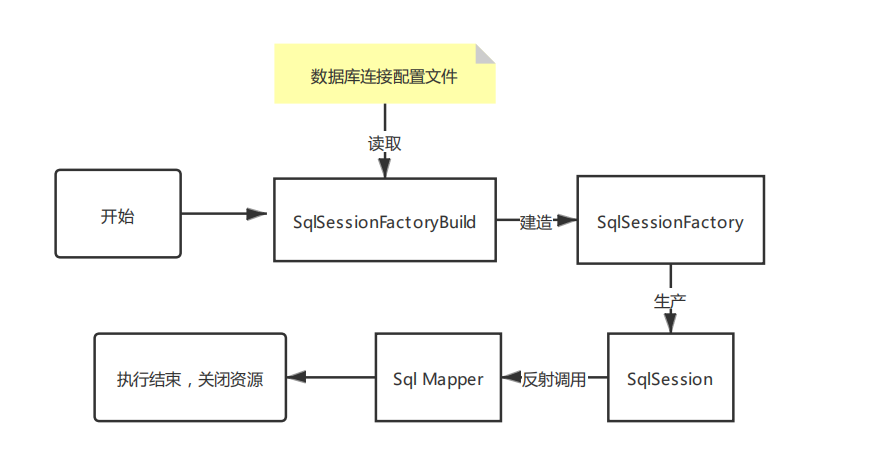
作用域理解
-
-
SqlSessionFactory 可以被认为是一个数据库连接池,它的作用是创建 SqlSession 接口对象。因为 MyBatis 的本质就是 Java 对数据库的操作,所以 SqlSessionFactory 的生命周期存在于整个 MyBatis 的应用之中,所以一旦创建了 SqlSessionFactory,就要长期保存它,直至不再使用 MyBatis 应用,所以可以认为 SqlSessionFactory 的生命周期就等同于 MyBatis 的应用周期。
-
由于 SqlSessionFactory 是一个对数据库的连接池,所以它占据着数据库的连接资源。如果创建多个 SqlSessionFactory,那么就存在多个数据库连接池,这样不利于对数据库资源的控制,也会导致数据库连接资源被消耗光,出现系统宕机等情况,所以尽量避免发生这样的情况。
-
因此在一般的应用中我们往往希望 SqlSessionFactory 作为一个单例,让它在应用中被共享。所以说 SqlSessionFactory 的最佳作用域是应用作用域。
-
如果说 SqlSessionFactory 相当于数据库连接池,那么 SqlSession 就相当于一个数据库连接(Connection 对象),你可以在一个事务里面执行多条 SQL,然后通过它的 commit、rollback 等方法,提交或者回滚事务。所以它应该存活在一个业务请求中,处理完整个请求后,应该关闭这条连接,让它归还给 SqlSessionFactory,否则数据库资源就很快被耗费精光,系统就会瘫痪,所以用 try...catch...finally... 语句来保证其正确关闭。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号