

Linux 常用命令总结(三)
一、实用命令
1、crontab(定时任务)
(1)基本概念
crontab 是用来管理定时任务的命令。
系统启动后,将会自动调用 crontab,如果存在任务,则根据相关定义去执行。
(2)常用场景
系统周期性执行的工作。比如:系统数据备份,定期清理缓存等。
个人定期执行的工作。比如:每隔几分钟检查邮件服务器是否存在新邮件。
(3)语法规则
【语法:】 crontab [options] crontab [options] file 【options:】 -u <user> 指定某用户的定时任务。 -e 编辑当前用户的任务,进入 vi 文字编辑器。 -l 查看当前用户的任务 -r 删除当前用户的任务 【定时任务格式:】 f1 f2 f3 f4 f5 command 说明: f1 表示分钟(0 - 59) f2 表示小时(0 - 23) f3 表示天数(1 - 31) f4 表示月数(1 - 12) f5 表示星期几(0 - 6, 0 表示 星期天,1 表示星期一...) command 表示待执行的命令 即:(通过 cat /etc/crontab 可以查看) # .---------------- minute (0 - 59) # | .------------- hour (0 - 23) # | | .---------- day of month (1 - 31) # | | | .------- month (1 - 12) OR jan,feb,mar,apr ... # | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat # | | | | | .---- command to be executed # * * * * * command 注: f1 为 * 时,表示每分钟执行。f2...f5 类似。 f1 为 a-b 时,表示从第 a 分钟到第 b 分钟时间段内,每分钟执行一次。f2...f5 类似。 f1 为 */n 时,表示每隔 n 分钟执行一次。f2...f5 类似。 f1 为 a,b,c 时,表示第 a、b、c 分钟执行一次。f2...f5 类似。
(4)相关命令
【查看 crontab:】 cat /etc/crontab 【编辑 crontab:】 crontab -e 注: 不同的用户创建的任务,最终出现在 /var/spool/cron 下,文件名为 用户名。 比如:root 用户创建的任务最终存储在 /var/spool/cron/root 文件中。 【查看 crontab:】 crontab -l cat /var/spool/cron/root # 查看 root 用户的定时任务 【删除所有 crontab:】 crontab -r 【查看、启动、重启、停止 crontab 服务:】 service crond status service crond start/stop/restart 【查看日志:】 tail -f /var/log/cron
(5)举例:
【每分钟执行一次 echo:】 * * * * * echo 11 >> /root/test/text.txt 注: 若脚本中命令不生效,将命令换成 绝对路径 试一下。 通过 which 可以查找 命令所在的 绝对路径,比如: which echo 输出为 /usr/bin/echo 替换绝对路径,比如: * * * * * /usr/bin/echo 11 >> /root/test/text.txt 【每个月 1 号、15 号 执行一次 echo:】 0 0 1,15 * * echo 11 >> /root/test/text.txt
2、sh、source、exec(执行脚本)
(1)基本概念
【sh:】 使用 sh script.sh 执行脚本时,当前 shell 是父进程,生成一个子 shell 进程,在子 shell 中执行脚本。 脚本执行完毕,退出子 shell,回到当前 shell。 ./script.sh 与 sh script.sh 等效 注: echo $$ # 输出当前 shell 的进程号 【source:】 使用 source script.sh 方式,在当前上下文中执行脚本,不会生成新的进程。 脚本执行完毕,回到当前 shell。 . script.sh(. 与 script.sh 之间有一个空格) 与 source script.sh 等效。 【exec:】 使用 exec command 方式,一般用于脚本内部,会用 command 进程替换当前 shell 进程,并且保持 PID 不变。 执行完毕,直接退出,不回到之前的 shell 环境。
(2)问题一:sh、source 区别
【sh、source 区别:】
使用 sh 和 source 方式下,脚本执行完毕,都会回到之前的 shell 中。
通过 sh 执行脚本时,修改的上下文(比如:环境变量)不会影响当前 shell。
通过 source 执行脚本时,修改的上下文(比如:环境变量)会影响当前 shell。
(3)问题二:修改 PATH 变量,不重启使其生效
【修改 PATH 变量,不重启使其生效:】 Step1: 在 /etc/profile 文件末尾追加 PATH 设置。 比如: echo 'export MAVEN_HOME=/usr/local/maven/apache-maven-3.6.1' >> /etc/profile echo 'export PATH=$MAVEN_HOME/bin:$PATH' >> /etc/profile Step2: 执行 source /etc/profile 使其生效
(4)问题三:在脚本中执行 source /etc/profile 不生效
【在脚本中执行 source /etc/profile 不生效:】 方式一: 可以直接使用 source 脚本名 直接去调用,不需要在脚本中写 source /etc/profile 方式二: 在脚本执行 source /etc/profile 后,追加 exec 语句。 通过 exec bash -l 或者 exec /bin/bash -l 或者 exec $SHELL -l 去打开一个新进程。 注: exec 会导致 exec 之后的语句不执行,exec 一般放于脚本末尾。
3、jq(json 解析工具)
(1)基本概念
jq 是一款在使用命令行处理 JSON 数据的工具,可用于处理 标准输入、管道、文件 传递的 JSON 数据,经过一系列 过滤器、表达式 后,提取成需要的数据 并输出到 标准输出中。
(2)相关地址
jq 官网地址: https://stedolan.github.io/jq/
jq 文档: https://github.com/stedolan/jq/wiki
jq 文档: https://stedolan.github.io/jq/manual/
(3)安装
【centos:】 yum install -y epel-release yum install -y jq 【其余方式参考官网提供方式:】 https://stedolan.github.io/jq/download/
(4)语法规则
【语法:】 jq [options] <jq filter> [file...] 【options: 】 -c 紧凑输出(默认为 树形结构,紧凑输出将树形结构转为一行输出) -r 输出原始字符串,不在结果上加双引号 -R 读取原始字符串,在结果上加上双引号 -C 字符串着色 -M 字符串不着色 --tab 使用 tab 替换缩进符 -s 将结果使用数组保存 --arg a v 将变量 $a 设置为值 v 注: 对于待解析的数据,其所有的属性名必须是以双引号包括的字符串,否则可能会解析失败。 数据不存在时,返回 null 。 【jq filter -- 基本规则: 】 jq 根据语法规则解析 jq filter,并将其应用在 JSON 数据上,从而解析出想要的结果。 . 是最基本的过滤器。仅用 . 作为过滤器时,表示对整个 JSON 数据的引用,结果是格式化输出 JSON 数据。 '' 单引号可以不使用,但是若组合了多个过滤器,需要使用单引号包裹。 "" 双引号用于包裹特殊字符。比如: ."key$" 或者 .["key$"] , 用于输出多个过滤器结果。比如: .key1,.key2 表示过滤 key1 key2 的数据 | jq filter 支持串行化操作,一个复杂的 filter 可以由多个简单的 filter 通过 管道符 "|" 连接组成,每个 filter 均以 前一个 filter 的结果作为输入数据进行处理。 .. 递归输出每个值。 [] 将结果构造为一个数组,比如: '[.key1,.key2]' {} 将结果构造为一个对象,比如: '{"result": .key1}'。 