
DQL---条件查询、单行函数、多行函数、分组函数、数据类型
一、DQL
1、基本规则:
(1)对于日期型数据,做 *,/ 运算不合法,可以进行 +, - 运算。比如给日期加一天或减一个月,结果仍为一个日期。两个日期间只能为减法,返回两个日期相差的天数,两个日期间做加法没任何意义。
(2)包含空值(null)的数学表达式计算结果均为空值。
(3)给字段取别名时,别名使用 双引号 括起来(根据双引号里的内容显示),不加双引号时会转为大写。字段与别名间可以使用AS关键字,也可使用空格。
(4)oracle中连接字符是 || (也可以使用单行函数concat()), 不是java中的 + 。
(5)字符串使用 单引号 括起来,字符串区分大小写。
(6)distinct用于过滤重复的数据,但不能乱用。
(7)dual为虚表,是一个不存在的表,只为满足SELECT语法,通常用来测试表达式的结果。
2、DQL基本关键字
(1)SELECT后跟想查询的列,即最后显示的列。
(2)FROM后跟的是想查询的表。
(3)WHERE后跟的是查询限制条件。 WHERE后跟的是数字时,可以不用单引号引起,但若为字符串或者日期格式时,需要用单引号引起。
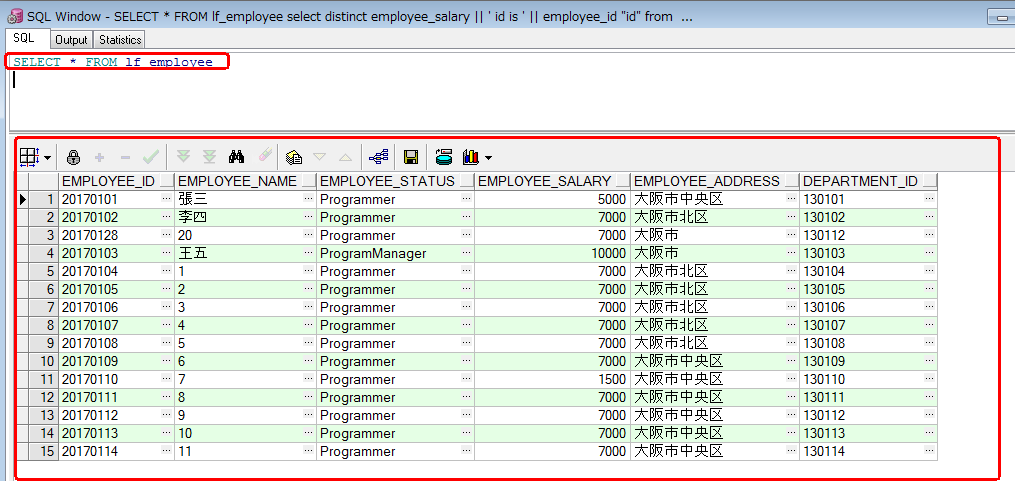
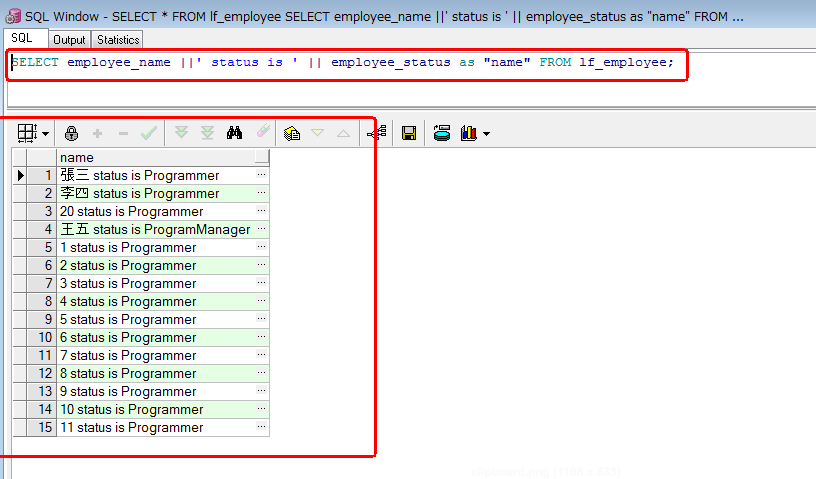
--举例: --打印系统时间 SELECT SYSDATE FROM dual; --只会显示一行’helloworld‘。 --输出整张表的信息 SELECT * FROM lf_employee; --使用字符串,别名,连接符输出表的信息 SELECT employee_name ||' status is ' || employee_status as "name" FROM lf_employee; --正确使用distinct关键字 SELECT distinct employee_status status, department_id as "Id" FROM lf_employee;
二、条件查询语句、以及排序
1、Between ... And ...
