
Redis 基本认识(笔试、面试题)
一、Redis
1、简介
【官方简介地址:】 https://redis.io/topics/introduction
看不懂不要紧,先混个眼熟,慢慢来...。
【初步认识 Redis:】 Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker. 【翻译:】 Redis 是一个开源的、基于内存的数据存储结构,可以作为数据库、缓存、消息中间件。 【重点:】 基于内存、支持多种数据结构、常用于缓存。
2、为什么使用 Redis 作为缓存?
(1)为什么要使用缓存?
对于一个系统来说,若直接操作数据库,每次读写都经过磁盘操作,当并发量过高时,磁盘读写速度极大地影响系统的性能。使用缓存,即在访问磁盘前设置一个缓冲区,若缓冲区没有数据,再去数据库进行操作,这样可以极大地减少磁盘操作,从而提高系统性能。
(2)Redis 是基于内存的、一个高性能的 key - value 数据库(非关系型数据库)。
内存的处理速度比操作磁盘快,可以提高性能。
缓存分担了部分请求,减少了数据库访问压力,提高了并发量。
说起 key - value 库,容易想到 Java 中的 Map,map 实现的是本地缓存(即每台机器各自拥有自己的缓存),容量有限,随着 JVM 存在、消失。而 Redis 实现的是分布式缓存(即多台机器可以共享一份缓存数据),其数据可以持久化到硬盘中,可以自定义缓存过期机制。
3、Redis 的数据结构?使用场景?
(1)常用命令:
【参考地址:】 http://doc.redisfans.com/ https://www.cnblogs.com/l-y-h/p/12656614.html
(2)常用数据结构:
Redis 是由 C 语言编写的,其存储是以 key - value 的形式。key 为字符串,value 为 Redis 的数据结构。常用数据结构为:string、list、set、hash、sortedset。
底层实现原理,以后有空再去研究...
不同数据结构,若采用不同的编码格式,底层会有不同的实现。
(3)常用数据结构使用场景(举例,可能不太恰当,大致理解一下):
String 使用场景:
比如:一些博客、文章的阅读量、点赞数等。
可以根据 文章 ID 生成一个键。当某用户阅读、点赞后,在相应的 value 上加 1。
比如 :
key 为 文章阅读量:文章id,
value 为对应的 文章阅读量。
可以通过 incr、decr 等进行加减阅读量。
【根据文章ID 生成一个 key:(每个文章都有不同的 id,从而区分不同的 key)】 set article:readcount:1001 0 文章 id 为 1001 的文章当前阅读量为 0 set article:readcount:1002 0 文章 id 为 1002 的文章当前阅读量为 0 【阅读时,数量增 1:】 incr article:readcount:1001 文章 id 为 1001 的文章阅读量加 1 【获取阅读量:】 get article:readcount:1001 获取文章 id 为 1001 的文章阅读量
Hash 使用场景:
比如:电商网站的购物车。
可以根据 用户ID 生成一个 key,商品 ID 为 field,商品数量为 field 对应的 value。
可以使用 hgetall 获取所有的 field - value,即实现全选。
可以使用 hincrby 对指定的 field 修改数量。
