分布式并行计算MapReduce
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
HDFS:
(1)功能:
NameNode:负责管理文件系统的 namespace 以及客户端对文件的访问;
DataNode:用于管理它所在节点上的存储;
FailoverController:故障切换控制器,负责监控与切换 Namenode 服务;
JournalNode:用于存储 EditLog;
Balancer:用于平衡集群之间各节点的磁盘利用率;
HttpFS:提供 HTTP 方式访问 HDFS 的功能。
(2)工作原理:
HDFS组成:
- NameNode:Master节点(也称元数据节点),是系统唯一的管理者。负责元数据的管理(名称空间和数据块映射信息);配置副本策略;处理客户端请求
- DataNode:数据存储节点(也称Slave节点),存储实际的数据;执行数据块的读写;汇报存储信息给NameNode
- Sencondary NameNode:分担namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。注意:在hadoop 2.x 版本,当启用 hdfs ha 时,将没有这一角色
- client:系统使用者,调用HDFS API操作文件;与NameNode交互获取文件元数据;与DataNode交互进行数据读写。注意:写数据时文件切分由Client完成
HDFS架构原则:
- 元数据与数据分离:文件本身的属性(即元数据)与文件所持有的数据分离
- 主/从架构:一个HDFS集群是由一个NameNode和一定数目的DataNode组成
- 一次写入多次读取:HDFS中的文件在任何时间只能有一个Writer。当文件被创建,接着写入数据,最后,一旦文件被关闭,就不能再修改
- 移动计算比移动数据更划算:数据运算,越靠近数据,执行运算的性能就越好,由于hdfs数据分布在不同机器上,要让网络的消耗最低,并提高系统的吞吐量,最佳方式是将运算的执行移到离它要处理的数据更近的地方,而不是移动数据
(3)工作过程:
写操作
1、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client请求第一个 block该传输到哪些datanode服务器上
4、namenode返回3个datanode服务器ABC
5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
读操作
1、跟namenode通信查询元数据,找到文件块所在的datanode服务器
2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4、客户端以packet为单位接收,现在本地缓存,然后写入目标文件
MapReduce:
(1)功能:
(2)工作原理:
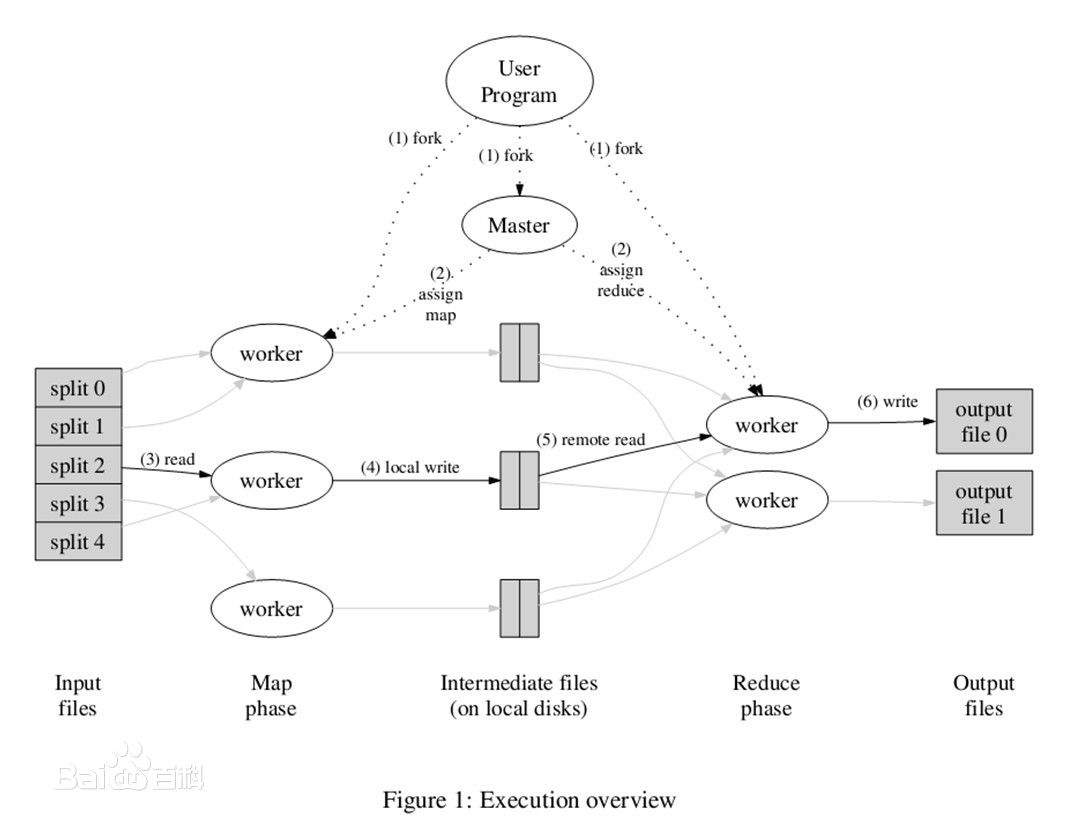
(3)工作过程:
MapReduce的工作过程分为两个步骤:map和reduce。每个阶段的输入输出都是key-value的形式,key和value的类型可以自行指定。map阶段对切分好的数据进行并行处理,处理结果传输给reduce,由reduce函数完成最后的汇总。