比如: {"key1":{"key11":"value11","key12":"value12"}}, 可以通过 '.key1 | .key11' 去解析 key11 的值。 echo '{"key1":{"key11":"value11","key12":"value12"}}' | jq '.key1 | .key11' 【jq filter -- 对象操作: 】 jq 使用类似于 '.key' 的方式过滤 JSON 对象,当数据不存在时,返回 null。 过滤单个对象: '.key1' 等价于 .'["key1"]' 过滤多个对象 '.key1, .key2' 等价于 .'["key1", "key2"]' 过滤对象的对象: '.key1.key2' 等价于 '.key1 | .key2' 【jq filter -- 数组操作: 】 jq 使用类似于 '.[index]' 的方式过滤 JSON 数组。 过滤单个数组元素: '.[index]' index 从 0 开始,正序输出,若为负数,反序输出(0 表示第一个元素, -1 表示最后一个元素)。 过滤多个数组元素: '.[index, index2]' 过滤所有数组元素: '.[]' 过滤数组某个范围的数据: '.[startIndex:endIndex]' 包含 startIndex ,但不包含 endIndex
(5)举例(简单)
【vi test.json 编辑 json 数据】 { "key1": "value1", "key2": "value2" } 【cat test.json | jq 格式化输出数据】 { "key1": "value1", "key2": "value2" } 【cat test.json | jq -c 输出紧凑的数据】 {"key1":"value1","key2":"value2"} 【cat test.json | jq -R 输出结果会加上双引号】 "{" " \"key1\": \"value1\", \"key2\": \"value2\"" "}" 【cat test.json | jq -s 结果使用数组形式保存】 [ { "key1": "value1", "key2": "value2" } ] 【cat test.json | jq --arg name jarry '{name: $name}' 将变量 $a 设置为值 v】 { "name": "jarry" }
(6)举例(解析对象 Object)
【vi test.json 编辑 json 数据】 { "key1": { "key11": "value11", "key12": "value12" }, "key2": "value2" } 【cat test.json | jq .key1 获取 key1 对应的 value】 { "key11": "value11", "key12": "value12" } 【cat test.json | jq .'["key1"]' 获取 key1 对应的 value】 { "key11": "value11", "key12": "value12" } 【cat test.json | jq .key1,.key2 获取 key1,key2 对应的 value】 { "key11": "value11", "key12": "value12" } "value2" 【cat test.json | jq .'["key1", "key2"]' 获取 key1,key2 对应的 value】 { "key11": "value11", "key12": "value12" } "value2" 【cat test.json | jq .[] 获取所有的 value】 { "key11": "value11", "key12": "value12" } "value2" 【cat test.json | jq .key1.key11 获取 key11 对应的 value】 "value11" 【cat test.json | jq -r .key1.key11 获取 key11 对应的 value】 value11 【cat test.json | jq keys 获取所有 key 组成的数组】 [ "key1", "key2" ] 【cat test.json | jq [.[]] 获取所有的 value 组成的数组】 [ { "key11": "value11", "key12": "value12" }, "value2" ]
(7)举例(解析数组 Array)
【vi test.json 编辑 json 数据】 [ { "key1": ["value1"], "key2": "value2" }, ["value3", "value4"] ] 【cat test.json | jq .[] 获取数组所有的元素】 { "key1": [ "value1" ], "key2": "value2" } [ "value3", "value4" ] 【cat test.json | jq .[0] 获取数组的第一个元素】 { "key1": [ "value1" ], "key2": "value2" } 【cat test.json | jq .[1] 获取数组的第二个元素】 [ "value3", "value4" ] 【cat test.json | jq .[0:2] 获取数组 第一个元素 到 第三个元素】 [ { "key1": [ "value1" ], "key2": "value2" }, [ "value3", "value4" ] ] 【cat test.json | jq .[0].key1 获取 Object 对象的 value 值】 [ "value1" ] 【cat test.json | jq '.[0] | .key1' 获取 Object 对象的 value 值】 [ "value1" ] 【cat test.json | jq .[0].key1,.[0].key2】 [ "value1" ] "value2" 【cat test.json | jq .[1][0] 获取 数组元素 】 "value3" 【cat test.json | jq '.[1] | .[0]'】 "value3" 【cat test.json | jq [.[0].key2]】 [ "value2" ] 【cat test.json | jq [.[1][0]]】 [ "value3" ]
4、logrotate(管理日志文件)
(1)基本概念
logrotate 是 Linux 上的一个日志文件管理工具。 可以删除 旧的日志文件,并创建新的日志文件。这个过程可以称为 “日志轮替”。 可以根据 日志文件的大小、以及 日志文件 的存放天数 来进行处理。一般通过 cron 程序来执行。 crontab 会每天执行一次 /etc/cron.daily 目录下的脚本,该目录下存在一个 /etc/cron.daily/logrotate 文件,内部执行 logrotate 命令。 若 logrotate 配置在其他目录下,比如: /etc/cron.daily/,/etc/cron.weekly/,/etc/cron.monthly/,/etc/cron.hourly/,则可能 每天、每周、每月、每小时 执行一次。 一般情况下,logrotate 每天由 crontab 执行一次,可以手动执行 logrotate 命令(-f 强制执行),或者 自定义定时任务。
(2)语法规则