SELECT employee_name, employee_salary salary FROM lf_employee WHERE employee_salary BETWEEN 4000 AND 7000; --等价于employee_salary >= 4000 AND employee_salary <= 7000
2、操作符(AND, OR, IN)
比较操作符:>, < , =, >=, <= , <>(此为不等于,不建议写!=)。 关键字:AND(需同时满足条件),OR(满足一个条件即可 ),且AND优先级大于OR。 比较操作符:IN(list), NOT IN(list)。 list指集合,表示多个元素,IN(list)表示在list取出满足(一个)条件的数据,NOT IN(list)表示取出不符合条件的list数据。 IN等价于OR的用法。 ANY与ALL不能单独使用,其需要与>,<,=,<=,>=等连用。 >ANY 大于最小值。 >ALL 大于最大值。 <ANY 小于最大值。 <ALL 小于最小值。 ALL与IN的区别在于IN是进行值比较,ALL进行的是范围比较。 SELECT employee_name, employee_salary FROM lf_employee WHERE employee_salary in(4000, 5000, 6000); --等价于 employee_salary = 4000 OR employee_salary = 5000 OR employee_salary = 6000 SELECT employee_id, employee_salary FROM lf_employee WHERE employee_salary > ANY(1000, 2000) --等价于 employee_salary > 1000
3、like,模糊查询
-- % 表示匹配多个字符(0~n个字符) -- _ 表示匹配单个字符(1个字符) SELECT employee_name, employee_salary FROM lf_employee t WHERE t.employee_name like '_'; --表示查询名字为单个字符的人 SELECT employee_name, employee_salary FROM lf_employee t WHERE t.employee_name like '1%'; --表示查询以1开头的所有人名。
4、escape,转义字符
SELECT employee_name, employee_salary FROM lf_employee t WHERE t.employee_name like '%\_%' escape '\'; --表示查询含有_的名字。将通配符_转义为下划线_。 SELECT employee_name, employee_salary FROM lf_employee t WHERE t.employee_name like '%_%'; --查询所有名字
5、order by ... desc/asc,排序
SELECT employee_id, employee_salary FROM lf_employee t ORDER BY t.employee_salary asc, t.employee_id desc --先按照薪资升序排序,当薪资相同时,按照id降序排序。默认按照升序排序,即asc可不写。
6、DISTINCT
