【八】Kubernetes 五种资源控制器详细介绍以及功能演示
一、控制器说明
Pod 的分类:
- 自主式 Pod:该类型的 Pod 无论是异常退出还是正常退出都不会被创建,也就是说没有对应的管理者。
- 控制器管理的 Pod:该类型 Pod 在控制器的生命周期里,控制器始终要维持 Pod 的副本数,日常中基本都是使用该类型 Pod ,因为自主式 Pod 不能保证稳定性等之类的问题。
Deployment 介绍
Deployment 是为 Pod 和 ReplicaSet 提供了一个 声明式定义方法,也就是你只要负责描述 Deployment 中的目标状态,而 Deployment 控制器会去对 ReplicaSet 进行操作使其变成期望的状态。
Deployment 是用来取代以前的 ReplicationController 达到更方便的管理应用。
典型的应用场景如下:
-
定义 Deployment 来创建 ReplicaSet 和 Pod
-
滚动升级和回滚应用
-
扩容和缩容
-
暂停和继续 Deployment
Deployment 创建 RS 流程图如下:
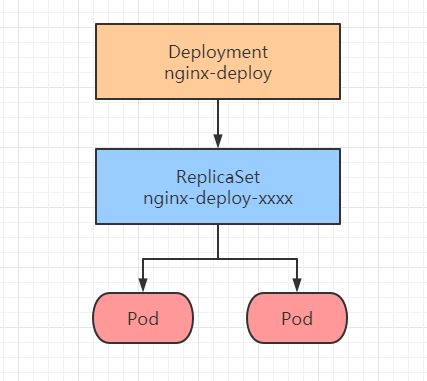
这里针对上面第一点强调一下,Deployment 不是直接管理或者创建 Pod,而是通过创建 ReplicaSet 来创建和管理 Pod。
创建 Deployment 时名称为 nginx-Deploy,RS 也会被创建出来,名称为 nginx-Deploy-xxx,xxx为随机码。
DaemonSet 介绍
DaemonSet 确保全部(或者一些)节点上运行 一个 Pod 的副本。 当有节点加入集群时, 也会为他们 新增一个 Pod 。 当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的 所有 Pod。
上述简介摘自官方
如果需要多个 Pod 运行在每个 Node 上的话,可以定义多个 DaemonSet 的方案来实现。
DaemonSet 典型应用场景:
-
运行集群存储,例如在每个 Node 上运行
glusterd、ceph等 -
每个 Node 上运行日志收集,例如
fluentd、logstash等 -
每个 Node 上运行监控程序,例如
Prometheus Node Exporter、collectd等
StatefulSet 介绍
StatefulSet 是用来管理 有状态服务,为了解决有状态服务的问题,而 Deployment 和 ReplicaSet 更适用于无状态服务的部署。
StatefulSet 为每个 Pod 维护了一个有粘性的 ID,无论怎么调度,每个 Pod 都有一个永久不变的 ID。
StatefulSet 应用场景:
- 稳定的、唯一的网络标识符。
- 稳定的、持久的存储。
- 有序的、优雅的部署和缩放。
- 有序的、自动的滚动更新。
Job 介绍
Job 负载批处理任务,仅执行一次的任务,它能够保证批处理任务的一个或者多个 Pod 成功执行结束。
可以设置 Job 执行成功的数值,Job 跟踪记录成功完成的 Pod 个数,当数量达到指定的成功个数阈值时,任务结束。
我们不需要担心程序是否执行成功,如果 Jod 没有以0代码成功退出的话,它会重新执行这个程序。
CronJob 介绍