【语法:】 logrotate [options] <configfile> 【options:】 -d, --debug 显示指令执行过程,不进行实际操作 -v, --verbose 显示指令执行过程,进行实际操作 -f, --force 强制执行 -s, --state=statefile 指定日志更新状态,形如:"/var/log/yum.log" 2021-4-1-10:54:26 【logrotate 基本格式:】 日志文件路径 + {} 组成,{} 内部每行表示一个规则。 若配置多个文件,文件名独立成行。 *.log { rule1 rule2 ... } xxx.log xxx.log2 { rule1 rule2 ... } 【logrotate 基本规则参数:】 compress 使用 gzip 压缩日志文件。 nocompress 不压缩日志文件。 copytruncate 先复制日志文件,再清空。复制与清空之间存在时间差,可能丢失部分日志数据。 create mode owner group 创建空文件,并指定权限、用户名、组名。比如: create 0600 root root。 nocreate 不创建新的空文件。 daily 指定 日志轮替 周期为 每天。 weekly 指定 日志轮替 周期为 每周。 monthly 指定 日志轮替 周期为 每月。 delaycompress 延迟压缩过程到 下一次 进行 日志轮替 时进行。与 compress 配合使用,即当前日志文件 需要等待下一次 日志轮替 时才进行 压缩。 ifempty 即使日志文件为空,也进行 日志轮替。 notifempty 日志文件为空,则不作 日志轮替。 missingok 如果日志文件不存在,仍可以继续处理,不会出错。 nomissingok 如果日志文件不存在,则会出错(显示出错信息)。 noolddir 日志存储在同一个目录下。 olddir [目录名] 指定日志存储目录。 rotate [数量] 指定日志文件备份数量。执行一次日志轮替,就生成一次备份文件,超过后,备份文件内容将清空,若未配置,则直接修改原文件。 size [大小] 当日志文件超过指定的文件大小时进行日志轮替,默认单位为 byte,可以为 K、M、G,比如: size 10M sharedscripts 对多个日志文件 执行 postrotate 或者 prerotate 命令。 dateext 使文件以日期为后缀。默认为 xxx.log.1,xxx.log.2 等,以日期结尾,比如:xx.log.2020-04-20 dateformat -%Y%m%d%H.%s 配合 dateext 使用,改变日期后缀的格式。 prerotate~endscript 预操作,在执行 日志轮替前 先执行 prerotate~endscript 之间的命令。 postrotate~endscript 后操作,在执行 日志轮替后 执行 postrotate~endscript 之间的命令。
(3)相关文件
【cat /etc/cron.daily/logrotate】 #!/bin/sh /usr/sbin/logrotate -s /var/lib/logrotate/logrotate.status /etc/logrotate.conf EXITVALUE=$? if [ $EXITVALUE != 0 ]; then /usr/bin/logger -t logrotate "ALERT exited abnormally with [$EXITVALUE]" fi exit 0 【cat /etc/logrotate.conf】 # see "man logrotate" for details 通过 man logrotate 指令可以查看 logrotate 详情 # rotate log files weekly 每周进行一次 日志轮替 weekly # keep 4 weeks worth of backlogs 保留最近 4 周的日志 rotate 4 # create new (empty) log files after rotating old ones 创建一个空的新文件 在 日志轮替 老文件后 create # use date as a suffix of the rotated file 使文件以日期为后缀 dateext # uncomment this if you want your log files compressed compress 表示压缩日志文件 #compress # RPM packages drop log rotation information into this directory 存放 rpm 安装的软件的日志轮替规则,自定义日志轮替 include /etc/logrotate.d # no packages own wtmp and btmp -- we'll rotate them here 配置 wtmp、btmp 日志轮替规则 /var/log/wtmp { monthly create 0664 root utmp minsize 1M rotate 1 } /var/log/btmp { missingok monthly create 0600 root utmp rotate 1 } # system-specific logs may be also be configured here 可以在此处配置系统日志轮替规则
(4)配置 logrotate 的方式
【方式一:】 直接在 /etc/logrotate.conf 文件中进行配置。 一般用于配置非 rpm 安装的软件的系统文件。 【方式二:】 在 /etc/logrotate.d 文件夹下 新建一个配置文件。 一般 rpm 安装的软件 会自动生成一个配置文件。比如:/etc/logrotate.d/yum 【cat /etc/logrotate.d/yum】 /var/log/yum.log { missingok notifempty maxsize 30k yearly create 0600 root root }
(5) logrotate 切割文件的小问题
假设原始文件为 test.log。 默认情况下, logrotate 会将原始文件 test.log 重命名为 test.log.1,然后重新生成一个 test.log 文件。 某种特殊情况下,由于自身程序一直在调用 test.log 文件,导致 test.log 文件重命名后,日志仍写入重命名后的文件 test.log.1 中。而不是新的 test.log 文件。导致 test.log 文件一直是空文件。 解决办法: 使用 copytruncate,将原文件内容 copy 一份到新文件,然后清空原文件。 日志仍写入原文件。但是文件过大时,copy 会耗时,可能导致日志丢失。 /usr/local/tomcat/logs/*.log { daily missingok copytruncate ifempty size 1M create 0600 root root rotate 5 }
5、sed(修改文本)
(1)基本概念
【基本概念:】 sed 是一个过滤和转换文本的流编辑器(非交互式)。 用于处理 文件 或者 管道符 传递的文本数据,可以对数据行进行替换、删除、新增、选取等特定工作,简化对文件的反复操作。 默认情况下,sed 逐行处理 输入数据,会将修改结果输出,不会修改源文件。 【处理流程:】 1、将正在处理的行 保存在一个临时缓存区(模式空间)中. 2、处理临时缓存区中的数据,将结果输出。处理完一行,就将其从临时缓存区删除。 3、重复 1-2 部署,直至数据处理完成。
(2)语法规则
【语法:】 sed [options] 'command' fileName1 [fileName2] # sed 命令格式 sed [options] -f scriptFile fileName(s) # sed 脚本模式(根据 scriptFile 中的 sed 命令对 fileName 表示的文件进行操作) 【options:】 -i 直接修改源文件内容,不输出。 -e 默认选项,不修改源文件(可以进行重定向覆盖源文件)。 -n 禁止默认输出行为(输出所有内容),仅显示模糊匹配的行,不修改源文件。 【command:】 command 定义如何处理文件,默认处理所有行。可以通过 数字、字符、正则表达式 组合形式过滤文件。 【command -- 数字(从 1 开始,1 表示第一行):】 单个数字表示第几行 $ 表示最后一行 使用 , 连接,表示 第几行 到 第几行 使用 ~ 连接,表示从 第几行 开始,每隔 几行 取一行 比如: 2 表示第 2 行。 $ 表示最后一行。 2,4 表示第 2 行 到 第 4 行。 2~3 表示从第 2 行开始,每隔 3 行取一行。 2,+4 表示从第 2 行到 第 2+4 行。 【command -- 字符:】 a\ 表示在当前行后面插入一行 或 多行。追加多行时,除最后一行,每行需要以 \ 结尾(表示换行)。 i\ 表示在当前行之前插入一行 或 多行。追加多行时,除最后一行,每行需要以 \ 结尾(表示换行)。 c\ 表示使用新文本替换当前行。追加多行时,除最后一行,每行需要以 \ 结尾(表示换行)。 d 表示删除选择的行。 h 把模式空间里的内容复制到暂存缓冲区. H 把模式空间里的内容追加到暂存缓冲区 g 把暂存缓冲区里的内容复制到模式空间,覆盖原有的内容 G 把暂存缓冲区的内容追加到模式空间里,追加在原有内容的后面 x 交换暂存缓冲区 与 模式空间的内容。 n 读取下一个输入行到模式空间。 N 追加下一个输入行到模式空间。 p 显示每行的内容,若与 options 中的 -n 使用时,可以仅输出 选定的 内容。 P 仅显示第一行。 q 结束 sed 操作 ! 非,表示对非选中行进行操作。 = 输出当前行号。 【command -- 正则表达式:】 s/regexp/replacement/ 根据 regexp 匹配到指定字符串,然后使用 replacement 进行替换。 /regexp/ regexp: ^ 行首定位符,匹配 xx 开头的行。 /^xx/ $ 行位定位符,匹配 xx 结尾的行. /xx$/ . 匹配单个字符(除换行符外)。 /x..x/ * 匹配 0个 或 多个 字符(不能用于首字母)。 /x*x/ [] 匹配指定字符组的任一个字符。 /[Xx]xx/ [^] 匹配不在指定字符组内的任一字符。 /[^Xx]xx/ \(..\) 匹配拆分子串,下标从 1 开始,在替换字符串中使用 \1、\2 对其进行引用。 s/\(love\)a\(b\)le/\1rs\2/ -> loversb & 保存查找串,在替换字符串中使用 & 进行引用。 s/my/**&**/ -> **my** \< 词首定位符,匹配 xx 开头的词。 /\<xx/ \> 词尾定位符,匹配 xx 结尾的词。 /xx\>/ x\{m\} 匹配重复 x 行 m 次的行。 /x\{5\}/ x\{m,\} 匹配重复 x 行至少 m 次的行。 /x\{5,\}/ x\{m,n\} 匹配重复 x 行至少 m 次,但是少于 n 次的行。 /x\{5,10\}/