--去除列的重复行。 --对单列去重,则无重复行。 --对多列去重,则多列的组合不重复行。 SELECT DISTINCT employee_salary, employee_id FROM lf_employee --正确输出结果 SELECT employee_id,DISTINCT employee_salary FROM lf_employee --报错
三、单行函数
单行函数可以嵌套,执行循序为从内到外。
1、字符函数:
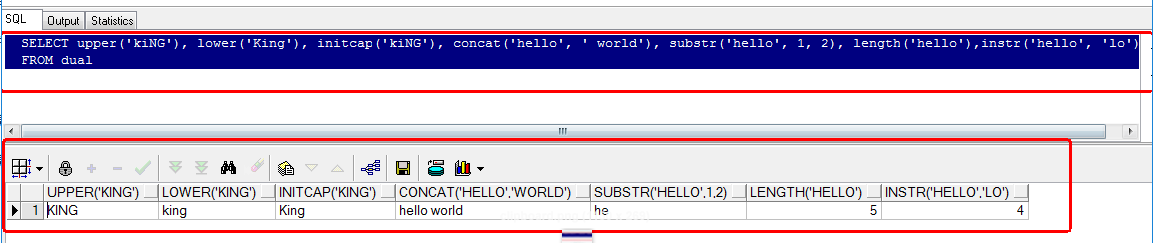
lower(char) --将字符串char转为全大写。 upper(char) --将字符串char转为全小写。 initcap(char) --将字符串char中每个单词的首字母转为大写,其余字母不变。 concat(char1, char2) --将两个字符串拼接。等价于 char1 || char2 。 substr(char, a, b) --截取字符串char,从第a个位置开始,输出b个字符。 length(char) --输出字符串char的长度。 instr(char1, char2) --返回字符串char2首次出现在字符串char1中的位置,不存在则返回0。 lpad(char1, n, char2) --左对齐,显示n位char1,不足的用char2补左边缺失的位。 rpad(char1, n, char2) --右对齐,显示n位char1,不足的用char2补右边缺失的位。 trim('h' from 'hhellohhworldhh') --去除首尾相同的字符 replace('abbbcd', 'bb', 'm') --替换匹配的字符 SELECT upper('kiNG'), lower('King'), initcap('kiNG'), concat('hello', ' world'), substr('hello', 1, 2), length('hello'),instr('hello', 'lo') FROM dual SELECT lpad(employee_salary, 10, '*'), rpad(employee_salary, 10, '*'), trim('h' from 'hhellohhworldhh'), replace('abbbcd', 'bb', 'm') FROM lf_employee

2、数字函数
ROUND(m[,n]) --四舍五入,round(45.926, 2) = 45.93 TRUNC() --截断,trunc(45.926, 2) = 45.92 --注意:若存在第二个参数,第二个参数为正数时,对小数点右边进行操作,为负数时,对小数点左边进行操作。 CEIL(n) --取大于或等于n的最小整数 FLOOR(n) --取小于或等于n的最大整数。 MOD(m, n) --求余,mod(1600, 300) = 1600%300 = 100 SELECT round(45.926, 2), round(45.926, -1), trunc(45.926, 2), trunc(45.926, -1), mod(1600, 300), mod(300, 1600) FROM dual

3、日期函数
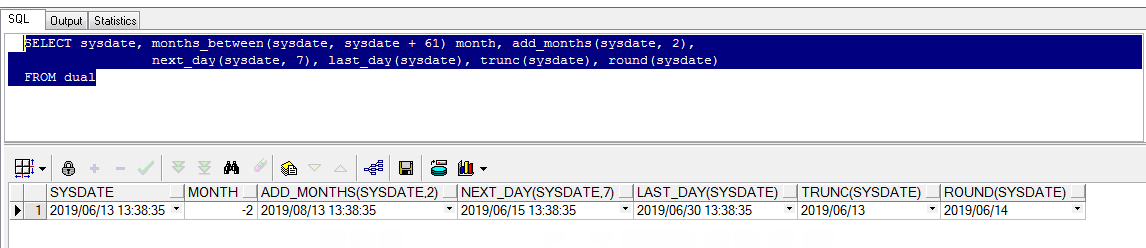
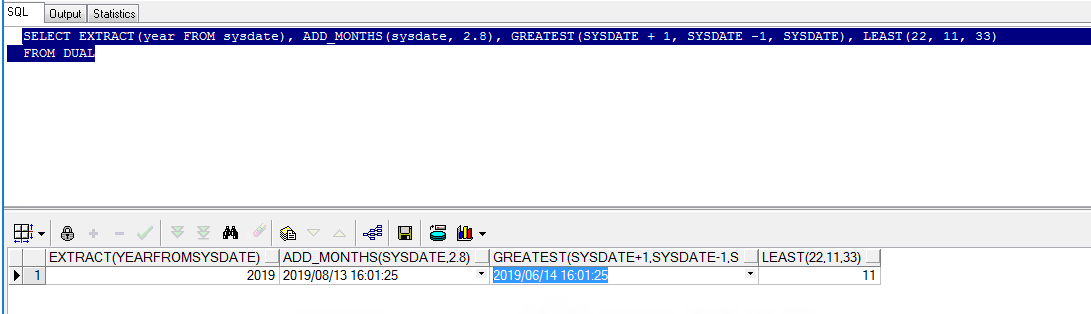