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc
2)编写map函数和reduce函数,在本地运行测试通过
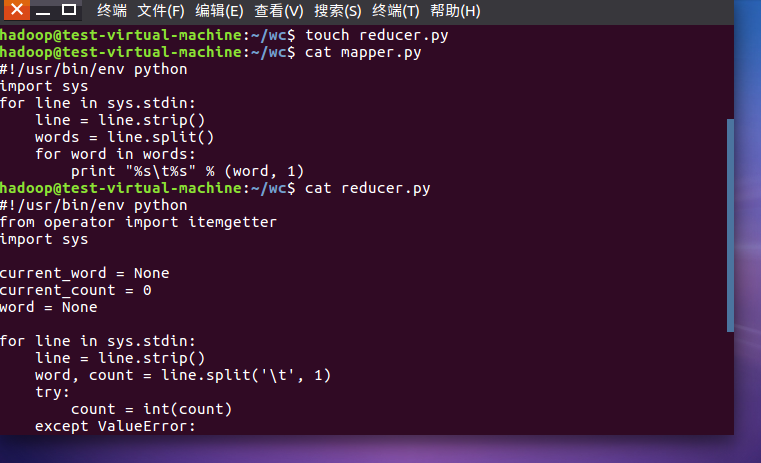
3)启动Hadoop:HDFS, JobTracker, TaskTracker
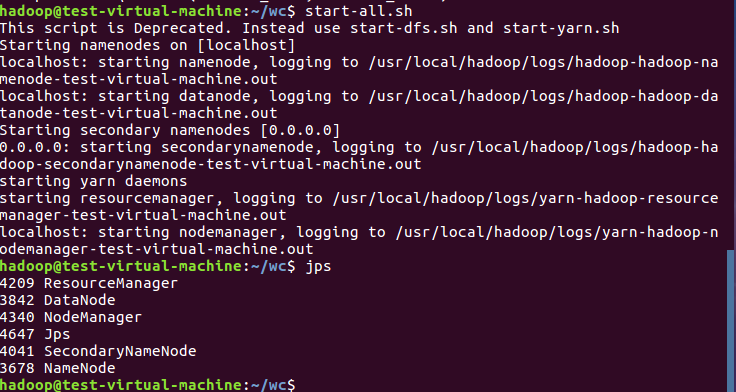
4)把文本文件上传到hdfs文件系统上 user/hadoop/input
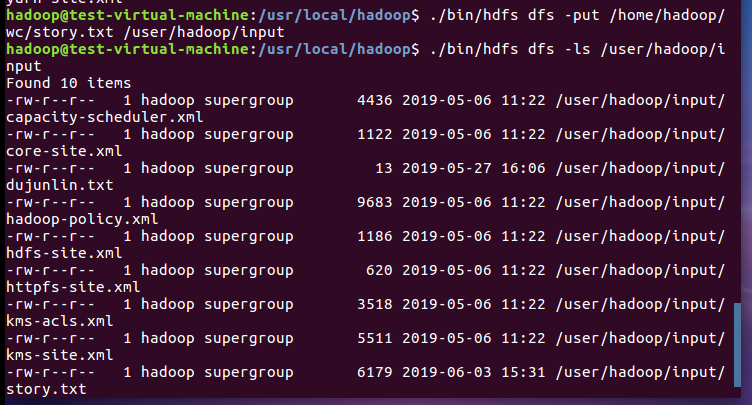
5)streaming的jar文件的路径写入环境变量,让环境变量生效
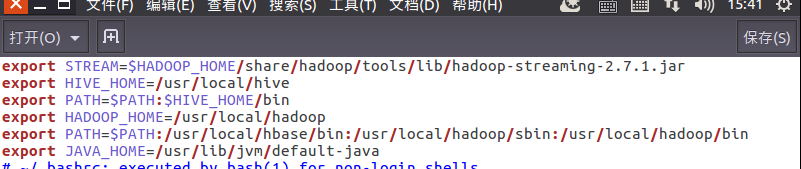

6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh


7)source run.sh来执行mapreduce
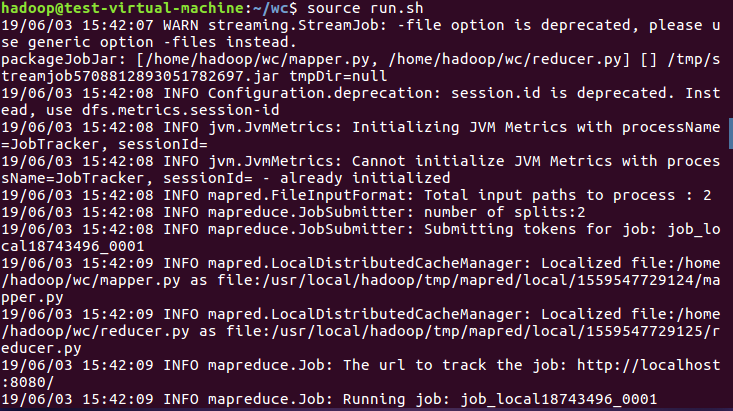
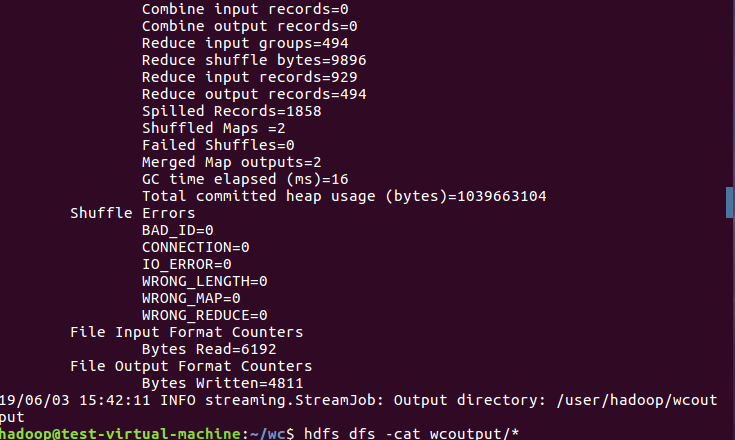
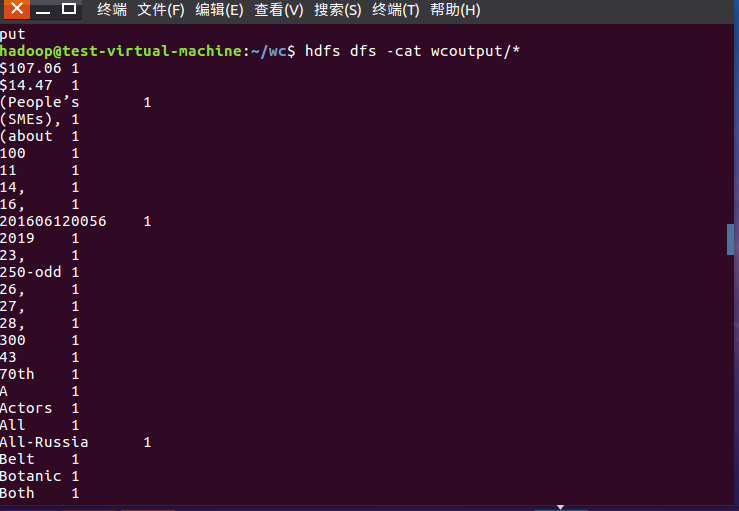
8)查看运行结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号