

Java学习笔记
Java学习笔记
第一章 java基础
1.1 java关键字和标识符
关键字:
一般是编译器(eclipse或者idea)高亮显示的都是java当中的关键字,这些关键字是程序员开发者不能修改的东西,比如public class static package等等,是sun公司规定好的。
标识符:
是程序员开发者能自己命名的单词,比如类名、方法名、变量名这些都是标识符
其中 Hello、main就是标识符
public class Hello {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}
标识符在使用的时候要遵守规则和规范:
a、规则:字母、数字、下划线、美元符号($),不能以数字开头,不能使用关键字
规则就是法律、语法,必须遵守,不遵守java语言就不通过,编译不通过
b、规范:可以不遵守,但我建议大家跟规则一样都要遵守,不遵守java也不会报错,跟道德一样
1.1 见名知意
1.2 驼峰式命名,有高有低,高低指的是英文的大小写
类名:首先不能用中文,用英文每个单词首字母大写,比如UserLogin
方法名:首字母小写,其余大写,比如eatFoods
变量名:
常量:每个单词全大写,单词之间下划线分开,COMPUTER_COLOR就是常量
public static final String COMPUTER_COLOR = "红色";
普通变量:首字母小写,其余大写,比如 computorBrand
1.2 字面值
字面值:java当中的数据,java语言组成部分,跟关键字、标识符一样
10、100、-200 整数
1.2 -1.2 浮点数
true、false 布尔值
'A' 'b' '我' 字符
“LiMing” 字符串
1.3 基本数据类型
计算机的一些常识
byte kb mb gb tb
1kb = 1024b
1mb = 1024kb
1gb = 1024mb
1tb = 1024gb
现在的计算机都是交流电的形式运行的,他只识别所谓的0、1电信号
java当中的8种数据类型:
整数型:
byte
short
int
long
浮点型(一般用来表示小数的):
float
double
字符型
char
布尔型
booblean
进制:
2进制 0001
10进制 1 2 3 11 12 13
8进制 012
16进制 0xF
数据类型 占用字节数(1字节=8bit 也就是8位)
--------------------------------------------
byte 1
short 2
int 4
long 8
float 4
double 8
boolean 1
char 2
注意:
1、在java当中定义的整数字面值默认是int类型
在我们平常使用的时候,不要太过纠结它的大小,一般用默认的int类型定义整数就可以了。
2、类型转换问题:
用小范围的数接收大范围的数的时候,需要进行强制类型转换,但是转换之后的数据会不准确,也就是精度丢失。
强制类型转换的时候慎重加慎重。
只要涉及到类型转换就要慎重!!!!!
3、在java当中定义浮点字面值的时候默认是double类型
4、默认值:一切向0看齐
整数:默认值就是0
浮点数:默认0.0
布尔值:默认false
1.4 字符
编码:计算机协会规定了一套标准,用来作为计算机和文字之间的一套字典参照表,文字和数字之间的转换表,
因为计算只认0、1,单纯的文字计算机解释不了。
解码:计算机按照规定格式的字典参照(编码格式),将存储到计算机内存当中的编码后的二进制文字再解释出来。
编码-解码要按照同一套标准,如果两边标准不一致,就会出现乱码的问题。
常见的编码格式:Ascll、GBK、Unicode(Utf-8)
以后开发当中经常用到的编码UTF-8
如何定义一个字符:
语法: char 变量名 = 字面值;
字面值是用''括起来的字符,字符只能是单个字符,当然转义字符是一种特殊的字符,不要混淆了,其实也是单 个字符。
如: char char1 = 'A';
char cahr2 = '我';
char char3 = '\u0001';
转义字符:有一些特殊的字符无法用我们认识的文字表示出来,就规定了可以将常见的字符进行转义,表示出来
比如
\n, 不加\ 就是一个普通的n字符,加了就是回车或换行
\t, 不加\ 就是一个普通的t字符,加了就是tab键
\\ \b \r
1.5 算数运算符
加(+)、减(-)、乘(*)、除(取商/ 取余%)、自增(++)、自减(--)
注意:核心点自增和自减
自增: ++前后都可以放变量
变量在前:先用后本身的值加1
变量在后:先本身的值加1再用
自减: --前后都可以放变量
变量在前:先用后变量本身的值减1
变量在后:先本身的值减1再用
public class Test03 {
public static void main(String[] args) {
int a = 10;
int b = 3;
System.out.println(a+b);
System.out.println(a-b);
System.out.println(a*b);
System.out.println(a/b);
System.out.println(a%b);
//++ --
//a++ 先用后加
//++a 先加后用
System.out.println("===========");
int c = 1;
System.out.println(c++);//1
System.out.println(++c);//3
System.out.println(c++);//3
System.out.println(++c);//5
System.out.println("############");
int d = 1;
int f = d++;
//在程序跑完第23行的时候,它做了哪些事情
//做了两件事
//第一件事情:先把d的值给f
//第二件事情:d自增,就是d本身加1,这时候d=d+1变成了2
//注意前后两件事是按顺序的
//f=1;
//d=2;
System.out.println(d);
System.out.println(f);
f = ++d;
//在程序跑完第35行的时候,它做了哪些事情
//做了两件事
//第一件事情:d自增,就是d本身加1,这时候d=d+1变成了3
//第二件事情:把自增后的d的值给到了f
//注意前后两件事是按顺序的
//d=3
//f=3
System.out.println(d);
System.out.println(f);
}
}
1.6 赋值运算
= (赋值)
+=(加等于)
-= (减等于)
*=(乘等于)
/= (除等于)
%=(模等于)
注意:
1、做这些运算的时候,可能会出现精度丢失,也就是数据丢失的问题,需谨慎,而且编译器是不会报错的
能解决的方法就是多自测
2、会存在类型转换的问题,不要想当然的认为a+=b就是a=a+b,具体以下为例
public class Test04 {
public static void main(String[] args) {
int a = 10;
int b = 2;
a += b;
System.out.println(a);//12
System.out.println(b);
a -= b;
System.out.println(a);//10
a *= b;
System.out.println(a);//20
a /= b;
System.out.println(a);//10
a %= b;
System.out.println(a);//0
System.out.println("============");
byte c = 126;
//byte f = 128;
int d = 2;
c += d;//c = 126+ 2
//byte c = 128;
//做这些运算的时候可能会出现精度丢失的问题
//编译器是检查不出来的,所以以后编程需谨慎,多自测
System.out.println(c);
long f = 100;
int g = 200;
f += g;
System.out.println(f);
double h = 10.1;
//g += h 并不等价于 g=g+h
//无论是+=还是-=等等赋值运算符会存在自动类型转换的问题
//其实下边这两个是等价的
g += h;
g = g + (int)h;
}
}
1.7 关系运算符
表达式:变量和符号组成的一条式子,它的结果是一个值;
< <= >= ==
表达式和表达式之间可以串联使用
public class Test05 {
public static void main(String[] args) {
System.out.println(4 == 3);
System.out.println(4 != 3);
System.out.println(4 > 3);
System.out.println(4 < 3);
System.out.println(4 >= 3);
System.out.println(4 <= 3);
boolean a = (4 > 3);
boolean b = (5 < 2);
System.out.println(a == b);
System.out.println((4 > 3) == (5 < 2));
}
}
1.8 逻辑运算符
什么是短路:
在程序当中正常的执行顺序被某个运算符给中断了,一条语句后边程序就不执行(不是不需要)了,
类似于生活中的短路现象。
常用的逻辑运算符:
!非
&&短路与
|| 短路或
具体后两种逻辑运算符达短路现象以下程序为例
public class Test01 {
public static void main(String[] args) {
System.out.println(!(4 > 3));
int a = 1;
//&&短路与
//true && true 为true
//true && flase 为false
//false && true 为false
//false && false 为false
System.out.println((4>3) && (5<2));//false
System.out.println((4<2) && (5>a++));
System.out.println(a);
//||短路或
//true || true 为true
//true || flase 为true
//false || true 为true
//false || false 为false
System.out.println((1>3) || (4<5));
int b = 2;
System.out.println((5>3) || (6<b++));
System.out.println(b);
}
}
1.9 三元运算符
语法:
条件表达式 ? 表达式1 : 表达式2;
注意:
1、三元运算结果是一个值,不能作为一条独立的语句;
2、后边两个表达式的数据类型要统一,不然编译期出错,当然发生自动类型转换的时候没问题的。
public class Test02 {
public static void main(String[] args) {
int a = 30;
int b = 30;
a = (b == 20 ? 2000 : 3000);
System.out.println(a);
//a = (b == 20 ? 2000 : 11.2);
//编译器a的类型模糊,不确定是整型还是浮点型,报错
}
}
2.0 运算符的优先级
没有必要去刻意记忆运算符的优先级,最简单的方式就是表达式之间加();
2.1 程序流程控制
2.1.1 选择结构if
三种用法
1、if(布尔表达式){
语句体;
}
2、if(布尔表达式1){
语句体1;
}else{
语句体2;
}
3、if(布尔表达式1){
语句体1;
}else if(布尔表达式2){
语句体2;
}else if(布尔表达式3){
语句体3;
}.......esle{
语句体...;
}
注意:
1、if else else if可以相互结合或者嵌套使用
2、在第三种方式里面else if是除了if或者elseif的其他情况,有些条件不要写重了
3、花括号括起来的是代码块,}不需要以分号结尾,他是一个整体结构,
只有一条条语句才需要分号结尾
public class Test03 {
public static void main(String[] args) {
int x = 0;
//if的第一种用法
if(x != 1) {
System.out.println(x);
}
int score = 60;
if(score > 90) {
System.out.println("优秀");
}
if(score < 90 && score > 70) {
System.out.println("良好");
}
if(score < 70) {
System.out.println("不及格");
}
//if的第二种用法
int age = 20;
if(age > 18) {
System.out.println("成年人");
}else {
System.out.println("未成年");
}
if(score > 70) {
if(score < 90) {
System.out.println("良好");
}else {
System.out.println("优秀");
}
}else {
System.out.println("不及格");
}
//if 的第三种用法
if(score > 90) {
System.out.println("优秀");
}else if(score > 70) {
System.out.println("良好");
}else {
System.out.println("不及格");
}
System.out.println("==========");
int score1 = 96;
if(score1 > 90) {
System.out.println("优秀");
}else if (score1 > 95) {
System.out.println("非常优秀");
}
}
}
2.1.2 switch语句
switch开关的意思
语法:
switch(表达式){
case 常量值:
语句体;
break;//可加可不加,但是要慎重
case 常量值:
语句体;
break;
......