SYSDATE --返回当前系统时间,精确到秒。 SYSTIMESTAMP --返回当前系统时间,精确到纳秒。 MONTHS_BETWEEN (date1, date2) --用于计算date1和date2之间有几个月。若date1比date2早,则返回负数,若date1比date2晚,则返回正数,相同则返回0. ADD_MONTHS(date, month) --用于给date加上month个月,当month为小数时,会先被截取(trunc)成整数再参与运算。 NEXT_DAY(data, char) --表示data之后下一个星期几是哪天。若char表示为数字,即char为1~7时,表示星期日~星期六。 LAST_DAY(date) --表示date所在月的最后一天 ROUND(date) --将日期四舍五入 TRUNC(date) --将日期截断 EXTRACT(date from datetime) --从datetime中返回date指定的数据。 GREATEST(expr1[,expr2[,expr3]]) --为比较函数,返回参数中最大的值。 LEAST(expr1[,expr2[,expr3]]) --为比较函数,返回参数中最小的数。 -- 注意: 比较时,需要参数类型一致。比较时第二个参数会隐式转为第一个参数,若能够转换,则比较,否则会报错。 SELECT sysdate, months_between(sysdate, sysdate + 61) month, add_months(sysdate, 2), next_day(sysdate, 7), last_day(sysdate), trunc(sysdate), round(sysdate) FROM dual SELECT EXTRACT(year FROM sysdate), ADD_MONTHS(sysdate, 2.8), GREATEST(SYSDATE + 1, SYSDATE -1, SYSDATE), LEAST(22, 11, 33) FROM DUAL
4、转换函数
--隐式转换: date <==> varchar2 <==> number --显示转换: date 通过 to_char() 函数转为 char。 char 通过 to_date() 函数转为 date。 char 通过 to_number() 函数转为 number。 number 通过 to_char() 函数转为 char。 其中: to_char(数字, '格式'), $表示在数字前加$符号,L表示本地货币,.表示小数点, ,表示分隔符。 SELECT to_char(sysdate, 'yyyy"年"mm"月"dd"日"'), to_char(201906.13, 'L999,999.99'), to_char(201906.13, '$999,999.99'), to_char(201906.13, '999,999.99'), to_date('2019.06,13', 'yyyy-mm-dd') FROM dual

5、通用函数
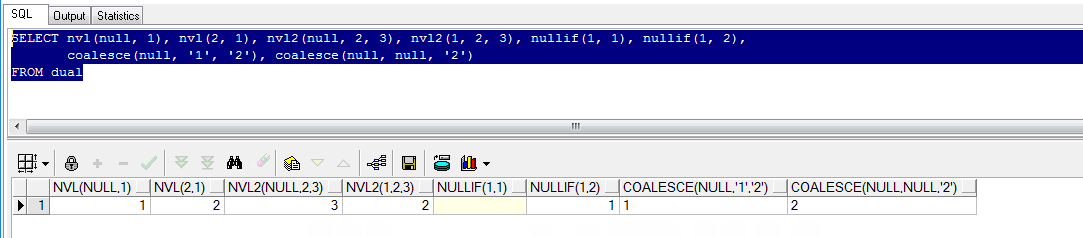
-- NULL与任何数字计算结果仍为NULL。 -- NULL与字符串连接,NULL会被当成空格。 -- 在WHERE条件中判断不为NULL时,需写成IS NOT NULL,为空写成IS NULL。 NVL(e1, e2) --当e1为null时,使用e2去替换它。 NVL2(e1, e2, e3) --当e1不为null时,返回e2。e1为null时,返回e3。 NULLIF(e1, e2) --当e1不等于e2时,返回e1。相等时返回null。 coalesce(e1, e2, e3, ..., en) --当e1为null时,执行e2,e2若为null,执行e3,循环执行,直至不为null或执行完。 SELECT nvl(null, 1), nvl(2, 1), nvl2(null, 2, 3), nvl2(1, 2, 3), nullif(1, 1), nullif(1, 2), coalesce(null, '1', '2'), coalesce(null, null, '2') FROM dual