注:
s@regexp@replacement@ 等同于 s/regexp/replacement/
如果 replacement 是目录,即存在 "/",使用 s/regexp/replacement/ 需要对 "/" 进行转义(不太方便)。使用 s@regexp@replacement@ 可以不用转义。
举例:
temp=https://www.baidu.com/
echo ${SendSQSQueue} # https://www.baidu.com/
temp=$(echo ${temp} | sed "s@\/@\\\/@g")
echo ${SendSQSQueue} # https:\/\/www.baidu.com\/
(3)举例(数字)
【vi test.txt】 java javascript python c++ go 【sed -n '2p' test.txt 仅输出 test.txt 第二行内容】 javascript 【sed -n '3,$p' test.txt 输出第 3 行 到最后一行的内容】 python c++ go 【sed -n '2,+2p' test.txt 输出第 2 行开始,到第 4 行(2+2=4)的内容】 javascript python c++ 【sed -n '2~3p' test.txt 输出从第 2 行开始,每隔 3 行的内容】 javascript go
(4)举例(字符)
【vi test.txt】 java javascript python c++ go 【sed -e '2a\hello' test.txt 在 第二行 与 第三行 之间 插入新的一行 hello。此时 hello 作为新的第三行单独存在】 java javascript hello python c++ go 【sed -e '3c\helloworld' test.txt 使用 helloworld 替换 第三行】 java javascript helloworld python c++ go 【sed -e '3i\world' test.txt 在 第三行 之前插入 新的一行 world】 java javascript world helloworld python c++ go 【sed -e '3,4d' test.txt 删除第三行、第四行】 java javascript python c++ go
(5)举例(正则表达式)
【vi test.txt】 java javascript python c++ go 【sed -n '/^java/p' test.txt 输出所有以 java 开头的行】 java javascript 【sed -n '/.*va/p' test.txt 输出包含 va 的行,若写成 /*va/ 的形式,可能匹配不到数据】 java javascript 【sed -n '/\<ja/p' test.txt 输出包含 ja 开头的词的行】 java javascript 【sed -n '/\>++/p' test.txt 输出包含 ++ 结尾的词的行】 c++ 【sed -e 's/c++/c--/' test.txt 替换 c++ 为 c--】 java javascript python c-- go 【sed -e 's/\(c\)\(++\)/\1--/' test.txt 替换字符串,\1 用于替代 \(c\),最终效果为 c++ -> c--】 java javascript python c-- go 【sed -e 's/c++/--&&--/' test.txt & 用于替代查找串,此处 & 等同于 c++】 java javascript python --c++c++-- go
【sed -E "s@(ja)(.*)@\1x/x@" test.txt 等同于 sed -E "s/(ja)(.*)/\1x\\/x/" test.txt】
jax/x
jax/x
python
c++
go
二、网络相关
1、netstat(显示网络状态)
(1)基本概念
netstat 命令用于显示网络状态。
通过 netstat 可以知道整个 Linux 系统的网络情况。
(2)语法规则
【语法:】 netstat [options] 【options:】 -a, --all 显示所有的网络状态(包括 监听、非监听的 Socket) -l, --listening 只显示正在监听的 Socket -c, --continuous 持续的列出网络状态 -C, --cache 显示路由缓冲中的路由信息 -e, --extend 显示网络其他相关信息 -F, --fib 显示路由缓冲信息 -n, --numeric 显示 ip 地址而不是去解析域名获取 主机、端口或用户名。 -o, --timers 显示与网络定时器有关的信息。 -p, --program 显示 Socket 所属进程的 PID 和名称。 -t, --tcp 显示 TCP 传输协议的连线状况。 -u, --udp 显示 UDP 传输协议的连线状况。 -i, --interfaces 显示网络界面信息表单(网卡信息)。
(3)举例
【显示网卡相关信息:】 netstat -i 【显示 tcp 连接情况:】 netstat -nltp
2、telnet(连接远程机器,确认机器端口是否开放)
(1)基本概念
telnet 命令用于使用 TELNET 协议与另一个主机进行交互通信。
可以对另一主机进行远程登录、管理操作(有些 linux 服务器不支持 telnet,使用 ssh)。
可以通过 telnet 来确认远程主机的某个端口是否开放。也是日常网络故障排错的重要一部分。
(2)安装
【centos7: 】 yum -y install telnet-server yum -y install telnet
(3)语法规则
【语法:】
telnet [options] [ip] [port]
【options:】
此处省略,通过 man telnet 可以查看语法规则。
(4)举例
【连接远程主机:】 telnet 192.168.210.157 【确认远程主机上某个端口是否可用:】 telnet 192.168.210.157 8080 注: 输出中出现 "Escape character is '^]'" 即表示端口开放。
3、nslookup(查询域名服务器)
(1)基本概念
nslookup 是一个查询 Intelnet 域名服务器的程序。有两种模式: 交互式、非交互式。
交互模式允许 用户查询名称服务器 以获取有关 各种主机 和 域的信息 或 输出域中的主机列表。
非交互模式仅用于输出主机 或 域的名称 等信息。
(2)语法规则
【语法:】 nslookup [options] domain [DNS-Server] 【options:】 此处省略,通过 man nslookup 可以查看语法规则。
(3)举例:
【查询百度域名情况:】 nslookup www.baidu.com Server: 192.168.157.2 Address: 192.168.157.2#53 Non-authoritative answer: www.baidu.com canonical name = www.a.shifen.com. Name: www.a.shifen.com Address: 14.215.177.38 Name: www.a.shifen.com Address: 14.215.177.39 【指定域名服务器进行查询:】 nslookup www.baidu.com 8.8.8.8 Server: 8.8.8.8 Address: 8.8.8.8#53 Non-authoritative answer: www.baidu.com canonical name = www.a.shifen.com. Name: www.a.shifen.com Address: 14.215.177.38 Name: www.a.shifen.com Address: 14.215.177.39 【反向 DNS 解析:】 nslookup -ty=ptr 8.8.8.8 Server: 127.0.0.53 Address: 127.0.0.53#53 Non-authoritative answer: 8.8.8.8.in-addr.arpa name = dns.google. Authoritative answers can be found from:
三、系统内存、磁盘相关
1、free(显示内存使用情况)
(1)基本概念
显示机器内存使用情况(包括已用和未用的内存空间)。
显示 系统中 已用和未用的 物理内存和交换内存, 共享内存和 内核使用的 缓冲区的 总和。
(2)语法规则
【语法:】 free [options] 【options:】 -b, --bytes 以 B 为单位显示内存 -k, --kilo 以 KB 为单位显示内存(默认) -m, --mega 以 MB 为单位显示内存 -g, --giga 以 GB 为单位显示内存 -h, --human 优化输出,数据显示带单位 -t, --total 额外增加一个 total 行,显示总和 -s N, --seconds N 每隔 N 秒输出一次 -c N, --count N 输出 N 次后退出
(3)举例
【free -h】 total used free shared buff/cache available Mem: 1.8G 763M 256M 20M 799M 852M Swap: 2.0G 776K 2.0G 【free -h -s 2 -c 3】 total used free shared buff/cache available Mem: 1.8G 762M 257M 20M 799M 853M Swap: 2.0G 776K 2.0G total used free shared buff/cache available Mem: 1.8G 762M 257M 20M 799M 853M Swap: 2.0G 776K 2.0G total used free shared buff/cache available Mem: 1.8G 762M 257M 20M 799M 853M Swap: 2.0G 776K 2.0G
2、df(显示磁盘使用情况)
(1)基本概念
显示目前在 Linux 系统上的文件系统磁盘使用情况统计。
(2)语法规则
【语法:】 df [options] [file] 【options:】 -a, --all 列出所有的文件系统 -h,--huma-readable 以易读的方式列出,带单位 -H, --si 与 -h 类似,但是计数单位为 1000,不是 1024 -T, --print-type 输出每个文件的类型 --type=TYPE 只显示指定类型的文件系统 --exclude-type=TYPE 只显示指定类型以外的文件系统
(3)举例
【df -Th】 文件系统 类型 容量 已用 可用 已用% 挂载点 devtmpfs devtmpfs 894M 0 894M 0% /dev tmpfs tmpfs 910M 0 910M 0% /dev/shm tmpfs tmpfs 910M 19M 892M 3% /run tmpfs tmpfs 910M 0 910M 0% /sys/fs/cgroup /dev/mapper/centos-root xfs 17G 13G 4.2G 76% / /dev/sda1 xfs 1014M 184M 831M 19% /boot tmpfs tmpfs 182M 12K 182M 1% /run/user/42 tmpfs tmpfs 182M 0 182M 0% /run/user/0 【df --exclude-type=xfs -hT】 文件系统 类型 容量 已用 可用 已用% 挂载点 devtmpfs devtmpfs 894M 0 894M 0% /dev tmpfs tmpfs 910M 0 910M 0% /dev/shm tmpfs tmpfs 910M 19M 892M 3% /run tmpfs tmpfs 910M 0 910M 0% /sys/fs/cgroup tmpfs tmpfs 182M 12K 182M 1% /run/user/42 tmpfs tmpfs 182M 0 182M 0% /run/user/0
3、du(显示文件占用磁盘空间)
(1)基本概念
显示指定的目录或文件所占用的磁盘空间。
默认为当前目录。
(2)语法规则
【语法:】 du [options] [file] 【options:】 -a, --all 显示对所有文件的统计,而不只是包含子目录。 -b, --bytes 输出以字节为单位的大小,替代缺省时1024字节的计数单位。 -c, --total 在处理完所有参数后给出所有这些参数的总计。即用于统计指定的一组文件或目录使用的空间的总和。 -h, --human-readable 以易读的方式输出,带单位 -s或--summarize 只显示指定目录占用磁盘空间的总和(不与 a 连用)。
(3)举例
【ls -lh】 总用量 11M drwxr-xr-x. 9 root root 220 3月 19 2021 apache-tomcat-9.0.44 -rw-r--r--. 1 root root 11M 3月 19 2021 apache-tomcat-9.0.44.tar.gz 【du -shc *】 17M apache-tomcat-9.0.44 11M apache-tomcat-9.0.44.tar.gz 28M 总用量
4、mount(挂载文件系统)
(1)基本概念
用于挂载文件系统。
(2)语法规则
【语法:】 mount [-lhV] mount -a [-frvw] [-t vfstype] [-O optlist] mount [-frvw] [-o option[,option]...] device|dir mount [-frvw] [-t vfstype] [-o options] device dir 【options:】 -a, --all 挂载 /etc/fstab 中的定义的所有文件系统 -t, --types <列表> 限制文件系统类型集合 -T, --fstab <路径> /etc/fstab 的替代文件 -v, --verbose 打印当前进行的操作 -o, --options <列表> 挂载选项列表,以英文逗号分隔 -f, --fake 模拟 mount 动作,并未真正执行,通常与 -v 连用 -r, --read-only 以只读方式挂载文件系统(同 -o ro) -w, --rw, --read-write 以读写方式挂载文件系统(默认)
(3)举例
【挂载类型为 cifs 的目录】 mount -t cifs --verbose -o vers=3.0,sec=ntlmsspi,cred=/home/ec2-user/creds.txt,rsize=130048,wsize=130048,cache=none //172.24.14.0/share /mnt/fsx 【挂载 /etc/fstab 定义的文件系统】 mount -a 【cat /etc/fstab】 /dev/mapper/centos-root / xfs defaults 0 0 UUID=2a32db5c-0484-4f80-b574-74fd01ff36e0 /boot xfs defaults 0 0 /dev/mapper/centos-swap swap swap defaults 0 0
5、top(显示系统运行情况)
(1)基本概念
用于分析系统的整体性能,能够实时显示系统中各个进程的资源占用情况(类似于 Windows 中的 任务管理器)。
(2)语法规则
参考:https://www.cnblogs.com/l-y-h/p/12584563.html#_label0_7
(3)关注点