default:
语句体;
break;
}
注意:switch开关在用的时候,只需要知道什么时候打开什么时候结束;
当switch表达式与case常量值匹配的时候开关打开,依次执行语句,去寻找break,直到遇到break
switch结束,找不到的话,直到switch结尾;
break:一般是用来结束switch和循环的;
public class Test04 {
public static void main(String[] args) {
int weekNum = 2;
switch(weekNum) {
case 1:
System.out.println("星期一");
break;
case 2:
System.out.println("星期二");
// break;
case 3:
System.out.println("星期三");
break;
case 4:
System.out.println("星期四");
break;
case 5:
System.out.println("星期五");
break;
case 6:
System.out.println("星期六");
break;
case 7:
System.out.println("星期天");
break;
default:
System.out.println("不存在的星期数字!");
break;
}
}
}
2.1.3 补充
获取键盘输入
import java.util.Scanner
public class Test05 {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
System.out.println("请输入一个数字:");
int a = scanner.nextInt();
System.out.println(a);
}
}
关于导包,比如
import java.util.Scanner
Scanner是别人写好的类,我们可以直接拿来用,但是,前提条件:
1、项目当中有相关的jar包
2、要通过import导入,其中上边java util都是文件夹 Scanner是类
要注意:不同文件夹下可能有同名的类,不要导错了
java.util.Scanner这个整体叫全限定类名
2.1.4 循环结构
注意:写循环一定不要写死循环,比如for(;😉 while(true){} do{}while(true)
2.1.4.1for循环(平时开发最常用)
语法结构:
for(1、初始条件表达式;2、是否循环判断表达式;4、增量表达式(步幅)){
3、循环执行的程序(循环体);
}
它的执行顺序:
第一步:初始表达式(只执行一次)
第二步:是否循环
如果第二步为真,执行第三步
如果第二步为假,结束
第三步:执行循环体,执行第四步
第四步:变量进行增量操作,执行第二步
public static void main(String[] args) {
//int x=1只执行一遍
for(int x = 1; x <= 100; x++) {
System.out.println(x);
}
}
注意:1、2、4三个表达式可以不写,但是成死循环了
for循环内初始表达式定义的变量只能在for循环里面使用,如果想在for循环外边使用该变量,需要把这个变量定义在for循环外边
public static void main(String[] args) {
//int x=1只执行一遍
int x;
for(x = 1; x <= 100; x++) {
System.out.println(x);
}
System.out.println(x);
}
增量表达式位置比较灵活,也可以写在循环体里面
2.1.4.2 while循环(不常用)
语法: while(循环条件表达式){
循环语句;
}
/*
* 输出1-100内3的倍数
* */
public class Test03 {
public static void main(String[] args) {
int x = 1;
while(x <= 100) {
if(x % 3 == 0) {
System.out.println(x);
}
x++;
}
}
}
2.1.4.3 do while循环(不常用)
语法: do{
循环语句;
}while(循环条件表达式);
/*
* 打印1-100之内的偶数
* */
public class Test04 {
public static void main(String[] args) {
int x = 1;
do {
if(x % 2 == 0) {
System.out.println(x);
}
x++;
}while(x <= 100);
System.out.println("========");
System.out.println("++++++++++");
}
}
注意:while循环是先判断后执行循环语句
dowhile先执行循环语句再判断
2.1.4.4 break和continue
break:
1、意为中断终止的意思
2、break;是一条独立的语句
3、可以用在switch中,可以用在循环当中
用在switch中是用来关闭开关的
用在循环当中用来结束当前for循环,离它最近的循环,结束不意味着整个程序终止,终止的是一个代码 块,代码块这里就是所谓的循环体
/*
* 输出256-1688内两个13的倍数
* */
public class Test05 {
public static void main(String[] args) {
int sum = 0;
int x;
for(x = 256; x <= 1688; x++) {
if(x % 13 == 0) {
System.out.println(x);
sum = sum + 1;
if(sum == 2) {
break;
}
}
}
System.out.println(x);
}
}
continue:
继续的意思,用于跳出当前循环(离它最近的循环),继续下一次循环;
continue;是一条独立的语句
/*
* 打印1-100内非7的倍数的整数
* */
public class Test06 {
public static void main(String[] args) {
for(int x = 1; x <= 100; x++) {
if(x % 7 == 0) {
continue;
}
System.out.println(x);
}
}
}
2.2 数组
定义:用来存储多个相同数据类型的数据模型(相同、多个)
声明方式:
第一种: 数据类型[] 数组变量名 = {};
{}里面是具体存放的一个对应数据类型的数
例:int[] twoDepAges = {20,30,18};
第二种:数据类型[] 数组变量名 = new 数据类型[数组的长度];
以上两种方式都是要在JVM堆内存中开辟一段内存空间,用来存放数组数据,数组变量名是赋的值不是表面上看到的数组,其实是数组变量赋的值是堆内存存放数组数据所在的地址,并且这个地址数据又被放在了栈内存当中。
注意:数组每一次声明,都是要重新开辟堆内存的,即使两个数组存的数据一样,如果是声明了两个数组变量,两个数组变量是不相等的,具体参考最后一个代码实例;
具体关于JVM内存结构,看2.3
public static void main(String[] args) {
int pengAge = 32;
int wangPengAge = 18;
int dongHaoAge = 20;
//定义了一个长度是33的整数数组
//第一种方式
//int[] twoDepAges = {10,20};
//第二种方式
int[] twoDepAges = new int[33];
}
数组的存值、取值、遍历
/*
* 第一种数组声明方式(静态初始化)
* 存值
* 取值
* 遍历
* */
public class Test02 {
public static void main(String[] args) {
//声明,在声明的时候已经存值了
int[] depAges = {18,20,30};
//取值,取出第三个位置的存放的数
//数组变量名[下标]
int pengAge = depAges[2];
System.out.println(pengAge);
System.out.println(depAges[0]);
//数组越界,取值的时候下标不能超出数组的长度范围
// System.out.println(depAges[3]);
System.out.println("=============");
//数组遍历
for(int x = 0; x <= 2; x++) {
System.out.println(depAges[x]);
}
int[] depHigh = {44,3,55,23,33,45,89,42,77};
//获取数组的长度
//数组变量名.length, length不是最大的下标,其实就是
//数组数据的个数
System.out.println(depHigh.length);
for(int y = 0; y < depHigh.length; y++) {
System.out.println(depHigh[y]);
}
//增强for循环
int[] depWeight = {12,13,14};
for(int z : depWeight) {
System.out.println(z);
}
boolean[] flags = {true,false,false};
for(boolean m : flags) {
System.out.println(m);
}
}
}
/*
* 第二种数组声明方式,动态初始化
* 存值
* 取值
* 遍历:两种声明方式的遍历是一样的
* */
public class Test03 {
public static void main(String[] args) {
//这里的33是指的数组里面数据的个数,数组的长度
//其实这种方式也存值了,只不过不同数据类型系统给了一个默认值
//整型:0
//浮点型:0.0
//布尔型:false
//引用数据类型:null
int[] depAges = new int[33];
System.out.println(depAges[1]);
double[] depAges1 = new double[20];
System.out.println(depAges1[3]);
boolean[] depAges2 = new boolean[12];
System.out.println(depAges2[4]);
//重新赋值(存值)
//int a = 0;a = 30;
System.out.println(depAges[2]);
depAges[2] = 30;
System.out.println(depAges[2]);
}
}
关于数组的比较,以下为例,自己结合JVM体会一下

public class Test04 {
public static void main(String[] args) {
int[] a = {1,2,3,4};
int[] b = a;
int c = 10;
int d;
// System.out.println(d);
System.out.println(a);
System.out.println(b);
System.out.println(a == b);
a[1] = 10;
System.out.println(b[1]);
System.out.println(a);
System.out.println(b);
int x = 1;
int y = x;
}
}
public class Test05 {
public static void main(String[] args) {
int[] a = new int[3];
a[0] = 10;
a[1] = 20;
a[2] = 30;
int[] b = new int[3];
b[0] = 10;
b[1] = 20;
b[2] = 30;
System.out.println(a);
System.out.println(b);
System.out.println(a == b);
int[] c = {1,2};
int[] d = {1,2};
int[] f = new int[2];
f[0] = 1;
f[1] = 2;
System.out.println(c == d);
System.out.println(c == f);
}
}
2.3 JVM内存模型

程序计数器:主要是控制线程当中程序的执行性顺序的;
虚拟机栈:我们平常接触到的最多的就是局部变量,局部变量定义的时候必须要给初始值,这是JVM规定的;
堆:存放对象和数组
元数据:常量池(比如字符串常量)、方法元信息、类元信息
2.4 字符串
声明:
第一种(字符串常量):
String 字符串变量名 = "字符串字面值";
第二种(字符串对象):
String 字符串变量名= new String("字符串字面值");

public class Test01 {
public static void main(String[] args) {
//第一种,创建字符串常量
String s1 = "hello world";
String s2 = "h";
String s3 = " ";
String s4 = "";
String s5 = "我";
String s6 = "china中国";
//第二种,创建字符串对象
String s7 = new String("wukelan");
String s8 = new String("中国");
}
}
字符串拼接:+
1、+在java当中有两种运算方式
加法运算
字符串拼接运算
2、在字符串拼接时,表达式中如果出现了多个+,而且在没有小括号的前提下,遵循从左到右依次运算
如果+左右是数字,做加法运算,如果+左右至少有一个字符串就做拼接运算
public class Test02 {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "world";
String s3 = s1 + s2;
System.out.println(s3);
String s4 = s1 + 10;
System.out.println(s4);
String s5 = s1 + 10 + 20;
System.out.println(s5);
String s6 = 10 + 20 + s1;
System.out.println(s6);
String s7 = 10 + (20 + s1);
System.out.println(s7);
}
}
字符串比较的两种方式,特别是字符串拼接的比较
/*
* 字符串比较:
* 1、== 比较的是地址
* 2、equals 比较的是字符串值(字面值)
* */
public class Test03 {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "world";
String s3 = s1;
String s4 = "hello";
String s5 = new String("hello");
String s6 = new String("hello");
String s7 = "helloworld";
//先创建一个字符串对象,然后将两个字符串值拼接,去常量池搜索
//拼接后的字符串,如果存在,将对象的地址指向该字符串常量池地址
//然后,将对象的地址给到s8
String s8 = s1 + s2;
//先拼接字符串,然后去常量池搜索拼接后的字符串,如果存在
//直接将该常量池当中的字符串地址指向s8
String s9 = "hello" + "world";
String s10 = s1 + "world";
String s11 = "hello" + new String("world");
System.out.println(s1==s2);
System.out.println(s1 == s4);
System.out.println(s1 == s5);
System.out.println(s5 == s6);
System.out.println(s7 == s9);
System.out.println(s7 == s8);
System.out.println(s7 == s10);
System.out.println(s7 == s11);
System.out.println("=========================");
System.out.println(s1.equals(s4));
System.out.println(s7.equals(s8));
System.out.println(s7.equals(s9));
System.out.println(s1.equals(s2));
}
}
两个string相关的类StringBuffer StringBuilder
/*
* 两个String相关的类
* StringBuffer 线程安全
* StringBuilder 非线程安全
* */
public class Test04 {
public static void main(String[] args) {
//+和append的区别,+如果是字符串对象的拼接需要每次都要创建一个对象
//StringBuffer.append不需要每次创建对象
StringBuffer s1 = new StringBuffer("hello");
//追加
s1.append("world");
String s2 = new String("hello");
String s3 = s2 + "world";
String s4 = s3 + "1111";
System.out.println(s1);
s1.reverse();
System.out.println(s1);
StringBuffer s5 = new StringBuffer("123456");
s5.delete(1, 2);
System.out.println(s5);
StringBuilder s6 = new StringBuilder("hello");
System.out.println(s6);
s6.reverse();
String s7 = "abcdef";
System.out.println(s7.charAt(4));
System.out.println(s7.substring(0, 4));
}
}
2.5 方法
方法:将java当中某一特定的功能抽取出来,包含在大括号内,这样的形式成为方法;
方法的使用在java当中叫做调用。
方法的定义:
[修饰符列表] 返回类型 方法名(形参列表){
方法体;
return 对应的数据类型;(当有返回值时使用)
}
1、修饰符列表:
方法中的修饰符可以有多个
现在先统一用public static,至于为什么后边讲解
2、返回类型
a、当方法不需要返回结果时,返回类型定义为void(空)
b、当方法需要返回结果时,放回类型可以为基本数据类型、引用数据类型,结合return使用,
也就是return返回的类型必须要和方法定义的返回类型保持一致;
而且,方法体中代码终止的地方必须要有return
方法体中不能出现不可到达的代码,否则编译不通过
3、方法名(标识符):
命名规范:见名知意,尽量使用动词,使用英文,多个单词的话首字母小写其余大写
4、形参列表(可以没有,也可以有多个)
形参:方法当中定义的参数列表
实参:调用方法时传入的实际的值(字面值)
注意:形参的类型可以为基本数据类型,引用数据类型
在方法调用的时候,形参和实参必须保持一致(类型一致,个数一致、顺序一致),方法中 形参类型跟变量名无关
/*
* 方法的定义和使用
* */
public class Test02 {
public static void main(String[] args) {
int result = sum(10,20);
System.out.println(result);
print(10,20);
System.out.println(getMax(5,6));
}
/*
* 求和运算
* */
public static int sum(int a, int b) {
return a + b;
}
/*
* 打印a*b的结果
* void也是一种类型,代表空
* */
public static void print(int a, int b) {
System.out.println(a*b);
// return;
}
/*
* 比较两个整数的大小,返回大的值
*
* */
public static int getMax(int a, int b) {
if(a > b) {
return a;
}else {
return b;
}
}
/*
* 1-10之间找7
* */
public static int getSeven() {
for(int i = 1; i <= 10; i++) {
if(i == 7) {
return i;
}
}
return 0;
}
}

/*
* 形参和实参
* */
public class Test03 {
public static void main(String[] args) {
//1、形参实参必须类型一致
//20 "10"就是实参,使用或调用方法时传入给到的参数
//sum方法当中 a b形参
//int result = sum("10",20);
//2、个数一致
//String result1 = append("100", 20, 30);
//3、顺序一致
//String result2 = append(10, "20");
long a = 100;
long b = 1000000000000L;
//自动类型转换
long result3 = mutiple(20,30);
//传递的是数组的地址,在调用testArr的时候,这个方法根据
//形参接收到数组的地址,然后根据地址找到对应的数组,
//将数组存放在堆当中的数组数据改变了,
//但是实际array指向的地址没有被改变
//那么main方法中调用testArr结束的时候,
//还是根据地址去堆里找之前存放的数组,
//这个时候第二个位置的数被改变了
int[] array = {0,1,2,3};
System.out.println(array);
testArr(array);
System.out.println(array[1]);
//int d 是main当中的参数,调用add的时候传递的实参是值
//add方法中用形参接收,改变形参的值对main当中的d没有影响
int d = 10;
add(d);
System.out.println(d);
}
/*
* 求和
* */
public static int sum(int a, int b) {
return a + b;
}
/*
* 拼接字符串
* */
public static String append(String a, int b) {
return a + b;
}
/*
* 乘法
* */
public static long mutiple(long a, long b) {
return a * b;
}
/*
*改变数组第二个位置的数
* */
public static void testArr(int[] a) {
a[1] = 10;
}
public static void add(int a) {
a = a + 1;
}
}
/*
* 方法当中定义变量(局部变量)必须要给初值值
* */
public class Test04 {
public static void main(String[] args) {
}
/*
* 打印
* */
public static void print() {
int a = 0;
System.out.println(a);
//b没有初始值程序报错
//int b;
//System.out.println(b);
}
}
/*
* 方法相互调用
* 1、方法当中可以调用方法,但是不能嵌套方法,跟ifelse for循环不一样
* 2、方法在类当中的位置没要求
* 3、方法相互调用可能会有问题,可能会有栈溢出的问题
* 4、递归调用(尽量不要写)
* 5、方法调用遵循栈的原则(子弹匣),先进后出
*
* */
public class Test05 {
public static void main(String[] args) {
System.out.println("+++++++++");
method1();
System.out.println("==============");
}
public static void method1() {
System.out.println("method1 start");
method2();
System.out.println("method1 end");
}
public static void method2() {
System.out.println("method2 start");
System.out.println("method2 end");
//method1();
}
//递归调用
public static void method3() {
method3();
}
}
2、面向对象编程
2.1 面向对象和面向过程
面向过程:整个系统由一个主方法去完成,然后如果某一环节出问题,其他环节都受到影响。
这样,系统的耦合度(程序和程序之间关联度)非常高,复用率非常低。
涉及一些小的系统的时候,面向过程还是有优势的,效率要高。
面向对象:整个系统由主方法去完成对象和对象之间的相互合作,这样的话,可以极大的提高代码
复用率,以及降低系统的耦合度。
2.2 类
概念:客观世界不存在的东西,就是看不见摸不着的东西,他是一个抽象的概念,在java当中就是一个模板。
抽象:将很多事物具有共性提取出来给出一个概念,这是一个抽象的过程。
类—>对象的过程,在java当中叫实例化
对象—>类的过程,在java当中叫抽象
2.2.1 定义
[修饰符列表] class 类名 {
类体;
}
修饰符列表: public,用它修饰类的时候类名要和文件名必须保持一致
abstract final等也可作为类的修饰符
类名:参考标识符规范去定义
类体:包括属性和方法
属性:用变量表示
变量(成员变量):包括实例变量和静态变量
实例变量:变量的访问需要创建实例
静态变量:后边补充...