CronJob 就像 Linux 的 crontab。 它用 Cron 格式进行编写, 在给定时间点只运行一次、周期性地在给定的调度时间执行 Job。
典型应用场景:
创建周期性运行的 Jod,最常用的是 数据库备份。
二、控制器创建实例测试
RS 与 Deployment 实例测试
在 K8s 新版本中,官方不再使用 ReplicationControler(RC),而是使用 ReplicaSet(RS)代替 RC,其实 RS 和 RC 本质没什么不同,只是 RS 多了一个支持集合式的 selector。
支持集合式的 selector 作用:
在创建 Pod 的时候会为它打上标签(tag),也会为 Pod 里面的容器打上标签,当需要删除容器或者进行其他操作的时候,可以通过标签来进行相关操作。
接下来我们演示一下 RS 标签的作用
rs_frontend.yaml 资源清单如下:
apiVersion: apps/v1
kind: ReplicaSet
metadata: # RS 元素信息
name: frontend # RS 名称
labels: # 自定义标签
app: guestbook # RS 标签
tier: frontend # RS 标签
spec:
replicas: 3 # Pod 副本数
selector: # 选择标签
matchLabels: # 匹配标签
tier: frontend # 匹配 frontend 标签
template: # Pod 模板
metadata: # Pod 元素信息
labels: # 自定义标签
tier: frontend # 标签 frontend
spec:
containers:
- name: mynginx # 容器名称
image: hub.test.com/library/mynginx:v1 # 镜像地址
RS 创建
[root@k8s-master01 ~]# kubectl create -f rs_frontend.yaml
replicaset.apps/frontend created
查看 Pod 和 RS 状态
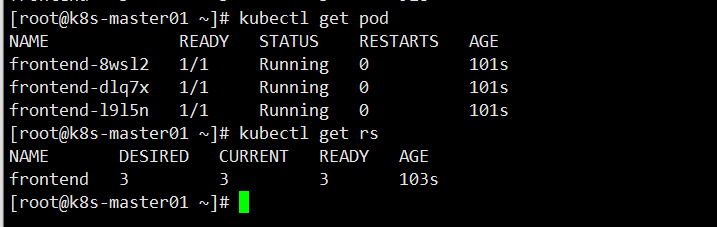
查看 Pod 选择标签,这三个 Pod 的标签都是frontend
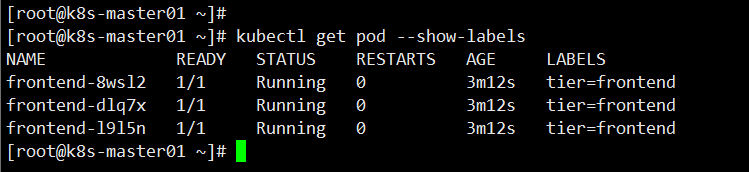
接下来修改其中一个 Pod 标签测试
[root@k8s-master01 ~]# kubectl label pod frontend-8wsl2 tier=frontend1 --overwrite
pod/frontend-8wsl2 labeled
再次查看 Pod 状态及标签
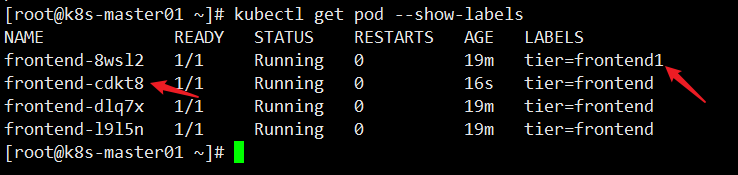
此时已经变成四个 Pod ,因为 RS 是通过
frontend标签进行 Pod 匹配,RS 检测到frontend标签的 Pod 此时少了一个,所以会新创建一个属于自己的标签 Pod 出来,从而满足期望值。而此时
frontend-8wsl2这个 Pod 已经不属于 RS 的控制范围之内了,因为它的标签是frontend1。
把 RS 给删除后可以更直观的看出标签的作用
[root@k8s-master01 ~]# kubectl delete rs frontend
replicaset.apps "frontend" deleted
