理解爬虫原理
- 简单说明爬虫原理
爬虫,是按照一定的规则,自动地抓取万维网信息的程序或者脚本,实质就是通过程序自动去获取 Web 页面上想要获取的数据,即自动抓取数据。
浏览器的所有结果都是由代码组成,爬虫就是为了获取这些内容,通过过滤、分析代码,从中获取我们想要的数据。
2. 理解爬虫开发过程
1).简要说明浏览器工作原理;
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
2).使用 requests 库抓取网站数据;
Request:浏览器就发送消息给该网址所在的服务器,这个过程叫做HTTP Request。
Request详解
请求方式:主要有GET、POST两种类型,另外还有HEAD、PUT、DELETE、OPTIONS等。
请求URL:URL全称统一资源定位符,如一个网页文档、一张图片、一个视频等都可以用URL唯一来确定。
请求头:包含请求时的头部信息,如User-Agent、Host、Cookies等信息。
请求体:请求时额外携带的数据如表单提交时的表单数据
版权声明:本文为博主原创文章,转载请附上博文链接!
requests.get(url) 获取校园新闻首页html代码
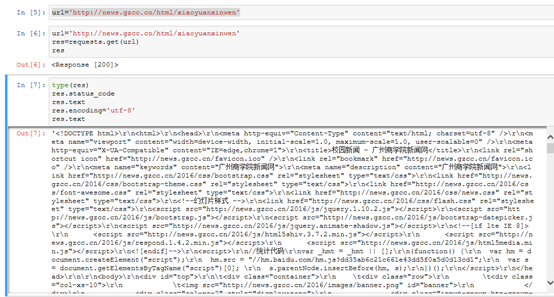
3).了解网页
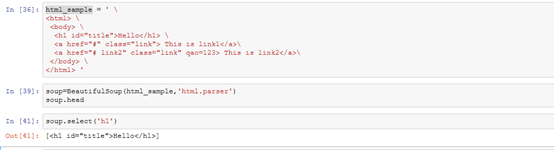
写一个简单的html文件,包含多个标签,类,id
4).使用 Beautiful Soup 解析网页;
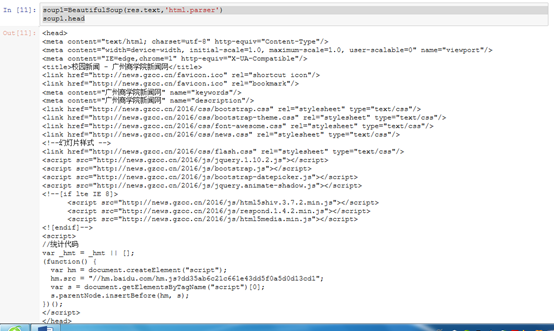
通过BeautifulSoup(html_sample,'html.parser')把上述html文件解析成DOM Tree
select(选择器)定位数据
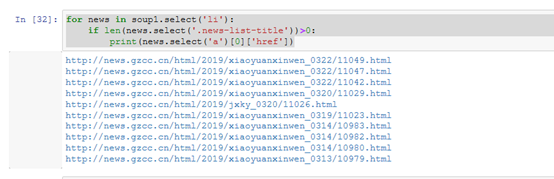
找出含有特定标签的html元素
找出含有特定类名的html元素
找出含有特定id名的html元素
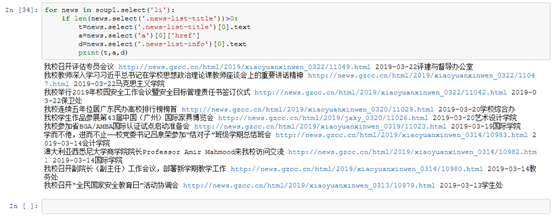
3.提取一篇校园新闻的标题、发布时间、发布单位

 浙公网安备 33010602011771号
浙公网安备 33010602011771号