方法:实例方法和静态方法
[修饰符列表] 返回类型 方法名(参数列表){
方法体
}
public class Student {
/* 1、属性用变量表示
2、可以为基本数据类型也可以为引用数据类型
3、引用数据类型,他就是一个变量,指向的是一个内存地址
比如String,所有java当中的class都是引用数据类型,
当前我们所在的Student就是引用数据类型
4、int age是实例变量,它属于对象,只能通过对象访问,
或者访问它的时候必须要经过类-对象的实例化过程
5、类体当中的变量可以没有初值,系统会给默认值,
一切向0看齐
整型->0
浮点型->0.0
引用数据类型->null
6、类体当中,在方法之外的变量统一叫做成员变量
方法体中的变量叫做局部变量
*/
int age;
boolean sex;
int stuId;
/*
* 引用数据类型
* */
String name;
//方法后边补充
}
2.3 对象
什么是对象:客观世界真是存在的物体,看的见摸得着的。
创建对象:
类名 引用变量名 = new 类名();
访问类的变量和方法
访问变量: 引用变量名.实例变量名
给实例赋值: 引用变量名.实例变量名 = 字面值
比如如下代码(Test02):
访问方法:引用变量名.方法名(实参列表)
public class Test02 {
public static void main(String[] args) {
//类-对象的过程,实例化,需要使用new关键字
//new Student()就是一个对象
//peng是一个引用,指向的是这个对象的内存地址
//.简单理解为"的"意思
Student peng = new Student();
System.out.println(peng.age);
System.out.println(peng.name);
peng.age = 10;
peng.name = "xiaopeng";
}
}

上图片代表了一个Test03当中通过Fruits类实例化出一个banana的过程。
public class Fruits {
int weight;
String color;
String taste;
double price;
}
public class Test03 {
public static void main(String[] args) {
//前后两个banana是两个不同对象的引用地址
//每new一次就要在堆内存中开辟一个对象空间,所以前后打印的内容是不一样的
Fruits banana = new Fruits();
System.out.println(banana);
banana = new Fruits();
System.out.println(banana);
}
}
2.4 方法
方法的定义:
[修饰符列表] 返回类型 方法名(参数列表){
方法体;
return 对应方法的返回类型;(返回不为空的时候)
}
类当中的方法:
实例方法(需要创建对象才能访问)
如何调用: 引用变量名.方法名(实参列表)
静态方法
/*
* 先掌握方法的定义和调用,其他可以选择性放弃
* 能定义出来,能传值,能.调用出来,能接收返回值就可以了
* */
public class Cat {
//属性
int age;
String color;
String sex;
int weight;
//方法
//public static修饰词,可以没有
//静态方法
public static void sing() {
System.out.println("喵喵喵.........");
}
//实例方法,需要通过对象才能使用
public void catchMouse() {
System.out.println("抓老鼠.......");
}
//方法当中的参数可以为基本数据类型也可以为引用数据类型
//引用是一个变量,变量指向的是一个内存地址
public void eatFish(int fishNum) {
System.out.println("一顿能吃" + fishNum + "只鱼!");
}
public void eatFoods(String foodName) {
System.out.println("猫在吃" + foodName);
}
public void eatMouse(Mouse mouse) {
System.out.println("猫吃了一个" + mouse.name);
}
public void drink(int num) {
System.out.println("猫一次喝了2L水!");
num = num - 2;
}
public void eating(Food food) {
System.out.println("猫吃了十斤猫粮");
food.weight = food.weight - 10;
}
/*
* 方法返回值:可以为基本数据类型和引用数据类型
* 根据传进来的星期数,返回能睡几个小时
* */
public int canSleepHours(String weekOfday) {
if(weekOfday.equals("星期一")) {
return 2;
}else {
return 1;
}
}
/*
* 返回引用数据类型
* */
/*
public Wief getWief(int age, int sex) {
return xiaoHong;
}*/
}
测试类
public class Test01 {
public static void main(String[] args) {
Cat cafeCat = new Cat();
cafeCat.color = "咖啡色";
cafeCat.sex = "男";
cafeCat.catchMouse();
//方法传参,传递基本数据类型
cafeCat.eatFish(3);
//Cat.sing();
//cafeCat.sing();
//方法传参,传递引用数据类型
cafeCat.eatFoods("饼干");
//需要定义一个引用变量,然后引用变量指向一个具体的mouse对象
//调用eatMouse的时候将引用传递过去
//注意:这个地方是传的引用,也就是地址,地址是指向的对象的地址值
Mouse jerry = new Mouse();
jerry.name = "jerry";
cafeCat.eatMouse(jerry);
//传参改变的问题
//1、参数为基本数据类型,传递的是实际的数值
//传过去的值其实又被重新复制了一份
int cupWater = 10;
cafeCat.drink(cupWater);
System.out.println(cupWater);
//2、传递引用数据类型
//传递的是对象的地址,改变了地址指向的对象的属性值,都会受到影响
Food cafeFood = new Food();
cafeFood.weight = 20;
cafeCat.eating(cafeFood);
System.out.println(cafeFood.weight);
//返回值
int result = cafeCat.canSleepHours("星期二");
System.out.println(result);
}
}
2.4.1 方法重载
重载:也叫overload,就是一个类当中可以有相同方法名但参数列表不同的方法,这种现象叫做重载。
作用:方便调用者使用,在使用的时候就像是在使用同一个方法,其实本质不是一个。
什么时候用到重载:多个方法的功能相似的时候可以考虑。
重载的条件: 1、方法名相同(区分大小写)
2、形参不同(类型、个数、顺序不同)
注意:跟方法的返回类型无关
public class Calcuator {
public int sum(int a, int b) {
System.out.println("int.........");
return a + b;
}
//不行,这里是方法重复而不是重载了
// public int sum(int c, int d) {
// System.out.println("int.........");
// return c + d;
// }
public int sum(int a, int b, int c) {
System.out.println("int.........");
return a + b + c;
}
public double sum(double a, double b) {
System.out.println("double.........");
return a + b;
}
public float sum(float a, float b) {
System.out.println("float...........");
return a + b;
}
}
2.5 包(package)
包的作用:用来限制类的使用或者访问,有可能在一个项目当中不同包下有相同的类,但是相同名称的类包含的属性和方法可能不一样,需要使用哪个方法就要对应选择导入(import)相应的类。
注意:如果选的是同一包下的类,就不需要导包(import)。
import java.util.Scanner
import是导入的意思,java.util.Scanner这是一个全限定类名,java.util是包路径 Scanner是类名
2.6 this关键字
1、this在java当中是一个关键字,是这个的意思,用来表示指向当前对象的引用。
什么是引用? 引用是一个变量,变量指向的是一个内存地址
2、每创建一个对象就有一个相应的this
3、this关键字一般出现在实例方法或者构造方法中,用来表示执行此方法的当前对象。
public class Flower {
int high;
public Flower() {
System.out.println("++++++++++=");
}
public void water() {
System.out.println("water========" + this);
high = high + 1;
}
public static void shiFei() {
//报错,因为this是对象级别的变量,不能出现在static方法当中
//this;
}
}
public static void main(String[] args) {
Flower xiLanHua = new Flower();
System.out.println(xiLanHua);
xiLanHua.high = 10;
xiLanHua.water();
System.out.println(xiLanHua.high);
Flower rose = new Flower();
System.out.println(rose);
rose.high = 20;
rose.water();
System.out.println(rose.high);
}
2.7 构造方法
1、构造方法,又叫做构造器、Constructor
2、作用:创建对象,给对象属性赋值
3、构造方法的定义:
[修饰符列表] 当前的类名(形参列表){
构造方法体;
}
注意:构造方法是没有返回类型的,即使是void也不能加
4、构造方法有两种
a、形参列表有参数叫做有参构造,
b、无参数叫做无参构造,又叫做空构造
5、
a、如果类当中没有声明构造方法,其实是有一个默认的无参构造;
b、如果类当中声明了构造方法(不管有参无参),系统不会再默认有一个无参构造了!!!
如果想要调用无参构造创建对象必须显示在类当中声明出来;
public class User {
String name;
int age;
//无参构造
public User() {
System.out.println("调用无参构造.....");
}
//有参构造
public User(String a, int b) {
// System.out.println("调用有参构造......");
this.name = a;
this.age = b;
}
}
public static void main(String[] args) {
User zhangSan = new User();
User liSi = new User("李四", 20);
//sum(1,2);
//sum(1.2,1.3);
User wangP = new User();
wangP.age = 20;
wangP.name = "wangp";
User dongH = new User();
dongH.age = 18;
dongH.name = "dongH";
User liSiY = new User("lSY",20);
}
2.8 静态(static)
2.8.1 静态变量、实例变量
1、静态变量,用static修饰符修饰的变量,它是类级别的变量,使用的时候通过 类名.变量名
比如:American.nation
所谓的类级别的变量是指,定义在这个类当中的某个属性只会有一个值,比如国家的国籍问题
一般情况下这种变量被定义为 static final的
2、实例变量,所谓的实例就是指对象,对象级别的变量,只能通过创建对象访问。
public class American {
//实例变量,对象级别的属性
int carId;
//类级别的属性
final static String nation = "美国国籍";
public static void eat() {
System.out.println("吃饭.........");
}
}
public static void main(String[] args) {
// American.nation = "美国国籍";
American teLangPu = new American();
teLangPu.carId = 1001;
System.out.println(teLangPu.nation);
// teLangPu.nation = "美国国籍";
American baiDeng = new American();
baiDeng.carId = 1002;
// baiDeng.nation = "中国国籍";
System.out.println(baiDeng.nation);
American aoBaMa = new American();
aoBaMa.carId = 1003;
// aoBaMa.eat();
// aoBaMa.nation = "美国国籍";
System.out.println(aoBaMa.nation);
//静态变量使用的时候要用 类.静态变量名,不能用对象
System.out.println(American.nation);
American.eat();
}
2.8.2 静态方法
静态方法主要是掌握:静态方法中不能直接访问实例变量、实例方法,如果非要访问必须要创建对象。
静态方法以后主要是用在工具类中,现在不常用,所以以后定义方法大部分还是实例方法。
/*
* 变量
* 类{
* 属性:变量
*
* 方法:
*
* }
*
* 1、变量:成员变量和局部变量
* a、成员变量:定义类体当中方法之外的变量
* 分为:实例变量和静态变量
* 实例变量:对象级别的变量,需要依赖对象来访问
* 静态变量:类级别的变量,比如美国人类的国籍,男人类的性别,
* 这种取决于当前类的变量可以用静态变量来定义。
* b、局部变量:方法体当中声明的变量
* 方法体当中声明的局部变量,必须要给默认值、初值(系统规定的)
* 方法当中的形参变量,也可以认为是局部变量
* 2、方法:实例方法和静态方法
* 实例方法:对象级别的方法,需要创建对象才能调用,
* 通过"引用."的方式调用
* 静态方法:类级别的放法,无需创建对象,
* 通过"类名."的方式调用
*
* 注意:a、静态方法中不能直接访问实例变量、实例方法,
* 因为实例变量和方法都是对象级别的,
* 而静态是类级别的不需要创建对象就可以调用
* 这与实例变量、方法相悖
* b、如果非要访问实例变量或者调用实例方法就需要
* 在静态方法中创建对象
* c、实例方法当中可以访问实例变量、静态变量
* 也可以调用实例方法、静态方法
* d、什么时候用静态方法?什么时候用实例方法?
* 一般静态方法用在工具类当中。
* 实例方法:比如考试这个行为,每个人考试的成绩是不同的,是具体到对象上的一种行为
* 就可以用实例方法表示。
* */
public class Man {
//实例变量
int age;
//静态变量
static String sex = "男";
//实例方法
public void method(int d) {
age = 10;
//c是局部变量
int c = 0;
System.out.println(d);
}
//静态方法
public static void method2() {
System.out.println("====");
Man wo = new Man();
wo.age = 10;
// age = 10;
sex = "女";
}
public void method3() {
method(1);
method2();
age = 10;
sex = "男";
}
public static void main(String[] args) {
// method();
// age = 10;
Man man = new Man();
Man.method2();
man.method2();
}
}
2.9 面向对象的三大特征(封装、继承、多态)
2.9.1 封装
封装:在java当中将一些信息隐藏起来,限制它的访问。
在java当中主要是通过访问修饰符来限制的
修饰符 同类 同包不同类 子类 (后边补充) 不同包不同类
public true true true true
protected true true true false
无修饰符 true true false false
private true false false false
public class Person {
//关于以下几个修饰符最常用的public private
public int age;
protected String name;
boolean sex;
private int high;
private void printAge() {
age = 10;
name = "111";
sex = false;
high = 120;
}
public void test() {
printAge();
}
}
java当中最常用的一种封装方式是,将类当中的属性设置为private私有属性,然后通过生成对应的get/set方法访问属性。
生成的get/set方法一般都要按照开发规范来定义,比如方法名setName getName都是get/set加上对应的属性名首字母大写开头
具体以下代码为例
public class Person {
private int age;
private String name;
//set get
//set是设定,可以认为是赋值
//get是获取,可以认为是取值
public void setAge(int age) {
if(age > 0 && age <= 100) {
this.age = age;
}else {
System.out.println("年龄不合法!");
}
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
public void setName(String name) {
if(name.length() < 4) {
this.name = name;
}else {
this.name = name.substring(0, 3);
}
}
}
public class PersonTest {
public static void main(String[] args) {
Person liMing = new Person();
liMing.setAge(10);
System.out.println(liMing.getAge());
liMing.setName("我是李明");
System.out.println(liMing.getName());
}
}
2.9.2 继承
2.9.2.1 继承概念
1、继承:现实生活当中存在这样的场景,父亲拥有的东西,儿子可以不用再奋斗了,儿子可以直接继承父亲的财产。
2、在java当中的作用:
可以提高代码的复用性
体现在覆盖和多态方面(没有继承就没有多态)
3、怎么实现继承:用关键字 extends
public 子类名 extends 父类名{
类体
}
4、关于继承,在java当中只能单继承,一个子类只能有一个父类,也就是不能出现这种现象
public A extends B,C{}
但是可以间接继承,
publi A extends B , public B entends C
这个时候A间接继承C
5、public A extends B{}
A叫做子类,派生类、衍生类
B叫做父类、基类、超类
在java当中有祖宗类叫Object,所有的类都默认继承它,只要是定义的类都拥有Object的一些属性和方法
6、私有属性和方法不能被子类直接访问(可以通过父类的get、set方法访问)
继承的好处?