可以使用 hlen 获取当前购物车商品的种类。等等操作。
比如:
key 为 用户 ID user:用户 ID
field 为 商品 ID wares:商品 ID
value 为 商品数量 商品数量
注:
其余信息可以通过 ajax 根据 用户 ID 、商品 ID 进行查询并返回显示。
【根据用户 ID、商品 ID、商品数量 生成一个 key,】 hset user:10001 wares:3001 1 给 10001 用户 添加 一个 3001 商品。 hset user:10001 wares:3002 2 给 10001 用户 添加 两个 3002 商品。 【全选操作:】 hgetall user:10001 获取 10001 用户所有的 商品(field)以及数量(value) 【增加商品数量:】 hincrby user:10001 wares:3002 3 给 10001 用户再增加 3 个 3002 商品

List 使用场景:
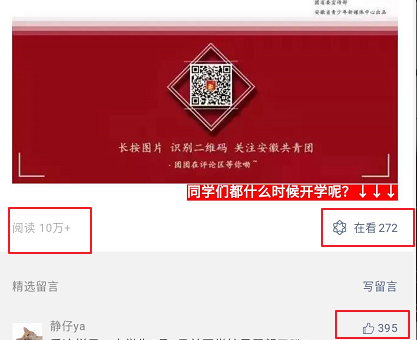
比如:微信订阅号推送的消息。
不同的公众号推送消息有先有后,最后是按照时间顺序进行排序显示(最近的时间显示在最上面)。
可以使用 List 存储接收的消息 ID。每接受一个 公众号消息 的 ID,就 LPUSH 进 List 中,最后使用 LRANGE 去获取最新的推送消息。
【接收公众号推送消息的 ID:】 LPUSH msg:我的订阅号-id 安徽共青团:10001 LPUSH msg:我的订阅号-id 唐唐频道:20001 LPUSH msg:我的订阅号-id 全是黑科技:34811 LPUSH msg:我的订阅号-id 程序人生:2233 LPUSH msg:我的订阅号-id 共青团中央:32345 【展示公众号 ID:】 LRANGE msg:我的订阅号-id 0 -1

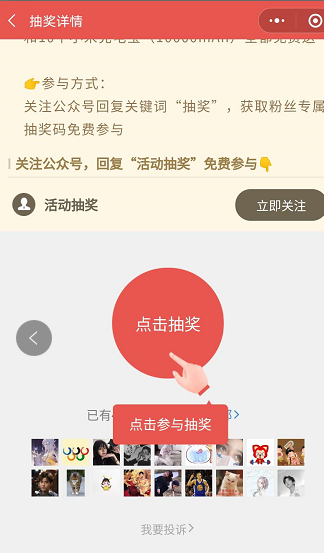
Set 使用场景:
比如:抽奖小程序,获取朋友圈点赞的用户信息,可能关注的人(需要使用并集等操作)等。
抽奖就是在一堆用户中随机抽取用户。由于 Set 不可重复性,可以保证用户唯一。
使用 SADD 可以添加用户 ID 到 set 中。
使用 SMEMBERS 可以查看当前参与抽奖的所有元素。
使用 SRANDMEMBER、SPOP 可以抽取获奖者用户。
【添加用户:】 sadd user 1001 1002 1003 1004 【查看所有用户:】 smembers user 【抽选用户,不删除用户:】 srandmember user 3 【抽选用户,删除用户:】 spop user 3
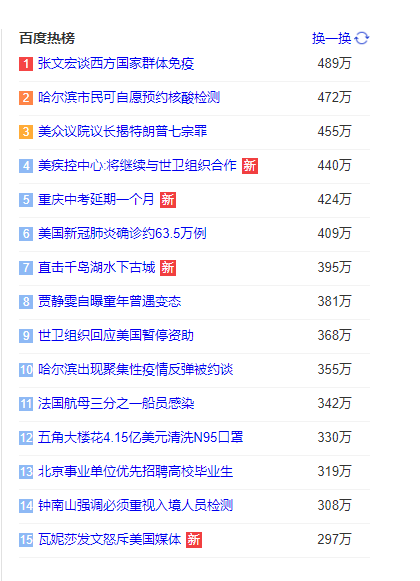
sortedset(zset)使用场景:
比如:微博热搜榜、百度热议榜等。
二、Redis 持久化、数据库、单线程
1、Redis 数据库
Redis 默认有 16 个库,库编号为 db0 - db15。数据库之间的数据是相互隔离的、互不影响的。
Redis 是 C/S 结构,有一个 redis-cli 和 redis-server。 redis-server 用于启动 Redis 服务,默认数据库数量为 16,可以修改。redis-cli 用于连接某个数据库。
数据库中采用哈希表存储键值对,其中 value 可以为不同类型的数据结构。
2、Redis 键过期处理
(1)为什么进行过期处理?
