

Elasticsearch- 查询
默认查询
GET /my_index/_search
条件查询
GET /my_index/_search?q=text:国人
返回结果解析:
{
"took": 30, # 总耗时多少毫秒
"timed_out": false, # 是否超时
"_shards": { # 查询分片情况
"total": 1, # 搜索1个分片
"successful": 1, # 成功1个分片
"skipped": 0, # 跳过了0个分片
"failed": 0 # 失败了0个分片
},
"hits": {
"total": { # 检查的结果数
"value": 1,
"relation": "eq"
},
"max_score": 0.2876821, # 匹配度,越匹配分数越高
"hits": [ # 匹配搜索的详细数据
{
"_index": "my_index",
"_id": "1",
"_score": 0.2876821,
"_source": {
"text": "中华人民共和国人民大会堂"
}
}
]
}
}
查询name中包含“国人”的
GET /my_index/_search?q=+name:国人
查询name中不包含“国人”的
GET /my_index/_search?q=-name:国人
设置超时时间:10ms
GET /my_index/_search?q=text:国人&timeout=10ms
全局设置:配置文件中设置search.default_search_timeout:100ms默认不超时
multi-index多索引搜索
GET /book,book1/_search?q=name:php
或者使用
GET /book*/_search?q=name:php
分页
类似于mysql:select * from user limit 1,5
GET /book,book1/_search?q=name:php&from=0&size=3
DSL
# 查询name中带有php的,并且根据price倒序查询
GET /book/_search
{
"query": {
"match": {
"name": "php"
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
# 分页查询
GET /book/_search
{
"query": {"match_all": {}},
"from": 0,
"size": 20
}
# 查询指定字段
# match_all 查询所有
# _source 查询字段
GET /book/_search
{
"query": {"match_all": {}},
"_source": ["name", "price"]
}
# multi_match 跨多个字段搜索查询,想在name、desc字段中搜索 google 一词
# fields: 搜索涉及的字段列表
GET /book/_search
{
"query": {
"multi_match": {
"query": "google",
"fields": ["name", "desc"]
}
}
}
# 查询范围;price>=10 and price<=20
# gte 大于等于,gt 大于,lte 小于等于,lt 小于
GET /book/_search
{
"query": {
"range": {
"price": {
"gte": 10,