能提高代码的复用性,父类当中拥有的方法和属性,子类当中就不需要再定义了,
如果子类当中继承过来的方法一定要改造一下,这时候就需要重写的机制
public class Parent {
public int money;
public Parent() {
System.out.println("父类构造方法......");
}
public void method() {
System.out.println("Parent method....");
}
}
public class Child extends Parent{
public Child() {
System.out.println("子类构造方法.....");
}
}
public class ChildTest {
public static void main(String[] args) {
Child xiaoMing = new Child();
xiaoMing.money = 100;
xiaoMing.method();
}
}
2.9.2.2 继承—方法覆盖(重写)
(1)重写:子类当中有一个和父类当中相同的方法,子类将父类当中的方法重新实现了一下
(2)重写的条件:
1、两个类,类直接存在着继承关系(包括间接继承)
2、方法名相同
3、参数列表相同,和参数名无关
4、返回类型相同,必须严格一致(不存在所谓的自动转型)
5、访问修饰符相同或者子类的访问修饰符权限高于父类的访问修饰符
(3)什么情况下使用重写?重写有什么好处?
当子类继承父类的方法无法满足当前的业务需求时需要重写;
重写可以提高代码的复用性,有了继承和继承重写机制,才有了后边面向对象多态的机制
(4)构造方法不能被重写
(5)自己总结一下方法重载和方法重写的区别??
public class Animal extends Biology{
public int age;
public int high;
public String name;
private int call(int b) {
System.out.println("动物都会叫");
return 2;
}
protected void move() {
System.out.println("动物都会动");
}
// public void eat() {
// System.out.println("动物都会吃......");
//
// }
public int breathe() {
System.out.println("动物都会呼吸.....");
return 1;
}
}
public class Cat extends Animal{
public int tail;//尾巴
public void catchMouse() {
System.out.println("猫都会抓老鼠......");
}
public int call(int a) {
System.out.println("喵喵喵.......");
return 2;
}
public void move() {
System.out.println("猫在动......");
}
// public void method() {
//
// }
// public int method() {
// return 1;
// }
// public int eat() {
// System.out.println("猫都会吃鱼......");
// return 2;
// }
// public byte breathe() {
// System.out.println("猫也会呼吸.....");
// return 3;
// }
public void drink() {
System.out.println("猫也会喝水......");
}
}
public class CatTest {
public static void main(String[] args) {
Cat cafeCat = new Cat();
cafeCat.age = 10;
cafeCat.high = 20;
cafeCat.name = "加菲猫";
cafeCat.tail = 1;
cafeCat.drink();
cafeCat.call(1);
cafeCat.catchMouse();
Tree bigTree = new Tree();
bigTree.drink();
//父类当中的构造方法能不能被重写??
}
}
2.9.3 super关键字
(1)super是java当中的一个关键字,是一个引用,指向子类当中创建的父类对象
(2)super的用法
1、创建子类对象的时候,调用子类构造方法,会在子类构造方法当中隐式调用父类的构造方法,相当于super();
super()必须要放在方法体的第一行,因为先有父类对象,才有子类对象
2、也可以使用super(实参)调用父类的有参构造
3、当父类当中只声明了有参构造方法,创建子类对象时必须显示调用父类的有参构造,否则会编译不通过;
因为如果不显示调用父类有参构造,系统默认调用父类无参构造,结果父类中没有无参构造(父类中如果声明了无参构造,默认 的无参构造方法就不存在了),所以编译报错。
4、可以使用super. 访问父类的属性和调用父类的方法
(3)为什么子类实例化要调用父类构造方法??
因为子类继承了父类,子类实例化时想要继承父类的属性和方法(实例变量、实例方法),需要有父类对象才能继承,所以要先创建父类对象,创建父类对象就要调用父类的构造方法。
public class Car {
String name;
public void run() {
System.out.println("车都会跑.....");
}
public Car() {
System.out.println("父类构造方法");
}
//
public Car(int a) {
System.out.println("父类有参构造方法......");
}
}
public class BMW extends Car{
int money;
//构造方法不能被重写,因为子类对象不能创建父类对象
// public Car() {
// System.out.println("=====");
// }
// public Car(int a) {
//
// }
public BMW() {
//super();//不加系统会隐式的调用父类的无参构造方法创建父类对象
//加上super就是显示的调用
// super(1);
// super();
// super();
System.out.println("子类的构造方法");
}
}
public class BMWTest {
public static void main(String[] args) {
//BMW是一个类,当然也就是一个引用数据类型
//BMW bmw5是声明了一个BMW类型的引用变量
//bmw5 指向的是一个地址,new BMW这个对象的堆地址
//BMW()是调用子类的构造方法
BMW bmw5 = new BMW();
System.out.println(bmw5);
}
}

this和super的总结
1、this和super都是java当中的关键字
2、this是每创建对象的时候就会生成一个相应的this引用,指向当前对象,可以参考上边的内存图
super是创建子类对象的时候,会创建一个父类对象,super是指向的创建的父类对象的引用
3、this()代表调用当前类的构造方法,super()代表调用父类构造方法
this()和super()必须要置于方法体的第一行
4、this.可以访问字类的属性和父类的属性,可以调用父类和子类的方法
super.可以访问父类的属性和调用父类的方法
2.9.4 多态
1、多态:编译期一种状态,运行时一种状态
2、多态相关的两个概念:转型
2.1 无论是向上转型还是向下转型,两个类型直接必须要存在继承关系,否则会报错类型转换异常!
2.2 向上转型(类似于自动类型转换):父类引用指向子类对象
Animal dog = new Dog();
2.3 向下转型
Cat cat = new Cat();
Animal cat = (Animal)cat;
3、为了防止类型转换异常,可以通过运算符instanceof在转换之前进行类型判断
语法: A instanceof B,结果是一个布尔值,表示A是否是一个B的类型
4、多态有什么好处?
提高代码的扩展力,以后功能需求可能随时变动,没有多态可能需要改动大量的代码,有了多态可能只需要修改几行代码。
public class Phone {
public int price;
public String chip;//芯片
public void call() {
System.out.println("打电话......");
}
}
public class Mi extends Phone{
public void redLine() {
System.out.println("遥控器......");
}
}
public class HuaWei extends Phone{
public String brand;
public String os;
public void nfc() {
System.out.println("刷卡坐公交车.....");
}
public void call() {
System.out.println("防诈骗......");
}
}
public class Test02 {
public static void main(String[] args) {
Phone phone = new Phone();
phone.call();
HuaWei mate5 = new HuaWei();
mate5.call();
// phone.nfc();
mate5.nfc();
System.out.println("===========");
//1、向上转型,子类对象指向父类引用
Phone mate6 = new HuaWei();
//2、向下转型,要慎重!!!可能会出现类型转换异常的错误
HuaWei mate61 = (HuaWei)mate6;
// mate6.brand = "梅特6";
mate6.call();
mate61.nfc();
//类型转换异常,因为Mi类和HuaWei类没有继承关系
// Mi mi11 = (Mi)mate6;
//上边程序报错,程序被中断了,后边的程序就无法继续了
System.out.println("++++++++++");
Phone phone1 = new Mi();
//instanceof是一个运算符
// A instanceof B 结果是一个布尔值
//可以防止强制类型转换的时候出现异常
if(phone1 instanceof HuaWei) {
HuaWei mate7 = (HuaWei)phone1;
mate7.nfc();
}
if(phone1 instanceof Mi) {
Mi mi12 = (Mi)phone1;
mi12.redLine();
}
//Phone引用数据类型
//引用数据类型的默认值是null
//空值强制转换的时候,不会出现转换异常,但是强转之后的变量也是一个null
//后边在使用的时候可能出现空指针异常
Phone phone2 = null;
// phone2.chip = "1111";
HuaWei mate9 = (HuaWei)phone2;
System.out.println(mate9);
mate9.nfc();
}
}
4、通过多态机制实现一个主人养宠物的例子,主人只需关注喂养的是一个宠物,而不需关注具体样的是什么类型的宠物,不同类型的宠物都有吃的行为,但是可能吃的粮食不一定,而主方法(main)不需要关注这些,主方法只关注主人和宠物这两个对象,具体内部的实现机制是通过多态和继承来表现的。
public class Pet {
public String name;
public void eat() {
System.out.println("宠物吃东西......");
}
}
public class Dog extends Pet{
public void eat() {
System.out.println(this.name + "吃狗粮......");
}
}
public class Cat extends Pet{
public void eat() {
System.out.println(this.name + "吃猫粮.....");
}
}
public class Master {
public String name;
public void feed(Pet pet) {
pet.eat();
}
}
public class PetTest {
public static void main(String[] args) {
Master xiaoMing = new Master();
xiaoMing.name = "小明";
Dog haShiQi = new Dog();
Cat cat = new Cat();
Pet pet = new Dog();
pet.name = "哈士奇";
xiaoMing.feed(pet);
System.out.println();
}
}
2.9.5 异常
2.9.5.1 什么是异常??
不正常的现象,在代码当中就是我们常见的报错,
Exception: CalassCastException、ArrayIndexOutOfBoundException、NullPointerException、 ArithmeticException
Error: StackOverflowError、OutOfMemoryError
2.9.5.2 异常的分类:
运行时异常(非检查异常):
CalassCastException ArrayIndexOutOfBoundException NullPointerException
ArithmeticException
非运行时异常(可检查异常、编译期异常):
FileNotFoundException (IO学习时会使用)SQLException(Jdbc学习时使用)
注意:运行时异常一般情况下不需要处理,用业务逻辑去控制,比如if else,比如类型转换时用
instanceof,空指针异常用非空校验去处理,而不是用trycatch或throws
非运行时异常,尽量自己trycatch 不要throws,这种异常建议必须要处理。
错误(error)StackOverflowError、OutOfMemoryError
解决不了,只能避免,平时写代码尽量不要写死循环、不要写递归。
2.9.5.3 处理异常的方式:
1、try catch
try{
可能出现异常的代码块
}catch(异常类){
异常处理代码块;
}
try花括号内的代码一定要是可能出现的代码,不要把所有代码都放在try内
public class Test03 {
public static void main(String[] args) {
int a = 10;
int b = 0;
//不加trycatch 是由jvm来处理的,程序会被中断,
//不会继续往下进行了
System.out.println(a / b);
//加了trycatch是我们自己手动处理了异常,没有交给jvm,程序不会中断
try {
//可能有问题的代码块;
System.out.println(a / b);
}catch(ArithmeticException e) {//catch(异常类)
//异常处理代码块
//printStackTrace是自己手动打印的信息虽然跟jvm报错信息一样,
//但是机制不一样
e.printStackTrace();//打印异常信息,异常类自带的方法
// System.out.println("分母不能为0!");
}
System.out.println(a + b);
}
}
2、throws
方法名 throws 异常类(){
方法体;
}
2.1 throws类似于现实生活当中的甩锅,推卸责任,所以尽量少用
2.2 如果方法一致往上throws,最终还是要交给JVM所以不建议
2.3 假如方法A throws一个异常,表示这个方法有问题,类似于我们生活当中,
你用我的东西可以但 是可能有问题,要么你自己处理,要么你再甩(throws)给别人
public class Test05 {
public static void main(String[] args) {
}
public static void test() throws FileNotFoundException {
//查找对应路径下的文件
FileInputStream file = new FileInputStream("D:/11.txt");
}
public static void test1() throws FileNotFoundException {
test();
}
}
3、博客系统(项目)
准备工作:
1、电脑(Windows、IOS)、环境(java开发环境、JDK、数据库、服务器)
2、开发工具(Eclipse、Idea)
3、开发
3.1 新建一个java项目,根据不同的业务给项目进行分层(package)
3.2 入口(平时用到的测试类)、相关的业务实现类(用户、博客)
第二章 数据库基础
1、数据库概述:
数据库(database):用来持久化数据的仓库(容器),数据以文件格式(windows下边是frm文件)持久化到磁盘。
数据库系统(DBMS):数据库系统是来管理数据库的软件;
分为关系型数据库系统:MySql、Oracle
非关系型数据库系统:MongoDB、Redis(缓存数据库)、Hbase
MySql的发展历史:MySql---SUN--Oracle(甲骨文公司)
数据库管理员:DBA,一般是指维护、管理和开发数据库的相关人员。
java开发人员一般需要掌握基本的数据库增删改查即可;
SQL:结构化查询语句语言。用于数据库管理系统和数据库之间通信的桥梁。
一般常见的数据库都支持SQL,但是不同的数据库系统的SQL语法不一样。
数据库当中的表:
表在数据库里面的,表是由行和列组成的,一张表相当于java当中的类,
一行数据相当于对象,列相当于类当中的属性。
数据库表设计的三范式:
第一范式:不能存在多值字段,比如用户表中有一个爱好是一个多值字段,这样就是不合理的
第二范式:数据库中一张表中尽量减少存在依赖关系非必要字段;
第三范式:数据库一张表中尽量减少存在传递依赖的字段;例如:
学生(学号, 姓名, 系名, 系主任名)
学号 和系名、系主任名之间存在着传递关系。
总结:
以后在设计表的时候,要综合考虑数据和字段的关系,单纯考虑字段可能考虑不周全,
考虑到一张表以后有可能存上千万条数据,如果存在冗余字段,在维护(做增删改)的时候,
需要的成本(需要改变的数据量)。
2、MySql的数据类型
数值型:tinyint、smallint、int、bigint、float、double、decimal
tinyint用来定义一些标识字段,比如男女(0 1表示)、删除标识(0 1 表示)
int或bigint用来表示大范围的整数(正数、负数),比如主键id
float、decimal用来表示小数,特别是decimal用来表示金钱
时间: date、datetime、timestamp
date表示年月日 datetime 年月日时分秒
timestamp时间戳
字符串型:char 一般用来表示类似于 男女性别这样的字段
varchar 用来定义大范围的文字
text 用来表示文本
以上这些类型在java当中是定义为String类型的字段
3、SQL语句的分类
DDL:主要是包含库、表结构相关的语句
create、drop、alter
DQL:查询语句select
DML: 增删改语句 insert、delete、update
DCL: 事务相关、控制相关
if else when commit rollbacck
授权相关 grant revoke
3.1补充
1、每一条独立的sql语句要以分号(英文)结尾
2、sql的注释
-- (后边有空格) # /**/
-- 这里是第一种注释
# 这里是第二种注释
/*这里是第三种注释*/
4、库相关SQL
建库语法: create database 库名 CHARACTER SET utf8 COLLATE utf8_general_ci;
其中 CHARACTER SET utf8 COLLATE utf8_general_ci是设置字符集的语句。
为什么要设置字符集?