Redis 是基于内存的,内存容量比较有限,如果长期将 key - value 存放在 内存中,会占用大量内存,这样肯定是不行的,所以需要对 key 设置过期时间,当 key 过期后,系统响应并将其删除,从而减少内存的占用。
(2)过期策略:
定时删除:到某个时间点,就进行删除 过期键 的操作,对 内存 友好,对 CPU 不友好。
惰性删除:每次获取键时,判断该键是否过期,过期则删除,对 CPU 友好,对 内存 不友好。
定期删除:每过一段时间,就去删除 过期键。
Redis 中采用 惰性删除 + 定期删除,即意味着 某个键 到了过期时间,也不一定会被立即删除。
(3)内存淘汰机制:
由于 Redis 可能会不及时的删除过期 key,导致 内存里堆积了很多没用的 key,会消耗大量内存。此时,需要通过内存淘汰机制,选择不需要的 key,并将其删除。
比如:设置消耗内存最大值,当超过内存最大值后,进行数据淘汰,将最近最少使用的 key 数据淘汰(一般应用于热搜排行榜的场景)。
【常见内存淘汰机制:】 allkeys-lru: 在所有 key 中,移除最近最少使用的 key(常用) allkeys-random: 在所有 key 中,随机移除 key。 volatile-lru: 在设置过期时间的 key 中,移除最近最少使用的 key volatile-random: 在设置过期时间的 key 中,随机移除 key。 volatile-ttl: 在设置过期时间的 key 中,优先移除 即将过期 的 key。
3、数据持久化 -- RDB
Redis 是基于内存的,Redis 一旦重启,所有数据都会丢失,所以一般会将数据持久化到硬盘中,Redis 重启后可以通过硬盘恢复数据。
Redis 采用两种方法进行数据持久化 -- RDB 、AOF。
(1)RDB(Redis DataBase)
RDB 基于快照,可以指定时间间隔、将某一时刻的所有数据保存到一个 RDB 文件中,是一个二进制文件,默认为 dump.rdb。Redis 启动时,若发现存在 rdb 文件,则会自动载入该文件(载入的过程是一个阻塞的状态)。
(2)通过三种方式可以实现 RDB。
Method1:SAVE 命令触发
客户端执行 SAVE 命令后,会阻塞当前 Redis 服务器(即 Redis 不能处理其他命令),直到 RDB 过程结束。若存在旧的 RDB 文件,会进行替换。(此方式若数据量过大,会影响系统性能)
Method2:BGSAVE 命令触发
客户端执行 BGSAVE 命令后,会创建一个子进程,由子进程来创建 RDB 文件,不会阻塞当前 Redis 服务器。
Method3:redis.conf 配置文件中配置
【save 格式:】 save m n 指的是 m 时间间隔内,至少出现了 n 次 key 变化,则进行保存 【举例:】 save 60 10000 指的是 60 秒内,至少出现了 10000 次 key 变化,则保存
(3)SAVE 与 BGSAVE 比较:
SAVE 属于 同步操作,会阻塞当前 Redis 服务器,但不会消耗额外内存。
BGSAVE 属于 异步操作,不会阻塞当前 Redis 服务器,但会消耗额外内存(创建子进程)。
(4)RDB 优缺点:
优点:
RDB 是全量备份,将数据压缩到二进制文件中,格式紧凑(文件小),适合数据备份以及恢复。
RDB 可以使用子进程去创建 RDB 文件,主进程不进行 磁盘操作。
缺点:
子进程进行持久化时,父进程若修改内存中的数据,子进程不会知晓,此时可能造成数据丢失。
4、数据持久化 -- AOF
(1)AOF(Append Only File)
AOF 指当 Redis 服务器执行写命令时,会将写命令 保存到 AOF 文件中(可以理解为日志记录)。
(2)AOF 执行流程:
Step1:命令追加到缓冲区