【load average:】 输出的第一行,表示系统运行时间、当前用户数、以及平均负载量(load average)。 其中: load average 三个数分别是 1 分钟、5 分钟、15 分钟的负载情况。 其一般与 CPU 以及 内核数有关,数值越小系统占用越小(具体规则没有研究)。 【%Cpu(s) 中的 id:】 输出的第三行,表示用户 CPU 相关信息。 其中: id 表示 idle,为 CPU 空闲率。 注: 按键盘左上角 数字 1 可以展开逻辑 CPU 的运行情况(多核情况下可以看到各个 逻辑 CPU 情况)。 以 %Cpu0、%Cpu1、%Cpu2、%Cpu3 等形式展示。 【%CPU、%MEM:】 输出 PID、USER 的那行,显示各个进程的相关信息。 其中: PID 表示进程 ID。 USER 表示进程所属用户。 TIME+ 表示进程运行时间(占用 CPU 的时间)。 %CPU 表示进程占用 CPU 百分比。 %MEM 表示进程占用 内存 百分比。 COMMAND 表示进程名。 交互界面常用按键: Q 退出 top 。(Ctrl + C 也行) P 按照 CPU 占用率降序排序(默认, %CPU)。 M 按照 内存 使用率降序排序(%MEM)。 N 按照 PID 降序排序(PID)。 T 按照 占用 CPU 时间排序(TIME+)。
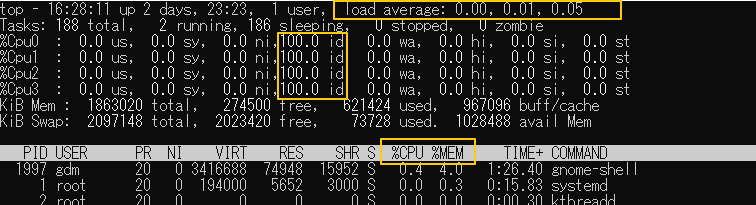
6、uptime(显示系统运行时间)
(1)基本概念
用于分析系统性能,可理解为 top 的简化版,其就相当于 top 输出的第一行,用于显示当前系统的负载情况。
(2)语法规则
【语法:】 uptime [options] 【options:】 -p 格式化输出系统运行时间 -s 显示系统启动时间
(3)举例
【uptime:】 16:46:23 up 2 days, 23:41, 1 user, load average: 0.00, 0.01, 0.05 【uptime -s:】 2021-12-14 17:05:10 【uptime -p:】 up 2 days, 23 hours, 41 minutes
7、vmstat(内存监测,显示虚拟内存统计信息)
(1)基本概念
Virtual Meomory Statistics(虚拟内存统计)的缩写,用来监控 CPU 使用、内存使用、IO 读写以及虚拟内存交换等信息(查看整个机器的使用情况而非各个进程使用情况,与 top 稍有区别)。
该信息可用于分析系统瓶颈。
(2)语法规则
【语法:】 vmstat [options] [delay [count]] 注: delay 表示时间间隔(秒) count 表示次数 比如: vmstat 2 3 表示 每隔 2 秒 输出一次,共输出 3 次。 【options:】 -t 输出时间戳 -w 更宽的显示输出内容 -s 显示统计信息 -d 显示磁盘情况 【输出信息:】 Procs r: 表示等待运行的进程数。这个值如果长期大于系统CPU个数,就说明CPU资源不足,可以考虑增加CPU。 b: 表示在等待资源的进程数(阻塞状态)。比如:正在等待I/O或者内存交换等。 Memory swpd: 虚拟内存使用情况,单位:KB free: 空闲的内存(free memory),单位KB buff: 被用来做为缓存的内存数(buffer memory),单位:KB cache: 用于文件缓存(swap cache),单位:KB Swap si: 从磁盘交换到内存的交换页数量,单位:KB/秒 so: 从内存交换到磁盘的交换页数量,单位:KB/秒 一般情况下,si、so 的值都为0,如果 si、so 的值长期不为 0,则表示系统内存不足,需要考虑是否增加系统内存 。 IO bi: 表示从块设备读入的数据总量(即读磁盘,块/秒) bo: 表示写入到块设备的数据总量(即写磁盘,块/秒) 默认块大小为 1024 KB。bi 和 bo 一般都要接近 0,不然就是 IO 过于频繁,需要调整。 System in: 每秒的中断数,包括时钟中断 cs: 每秒的环境(上下文)切换次数 in、cs 值越大,内核消耗的 CPU 时间就越多。 CPU us: 显示了用户进程消耗 CPU 的时间百分比。us 的值比较高时,说明用户进程消耗的 CPU 时间多。如果长期大于 50%,需要考虑优化用户进程。 sy: 显示了内核进程消耗 CPU 的时间百分比。sy 的值比较高时,就说明内核消耗的 CPU 时间多。如果 us+sy 超过 80%,需要考虑增加 CPU。 id: CPU 闲置时间百分比 wa: 表示 IO 等待所占的 CPU 时间百分比。wa 值越高,说明 IO 等待越严重。如果 wa 值超过 20%,说明 IO 等待严重
(3)举例
【vmstat -t 2 3:】 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- -----timestamp----- r b swpd free buff cache si so bi bo in cs us sy id wa st CST 1 0 73728 269416 4 973384 0 0 8 9 14 21 0 0 100 0 0 2021-12-17 17:07:48 0 0 73728 269400 4 973384 0 0 0 0 49 68 0 0 100 0 0 2021-12-17 17:07:50 0 0 73728 269400 4 973384 0 0 0 0 35 57 0 0 100 0 0 2021-12-17 17:07:52
8、iostat(磁盘 IO 监测)
(1)基本概念
用于输出 CPU、磁盘 IO 等统计信息。
(2)语法规则
【语法:】 iostat [options] [delay [count]] 注: delay 表示时间间隔(秒) count 表示次数 比如: iostat 2 3 表示 每隔 2 秒 输出一次,共输出 3 次。 【options:】 -c 显示 CPU 情况 -d 显示磁盘 I/O 情况 -x 显示拓展信息。 -k 单位为 KB/S -m 单位为 MB/S 【输出:】 avg-cpu: %user 显示了用户进程消耗 CPU 的时间百分比。 %system 显示了内核进程消耗 CPU 的时间百分比。 %idle 显示了 CPU 闲置时间百分比。 %iowait 显示了 CPU 等待完成磁盘 I/O 的百分比。 Device: rrqm/s 每秒进行 merge 到 device 的读操作数目 wrqm/s 每秒进行 merge 到 device 的写操作数目 r/s 每秒 merge 完成的读 I/O 次数 w/s 每秒 merge 完成的写 I/O 次数 %util I/O 操作的百分比,值接近 100% 时,则表示 I/O 请求饱和(达到瓶颈)。
(3)举例
【iostat -xcdk 2 2:】 Linux 3.10.0-1160.42.2.el7.x86_64 (localhost.localdomain) 2021年12月17日 _x86_64_ (4 CPU) avg-cpu: %user %nice %system %iowait %steal %idle 0.06 0.00 0.06 0.03 0.00 99.86 Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util sda 0.00 0.14 0.90 0.33 30.87 36.15 109.06 0.05 43.57 31.85 75.63 1.60 0.20 scd0 0.00 0.00 0.00 0.00 0.00 0.00 114.22 0.00 23.89 23.89 0.00 22.94 0.00 dm-0 0.00 0.00 0.89 0.39 30.72 35.83 103.68 0.07 51.31 32.40 93.88 1.49 0.19 dm-1 0.00 0.00 0.01 0.08 0.03 0.31 8.17 0.00 54.10 5.83 58.16 2.44 0.02 avg-cpu: %user %nice %system %iowait %steal %idle 0.00 0.00 0.00 0.00 0.00 100.00 Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 scd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 dm-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
9、mpstat(CPU 监测)
(1)基本概念
用于输出 CPU 的统计信息。
(2)语法规则