因为数据库的数据最终都是以文件的形式持久化到磁盘上的,字符集设置有问题容易出现乱码的问题。
删库语法: drop database 库名;
用库: use 库名;
注意:涉及到建库、特别是删库要慎重加慎重,可能以后在公司有DBA控制权限,但是还是要慎重!
5、表相关SQL
建表语法:
create table 表名(
字段名1 数据类型(宽度),
字段名2 数据类型(宽度),
字段名3 数据类型(宽度),
.......
);
注意:小括号内多个字段语句以逗号分隔,最后一个不加逗号
CREATE TABLE blog(
content VARCHAR(100),
tilte VARCHAR(50)
);
CREATE TABLE student(
id INT(11),
stu_name VARCHAR(10),
`password` VARCHAR(20)
);
CREATE TABLE teacher(
th_name VARCHAR(10)
);
注意:1、写sql时中英文输入法,特别是符号不要用错
2、库名、表名、字段名
一般情况下库名是项目名
表名tb_名字(多个英文下划线分开)而且表名不要太长,比如tb_student
字段名:多个英文下滑线分开
3、无论是什么名字,建议统一都用英文小写
删表语法:drop table 表名;
drop table if exists 表名;
上边两种,第一种如果删除的表不存在会报错,第二种不会。
DROP TABLE teacher;
DROP TABLE IF EXISTS teacher;
注意:删除要慎重!!!一定要!!
6、增加(insert)
语法1: insert into 表名 values(字段值1, 字段值2, ..........,字段值n);
关于字段值,第一个,语法1要把当前表中所有的栏位字段值都要给到值。
第二,如果字段值对应的栏位的数据类型是字符串,值是数字的话会自动变为字符串,不要用单引号括起来,其他的字符必须要用单引号阔气来。
INSERT INTO blog VALUES('111','222');
INSERT INTO blog VALUES(111,222);
INSERT INTO blog VALUES('标题','内容');
语法2:insert into 表名(栏位1, 栏位2, ......., 栏位n) values(值1, 值2, ......, 值n);
INSERT INTO blog(content) VALUES ('内容1');
INSERT INTO blog(content,tilte)
VALUES ('内容2','标题2');
content tilte
------------ --------------
博客内容 博客标题
111 222
内容1 (NULL)
内容2 标题2
注意:
1、语法2后边不需要给所有的栏位赋值,也就是第一个小括号中字段对应给到值即可,那么表中其他栏位的值怎么办?
如果这个栏位在创建表的时候设置的是有默认值的,就会用默认值自动填充,没有就是null。
2、int类型的字段在创建数据表的时候最好给到默认值。
CREATE TABLE cat(
age TINYINT(4) DEFAULT 1,
cat_name VARCHAR(10) DEFAULT '加菲猫',
sex CHAR(1)
);
INSERT INTO cat(age,sex) VALUES(10,'女');
age cat_name sex
------ --------- --------
10 加菲猫 女
上边的加菲猫是按创建表的时候设置的默认值自动填充的。
语法3:可以一次插入多条数据。
insert into 表名 values(字段值1, 字段值2, ..........,字段值n),(字段值1, 字段值2, ..........,字段值n),..........,(字段值1, 字段值2, ..........,字段值n);
INSERT INTO student
VALUES(1,'张三','123'),(2,'李四','456');
INSERT INTO student
VALUES(1,'张三','123'),(2,'李四','456');
语法4:insert into 表名(栏位1, 栏位2, ......., 栏位n) values(值1, 值2, ......, 值n),(值1, 值2, ......, 值n),....(值1, 值2, ......, 值n);
INSERT INTO student(id,stu_name)
VALUES(3,'王五'),(4,'赵六');
id stu_name password
------ -------- ----------
1 张三 123
2 李四 456
3 王五 (NULL)
4 赵六 (NULL)
7、更新SQL
语法: update 表名 set 栏位名1=值,栏位名2=值,.....,栏位名n=值 where 条件;
update修改的意思 set设定值的意思 where在符合条件的地方
注意:以后写修改语句where一定要尽可能要加上。
where条件要明确,你想要修改的数据一定要是确定符合条件的。
where 后边的条件可以为多个,可以用操作符连接
-- decimal(10,2) 10 代表整个数字的长度,2代表保留几位小数
CREATE TABLE goods(
id INT(11) PRIMARY KEY,
`name` VARCHAR(20),
price DECIMAL(10,2),
quality INT(11),
inventory SMALLINT(4)
);
INSERT INTO goods VALUES(5,'手机',1000,100,60);
INSERT INTO goods VALUES(2,'电脑',4000.126,100,60);
INSERT INTO goods VALUES(3,'手表',500.2,50,20),
(4,'耳机',100,60,10);
UPDATE goods SET price = 2400 WHERE `name` = '手机';
UPDATE goods SET price = 2500 WHERE inventory = 50
AND NAME='手机';
8、删除sql
语法: delete from 表名 where 条件;
注意:1、delete以后能不用就不用,一般业务上要删除数据用update给表中建立一个删除标记栏位,将此栏位进行逻辑删除。
2、如果非要用delete,要加明确的条件,不然会把整张表的数据全删掉了。
3、后边的where条件可以有多个,用操作符连接。
DELETE FROM goods WHERE id = 5;
UPDATE goods SET del_flag = 1 WHERE id = 4;
9、查询SQL
9.1 最简单的查询
语法1:select 栏位1,栏位2,....栏位n from 表名 where 条件;
从表当中找出符合where条件的数据然后再筛选出目标列数据。
语法2:select * from 表名 where 条件;
*代表所有栏位
注意:
1、查询的时候尽量减少栏位名,特别是表的栏位过多,能不用*就不用。
2、执行顺序, from ->where->select
SELECT NAME,price FROM goods WHERE NAME='耳机';
name price
------ ---------
耳机 2200.00
SELECT * FROM goods WHERE NAME = '耳机';
id name price quality inventory del_flag
------ ------ ------- ------- --------- ----------
4 耳机 2200.00 60 10 1
9.2 使用操作符查询
< > <= >= != <>
and or not
between and
is null is not null
like not like
注意:操作符是有优先级的,使用的时候搞不清优先级就使用()
id name price quality inventory del_flag
------ ------ --------- ------- --------- ----------
1 手机 2500.00 100 50 0
2 电脑 2200.00 100 30 0
3 手表 2200.00 50 20 0
4 耳机 2200.00 60 10 1
5 汽车 100000.00 10 (NULL) 0
6 鞋子 2300.00 70 25 0
7 衣服 2600.00 50 20 0
-- 找表中价格大于2200 并且 数量大于60 或者小于50 的数据
SELECT * FROM goods WHERE price > 2200
AND quality > 60 OR quality < 50;
-- 找表中价格大于2200 并且数量大于60 或者库存小于30的数据
SELECT * FROM goods WHERE price > 2200 AND (quality > 60
OR inventory < 30);
-- 找表中数量在50到70之间的数
SELECT * FROM goods WHERE quality >= 50 AND quality <= 70;
-- between and 他是一个闭区间
SELECT * FROM goods WHERE quality BETWEEN 50 AND 70;
id name price quality inventory del_flag
------ ------ ------- ------- --------- ----------
3 手表 2200.00 50 20 0
4 耳机 2200.00 60 10 1
6 鞋子 2300.00 70 25 0
7 衣服 2600.00 50 20 0
模糊查询like要结合通配符% 和_使用
注意:%是匹配任意个字符的意思,_匹配单个字符
-- 只要name中有手字的都能查到
SELECT * FROM goods WHERE NAME LIKE '%手%';
-- 查到name以手结尾的数据,%匹配任意个字符
SELECT * FROM goods WHERE NAME LIKE '%手';
-- 查到name以手开头的数据
SELECT * FROM goods WHERE NAME LIKE '手%';
-- 注意一个下滑线是匹配一个字符
SELECT * FROM goods WHERE NAME LIKE '__手';
SELECT * FROM goods WHERE NAME LIKE '_手_';
-- 如果通配符作为查询条件使用的时候要转义
SELECT * FROM goods WHERE NAME LIKE '%\_%';
9.3排序(order by)
语法:
1、 select 栏位1,栏位2,.....,栏位n from 表名 order by 栏位名
按照order by后边的对应栏位进行升序排列(默认升序)
2、升序排列
select 栏位1,栏位2,.....,栏位n from 表名 order by 栏位名1 asc
3、降序排列
select 栏位1,栏位2,.....,栏位n from 表名 order by 栏位名1 desc
4、多个栏位排序
select 栏位1,栏位2,.....,栏位n from 表名 order by 栏位名1 desc(或asc),栏位2 desc(或asc),...
注意:如果是升序asc可不加
字符串类型的字段或者栏位也可以作为排序条件,但是它有固定的排序规则,
排序之后的结果并不一定是我们想要的。
-- 查询学生表所有信息并按照成绩由低到高排序
SELECT * FROM student;
SELECT * FROM student ORDER BY score ASC;
-- 查询学生表所有信息并按照成绩由高到低排序
SELECT * FROM student ORDER BY score DESC;
-- 查询学生表当中男生的所有信息并按降序排列
SELECT * FROM student WHERE sex = '男'
ORDER BY score DESC;
-- 查询学生表中所有信息然后成绩降序排列、年龄升序排列
SELECT * FROM student ORDER BY
score DESC,age ASC;
-- 学生表按照姓名排序
SELECT * FROM student ORDER BY sname DESC;
9.4 分组函数(聚合函数)
count() 计数
sum() 求和
avg() 平均数
max() 最大值
min() 最小值
()里面是栏位名
1、count(1)、count(*)、count(栏位名)的区别
count(1)和count(*)统计的时候可以把null的记录统计在内,但是count(栏位名)不会
统计上null的栏位做为一条记录;
count(1)和count(星号),count(星)效率要高一些,效率高的前提是表当中有主键。
注意:分组函数之所以叫这个名字,因为其实它是在分组的基础上实现的,其实他也是默认将整张表的所有栏位自成一组。
-- 查询学生表当中的成绩最大值
SELECT MAX(score) FROM student;
-- 可以给查询结果字段起别名,表也可以起别名,用as关键字
SELECT MAX(score) AS max_score FROM student AS s;
-- 查询学生表中年龄最小值
SELECT MIN(age) FROM student;
-- 查询成绩平均值
SELECT AVG(score) FROM student;
-- 查询学生表中总成绩
SELECT SUM(score) FROM student;
-- 查询学生表中男生的总成绩
SELECT SUM(score) FROM student WHERE sex = '男';
-- 统计表中一共多少条数据
SELECT COUNT(sname) FROM student;
9.5 分组查询(group by having)
语法: select 分组函数(group by 后边的栏位名) from 表名 group by 栏位名 having 条件;
having 条件可不加!