遇到写命令时,将命令写入 aof_buf 缓冲区。
Step2:确认是否需要将缓冲区内容写入文件。
通过配置文件 redis.conf 中 appendfsync 去确定是否将缓冲区内容写入文件。
appendfsync always # 每次有数据修改发生时都会写入AOF文件(磁盘开销大)。 appendfsync everysec # 每秒钟同步一次,该策略为AOF的默认策略(丢失 1 秒数据)。 appendfsync no # 从不同步。高效但是数据不会被持久化(数据丢失)。
Step3:文件从缓冲区写入到文件。
将缓冲区的内容写入到 aof 文件中。
不停的执行写命令操作后,会使得 aof 文件变得越来越大,可以使用 BGREWRITEAOF 命令进行 AOF 重写(可以合并 写操作命令,减少文件内容冗余),此重写基于当前 数据库数据重写,不需要读取旧的 aof 文件。
BGREWRITEAOF 命令会创建子进程,由子进程进行 AOF 重写,其会存在一个 AOF 重写缓冲区,重写缓冲区用于 记录 创建子进程后 主进程执行的 写操作。当子进程执行完 AOF 重写后,向父进程发送请求,将重写缓冲区的数据写入新的 aof 文件中,从而使 当前数据库 与 AOF 文件写操作一致。
(3)AOF优缺点:
优点:
可以更好的保护数据,默认进行 1 秒同步一次的操作,最多丢失 1 秒数据。
缺点:
AOF 文件过大,恢复数据速度较慢。
(4)AOF、RDB 如何选择?
AOF、RDB 可以同时使用,但服务器优先使用 AOF 文件进行数据还原。
AOF:丢失数据少(视 appendfsync 而定),文件体积大,恢复数据速度较慢。
RDB:可能丢失一部分数据,文件体积小,恢复数据速度较快。
5、为什么 Redis 是单线程?速度为什么快?
(1)为什么 Redis 是单线程的?
Redis 基于内存进行操作,CPU 不是 Redis 的瓶颈,且单线程 比 多线程容易实现。
(2)速度为什么快?
基于内存操作,读写速度快。
单线程操作,避免频繁上下文切换。
采用了非阻塞 I/O 多路复用机制,保证系统高吞吐量。
注:
非阻塞 I/O 多路复用机制,用来保证多个连接时的系统吞吐量(此处不展开,有时间再总结)。
多路 指的是 多个 socket 连接。
复用 指的是 共用 同一个线程。
简单的讲,就是使单线程高效的处理多个连接请求。
6、Redis 和 memcached 区别?
(1)Redis 可以将数据持久化到硬盘中,memcached 只能将数据存储在内存中(断电后消失)。
(2)Redis 支持多种数据类型,memcached 支持类型简单。
三、缓存雪崩、缓存穿透、缓存与数据库读写一致
1、缓存穿透是什么?如何解决?
(1)缓存穿透是什么?
缓存穿透指查询一个不存在的数据,且数据不在缓存中,则查询会从数据库查询,而数据库查不到数据,则不会将数据存储在缓存中。以致于每次查询都会绕过缓存,从数据库查数据,使缓存失效。
(2)缓存穿透的可能原因?解决?
原因:
请求的参数不合理。
比如数据库的 id 自增,且从 100 开始,但是每次请求都是 100 以下的 id 或者 负数的 id,则每次查询,缓存中没有值,直接去查数据库,而数据库查不到值,就不会将数据保存到缓存中,从而使缓存失效。
解决:
方式一:对参数进行过滤处理(比如 BloomFilter),不合法的参数不会访问到数据库。
方式二:当数据库找不到数据时,返回一个空对象到缓存中,并设置一个过期时间,这样就可以从缓存中获取数据了。
2、缓存雪崩是什么?如何解决?
(1)缓存雪崩是什么?
缓存雪崩指的是由于某种原因,导致缓冲层出现了问题,所有的请求(大量请求)直接访问数据库(可以理解为发生大量数据穿透),从而使数据库宕机。
(2)缓存雪崩的可能原因?解决?