【语法:】 mpstat [options] [delay [count]] 注: delay 表示时间间隔(秒) count 表示次数 比如: mpstat 2 3 表示 每隔 2 秒 输出一次,共输出 3 次。 【options:】 -A 显示所有 CPU 情况 【输出:】 %user 显示了用户进程消耗 CPU 的时间百分比。 %sys 显示了内核进程消耗 CPU 的时间百分比。 %idle 显示了 CPU 闲置时间百分比。 %iowait 显示了 CPU 等待完成磁盘 I/O 的百分比。 %soft 软中断时间百分比 %irq 硬中断时间百分比
(3)举例
【mpstat 2 3:】 Linux 3.10.0-1160.42.2.el7.x86_64 (localhost.localdomain) 2021年12月17日 _x86_64_ (4 CPU) 18时21分07秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle 18时21分09秒 all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 18时21分11秒 all 0.12 0.00 0.12 0.00 0.00 0.00 0.00 0.00 0.00 99.75 18时21分13秒 all 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 平均时间: all 0.04 0.00 0.04 0.00 0.00 0.00 0.00 0.00 0.00 99.92
四、其他命令
1、nohup(后台运行程序)
(1)基本概念
nohup 即 no hang up(不挂起),即使关闭连接终端也不会终止程序的运行。
默认情况下,会在当前目录下生成一个名为 nohup.out 的文件。
(2)语法规则
【语法规则:】 nohup Command [ & ] 注: Command 为要执行的命令 & 表示命令在后台执行,终端退出后命令仍旧执行。 nohup 与 & 连用,可以让程序在后台执行,且退出用户终端也不会停止。
(3)举例
【后台启动 helloworld.jar 】 nohup java -jar helloworld.jar & 【要杀死进程:】 ps -aux | grep "helloworld" # 先找到后台进程 kill -9 PID # 再根据进程号杀死进程
2、wget(网络文件下载工具)
(1)基本概念
wget 是一款非交互式的网络文件下载工具。
(2)安装
【centos7:】
yum install -y wget
(3)语法规则
【语法:】 wget [options] [url] 【options:】 -r, --recursive 递归下载 -q, --quiet 安静下载,无信息输出 -v, --verbose 输出详细信息(默认) 注: 通过 wget --help 可以查看详细描述,此处省略
(4)举例
【获取 git 数据】
wget https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip
3、curl(发送请求、下载文件)
(1)基本概念
curl 一般用于向服务器发送请求,默认发送 Get 请求。
当与 -o 或 -O 参数连用时,可以用于下载文件。
(2)安装
【centos7:】
yum install -y curl
(3)语法规则
【语法:】 curl [options] [url] 【options:】 -b xxx 向服务器发送 cookie 数据 -c xxx 将服务器返回的 cookie 数据写入本地文件 -d xxx 发送 POST 的数据体,可以省略 -X POST -o xxx 将服务器回应保存为文件,功能等同于 wget -O 无需指定文件名,默认使用 URL 最后部分作为文件名 注: 通过 man curl 或者 curl --help 可以查看详细描述,此处省略
(4)举例
【向服务器发送 cookie 数据】 curl -b 'foo1=bar;foo2=bar2' https://www.baidu.com/ curl -b cookies.txt https://www.baidu.com/ 【将服务器返回的 cookie 数据写入文件】 curl -c cookies.txt https://www.baidu.com/ 【向服务器发送 POST 数据体】 curl -d'login=emma&password=123'-X POST https://baidu.com 【将回应数据保存在 test 中】 curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" 【默认文件名为 blog.git】 curl -O "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip"
五、设置开机自动启动脚本(CentOS7)
1、方式一:crontab 定时任务
crontab 开机自启动,通过 crontab 执行命令,可以间接的实现 开机自启动脚本。
crontab 用法见 https://www.cnblogs.com/l-y-h/p/15379861.html#_label0_0
2、方式二:修改脚本 (/etc/rc.local、/etc/rc.d/rc.local)
(1)基本认识
/etc/rc.local 是 /etc/rc.d/rc.local 的软连接,linux 机器重启的时候会去加载 这个文件。
将待执行的命令 写入 /etc/rc.d/rc.local 文件中,并给其可执行权限(默认没有执行权限)。
chomd +x /etc/rc.d/rc.local
重启机器后会加载 /etc/rc.d/rc.local 中的命令。
(2)cat /etc/rc.d/rc.local
#!/bin/bash # THIS FILE IS ADDED FOR COMPATIBILITY PURPOSES # # It is highly advisable to create own systemd services or udev rules # to run scripts during boot instead of using this file. # # In contrast to previous versions due to parallel execution during boot # this script will NOT be run after all other services. # # Please note that you must run 'chmod +x /etc/rc.d/rc.local' to ensure # that this script will be executed during boot. touch /var/lock/subsys/local
3、方式三:注册系统服务(chkconfig)
(1)基本认识
【linux 系统启动级别:】 级别有0-6共7个级别。 运行级别0:系统关机状态,默认级别不能设为 0,否则不能正常启动(一启动就关机)。 运行级别1:单用户工作状态,用于系统维护、找回 root 密码等,禁止远程登录,只能在当前计算机上操作。 运行级别2:多用户状态(无网络服务)。 运行级别3:多用户状态(有网络服务)。 运行级别4:作为保留级别,未使用。 运行级别5:图形界面状态。 运行级别6:系统重启状态,默认级别不能设为 6,否则不能正常启动(一启动就重启)。 【chkconfig:】 chkconfig 用于更新和查询系统服务的运行级别信息。 chkconfig 提供了一个简单的命令行工具,用于维护 /etc/rc[0-6].d 目录层次结构,免除了系统管理员直接操作这些系统中大量符号链接的任务目录。 chkconfig 不是立即自动禁止或激活一个服务,它只是简单的改变了符号连接。
(2)语法规则
【语法:】 chkconfig [--list] [--type <type>] [name] chkconfig --add <name> chkconfig --del <name> chkconfig --override <name> chkconfig [--level <levels>] [--type <type>] <name> <on|off|reset|resetpriorities> 【参数说明:】 -–add 增加所指定的系统服务,让 chkconfig 指令得以管理它,并同时在系统启动的叙述文件内增加相关数据。 -–del 删除所指定的系统服务,不再由 chkconfig 指令管理,并同时在系统启动的叙述文件内删除相关数据。 -–level 指定系统级别(0-6),表示服务在哪个级别启动、关闭。 --list 列出服务信息。 【on、off、reset 说明:】 如果在服务名后面指定了 on,off 或者 reset,那么 chkconfig 会改变指定服务的启动信息。 on 和 off 分别指服务被启动和停止,reset 指重置服务的启动信息。 对于 on 和 off,系统默认只对运行级 2,3,4,5 有效。reset 对所有级别均有效。