"lte": 20
}
}
}
}
# 查询name中"php开发"不被分词的数据
GET /book/_search
{
"query": {
"term": {
"name": "php开发"
}
}
}
# 查询name中"php开发", "js开发", "vue开发"不被分词的数据
GET /book/_search
{
"query": {
"terms": {
"name": ["php开发", "js开发", "vue开发"]
}
}
}
# 查询文档中有age字段的数据
put /book/_doc/1
{
"username": 1
}
put /book/_doc/2
{
"username": 2,
"age": 18
}
GET /book/_search
{
"query": {
"exists": {
"field": "age"
}
}
}
# 模糊查询 相似查询
包括以下几种情况
更改字符: name->mame
删除字符: apple->aple
插入字符: facebook->faceebook
调换两个相邻字符:ACT->ATC
eg:搜索"笔记电脑"时会把"笔记本电脑"搜索出来
eg:查询desc中包含facebook的数据 结果将facebook 输入成了faceebook
GET /book/_search
{
"query": {
"fuzzy": {
"desc": {
"value": "faceebook"
}
}
}
}
# 根据ID查询
GET /book/_search
{
"query": {
"ids": {
"values": [1,2,3]
}
}
}
# 查询name 字段以 dell 开头的数据
GET /book/_search
{
"query": {
"prefix": {
"name": {
"value": "dell"
}
}
}
}
# 正则匹配
# 正则查询desc字段中包含“fa ok”的数据
GET /book/_search
{
"query": {
"regexp": {
"desc": "fa.*ok"
}
}
}
# 多条件组合查询
# 插入数据
DELETE /website
PUT /website/_doc/1
{
"title": "my hadoop class",
"content": "hadoop is very bad",
"author_id": 111
}
PUT /website/_doc/2
{
"title": "my es class",
"content": "es is very bad",
"author_id": 112
}
PUT /website/_doc/3
{
"title": "my es class",
"content": "es is very good",
"author_id": 111
}
# 查询数据
# 查询 title中带有es,content中可以有es可以没有es,作者不是111的数据;must 必须包含,should 可包含可不包含,must_not 必须不包含
GET /website/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "es"
}
}
],
"should": [
{
"match": {
"content": "es"
}
}
],
"must_not": [
{
"match": {
"author_id": 111
