【二】Kubernetes 集群部署-kubeadm方式(亲测)
一、概述
本次部署 Kubernetes 集群是通过 kubeadm 工具来进行部署, kubeadm 是 Kubernetes 官⽅提供的⽤于快速部署 Kubernetes 集群的⼯具,利⽤其来部署 Kubernetes 集群操作起来非常简便。
废话多说了,反正也是摘自网上,开始操作吧。
二、环境说明
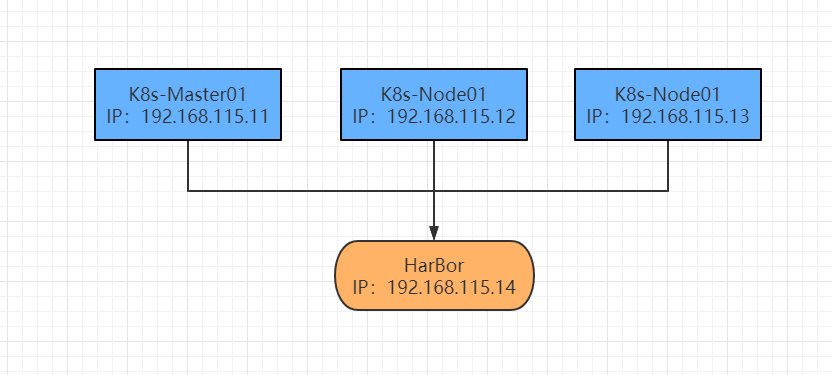
本次部署的环境一共使用四台机器,一台作为 HarBor 容器镜像仓库,另外三台作为 Kubernetes 集群,采用一主两从的一个方式,具体架构如下图。
版本说明:
操作系统:CentOS -7
Docker版本:20.10.6
Kubernetes版本:1.21.1
都是采用目前最新版本进行部署,CentOS 建议最小化安装,这样可以减轻系统重量。
三、准备工作(所有节点)
设置系统主机名以及 Host 文件的相互解析
hostnamectl set-hostname k8s-master01
hostnamectl set-hostname k8s-node01
hostnamectl set-hostname k8s-node02
[root@k8s-master01 ~]# cat >> /etc/hosts <<EOF
192.168.115.11 k8s-master01
192.168.115.12 k8s-node01
192.168.115.13 k8s-node02
EOF
拷贝到另外两台节点
[root@k8s-master01 ~]# scp /etc/hosts root@k8s-node01:/etc/hosts
[root@k8s-master01 ~]# scp /etc/hosts root@k8s-node02:/etc/hosts
安装相关依赖包
[root@localhost ~]# yum install -y conntrack ntpdate ntp ipvsadm ipset jq iptables curl sysstat libseccomp wgetvimnet-tools git
设置防火墙为 Iptables 并设置空规则
[root@localhost ~]# systemctl stop firewalld && systemctl disable firewall
[root@localhost ~]# yum -y install iptables-services && systemctl start iptables && systemctl enable iptables&& iptables -F && service iptables save
关闭 SELINUX
[root@localhost ~]# swapoff -a && sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
[root@localhost ~]# setenforce 0 && sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
调整内核参数,对 K8S 起到优化作用
cat > kubernetes.conf <<EOF
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0 # 禁止使用 swap 空间,只有当系统 OOM 时才允许使用它
vm.overcommit_memory=1 # 不检查物理内存是否够用
vm.panic_on_oom=0 # 开启 OOM
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
[root@localhost ~]# cp kubernetes.conf /etc/sysctl.d/kubernetes.conf
[root@localhost ~]# sysctl -p /etc/sysctl.d/kubernetes.conf
调整系统时区(如果是Asia/Shanghai,则跳过该步骤)
[root@localhost ~]# timedatectl set-timezone Asia/Shanghai
[root@localhost ~]# timedatectl set-local-rtc 0
[root@localhost ~]# systemctl restart crond
[root@localhost ~]# systemctl restart rsyslog.service
关闭系统不需要服务
[root@localhost ~]# systemctl stop postfix && systemctl disable postfix
设置 rsyslogd 和 systemd journald
设置日志保存方式,默认使用 systemd journald 日志存储方案。
[root@localhost ~]# mkdir /var/log/journa
[root@localhost ~]# mkdir /etc/systemd/journald.conf.d
cat > /etc/systemd/journald.conf.d/99-prophet.conf <<EOF
[Journal]
# 持久化保存到磁盘
Storage=persistent
# 压缩历史日志
Compress=yes
SyncIntervalSec=5m
RateLimitInterval=30s
RateLimitBurst=1000
# 最大占用空间 10G
SystemMaxUse=10G
# 单日志文件最大 200M
SystemMaxFileSize=200M
# 日志保存时间 2 周
MaxRetentionSec=2week
# 不将日志转发到
syslogForwardToSyslog=no
EOF
重启 systemd-journald
[root@localhost ~]# systemctl restart systemd-journald
四、组件安装(所有节点)
Docker安装
[root@k8s-master01 ~]# yum install -y yum-utils device-mapper-persistent-data lvm2
[root@k8s-master01 ~]# yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@k8s-master01 ~]# yum update -y && yum install -y docker-ce
升级系统内核
CentOS 7.x 系统自带的 3.10.x 内核存在一些 Bugs,导致运行的 Docker、Kubernetes 不稳定,例如: rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