[root@k8s-master01 ~]# kubectl get pod --show-labels

其他的三个 Pod 都被删除了,只有标签为
frontend1Pod 没有被删除,因为该 Pod 标签不匹配 RS ,所以 RS 就不会对该 Pod 进行任何操作。
Deployment 实例测试
下面是 Deployment 示例。实际是创建了一个 ReplicaSet,负责启动三个 Nginx Pod。
nginx-deployment.yaml资源清单如下
apiVersion: apps/v1
kind: Deployment
metadata: # Deployment 元素信息
name: nginx-deployment # Deployment 名称
labels: # 自定义标签
app: nginx # Deployment 标签
spec:
replicas: 3 # Pod 副本数
selector:
matchLabels:
app: nginx # 匹配 frontend 标签
template:
metadata:
labels:
app: nginx # Pod 标签 frontend
spec:
containers:
- name: mynginx
image: hub.test.com/library/mynginx:v1 # 镜像地址
ports:
- containerPort: 80
创建 Deployment
[root@k8s-master01 ~]# kubectl apply -f nginx-deployment.yaml --record
deployment.apps/nginx-deployment created
--record 记录命令,方便回滚的时候方便查看每次 revision 变化。
查看 Deployment、RS、Pod 状态,全部都已经Running
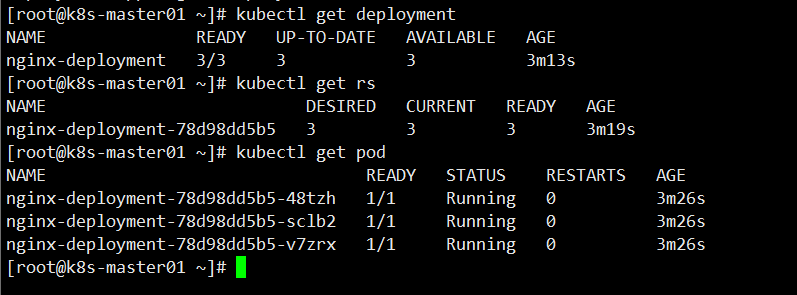
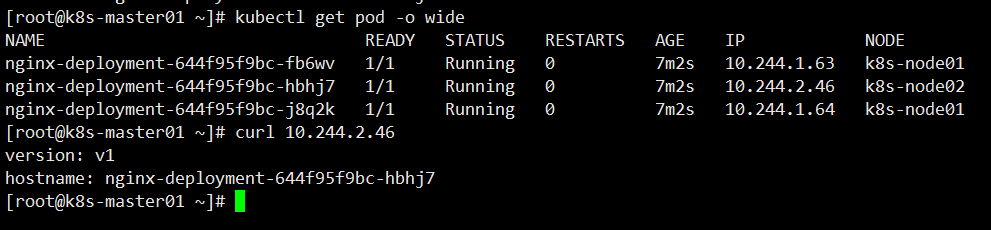
查看 Pod 详细信息,访问测试
[root@k8s-master01 ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-644f95f9bc-fb6wv 1/1 Running 0 7m2s 10.244.1.63 k8s-node01 <none> <none>
nginx-deployment-644f95f9bc-hbhj7 1/1 Running 0 7m2s 10.244.2.46 k8s-node02 <none> <none>
nginx-deployment-644f95f9bc-j8q2k 1/1 Running 0 7m2s 10.244.1.64 k8s-node01 <none> <none>
Deployment 扩容功能
[root@k8s-master01 ~]# kubectl scale deployment nginx-deployment --replicas=10
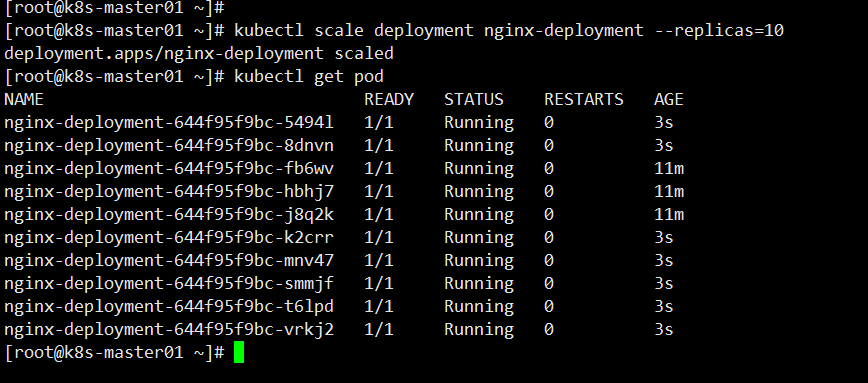
可以看到此时已经扩容到 10 个 Pod ,Deployment 扩容非常简单,一个命令就可以水平扩容,从而缓解应用对外提供的压力。
上面是手动扩容的,哪能不能根据 Pod 的负载情况来进行自动扩容缩呢?