意思是将表中的数据按照某个栏位进行分组;
多个栏位分组语法:
select 分组函数(group by 后边的栏位名) from 表名 group by 栏位名1,栏位 2.........;
注意:分组查询的结果集不要包含和分组无关的字段,没有意义。
-- 将学生表当中的学生按照性别进行分组,统计每个组的学生数
SELECT COUNT(id),sex FROM student GROUP BY sex;
-- 查询学生表当中男女组当中成绩大于90的记录数
SELECT COUNT(1),sex FROM student WHERE score > AVG(score)
GROUP BY sex ;
-- 执行顺序必须要记住
-- from -> where -> group by -> having -> select -> order by
-- 查询学生表当中男女组的总成绩只要男生的
-- having的用法和where类似,但是执行顺序是不一样的
SELECT SUM(score),sex FROM student
WHERE sex = '男' GROUP BY sex;
SELECT SUM(score),sex FROM student
GROUP BY sex HAVING sex='男';
-- 查询学生表当中每个部门的男女数
SELECT dep_id,sex,COUNT(sex) FROM student
GROUP BY dep_id,sex;
-- 查询学生表当中每个部门的男女数,总成绩,最大的年龄,平均成绩
SELECT dep_id,sex,COUNT(sex),SUM(score),MAX(age),AVG(score)
FROM student
GROUP BY dep_id,sex;
9.6 多表连接
9.6.1 多表连接的方式:
内连接(inner join, inner可以省略)--基础部分要掌握的
外连接(左外连接、右外连接)---高级部分讲
全连接(不用,不讲)
9.6.2 需要了解的一个概念笛卡尔积:
在数据库当中多张表进行连接的时候,如果不加限制条件,查询的结果集(记录数)是这几张表的乘积。
9.6.3 内连接:
语法1(建议以后就用这个,因为可读性强):
select 表1.栏位名,......,表1.栏位n,表2.栏位名,......,表2.栏位n from 表1 inner join
表2 on 条件;
-- "."是的意思,* 是所有栏位的意思
SELECT student.*,department.* FROM student
INNER JOIN department
ON student.dep_id = department.id;
id sname age sex score dep_id id dname
------ ------ ------ ------ ------ ------ ------ --------------
1 张一 20 男 93 1 1 破晓一部
2 张二 21 女 96 1 1 破晓一部
3 张三 22 男 85 1 1 破晓一部
4 张四 23 女 89 1 1 破晓一部
5 张五 19 男 67 1 1 破晓一部
6 李一 23 女 92 2 2 鸿鹄二部
7 李二 21 男 97 2 2 鸿鹄二部
8 李三 20 女 95 2 2 鸿鹄二部
9 李四 19 男 89 2 2 鸿鹄二部
10 李五 18 女 86 2 2 鸿鹄二部
11 王一 20 男 63 3 3 启程三部
12 王二 22 女 67 3 3 启程三部
13 王三 18 男 73 3 3 启程三部
14 王四 21 女 77 3 3 启程三部
15 王五 24 男 92 3 3 启程三部
给表起别名的方式
select 别名1.栏位名,......,别名1.栏位n,别名2.栏位名,......,别名2.栏位n from 表1 as 别名1
inner join 表2 as 别名2 on 条件;
SELECT a.*,b.* FROM student AS a
INNER JOIN department AS b
ON a.dep_id = b.id;
id sname age sex score dep_id id dname
------ ------ ------ ------ ------ ------ ------ --------------
1 张一 20 男 93 1 1 破晓一部
2 张二 21 女 96 1 1 破晓一部
3 张三 22 男 85 1 1 破晓一部
4 张四 23 女 89 1 1 破晓一部
5 张五 19 男 67 1 1 破晓一部
6 李一 23 女 92 2 2 鸿鹄二部
7 李二 21 男 97 2 2 鸿鹄二部
8 李三 20 女 95 2 2 鸿鹄二部
9 李四 19 男 89 2 2 鸿鹄二部
10 李五 18 女 86 2 2 鸿鹄二部
11 王一 20 男 63 3 3 启程三部
12 王二 22 女 67 3 3 启程三部
13 王三 18 男 73 3 3 启程三部
14 王四 21 女 77 3 3 启程三部
15 王五 24 男 92 3 3 启程三部
注意: on后边多个条件可以用and分开
语法2:
select 表1.栏位名,......,表1.栏位n,表2.栏位名,......,表2.栏位n from 表1,表2
where 条件;
SELECT student.*,department.dname FROM student,department
WHERE student.dep_id = department.id AND student.score > 80;
id sname age sex score dep_id dname
------ ------ ------ ------ ------ ------ --------------
1 张一 20 男 93 1 破晓一部
2 张二 21 女 96 1 破晓一部
3 张三 22 男 85 1 破晓一部
4 张四 23 女 89 1 破晓一部
6 李一 23 女 92 2 鸿鹄二部
7 李二 21 男 97 2 鸿鹄二部
8 李三 20 女 95 2 鸿鹄二部
9 李四 19 男 89 2 鸿鹄二部
10 李五 18 女 86 2 鸿鹄二部
15 王五 24 男 92 3 启程三部
给表起别名的方式
select 别名1.栏位名,......,别名1.栏位n,别名2.栏位名,......,别名2.栏位n from 表1 as 别名1,
表2 as 别名2 where条件;
注意:on后边多个条件可以用and分开
SELECT a.*,b.dname FROM student AS a,department AS b
WHERE a.dep_id = b.id AND score > 80;
id sname age sex score dep_id dname
------ ------ ------ ------ ------ ------ --------------
1 张一 20 男 93 1 破晓一部
2 张二 21 女 96 1 破晓一部
3 张三 22 男 85 1 破晓一部
4 张四 23 女 89 1 破晓一部
6 李一 23 女 92 2 鸿鹄二部
7 李二 21 男 97 2 鸿鹄二部
8 李三 20 女 95 2 鸿鹄二部
9 李四 19 男 89 2 鸿鹄二部
10 李五 18 女 86 2 鸿鹄二部
15 王五 24 男 92 3 启程三部
补充:
给栏位或者表起别名的时候AS可以省略,但是要用空格隔开
10、课后练习题
/*
1、创建库data_04
2、创建员工表employee
栏位
(id, ename,age,sex,level,salary,dep_id)
3、创建部门表department
栏位(id,dep_name)
员工表dep_id对应部门表的id
4、插入数据
5、查询员工表,并按照薪水由高到低和年龄由低到高进行排序
6、查询员工表中的最高薪水,最低薪水,总薪水,平均年龄
7、查询员工表中每个部门的最高薪水、部门名称
8、查询员工表中总薪水超过12000的部门,显示部门名称和总薪水
9、查询员工表中每个部门不同等级的员工的平均薪水
10、查询员工表中每个部门的男女员工数
11、查询每位员工的姓名、年龄、部门名称
12、查询每位员工的姓名、年龄、薪水、部门名称并按照薪水降序
*/
CREATE DATABASE data_04 CHARACTER SET utf8
COLLATE utf8_general_ci;
CREATE TABLE employee(
id INT(11) PRIMARY KEY,
ename VARCHAR(10),
age TINYINT(4),
sex CHAR(1),
`level` INT(11),
salary DECIMAL(10,2),
dep_id INT(11)
);
CREATE TABLE department(
id INT(11) PRIMARY KEY,
dep_name VARCHAR(10)
);
INSERT INTO department VALUES(1, '财务部');
INSERT INTO department VALUES(2, '人事部');
INSERT INTO department VALUES(3, '开发部');
INSERT INTO employee VALUES(1,'张一',20,'男',1,5000,1);
INSERT INTO employee VALUES(2,'张二',21,'女',2,4500,1);
INSERT INTO employee VALUES(3,'李一',23,'男',1,5500,2);
INSERT INTO employee VALUES(4,'李二',31,'女',2,5600,2);
INSERT INTO employee VALUES(5,'李三',24,'男',2,5700,2);
INSERT INTO employee VALUES(6,'王一',26,'女',1,10000,3);
INSERT INTO employee VALUES(7,'王二',25,'男',2,8000,3);
INSERT INTO employee VALUES(8,'王三',24,'女',2,7500,3);
-- 查询员工表,并按照薪水由高到低和年龄由低到高进行排序
-- 多个字段排序 按照从左到右的优先级进行排
SELECT * FROM employee ORDER BY salary DESC, age ASC;
SELECT * FROM employee ORDER BY age DESC, salary ASC;
-- 查询员工表中的最高薪水,最低薪水,总薪水,平均年龄
SELECT MAX(salary) AS 'maxSalary',MIN(salary),SUM(salary),AVG(age)
FROM employee;
-- 查询员工表当中所有员工信息,每位员工的薪水减1000
SELECT ename,age,salary-1000 AS a FROM employee;
-- 查询员工表中每个部门的最高薪水
SELECT MAX(salary) FROM employee GROUP BY dep_id;
-- 查询员工的姓名、薪水、部门名称
SELECT a.*,b.* FROM employee AS a INNER JOIN department b
ON a.dep_id = b.id;
SELECT a.ename,a.age,a.salary,b.dep_name
FROM employee AS a INNER JOIN department b
ON a.dep_id = b.id;
-- 查询员工表中每个部门的最高薪水、部门名称
-- 这条sql的执行顺序是:
-- 先from将两个表做笛卡尔积,on条件筛选,然后分组,最后select
SELECT MAX(salary) AS maxSalary,b.dep_name
FROM employee AS a INNER JOIN department b
ON a.dep_id = b.id GROUP BY b.dep_name;
-- 先from将两个表做笛卡尔积,on条件筛选,然后分组,然后select,最后order by
SELECT MAX(salary),b.dep_name
FROM employee AS a INNER JOIN department b
ON a.dep_id = b.id GROUP BY b.dep_name ORDER BY MAX(salary);
第三章 JDBC基础
1、jdbc概念
Java Database Connection,java连接数据库的意思。
jdbc其实就是sun公司制定的一套连接数据库的标准,它的本质是一套别人开发好的类库,我们可以通过这些类库,并按照它们的标准去连接到数据库进行增删改查。
2、Eclispe当中使用JDBC的准备工作
第一步、创建java项目
第二步:在项目根路径下创建一个lib文件夹,将mysql-connector-java-5.1.9.jar复制到此文件夹


第三步:选中此jar包右键找到BuildPath,然后点击add to build path
此步骤的作用主要是将别人开发好的jdbc类库添加为自己的项目依赖,然后自己的项目就可以用此jar包中别人开发好的类了

第四步:在src下边创建package,手写JDBC实现代码
3、jdbc连接数据库的步骤
第一步:装载驱动
Class.forName("com.mysql.jdbc.Driver");
注意:
1:其中com.mysql.jdbc.Driver需要注意不能写错,否则会报错ClassNotFoundException
2:针对Mysql 不同版本的数据库,名字不一样
5点几的版本用com.mysql.jdbc.Driver
8点几的版本用com.mysql.cj.jdbc.Driver
第二步:获得连接
Connection con = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/data_04?characterEncoding=utf-8","root","123456");
注意:
1:其中DriverManager是驱动管理类,就是我们导入的jar包当中提供类库,此类的getConnection可以建立数据库的连接。
2:jdbc:mysql://127.0.0.1:3306/data_04?characterEncoding=utf-8 是连接数据库的url,它主要分为以下几个部分:
(1)jdbc:mysql 代表协议,类似于浏览器请求当中的http、https,那什么是协议呢?
协议就是双方约定好数据以什么样的形式进行传输
(2)127.0.0.1代表数据库系统所在服务器的地址,关于IP?IP就是每一台服务器(电脑)的唯一标识
(3)3306 代表数据库系统这个程序占用的端口号(一般数据库的端口默认都是3306,当然也可以修改),每一个进程 占用一个端口,端口在每一个服务器上也是惟一的
(4)data_04 代表数据库,就是我所连接的服务器所在的数据库系统中的数据库名称
(5)?,是分隔符,问号后边的 characterEncoding=utf-8是url当中的参数设置,多个参数设置可以用&拼接,比如
jdbc:mysql://127.0.0.1:3306/data_04?characterEncoding=utf-8&useSSL=true
第三步:操作数据(准备sql、创建Statement、执行sql、获得结果)
插入数据:
String sql = "insert into department values (7,'项目二部'),(8,'项目三部')";
Statement stat = con.createStatement();
int ret = stat.executeUpdate(sql);
其中sql当中操作的表名是要在所连接的数据库当中存在的表,否则报错!
SQL语句要通过建立的连接创建的Statement才能发送(执行)。
修改数据:
String sql = "update department set name = '111' where id = 2";
Statement stat = con.createStatement();
int ret = stat.executeUpdate(sql);
删除数据:
String sql = "delete from department where id = 3";
Statement stat = con.createStatement();
int ret = stat.executeUpdate(sql);
查询数据:
String sql = "select ename,age,sex,salary from employee";
Statement stat = con.createStatement();
//执行查询,返回结果,executeQuery只能执行DQL语句
ResultSet ret = stat.executeQuery(sql);
while(ret.next()) {
System.out.print(ret.getString("ename"));
System.out.print(ret.getInt("age"));
System.out.print(ret.getString("sex"));
System.out.println(ret.getDouble("salary"));
}
第四步:释放资源
释放资源的作用:提高系统的可用度,提高系统的性能。一个数据库系统的资源或者连接是有限的,如果一段程序出错了或者长时间占用着资源会影响到其他的程序访问数据库。
当然长时间不主动释放资源,java和数据库系统有一些机制也会自动释放,但是自动释放是需要等待的,这会导致系统的性能大打折扣。
以下是一个完整的JDBC连接数据库并插入数据的例子:
package com.shuangti.jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class JdbcTest01 {
public static void main(String[] args) {
//JDBC操作步骤
//1、装载驱动
//2、获得连接
//3、操作数据(准备sql、编译执行sql、获得结果)
//4、释放资源
Statement stat = null;
Connection con = null;
try {
//第一步:装载驱动,mysql的驱动,名字一定要准确,不对就报异常
Class.forName("com.mysql.jdbc.Driver");
//第二步:获得连接
//DriverManager驱动管理
//https://www.baidu.com/
/*获得数据库连接需要三个部分:url,数据库登录账号,密码
* DriverManager.getConnection("url","账号","密码");
第一部分:url需要一下几个部分组成
jdbc:mysql://127.0.0.1:3306/data_04
1、协议jdbc:mysql类似于浏览器请求协议https
2、ip:是服务器唯一标识
localhost 127.0.0.1 本地ip
3、端口 3306 每个进程独占一个
4、数据库名data_04
第二部分:账号root
第三部分:密码123456
*
* */
//getConnection静态方法,获得连接
con = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/data_04?characterEncoding=utf-8","root","123456");
//第三步:操作数据
//准备sql
//sql中对应的表要是url当中的数据库名中存在的表
String sql = "insert into department values (7,'项目二部'),(8,'项目三部')";
stat = con.createStatement();
//update是更新的意思,可以执行DML语句(update、delete、insert)
//stat.executeUpdate返回一个int类型的结果,此结果是执行成功的记录数
int ret = stat.executeUpdate(sql);
if(ret > 0) {
System.out.println("插入成功:" + ret);
}else {
System.out.println("失败!");
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} finally {
//第四步:释放资源,倒序释放(stat->con)
if(stat != null) {
try {
stat.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(con != null) {
try {
con.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
}
以下是一个完整的JDBC连接数据库并查询数据的例子:
package com.shuangti.jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
/*
* 1、装载驱动
* 2、获得连接
* 3、操作数据
* 4、释放资源
*
* */
public class JdbcSelect01 {
public static void main(String[] args) {
try {
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://127.0.0.1:3306/data_04?characterEncoding=utf-8";
String uName = "root";
String pwd = "123456";
Connection con = DriverManager.getConnection(url,uName,pwd);
//准备sql、创建statement、获得结果
String sql = "select ename,age,sex,salary from employee";
Statement stat = con.createStatement();
//执行查询,返回结果,executeQuery只能执行DQL语句
ResultSet ret = stat.executeQuery(sql);
while(ret.next()) {
System.out.print(ret.getString("ename"));
// System.out.print(ret.getString("age"));
// System.out.print(ret.getInt(2));
System.out.print(ret.getInt("age"));
System.out.print(ret.getString("sex"));
// System.out.println(ret.getString("salary"));
System.out.println(ret.getDouble("salary"));
// System.out.println(ret.getString("id"));
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}finally {
//释放资源,ret->stat->con
//ret.close()
//stat.close()
//con.close();
}
}
}
关于上边查询的案例当中的ResultSet
ResultSet是一个结果集,因为查询select的结果是一张包含很多数据的表,所以有了它的出现。
ResultSet ret = stat.executeQuery(sql);
假设ret查询到的是以下结果集:
ret.next()第一次执行指向第一条数据,如果有数据就是true没有就是false,
后续每执行一次判断一次ret.next()是否为真,为真就跳到下一条数据。
ename age sex salary
------ ------ ------ ---------
张一 20 女 5000.00
张二 21 女 4500.11
李一 23 男 5500.00
4、关于Statement和PreparedStatement(也是java面试必背考点)
平时开发当中需要掌握的是PreparedStatement的用法,但是Statement也要了解。
4.1 jdbc中使用Statement执行增删改的例子:
//sql中对应的表要是url当中的数据库名中存在的表
String sql = "insert into department values (7,'项目二部'),(8,'项目三部')";
stat = con.createStatement();
//update是更新的意思,可以执行DML语句(update、delete、insert)
//stat.executeUpdate返回一个int类型的结果,此结果是执行成功的记录数
int ret = stat.executeUpdate(sql);
jdbc中使用Statement执行查询的例子:
String sql = "select ename,age,sex,salary from employee";
Statement stat = con.createStatement();
//执行查询,返回结果,executeQuery只能执行DQL语句
ResultSet ret = stat.executeQuery(sql);
while(ret.next()) {
System.out.print(ret.getString("ename"));
System.out.print(ret.getInt("age"));
System.out.print(ret.getString("sex"));
System.out.println(ret.getDouble("salary"));
}
4.2 jdbc中使用PreparedStatement执行增删改
String sql = "insert into user(uname,pwd) values(?,?)";
//?叫做占位符
PreparedStatement pre = con.prepareStatement(sql);
//1代表第一个问号,用name的值替换掉第一个问号
pre.setString(1, name);
//用pwd的值替换掉第二个问号
pre.setInt(2, pwd);
//executeUpdate()括号内不能加sql,因为他是预编译
//executeUpdate可执行insert update delete语句
pre.executeUpdate();
jdbc中使用PreparedStatement执行增删改
String sql = "select * from user where uname = ? and pwd = ?";
PreparedStatement pre = con.prepareStatement(sql);
pre.setString(1, name);
pre.setInt(2, pwd);
ResultSet ret = pre.executeQuery();
while(ret.next()) {
Sysetem.out.print(ret.getString("uname"));
Sysetem.out.print(ret.getString("pwd"));
}
关于Statement和PreparedStatement的区别:
Statement会存在Sql注入的问题,因为通过Statement执行的sql是拼接的,
而PreparedStatement是通过占位符替换的方式,所以不存在篡改sql的问题。
public static boolean login(String name, int pwd) {
Connection con = JdbcUtils.getCon();
String sql = "select * from user where uname = '" + name + " + "' and pwd =" + pwd;
try {
Statement pre = con.createStatement();
ResultSet ret = pre.executeUpdate(sql);
while(ret.next()) {
return true;
}
System.out.println("=========");
} catch (SQLException e) {
e.printStackTrace();
}
return false;
}
public static boolean login(String name, int pwd) {
Connection con = JdbcUtils.getCon();
String sql = "select * from user where uname = ? and pwd = ?";
try {
PreparedStatement pre = con.prepareStatement(sql);
pre.setString(1, name);
pre.setInt(2, pwd);
ResultSet ret = pre.executeQuery();
while(ret.next()) {
return true;
}
System.out.println("=========");
} catch (SQLException e) {
e.printStackTrace();
}
return false;
}
如果采用第一种方式,用户传入的name= 张三 pwd=123456 or pwd=123;
sql就变成了 select * from user where uname = '张三' and pwd = 123456 or pwd = 123;
这样的话就篡改了此业务原有的登录逻辑了,查出的结果也显然不是我们开发的程序所预想的结果,也就是存在所谓的安全漏洞(sql注入)。
如果采用第二种方式,用户传入的name= 张三 pwd=123456 or pwd=123;
sql就变成了 select * from user where uname = '张三' and pwd = '123456 or pwd = 123';
123456 or pwd = 12会作为一个字符串值作为sql当中的pwd的条件,也就不存在所谓的安全漏洞了。
5、将JDBC的四个步骤封装到一个工具类当中
注意静态代码块的用意,因为jdbc的第一步装载驱动只需执行一次,所以把它放在此处。
在java当中静态代码块什么时候执行呢?