6、条件表达式
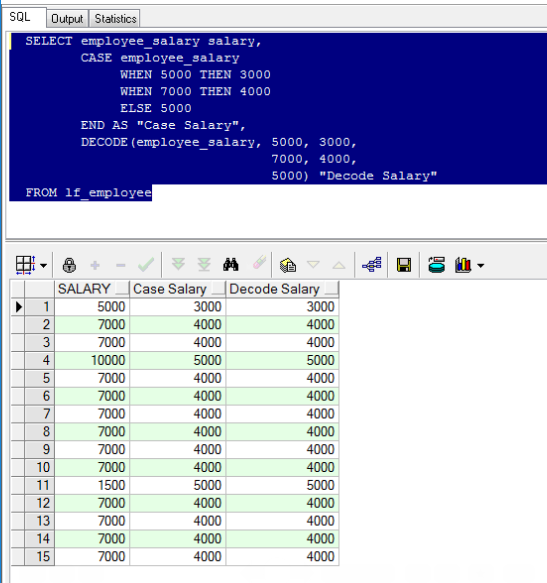
【简单Case函数:】 CASE 参数 WHEN 值1 THEN 结果1 WHEN 值2 THEN 结果2 ELSE 结果3 END; 【Case搜索函数:(可以进行更多的判断)】 CASE WHEN 表达式1 THEN 结果1 WHEN 表达式2 THEN 结果2 ELSE 结果3 END; 注:Case函数只返回第一个符合条件的值。 【Decode表达式:】 Decode(参数, 值1, 结果1, 值2, 结果2, 结果3) SELECT employee_salary salary, CASE employee_salary WHEN 5000 THEN 3000 WHEN 7000 THEN 4000 ELSE 5000 END AS "Case Salary", DECODE(employee_salary, 5000, 3000, 7000, 4000, 5000) "Decode Salary" FROM lf_employee
四、多行函数(聚合函数、组函数、集合函数)
1、聚合函数用于统计数据,聚合函数对一组值进行计算并返回单一的值。
2、聚合函数不能单独写在WHERE中,因为WHERE是对每行数据进行判断,而聚合函数是对所有数据进行操作。聚合函数一般与GROUP BY连用。
3、聚合函数忽略空值(NULL)。
假如:现有10个人,但只有4人有奖金,如果采用聚合函数直接进行计算的话,得到的结果是 (4人奖金和/4人),因为会忽略空值(即空值不参与聚合函数运算)。 若想实现(4人奖金和/10人),可按照如下写法: SELECT AVG(NVL(salary, 0)) FROM emp; 这个查询语句表示,当salary为NULL时,将其赋值为0,这样就可以让其参与聚合函数的运算。 --MAX(列名) 求某列的最大值 , MIN(列名) 求某列的最小值。 --AVG(列名) 求某列的平均值, SUM(列名) 求某列的总和。 --COUNT(列名) 求某列非空的记录数。 --COUNT(*) 统计表中的(非空)记录数。
注:SUM、AVG 只针对数值型数据。 MIN、MAX、COUNT 可以针对任意类型的数据。组函数只能写在HAVING中,不能写在WHERE里。
SELECT MAX(employee_salary), MIN(employee_salary), AVG(employee_salary), SUM(employee_salary),COUNT(employee_salary), COUNT(*) FROM lf_employee

五、分组函数(GROUP BY , HAVING)
1、GROUP BY一般写在FROM之后,用于分组。
2、若GROUP BY中出现多列,那么将列组合看成 分组的依据。
3、若SELECT中出现了非组函数列(非MAX,MIN等),那么这些列必须存在GROUP BY中,否则或报错,但GROUP BY中出现了非组函数列,SELECT中可以不存在。
比如:employee_status(非组函数列)存在SELECT中,而不在GROUP BY中,则会报错。 SELECT employee_id,employee_status,MAX(employee_salary), MIN(employee_salary) FROM lf_employee GROUP BY employee_id --错误写法,会报错 SELECT employee_id,employee_status,MAX(employee_salary), MIN(employee_salary) FROM lf_employee GROUP BY employee_id, employee_status --正确写法