}
}
]
}
}
}
filter过滤器
通过query查询
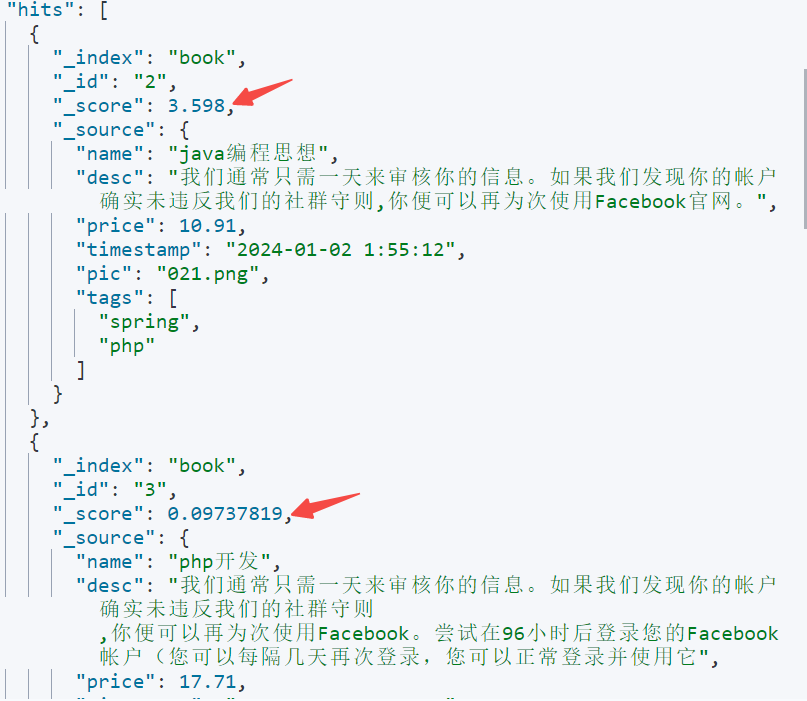
eg:查询desc中有"Facebook官网"并且价格在7-20之间的数据
在只查询desc中有"Facebook官网"时, 返回的_score 分别是3.598,0.097
GET /book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"desc": "Facebook官网"
}
}
]
}
}
}
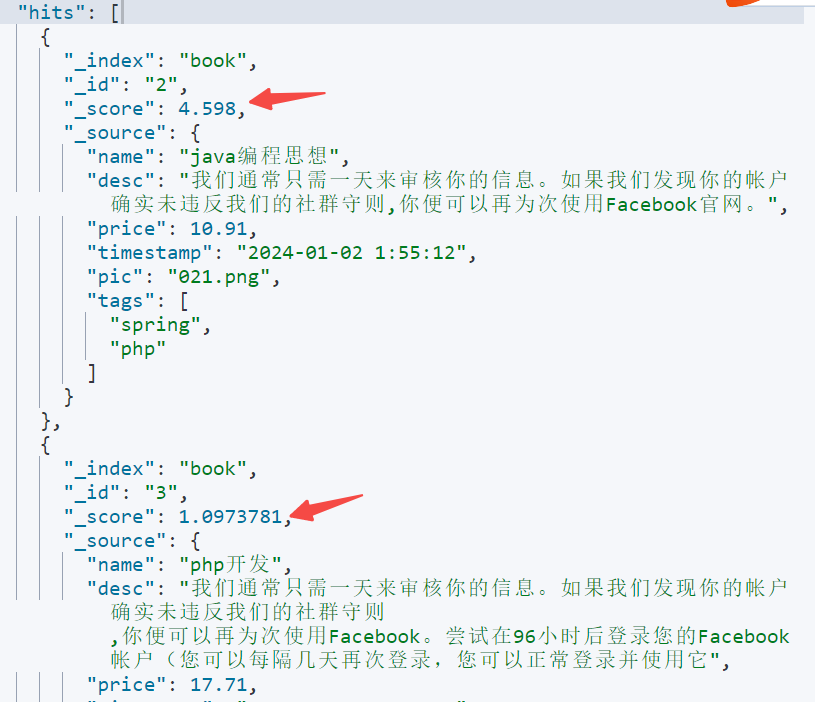
再加上价格条件查询时会发现返回的_score 分别是4.598,1.097
GET /book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"desc": "Facebook官网"
}
},
{
"range": {
"price": {
"gte": 7,
"lte": 20
}
}
}
]
}
}
}
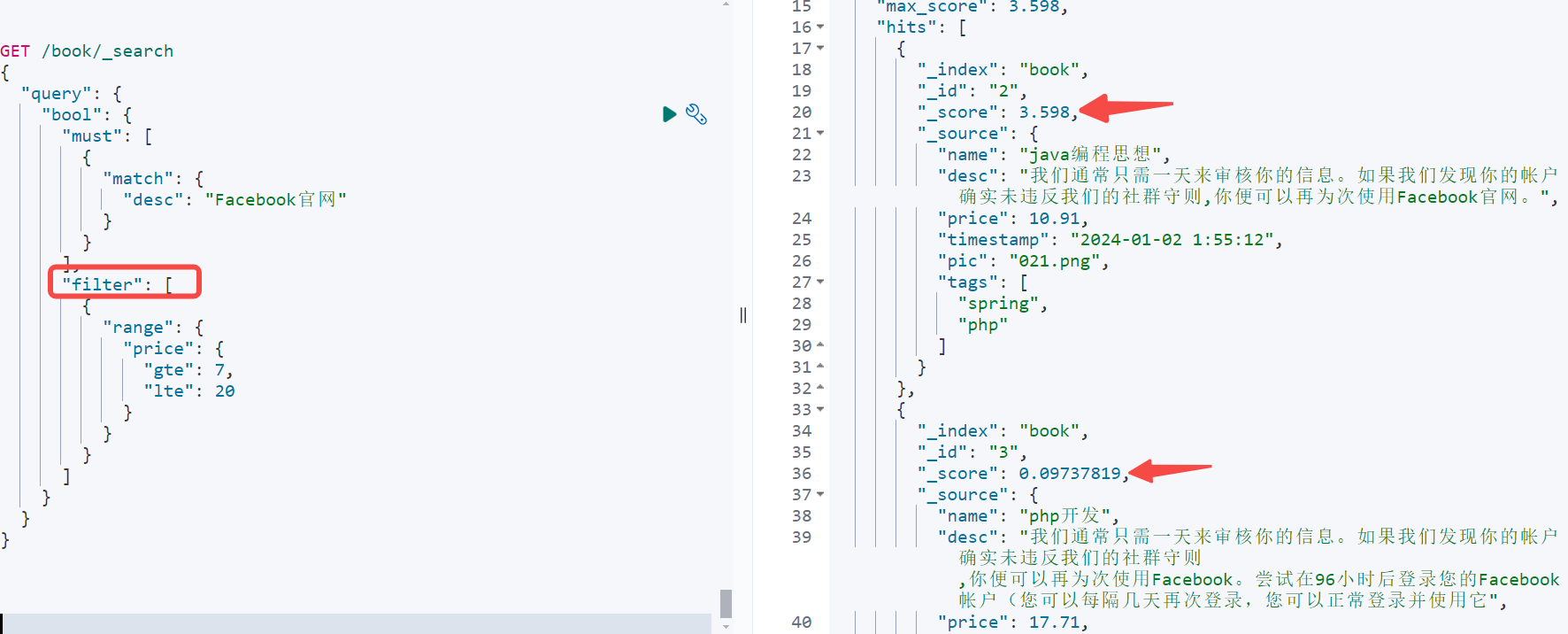
想要查询结果不影响到_score,此时需要使用filter过滤,即:在查询desc中有"Facebook官网"得到的结果中再去匹配价格范围的数据
GET /book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"desc": "Facebook官网"
}
}
],
"filter": [
{
"range": {
"price": {
"gte": 7,
"lte": 20
}
}
}
]
}
}
}
返回的结果:
query与filter概念对比
query,会去计算每个document相对于搜索条件的相关度,并按照相关度进行排序。
filter,仅仅只是按照搜索条件过滤出需要的数据而已,不计算任何相关度分数,对相关度没有任何影响。
应用场景:
在进行搜索,如果需要将最匹配搜索条件的数据先返回,那么用query
如果只是要根据一些条件筛选出一部分数据,不关注其排序,那么用filter
query与filter性能对比
query,要计算相关度分数,按照分数进行排序,而且无法cache结果
filter,不需要计算相关度分数,不需要按照相关度分数进行排序,同时还有内置的自动cache最常使用filter的数据
只使用过滤器的方式查询数据:
错误方式:
GET /book/_search
{
"query": {
"filter": {
"range": {
"price": {
"gte": 7,
"lte": 20
}
}
}
}
}
正确方式: 使用关键词:constant_score
GET /book/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"gte": 7,
"lte": 20
}
}
}
}
}
}
此时返回的 "_score": 1
想要将通过filter查询出的数据在再根据某个字段排序时,写法:
GET /book/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"price": {
"gte": 7,
"lte": 20
}
}
}
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