[root@localhost ~]# rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm
[root@localhost ~]# yum --enablerepo=elrepo-kernel install -y kernel-lt
# 查看系统可用内核
[root@localhost ~]# cat /boot/grub2/grub.cfg |grep menuentry
# 设置开机从新内核启动
[root@localhost ~]# grub2-set-default 'CentOS Linux (5.4.121-1.el7.elrepo.x86_64) 7 (Core)'
这里需要注意的是修改成你升级的版本,可能内核更新了导致版本和我的教程不一致。
安装完成后,重启所以节点,查看内核是否已经更改
[root@k8s-master01 ~]# uname -r
5.4.121-1.el7.elrepo.x86_64
配置 daemon.json
[root@k8s-master01 ~]# mkdir /etc/docker
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
}
}
EOF
mkdir -p /etc/systemd/system/docker.service.d
重启 Docker 服务
[root@k8s-master01 ~]# systemctl daemon-reload && systemctl restart docker && systemctl enable docker
准备一下 Kubernetes YUM源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpghttp://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
kubelet、 kubeadm、 kubectl 安装
这里安装最新版本的,也可以指定版本安装。
[root@k8s-master01 ~]# yum -y install kubeadm kubectl kubelet
...省略输出信息
[root@k8s-master01 ~]# systemctl enable kubelet.service
指定版本安装可能会出现报错
具体如下:
[root@k8s-master01 ~]# yum install kubelet-1.13.3 kubeadm-1.13.3 kubectl-1.13.3
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
* base: mirrors.aliyun.com
* elrepo: hkg.mirror.rackspace.com
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
正在解决依赖关系
--> 正在检查事务
---> 软件包 kubeadm.x86_64.0.1.13.3-0 将被 安装
--> 正在处理依赖关系 kubernetes-cni >= 0.6.0,它被软件包 kubeadm-1.13.3-0.x86_64 需要
---> 软件包 kubectl.x86_64.0.1.13.3-0 将被 安装
---> 软件包 kubelet.x86_64.0.1.13.3-0 将被 安装
--> 正在处理依赖关系 kubernetes-cni = 0.6.0,它被软件包 kubelet-1.13.3-0.x86_64 需要
--> 正在检查事务
---> 软件包 kubelet.x86_64.0.1.13.3-0 将被 安装
--> 正在处理依赖关系 kubernetes-cni = 0.6.0,它被软件包 kubelet-1.13.3-0.x86_64 需要
---> 软件包 kubernetes-cni.x86_64.0.0.8.7-0 将被 安装
--> 解决依赖关系完成
错误:软件包:kubelet-1.13.3-0.x86_64 (kubernetes)
需要:kubernetes-cni = 0.6.0
可用: kubernetes-cni-0.3.0.1-0.07a8a2.x86_64 (kubernetes)
kubernetes-cni = 0.3.0.1-0.07a8a2
可用: kubernetes-cni-0.5.1-0.x86_64 (kubernetes)
kubernetes-cni = 0.5.1-0
可用: kubernetes-cni-0.5.1-1.x86_64 (kubernetes)
kubernetes-cni = 0.5.1-1
可用: kubernetes-cni-0.6.0-0.x86_64 (kubernetes)
kubernetes-cni = 0.6.0-0
可用: kubernetes-cni-0.7.5-0.x86_64 (kubernetes)
kubernetes-cni = 0.7.5-0
可用: kubernetes-cni-0.8.6-0.x86_64 (kubernetes)
kubernetes-cni = 0.8.6-0
正在安装: kubernetes-cni-0.8.7-0.x86_64 (kubernetes)
kubernetes-cni = 0.8.7-0
您可以尝试添加 --skip-broken 选项来解决该问题
您可以尝试执行:rpm -Va --nofiles --nodigest
指定版本安装报错解决办法:
[root@k8s-master01 ~]# yum install kubelet-1.13.3 kubeadm-1.13.3 kubectl-1.13.3 kubernetes-cni-0.6.0
首先使用下面的命令获取 K8s 需求的镜像版本
[root@k8s-master01 ~]# kubeadm config images list
k8s.gcr.io/kube-apiserver:v1.21.1
k8s.gcr.io/kube-controller-manager:v1.21.1
k8s.gcr.io/kube-scheduler:v1.21.1
k8s.gcr.io/kube-proxy:v1.21.1
k8s.gcr.io/pause:3.4.1
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns/coredns:v1.8.0
由于国内网络原因 kubeadm init 会卡住不动,一卡就是半个小时,然后报出这种问题
[ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-apiserver:v1.21.1: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
解决办法,编写 Shell 脚本自动拉取并修改镜像名称
[root@k8s-master01 k8s-install]# cat pull_k8s_images.sh
set -o errexit
set -o nounset
set -o pipefail
# 修改你刚刚获取到的版本信息
KUBE_VERSION=v1.21.1
KUBE_PAUSE_VERSION=3.4.1
ETCD_VERSION=3.4.13-0
DNS_VERSION=v1.8.0
# update line 修改下载镜像的源(默认不需要修改)
GCR_URL=k8s.gcr.io
# 这里就是写你要使用的仓库(默认不需要修改)
DOCKERHUB_URL=gotok8s
# 这里是镜像列表(默认不需要修改)
images=(
kube-proxy:${KUBE_VERSION}
kube-scheduler:${KUBE_VERSION}
kube-controller-manager:${KUBE_VERSION}
kube-apiserver:${KUBE_VERSION}
pause:${KUBE_PAUSE_VERSION}
etcd:${ETCD_VERSION}
coredns:${DNS_VERSION}
)
##这里是拉取和改名的循环语句(默认不需要修改)
for imageName in ${images[@]} ; do
docker pull $DOCKERHUB_URL/$imageName
docker tag $DOCKERHUB_URL/$imageName $GCR_URL/$imageName
docker rmi $DOCKERHUB_URL/$imageName
done
执行脚本拉取镜像
[root@k8s-master01 ~]# chmod +x pull_k8s_images.sh
[root@k8s-master01 ~]# ./pull_k8s_images.sh
[root@k8s-master01 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
k8s.gcr.io/kube-apiserver v1.21.1 771ffcf9ca63 11 days ago 126MB
k8s.gcr.io/kube-proxy v1.21.1 4359e752b596 11 days ago 131MB
k8s.gcr.io/kube-scheduler v1.21.1 a4183b88f6e6 11 days ago 50.6MB
k8s.gcr.io/kube-controller-manager v1.21.1 e16544fd47b0 11 days ago 120MB
k8s.gcr.io/pause 3.4.1 0f8457a4c2ec 4 months ago 683kB
k8s.gcr.io/coredns/coredns v1.8.0 296a6d5035e2 7 months ago 42.5MB
k8s.gcr.io/etcd 3.4.13-0 0369cf4303ff 8 months ago 253MB
在 K8s 初始化的时候,可能会遇到的报错
failed to pull image k8s.gcr.io/coredns/coredns:v1.21.1: output: Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
解决办法
由于新版本改名了,后面多了一个“/coredns”,所以 tag 改名要改成 k8s.gcr.io/coredns/coredns:xxx
[root@k8s-master01 ~]# docker tag k8s.gcr.io/coredns:v1.8.0 k8s.gcr.io/coredns/coredns:v1.8.0
其他镜像拉取失败问题可以参考该文档:
https://blog.csdn.net/weixin_43168190/article/details/107227626
五、K8s-master01上配置
执行初始化
[root@k8s-master01 ~]# kubeadm init --kubernetes-version=v1.21.1 --apiserver-advertise-address 192.168.115.11 --pod-network-cidr=10.244.0.0/16 | tee kubeadm-init.log
--kubernetes-version : ⽤于指定 k8s 版本;
--apiserver-advertise-address :⽤于指定使⽤ Master 的哪个 network interface 进⾏通信,若不指定,则 kubeadm 会⾃动选择具有默认⽹关的 interface;
--pod-network-cidr :⽤于指定 Pod 的⽹络范围。该参数使⽤依赖于使⽤的⽹络⽅案,本⽂将使⽤经典的flannel ⽹络⽅案;| tee kubeadm-init.log 是将初始化过程输出到 kubeadm-init.log 日志文件中方便我们后续查看。
初始化完成之后按照提示执行
[root@k8s-master01 ]# mkdir -p $HOME/.kube
[root@k8s-master01 ]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8s-master01 ]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
在 Master上⽤ root⽤户执⾏下列命令来配置 kubectl
[root@k8s-master01 ]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> /etc/profile
[root@k8s-master01 ]# source /etc/profile
[root@k8s-master01 ]# echo $KUBECONFIG
查看K8s节点状态
[root@k8s-master01 flannel]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 NotReady control-plane,master 8m14s v1.21.1
我们发现已经可以成功查询node节点信息了,但是节点的状态却是NotReady,不是Runing的状态。
原因是此时我们使用ipvs+flannel的方式进行网络通信,但是flannel网络插件还没有部署,因此节点状态为NotReady。