原因一:
Redis 服务挂掉了,即缓存失效,所有请求不经过缓存直达数据库,数据库反应不过来而宕机。
如何解决:
Step1:应该尽量避免 Redis 服务挂掉。
为了实现 Redis 高可用,应该使用 主从模式 + 哨兵模式(或者采用 Redis 集群),尽量避免 Redis 服务挂掉。
Step2:应该尽量避免 数据库 挂掉。
万一 Redis 服务真的挂了,应当进行 熔断、降低、限流等操作,尽量避免数据库被干掉,至少要保证服务还能正常运行。
Step3:数据恢复。
对 Redis 数据进行持久化,重启 Redis 服务后,加载磁盘数据进行数据恢复。
原因二:
Redis 对数据设置了过期时间,同一时间这些数据失效,此时恰巧有大量请求同时访问这些数据,会穿过缓存直接访问数据库,造成大量缓存穿透,从而导致数据库宕机。
如何解决:
缓存的同时,将过期时间设置成随机值,此时能极大避免大量数据 过期时间一致。
3、缓存、数据库读写一致
(1)读操作流程:
Step1:查询缓存中是否存在数据,存在数据则直接返回。
Step2:缓存中不存在数据,则查询数据库中是否存在数据,存在数据,则将数据保存在缓存中,并返回数据。
(2)读写操作同时进行时可能出现数据不一致。
造成读写不一致的情况有很多。
比如一件商品,开始时 数据库、缓存里显示的库存数量均为 1000。此时读操作并没有问题。现在卖出一件商品,需要更新数据库,假如更新数据库数据成功,但是更新缓存数据失败 ,即此时数据库显示库存数量为 999,而缓存显示数量为 1000,则下次操作,获取到的商品数量仍为 1000,此时就造成了读写不一致。
(3)如何解决读写不一致?
方式一:一般给缓存的数据设置过期时间,数据过期则被删除,下次会从数据库查询并更新缓存。
方式二:保证数据库、缓存更新的原子性(分布式事务)。要么同时成功、要么同时失败。
(4)更新缓存、数据库的两种方式:
方式一:先删除缓存,再更新数据库。
方式二:先更新数据库,再删除缓存。
注:
对于更新缓存,一般直接删除某个数据,简单粗暴。下次读取时从数据库读取并保存到缓存中。
对于方式一(单线程情况):
若删除缓存失败,可以直接抛出异常,此时数据库与缓存数据均无变化,即数据一致。
若删除缓存成功,但是更新数据库失败,此时缓存中没有该数据,下次读取时,从数据库中读取并保存到缓存中,从而数据一致。
若删除缓存、更新数据库均成功,下次读取数据肯定一致。
对于方式一(高并发情况):
线程 A 进行更新操作,线程 B 进行读操作。
线程 A 删除缓存,此时线程 B 进行读取,发现缓存不存在,则直接从数据库中读取,并将该值存入缓存。
线程 A 对数据库数据进行更新,此时缓存中的值 与 数据库的值不一致了。
如何解决上述的数据不一致:
将命令操作积压到队列中(先进先出),进行串行化,比如先删除缓存,再更新数据库,最后再进行读取。
对于方式二(单线程情况):
若更新数据库失败,则直接抛出异常,此时数据库与缓存数据均无变化,即数据一致。
若更新数据库成功,但删除缓存失败,则数据库的数据为新数据,与缓存数据不一致了。
若更新数据库、删除缓存均成功,则下次读写的数据肯定一致。
如何解决上述的数据不一致:
不断重复删除 key,直至可以删除。
对于方式二(高并发情况):
线程 A 进行查询操作,线程 B 进行更新操作。
线程 A 查询时,恰好缓存失效,直接通过数据库进行查询,此时 线程 B 更新数据库数据,并进行缓存删除,然后 线程 A 将从数据库获取的数据写入缓存中,此时缓存数据与数据库数据不一致了。
上例情况发生概率很低,毕竟写操作的速度慢于读操作,且读操作要先于写操作进入数据库,且慢于写操作操作缓存,同时满足这个情况的概率只能说是走了狗屎运。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号