是可以的,K8s 提供了 HPA 功能,详细可以看 我这篇笔记 。
Deployment 更新镜像操作
[root@k8s-master01 ~]# kubectl set image deployment/nginx-deployment nginx=hub.test.com/library/mynginx:v2
nginx 为容器名称
查看 RS 状态,此时已经创建新的 RS,但是旧的 RS 还保留着,后续可以进行回滚操作

访问其中一个 Pod 测试
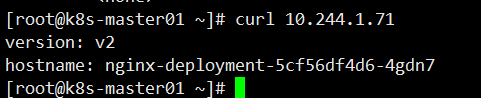
Deployment 回滚操作
[root@k8s-master01 ~]# kubectl rollout undo deployment/nginx-deployment
deployment.apps/nginx-deployment rolled back
已经回滚到之前的 RS 的版本
[root@k8s-master01 ~]# kubectl get rs
NAME DESIRED CURRENT READY AGE
nginx-deployment-5cf56df4d6 0 0 0 8m2s
nginx-deployment-644f95f9bc 10 10 10 37m
默认是回滚到上一个版本,访问测试

还可以滚动或者回滚到指定版本
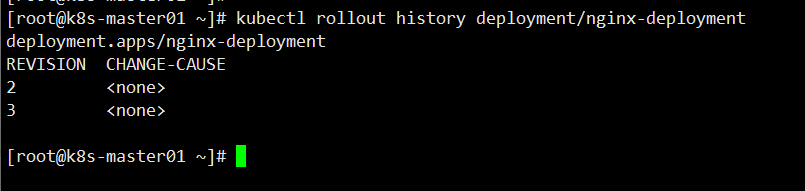
查看版本信息
[root@k8s-master01 ~]# kubectl rollout history deployment/nginx-deployment
回滚到指定版本命令如下,这里就不做测试
[root@k8s-master01 ~]# kubectl rollout undo deployment/nginx-deployment --to-revision=3
版本清理策略
可以在 Deployment 中设置 .spec.revisionHistoryLimit 字段以指定保留此 Deployment 的多少个旧有 ReplicaSet。其余的 ReplicaSet 将在后台被垃圾回收。 默认情况下,此值为 10 。
DaemonSet 实例测试
daemonset.yaml资源清单如下
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: daemonset-example
labels:
app: daemonset
spec:
selector:
matchLabels:
name: daemonset-example
template:
metadata:
labels:
name: daemonset-example
spec:
containers:
- name: mynginx
image: hub.test.com/library/mynginx:v1
创建 DaemonSet
[root@k8s-master01 ~]# kubectl create -f daemonset.yaml
daemonset.apps/daemonset-example created
查看 DaemonSet Pod 状态

分别在两个 Node 上一个 Pod ,因为 K8s 里面有个 污点的概念 ,所以 Master 上不会被创建,可以自行去了解一下,后续的文章中也会讲到。
把其中一个 Node 上的 Pod 删除,它会自动创建一个新的 Pod 来满足 DaemonSet 的期望值,每个 Node 上一个副本,如图所示。

Job 实例测试
job.yaml资源清单,它负责计算 π 到小数点后 2000 位,并将结果打印出来。
apiVersion: batch/v1
kind: Job
metadata:
name: pi # Job 名称
spec:
template:
spec:
containers:
- name: pi # Pod 名称
image: perl # 镜像名称
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
# 计算圆周率,计算小数点后 2000 位
restartPolicy: Never # 重启策略,永不重启
backoffLimit: 4 # 设置重试次数,达到后将 Job 标记为失败