安装Pod⽹络
wget https://xxxx.kube-flannel.yml 的时候可能会显示连接失败;
是因为网站被墙了,建议在/etc/hosts文件添加一条。
199.232.68.133 raw.githubusercontent.com
[root@k8s-master01 ]# wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
[root@k8s-master01 flannel]# kubectl apply -f kube-flannel.yml
如果可以FQ另外一种方式
[root@k8s-master01 ]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
再次查看节点状态,k8s-master01 已经 Ready
[root@k8s-master01 ]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready control-plane,master 10m v1.21.1
查看 kube-system pod 状态
[root@k8s-master01 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-558bd4d5db-lwc6f 1/1 Running 1 143m
coredns-558bd4d5db-lws29 1/1 Running 1 143m
etcd-k8s-master01 1/1 Running 1 144m
kube-apiserver-k8s-master01 1/1 Running 1 144m
kube-controller-manager-k8s-master01 1/1 Running 1 144m
kube-flannel-ds-wvjvx 1/1 Running 2 120m
kube-proxy-m7ssr 1/1 Running 1 120m
kube-scheduler-k8s-master01 1/1 Running 1 144m
附加:查看集群容器的详细状态
[root@k8s-master01 ]# kubectl get pod -n kube-system -o wide
六、K8s 集群添加 SLAVE 节点
可以通过我们初始化的时候输出的日志来复制添加,kubeadm-init.log 文件中。
[root@k8s-node01 ~]# kubeadm join 192.168.115.11:6443 --token idetsu.r3w9f4ph06c6vmre --discovery-token-ca-cert-hash sha256:ce86e3f982b8ecc716571426d671867be58b9a2b331464454e0730ebcdf65c8d
其他节点一样添加方式。
查看每个节点状态
[root@k8s-master01 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready control-plane,master 146m v1.21.1
k8s-node01 Ready <none> 123m v1.21.1
k8s-node02 Ready <none> 122m v1.21.1
[root@k8s-master01 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-558bd4d5db-lwc6f 1/1 Running 1 146m
coredns-558bd4d5db-lws29 1/1 Running 1 146m
etcd-k8s-master01 1/1 Running 1 146m
kube-apiserver-k8s-master01 1/1 Running 1 146m
kube-controller-manager-k8s-master01 1/1 Running 1 146m
kube-flannel-ds-lp9ns 1/1 Running 1 140m
kube-flannel-ds-t694v 1/1 Running 2 122m
kube-flannel-ds-wvjvx 1/1 Running 2 123m
kube-proxy-gs4mk 1/1 Running 2 146m
kube-proxy-m7ssr 1/1 Running 1 123m
kube-proxy-xsxhl 1/1 Running 1 122m
kube-scheduler-k8s-master01 1/1 Running 1 146m
到此 Kubernetes 集群已经部署完成了,你部署的过程中有什么疑问可以在下方留言,让大家一起帮你解决。
由于一遍文章太长了,HarBor 私有仓库部署、 K8s Dashboard(K8s Web管理界面)部署另起一篇来记录。
以上有不恰当或者讲得不对的地方,希望各位留言指正,如果对你有帮助麻烦 点赞 一下哦,谢谢!
七、附加操作
7.1 找不到 Token
如果 token 找不到,则可以去 Master上执⾏如下命令来获取
[root@k8s-master01 ~]# kubeadm token create
srlmuw.hyk2ghdx2dnodytr
[root@k8s-master01 ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^ .* //'
(stdin)= ce86e3f982b8ecc716571426d671867be58b9a2b331464454e0730ebcdf65c8d
节点填写格式
kubeadm join 192.168.115.11:6443 --token <token> --discoverytoken-ca-cert-hash sha256:<hash>
7.2 拆卸集群
⾸先处理各节点
kubectl drain <node name> --delete-local-data --force --ignore-daemonsets
kubectl delete node <node name>
⼀旦节点移除之后,则可以执⾏如下命令来重置集群
kubeadm reset
作者:神奇二进制
文章出处:https://www.cnblogs.com/l-hh/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利。
文章如有叙述不当的地方,欢迎指正。如果觉得文章对你有帮助,可以精神上的支持 [推荐] 或者 [关注我] ,一起交流,共同进步!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号