JVM当中存在一个元数据区或者叫方法区,当一个类当中使用到JdbcUtils这个类时,程序执行时JdbcUtils.class信息就会加载到方法区,
类一加载,静态代码块就会执行,而且只执行一次!!
import java.sql.*;
/*
* JDBC工具类
* */
public class JdbcUtils {
//静态代码块,类加载的时候只执行一次,以后再也不执行了
static {
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
/*
* 获得连接
* */
public static Connection getCon() {
String url = "jdbc:mysql://127.0.0.1:3306/data_04?characterEncoding=utf-8";
String uName = "root";
String pwd = "123456";
Connection con = null;
try {
con = DriverManager.getConnection(url,uName,pwd);
} catch (SQLException e) {
e.printStackTrace();
}
return con;
}
/*
* 释放资源
* ResultSet
* Statement或PrepareStatement
* Connection
* 释放资源有顺序 ResultSet->Statment或PrepareStatement->Connection
* */
public static void close(Connection con,
Statement stat, PreparedStatement pre,ResultSet ret) {
if(ret != null) {
try {
ret.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(stat != null) {
try {
stat.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(pre != null) {
try {
pre.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(con != null) {
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
以下代码使用JdbcUtils实现了一个注册登录的功能
import java.sql.*;
import java.util.Scanner;
public class BlogSys {
public static void main(String[] args) {
System.out.println("请注册一个用户");
Scanner scanner = new Scanner(System.in);
System.out.println("请输入用户名:");
String name = scanner.next();
System.out.println("请输入用密码:");
int pwd = scanner.nextInt();
//使用jdbc往user表中插入数据
//调用注册方法
register(name,pwd);
System.out.println("请登录");
System.out.println("请输入用户名:");
String name1 = scanner.next();
System.out.println("请输入用密码:");
int pwd1 = scanner.nextInt();
//调用登录方法
boolean flag = login(name1,pwd1);
if(flag) {
System.out.println("登录成功!");
}else {
System.out.println("登录失败!");
}
}
//用户注册
public static void register(String name, int pwd) {
Connection con = JdbcUtils.getCon();
//?可以叫做占位符
String sql = "insert into user(uname,pwd) values(?,?)";
try {
PreparedStatement pre = con.prepareStatement(sql);
pre.setString(1, name);
pre.setInt(2, pwd);
//executeUpdate()括号内不能加sql,因为他是预编译
pre.executeUpdate();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
//用户登录
public static boolean login(String name, int pwd) {
Connection con = JdbcUtils.getCon();
String sql = "select * from user where uname = ? and pwd = ?";
try {
PreparedStatement pre = con.prepareStatement(sql);
pre.setString(1, name);
pre.setInt(2, pwd);
ResultSet ret = pre.executeQuery();
while(ret.next()) {
return true;
}
System.out.println("=========");
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return false;
}
}
JavaEE
1、Http/Https
http://10.10.43.126:8080/oa/index.html
一个完整的Url请求包含:协议 域名 端口 uri
(1)协议:http、https
就是某个组织规定的一套标准,主要是发起请求或接收响应规定好数据的格式,
比如请求方式是Get还是Post,比如数据放在头部还体中。
http是超文本传输协议
什么是超文本?
就是指的一些音乐、图片、视频等等。
http协议包含请求协议和响应协议:
请求协议(request):
请求行:
请求方式(Get、Post)、uri、请求协议版本
关于Url和Uri
http://10.10.43.126:8080/oa/index.html这个是Url,它叫统一资源定位符
Url可以定位到某个资源的路径
/oa/index.html他叫Uri统一资源标识符,Uri无法定位资源。
头:
请求内容类型等
空白行:主要是分隔头和体
体:
可以放post提交的表单内容(常用)
响应协议(response):
状态行:
响应码、响应状态信息、http版本
响应码:
200:成功
404:地址有问题,找不到资源
500:服务端有问题,一般情况去查看一下服务端的源代码逻辑有误。
响应状态信息:响应码的描述信息
头:
响应的内容长度
响应的数据类型
空白行:
体:
一般是响应的数据
(2)http请求最终响应的都是数据,比如http://10.10.43.126:8080/oa/index.html
它响应不是一个html文件,而是服务端将html数据响应给浏览器,浏览器根据
响应协议(响应数据类型)做不同渲染。
2、Tomcat
web服务器和应用服务器
web服务器,具有接受客户端请求并做出响应的能力的一个服务器,它主要是能响应html
页面。
应用服务器:tomcat、Jetty
比如tomcat其实它是一个专用服务器,他是用来专门做javaWeb开发的,类似于之前学习的
JDBC,它的核心是servlet,可以用来响应或转发请求。
什么是Servlet?
Servlet是一种用Java语言编写的Web组件,运行于Web服务器端。它扩展了Web服务器的功能,它由Servlet容器管理,能够产生动态网页输出。已逐步取代了CGI。Servlet可以被编译成Java类,由Web服务器动态装入并运行,在运行期间对客户的请求产生响应。
servlet:它的本质是java程序,是一个接口,接口现在就把他认为是别人规定好的一套规范,只要是用来接收响应请求的java程序都要实现此接口。
servlet处理请求的具体流程:
http://127.0.0.1:8080/javaEE-01/new
客户端发起请求,到了tomcat,tomcat会根据应用上下文(javaEE-01)找到对应的项目路径,再跟应用上下文后边的资源路径,/new中的new是一个servlet,然后每一个servlet都会有两个对象,一个是request,一个是response,request可以接收客户端传过来的数据,response可以给客户端响应对应协议的数据。
当然servlet本质是java程序,它的内部可以处理一些服务端的逻辑,比如通过JDBC连接数据库,查询数据给出响应。
JavaWeb项目结构
- src/main/java下边是放项目java源程序的文件夹
- jre system library是放的jdk源程序
- reference library 是放的第三方jar包
- server runtime library是tomcat源程序jar包
- webapp下放的是静态网页相关的一些文件,比如js、css、图片、html、jsp
项目配置相关的文件,比如web.xm,springContext.properties
servlet的创建是有生命周期(从请求发起到结束):
1、创建:
就是创建servlet对象
创建对象需要new,然后调用构造方法
每一个请求,只创建一次,后续请求不再创建
为什么只创建一次?
如果每一次请求创建一个对象需要消耗大量的内存,严重影响服务器的性能。
2、初始化:(init)
每一个请求,只执行一次初始化,后续请求不再调用
3、请求处理(service)
每一个请求,执行一次
4、销毁(destroy)
tomcat停止服务,对象被销毁,而且也是只执行一次
总结:
(1)什么是请求?
浏览器地址栏输入url,回车
点击网页的一个连接
form表单提交
(2)有了servlet,浏览器发起请求,后端可以接收请求(request)数据,并做出响应(response)。
servlet如何使用
两种方式
(1)第一种:
实现servlet接口,并在web.xml中配置servlet
package com.shuangti.web;
import java.io.IOException;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
/*
* 1、implements是关键字,用来实现接口
* 2、Servlet是tomcat的核心接口,实现了此核心接口的类就能处理请求响应了。
* 接口就是开发者定义好的一套标准,实现此接口的类就被认为
* 给它打了一个标签,后续java运行的时候会按照一套固定的模式去运行它。
* 比如:某一个接口定义了飞行这个方法,
* 后边有一个鸟儿实现了这个接口,那么java运行的时候就会认为鸟儿
* 具有飞行的能力。
* 3、FirstServlet实现了Servlet接口后必须要将Servlet当中所有的
* 方法进行重写(实现)。
*
* */
public class FirstServlet implements Servlet{
public FirstServlet() {
System.out.println("servlet对象被创建");
}
@Override
public void init(ServletConfig config) throws ServletException {
// TODO Auto-generated method stub
System.out.println("servlet初始化");
}
@Override
public ServletConfig getServletConfig() {
// TODO Auto-generated method stub
return null;
}
@Override
public void service(ServletRequest req, ServletResponse res) throws ServletException, IOException {
// TODO Auto-generated method stub
String name = req.getParameter("name");
System.out.println("name====" + name);
System.out.println("servlet处理请求");
}
@Override
public String getServletInfo() {
// TODO Auto-generated method stub
return null;
}
@Override
public void destroy() {
// TODO Auto-generated method stub
System.out.println("servlet对象被销毁");
}
}
web.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd"
id="WebApp_ID" version="3.1">
<display-name>javaEE-02</display-name>
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file>
<welcome-file>index.jsp</welcome-file>
<welcome-file>default.html</welcome-file>
<welcome-file>default.htm</welcome-file>
<welcome-file>default.jsp</welcome-file>
</welcome-file-list>
<!-- 这里是xml的注释 -->
<!--1、servlet此标签配置的是servlet的全限定类名
servlet-name:是servlet的别名
servlet-class:com.shuangti.web.FirstServlet(全限定类名)
-->
<servlet>
<!--别名,一般情况用对应类名 -->
<servlet-name>FirstServlet</servlet-name>
<!-- 全限定类名(包名+类名) -->
<servlet-class>com.shuangti.web.FirstServlet</servlet-class>
</servlet>
<!--2、配置请求映射
客户端请求中uri中对应的资源路径地址
-->
<servlet-mapping>
<!--对应上边配置的servlet的别名,两个一定要严格一致 -->
<servlet-name>FirstServlet</servlet-name>
<!-- uri当中的项目路径后边的地址
url路径要以/开头
-->
<url-pattern>/first</url-pattern>
</servlet-mapping>
</web-app>
第二种方式(后续使用最多的方式):
继承HttpServlet类,并重写doGet、doPost方法
在类的上边添加@WebServlet注解
package com.shuangti.web;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* 1、HttpServlet是间接实现了Servlet接口
* 2、Servlet接口的一些抽象方法,是在父类当中已经实现了
* 3、FirstServlet自己创建的这个类,只需要重写一下父类
* 当中doGet、doPost方法就可以用来处理请求了。
* 什么是请求?