4、HAVING子句不能单独存在,必须跟在GROUP BY后面,其是对分组结果的进一步限制。HAVING是在第一次检索完成后,进行第二次的检索。
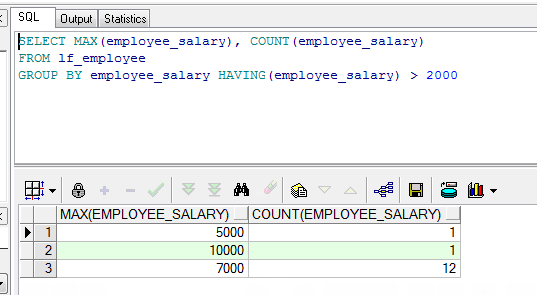
SELECT MAX(employee_salary), COUNT(employee_salary) FROM lf_employee GROUP BY employee_salary SELECT MAX(employee_salary), COUNT(employee_salary) FROM lf_employee GROUP BY employee_salary HAVING(employee_salary) > 2000

六、数据类型
1、常用数据类型:
NUMBER、 CHAR、VARCHAR2、DATE、TIMESTAMP、 LONG、CLOB。
--举例: CREATE TABLE emp{ --创建一个表 id NUMBER(4); --表示四位整数 name VARCHAR2(20); --最长20个字节的变长字符串 gender CHAR(1); --定长1个字节的字符串 sal NUMBER(6, 2); --表示四位整数,两位小数 hiredate DATE; --定义日期类型 }
2、NUMBER(oracle独有类型)
NUMBER指数字类型, 格式: NUMBER(P, S), P指数字的总位数(P取值为1~38),S指小数点后面的位数。 number类型和java数据类型对应关系: number类型长度 java数据类型 n>18 java.math.BigDecimal 10<=n<=18 java.lang.Long 1 <=n<=9 java.lang.Integer 举例: emp表中的sal列定义为: sal NUMBER(6, 2),则表示为整数部分最大为4位,小数部分最大为2位,即表示的最大值为9999.99 。
3、CHAR、VARCHAR2
CHAR表示固定长度的字符串。易造成空间的浪费,但索引效率高。 格式: CHAR(N),固定占用N个字节(不是字符),最大为2000字节。 VARCHAR2 相当于 其他数据库的 VARCHAR,表示可变长的字符串。VARCHAR2比CHAR空间利用率高,但性能差。 格式: VARCHAR2(N),最多占用N个字节,最大值为4000字节。
4、DATE、TIMESTAMP
DATE用于定义日期的数据。长度为7个字节。 对于日期数据,可以定义为Date类型,也可以定义为Varchar2(30)。 sysdate,本质为Oracle的内部函数,用于返回当前的系统时间,精确到秒。 TIMESTAMP用于保存日期时间,相比于DATE,TIMESTAMP可以保存更精确的值,精确到纳秒。 其长度为7字节或者11字节。长度为7字节时,与DATE相同。长度为11字节时,第8字节至第11字节内部采用整型运算,用于保存纳秒值。
5、LONG与CLUB类型
LONG是VARCHAR2的加长版,也是变长字符串,最多能存2GB的字符串数据。每个表最多只允许存在一个LONG列,且不能为主键、不能建立索引、不能出现在查询语句中。
CLUB:是Oracle推荐的, 建议用CLUB代替LONG,存储定长或变长字符串,最多4GB。