创建 Job 并查看状态
[root@k8s-master01 ~]# kubectl create -f job.yaml
job.batch/pi created
[root@k8s-master01 ~]# kubectl get pod -w
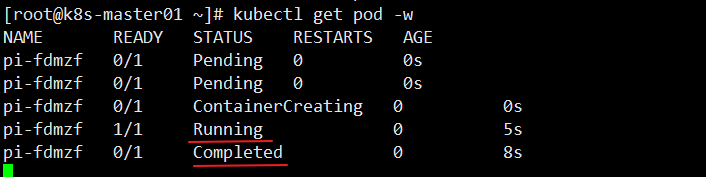
可以看到 Job 从 Running 到 Completed 的一个过程,该 Job 已经完成了计算。
查看具体结果
其他参数配置
.spec.completions 标志 Job 需要成功完成 Pod 个数,才视为整个 Job 完成。(默认1)
.spec.parallelism标志 Pod 并行运行个数。(默认1)
.spec.activeDeadlineSeconds标志 Job 的整个生命期,一旦 Job 运行时间达到设定值,则所有运行中的 Pod 都会被终止。(秒数值)
CronJob 实例测试
cronjob.yaml资源清单示例如下
apiVersion: batch/v1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *" # 每分钟执行一次
jobTemplate: # 指定需要运行的任务
spec:
template:
spec:
containers:
- name: hello
image: hub.test.com/library/busybox:latest
imagePullPolicy: IfNotPresent # 默认值,本地有则使用本地镜像就不拉取
command:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure # 重启策略,不失败则不重启
大家如果设置定时计划任务不确定时间的时候,可以通过这个小工具网站进行验证。
crontab 执行时间计算:https://tool.lu/crontab/
创建 CronJob
[root@k8s-master01 ~]# kubectl apply -f cronjob.yaml
cronjob.batch/hello created
查看 CronJob 状态
[root@k8s-master01 ~]# kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
hello */1 * * * * False 0 21s 21m
查看 Job 运行状态,默认是保存三个成功的 Pod 记录
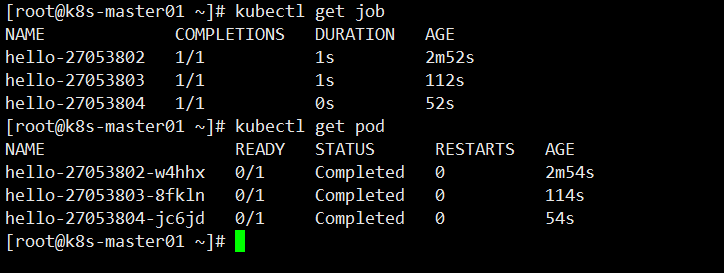
查看其中一个 Pod 日志,可以看到每分钟执行一个,符合我们预期设置要求。
[root@k8s-master01 ~]# kubectl logs hello-27053804-jc6jd
Wed Jun 9 08:44:00 UTC 2021
Hello from the Kubernetes cluster
[root@k8s-master01 ~]# kubectl logs hello-27053805-hfr5l
Wed Jun 9 08:45:00 UTC 2021
Hello from the Kubernetes cluster
其他参数配置
.spec.successfulJobsHistoryLimit设置保存执行成功的 Job 数量(默认3)
.spec.failedJobsHistoryLimit设置保存失败的 Job 数量(默认1)
.spec.concurrencyPolicy并发策略(默认Allow)
当读到这里的时候,你会发现 StatefulSet 还有进行实例测试,原因是 StatefulSet 需要跟 K8s 存储配合使用,所以后续讲到存储部署的时候再进行演示。
作者:神奇二进制
文章出处:https://www.cnblogs.com/l-hh/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
文章如有叙述不当的地方,欢迎指正。如果觉得文章对你有帮助,可以精神上的支持 [推荐] 或者 [关注我] ,一起交流,共同进步!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号