(3)如何新增一个服务
【步骤:】 Step1:服务脚本必须存放在/etc/init.d/目录下。编辑脚本。 Step2:使用 chkconfig --add 添加服务。 注: 假设服务名为myservice, 当我们运行添加服务的命令时候,会出现 "service myservice does not support chkconfig"。 一般在脚本开头加入 "#chkconfig: 2345 10 90" 即可: 其中: 2345 是系统启动级别,10是启动优先级,90是停止优先级,优先级范围是0-100,数字越大,优先级越低。 执行 --add 后,会在 /etc/rc[0-6].d 中创建软链接。
(4)举例:
【chkconfig --list】 netconsole 0:关 1:关 2:关 3:关 4:关 5:关 6:关 network 0:关 1:关 2:开 3:开 4:开 5:开 6:关 【vi /etc/init.d/autoStartUp.sh】 #!/bin/bash # chkconfig: 2345 20 90 # description: autoStartUp 【chkconfig --add /etc/init.d/autoStartUp.sh】 【ls -lh /etc/rc0.d/ /etc/rc2.d/】 /etc/rc0.d/: 总用量 0 lrwxrwxrwx. 1 root root 20 10月 8 21:42 K50netconsole -> ../init.d/netconsole lrwxrwxrwx. 1 root root 24 10月 11 22:11 K90autoStartUp.sh -> ../init.d/autoStartUp.sh lrwxrwxrwx. 1 root root 17 10月 8 21:42 K90network -> ../init.d/network /etc/rc2.d/: 总用量 0 lrwxrwxrwx. 1 root root 20 10月 8 21:42 K50netconsole -> ../init.d/netconsole lrwxrwxrwx. 1 root root 17 10月 8 21:42 S10network -> ../init.d/network lrwxrwxrwx. 1 root root 24 10月 11 22:11 S20autoStartUp.sh -> ../init.d/autoStartUp.sh 【chkconfig --list】 autoStartUp.sh 0:关 1:关 2:开 3:开 4:开 5:开 6:关 netconsole 0:关 1:关 2:关 3:关 4:关 5:关 6:关 network 0:关 1:关 2:开 3:开 4:开 5:开 6:关 【chkconfig --del /etc/init.d/autoStartUp.sh】 netconsole 0:关 1:关 2:关 3:关 4:关 5:关 6:关 network 0:关 1:关 2:开 3:开 4:开 5:开 6:关
4、方式四:注册系统服务(systemctl )
(1)基本认识
【systemd 与 systemctl】 systemctl 是 CentOS7 采用的 用于 Linux 启动处理和系统管理的机制,可以理解为 systemd 的管理工具。 systemd 是 CentOS7 完成引导程序进入操作系统后启动的第一个进程。可用于管理 服务 的启动顺序。 chkconfig 是 CentOS6 使用的。 【linux 启动流程】 在电源打开时启动 BIOS 从 BIOS 调用引导加载程序 引导加载程序引导 Linux 内核 Linux 内核启动 init 进程 (PID 1) Systemd 是 init 进程。
(2)语法规则
【语法:】 systemctl [OPTIONS...] [COMMAND] 【options:】 list-unit-files 列出所有可用单元 list-units 列出所有运行中的单元 list-unit-files --type=service 列出指定类型的单元 enable、disable 开启、禁用 服务 status/start/restart/stop 查看、启动、重启、关闭 服务 daemon-reload 重新加载 systemd 管理器配置 【常用命令:】 systemctl list-unit-files systemctl list-units systemctl list-unit-files --type=mount systemctl enable/disable xxx systemctl status/start/restart/stop xxx systemctl daemon-reload
(3)如何新增一个服务
【步骤:】 Step1:服务脚本必须存放在 /etc/systemd/system 目录下。 Step2:创建后缀名为[.service]的文件,并进行编辑。 Step3:使用 systemctl daemon-reload 重新加载 systemd 管理器配置。 注意: xx.service 有具体格式写法,不能乱写。 【xx.service 文件格式说明:】 [Unit] Description: 描述Unit的说明和依赖关系等 Before:此服务启动于右侧配置的组件之前 After:此服务启动于右侧配置的组件之后 [Service] Type: 服务过程启动完成的判定方法(默认为simple) PIDFile: 主进程PID文件 KillSignal: Systemctl stop命令发送哪个信号 TimeoutStopSec: 在停止结束前待机的时间 ExecStart: 服务的启动命令 ExexReload: 服务的重载命令 ExecStop: 服务的停止命令 ExecStartPre: 服务启动前的附加命令 ExecStartPost: 服务启动后的附加命令 ExecStopPost: 服务停止后执行的命令 Restart: 服务进程停止时的重启条件 PrivateTmp: 是否准备 /tmp 和 /var/tmp 专用于这个服务 KillMode: 如何使用未停止的进程 [Install] WantedBy: 启用时在此单元的 .wants 目录中创建链接 Requiredby: 启用时在此单元的 .required 目录中创建链接 【注意:(获取环境变量)】 systemd 的执行时不会加载用户 Shell 里的环境变量,如果需要从环境变量中取值,需要 service 中配置 Environment。 Environment= EnvironmentFile= 【注意:(Type=forking)】 Type 指定了在 ExecStart 中指定的命令启动服务进程时如何判断启动完成。 例如: 对于在 foie gras 中继续运行的命令, 使用 Type = simple, 表示执行命令时,判断启动完成。 或者: fork子进程并把它放在后台,如果第一个命令本身就是结束的类型, 设置 Type = forking, 在这种情况下,当执行的命令完成时,判断启动完成。
(4)举例
【vi /etc/systemd/system/test.service】 [Unit] Description=Test Service Server After=network.target remote-fs.target nss-lookup.target [Service] Type=simple PIDFile=/run/nginx.pid ExecStartPre=/usr/bin/rm -f /run/nginx.pid ExecStart=/usr/sbin/nginx ExecReload=/bin/kill -s HUP $MAINPID KillSignal=SIGQUIT TimeoutStopSec=5 Restart=always WorkingDirectory=/usr/local/test ExecStart=/usr/local/test/test.sh KillMode=process [Install] WantedBy=multi-user.target 【systemctl daemon-reload】 【systemctl list-unit-files | grep test】 test.service disabled