* 浏览器输入地址回车就是发起一个请求
* 网页上的链接点击就是发起请求
* form表单,点击提交按钮,执行action就是发起请求
* doGet、doPost是可以来处理不同请求方式的的方法
* 4、doGet、doPost方法当中都有两个形参,一个是request,一个是
* response
* request可以用来接收客户端发起的请求数据
* response可以用来响应数据给客户端
* 5、@WebServlet("/FirstServlet")
* 相当于在web.xml里面配置以servlet映射
* /FirstServlet相当于url短地址
*/
//第一种最常用
@WebServlet("/first")
//@WebServlet(name="TestServlet", urlPatterns={"/test1", "/test2"})
public class FirstServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String name = request.getParameter("uname");
System.out.println("get请求过来了");
System.out.println("name====" + name);
/*
* 假设用户为张三响应成功否则失败
*
* */
/*
* 通过response获取一个流对象通过流对象发送给客户端
* */
PrintWriter pt = response.getWriter();
if(name != null && name.equals("张三")) {
//响应给客户端数据:成功
pt.write("success");
}else {
//响应失败
pt.write("failed");
}
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
}
url请求传递数据请求格式
(1)Get请求方式
http://127.0.0.1:8080/javaEE-03/first?key1=value1&key2=value2&key3=value3.......
http://127.0.0.1:8080/javaEE-03/first对应Url
?后边对应请求传递参数,key代表参数名,value代表参数值,多个参数用&分隔开
(2)Post请求
http://127.0.0.1:8080/javaEE-03/first地址栏是不会有参数的。
我们最常用的form表单post提交的方式,数据会统一放在form data当中
Get和Post请求的区别
1、Get请求地址栏能看到参数,post不会
2、Get、Post都是Http协议的一部分,本质都是TCP/IP协议
3、Get请求Url不同浏览器的的长度都是限制的,Post不会
4、Get请求不能传递超文本数据,Post可以
5、Get发送数据经过一次请求,Post其实底层是经历了两次。
servlet相关的两个类
HttpServletRequest和HttpServletResponse
(1)request中的方法:
- getParameter方法只能获取单个不重复的参数值
- getParameterValues方法可以获取请求中参数名相同值不同的数据
- getsetAttribute 往request对象中存值
- getAttribute 通过request对象中取值
-getRequestDispatcher().forward 请求转发
(2)response中的fangf
-sendRedirect() 重定向
package com.shuangti.web;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
*
*/
@WebServlet("/second")
public class SecondServvlet extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
/*
* request.getParameter只能获取单个不重复的参数 String hobby =
* request.getParameter("hobby"); System.out.println(hobby);
* String hobby1 =request.getParameter("hobby");
* System.out.println(hobby1);
* 请求当中多个参数名相同,值不同时如何获取?
* 通过request.getParameterValues方法获取,返回一个String数组
*/
String[] hobbys = request.getParameterValues("hobby");
for(int i = 0; i < hobbys.length; i++) {
System.out.println("爱好" + i + ":" + hobbys[i]);
}
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
}
servlet的转发和重定向
(请求)转发

(响应)重定向

package com.shuangti.web;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* 转发和重定向的区别
* 1、(请求)转发:浏览器其实是发起了一次请求,
* 后端servlet会将浏览器请求响应转到另一个servlet,对于浏览器来说
* 是无感知的,就是一次请求
* 2、(响应)重定向:浏览器发起请求到servlet,servlet给出响应response
* 通过response告诉浏览器,让浏览器重新发起了另一个请求到
* 要重定向的servlet,其实相当于前后两次请求
* 3、转发可以将请求数据完整的转到另一个servlet
* 重定向因为请求发起两次的原因,第二次重定向的请求并没有把
* 第一次请求的request对象传递给第二个servlet会导致数据丢失
* 4、request中可以使用setAttribute和getAttribute进行存值取值
* 后续JSP中使用较多。
*/
@WebServlet("/LisiServlet")
public class LisiServlet extends HttpServlet {
//张三找李四借1000元
//借1000元这是一个请求request
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// System.out.println("我没钱,那我去找老王借");
//转发forward
//李四再去找老王借1000元
//把借1000元的请求给到老王
request.setAttribute("say", "几天就还你");
String money = request.getParameter("money");
System.out.println("借钱:" + money);
request.getRequestDispatcher("LaoWangServlet").forward(request, response);
//重定向sendRedirect
// System.out.println("李四没钱,告诉张三找老王去借");
// response.sendRedirect("LaoWangServlet");
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
}
package com.shuangti.web;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* Servlet implementation class LaoWangServlet
*/
@WebServlet("/LaoWangServlet")
public class LaoWangServlet extends HttpServlet {
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String say = (String)request.getAttribute("say");
System.out.println("say===" + say);
String money = request.getParameter("money");
System.out.println("money=====" + money);
System.out.println("老王有钱,借给你");
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
}
3、servlet的域对象
所谓的域对象就是,在tomcat启动项目时、浏览器打开关闭期间发送请求时、每发起一次请求时,服务端会生成相应的
一些对象,这些对象可以被共享,不同的对象有不同的使用范围,也就是所谓的域对象当中域代表作用域的意思。
三种域对象:
1、应用域对象:servletContext
a、 每一个web应用(在tomcat上发布的每一个项目)所有用户会共享这个对象,那么对象当中
的数据也是共享的
b、可以使用域对象的属性attribute以及对应的set、get方法setAttribute·和getAttribute在
应用域对象中进行存值取值
以下示例:
打开浏览器发起app请求,然后往应用域对象中存值,然后打开各种浏览器尝试发起First请求,会发现,不同浏览器发起的
请求都能获取到应用域对象中的值。
package com.shuangti.web;
import java.io.IOException;
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* Servlet implementation class AppServlet
*/
@WebServlet("/app")
public class AppServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//this.getServletContext()获取当前应用域对象
ServletContext context = this.getServletContext();
//在域对象当中存了一个值,这个值在当前应用所有用户共享
/*
* ServletContext应用域对象
* 某一个web应用所有用户会共享这个对象,那么对象当中
* 的数据也是所有用户共享的。
* 生命周期?
* 应用启动创建,应用停止对象销毁
* 方法:setAttribute("key","value");
* 往应用域对象中存值
* getAttribute("key")
* 在应用域对象中取值
*
* */
context.setAttribute("allUserData", "11111");
//打印当前请求上下文路径(当前项目的上下文路径)
//打印的结果是/javaEE-04
System.out.println(context.getContextPath());
}
}
@WebServlet("/First")
public class First extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
ServletContext context = this.getServletContext();
String allData = (String)context.getAttribute("allUserData");
System.out.println("all====" + allData);
}
}
2、会话域对象:session
/**
* 会话域对象Session
* 什么是会话?
* 简单的理解为每一个浏览器打开关闭的一个过程就是一个会话。
*
* session的机制:
* 浏览打开发起第一次请求,到了servlet层,他会先
* 检查当前sessionid是否存在,如果不存在就会创建一个对应
* session对象,生成一个唯一的id
* 当前浏览器未关闭,重新发起另一个请求的时候,会将浏览器端
* cookie当中存放的上次生成的sessionid带过来,这个时候
* servlet发现sessionid已存在就不会重新创建session对象了。
* 然后会根据当前sessionid找到对应session对象,实现会话数据共享。
*
* 说明:
* 一个会话的前提肯定是同一个浏览器;
* 会话可以清除,比如手动清除cookie中的数据
* 关闭浏览器会话结束。
*
*
*/
以下示例:
可以模拟几种场景:
1、打开Chrome浏览器,发起A请求,在session中存值,然后发起B请求,会看到session中的值能被取到
然后打开其他浏览器(注意这时不能关闭Chrome浏览器),发起B请求,这时无法取到session中存的sname值
2、关闭浏览器Chrome,重新打开Chrome,直接发起B请求,无法获取sname值。
@WebServlet("/A")
public class SessionA extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//request.getSession获取当前请求的会话域对象
//每一个会话都会共享返回的这个会话对象request.getSession()
HttpSession session = request.getSession();
session.setAttribute("sname", "2222");
//设置会话10秒钟过期
//session.setMaxInactiveInterval(10);
System.out.println("sessionId===" + session.getId() );
}
}
@WebServlet("/B")
public class SessionB extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//获取当前会话对象
HttpSession session = request.getSession();
//在当前会话域对象中取值
String sname = (String)session.getAttribute("sname");
System.out.println("sname===" + sname);
System.out.println("B======sessionId===" + session.getId() );
}
}
3、请求域对象:request
/**
* 请求域对象request:
* 它是每发起一个请求就会创建一个请求域对象,当前请求的请求域对象
* 中的数据是共享的,不同请求(servlet)之间不能共享request当中的
* 数据。
*
*/
@WebServlet("/Req1")
public class Req1 extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//往请求域对象当中存一个值
request.setAttribute("req", "33333");
}
}
@WebServlet("/Req2.do")
public class Req2 extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String req = (String) request.getAttribute("req");
System.out.println("req===" + req);
}
}
4、过滤器Filter
过滤器是在浏览器发起请求到达servlet层前加了一层过滤的作用,类似于现实生活当中的漏勺,可以通过
@WebFilter注解配置哪些Url是需要经过过滤器的
过滤器的实现方式:
@WebFilter("需要过滤的url")
public class 过滤器 implements Filter{
}
参考以下示例:
import java.io.IOException;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.annotation.WebFilter;
//@WebFilter是过滤器的注解,/*是代表过滤所有的请求
// *.do可以过滤地址以do结尾的所有请求
@WebFilter("*.do")
public class WFilter implements Filter{
@Override
public void init(FilterConfig filterConfig) throws ServletException {
// TODO Auto-generated method stub
}
/*
* doFilter是过滤器的核心方法
* 所有的过滤功能的实现都写在这里面
* */
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
System.out.println("只要是请求都得先过我这里.......");
//放过当前请求,让它继续到servlet层
chain.doFilter(request, response);
}
@Override
public void destroy() {
// TODO Auto-generated method stub
}
}
5、jsp--java server page
jsp是java服务端页面的意思,它的本质是java,并且是一个servlet。
jsp被tomcat生成的java放在tomcat目录下的子目录work当中,以我的tomcat路径为例:
D:\Program Files\apache-tomcat-8.5.72\work\Catalina\localhost\javaEE-05\org\apache\jsp
以下示图为例:
浏览器发起请求http://127.0.0.1:8080/javaEE-05/hello.jsp,到达tomcat服务,tomcat根据请求路径
生成对应jsp文件的java类(本质是一个servlet),然后将jsp文件中的html内容通过,out.write写入到响应
流当中,然后再通过tomcat响应给客户端

我们可以观察以下一个jsp请求后tomcat生成的对应java类如下:
发现second_jsp是由index.jsp生成的对应servlet java类index_jsp.java
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<form action="https://www.baidu.com/" method="get">
用户名:<input type="text" name="uname" placeholder="输入手机号"/><br>
密码:<input type="password" /><br>
邮箱:<input type="email" /><br>
</form>
</body>
</html>
/*
* Generated by the Jasper component of Apache Tomcat
* Version: Apache Tomcat/8.5.72
* Generated at: 2022-04-22 02:59:19 UTC
* Note: The last modified time of this file was set to
* the last modified time of the source file after
* generation to assist with modification tracking.
*/
package org.apache.jsp;
import javax.servlet.*;
import javax.servlet.http.*;
import javax.servlet.jsp.*;
public final class index_jsp extends org.apache.jasper.runtime.HttpJspBase
implements org.apache.jasper.runtime.JspSourceDependent,
org.apache.jasper.runtime.JspSourceImports {
private static final javax.servlet.jsp.JspFactory _jspxFactory =
javax.servlet.jsp.JspFactory.getDefaultFactory();
private static java.util.Map<java.lang.String,java.lang.Long> _jspx_dependants;
private static final java.util.Set<java.lang.String> _jspx_imports_packages;
private static final java.util.Set<java.lang.String> _jspx_imports_classes;
static {
_jspx_imports_packages = new java.util.HashSet<>();
_jspx_imports_packages.add("javax.servlet");
_jspx_imports_packages.add("javax.servlet.http");
_jspx_imports_packages.add("javax.servlet.jsp");
_jspx_imports_classes = null;
}
private volatile javax.el.ExpressionFactory _el_expressionfactory;
private volatile org.apache.tomcat.InstanceManager _jsp_instancemanager;
public java.util.Map<java.lang.String,java.lang.Long> getDependants() {
return _jspx_dependants;
}
public java.util.Set<java.lang.String> getPackageImports() {
return _jspx_imports_packages;
}
public java.util.Set<java.lang.String> getClassImports() {
return _jspx_imports_classes;
}
public javax.el.ExpressionFactory _jsp_getExpressionFactory() {
if (_el_expressionfactory == null) {
synchronized (this) {
if (_el_expressionfactory == null) {
_el_expressionfactory = _jspxFactory.getJspApplicationContext(getServletConfig().getServletContext()).getExpressionFactory();
}
}
}
return _el_expressionfactory;
}
public org.apache.tomcat.InstanceManager _jsp_getInstanceManager() {
if (_jsp_instancemanager == null) {
synchronized (this) {
if (_jsp_instancemanager == null) {
_jsp_instancemanager = org.apache.jasper.runtime.InstanceManagerFactory.getInstanceManager(getServletConfig());
}
}
}
return _jsp_instancemanager;
}
public void _jspInit() {
}
public void _jspDestroy() {
}
public void _jspService(final javax.servlet.http.HttpServletRequest request, final javax.servlet.http.HttpServletResponse response)
throws java.io.IOException, javax.servlet.ServletException {
final java.lang.String _jspx_method = request.getMethod();
if (!"GET".equals(_jspx_method) && !"POST".equals(_jspx_method) && !"HEAD".equals(_jspx_method) && !javax.servlet.DispatcherType.ERROR.equals(request.getDispatcherType())) {
response.sendError(HttpServletResponse.SC_METHOD_NOT_ALLOWED, "JSP 只允许 GET、POST 或 HEAD。Jasper 还允许 OPTIONS");
return;
}
final javax.servlet.jsp.PageContext pageContext;
javax.servlet.http.HttpSession session = null;
final javax.servlet.ServletContext application;
final javax.servlet.ServletConfig config;
javax.servlet.jsp.JspWriter out = null;
final java.lang.Object page = this;
javax.servlet.jsp.JspWriter _jspx_out = null;
javax.servlet.jsp.PageContext _jspx_page_context = null;
try {
response.setContentType("text/html; charset=UTF-8");
pageContext = _jspxFactory.getPageContext(this, request, response,
null, true, 8192, true);
_jspx_page_context = pageContext;
application = pageContext.getServletContext();
config = pageContext.getServletConfig();
session = pageContext.getSession();
out = pageContext.getOut();
_jspx_out = out;
out.write("\r\n");
out.write("<!DOCTYPE html>\r\n");
out.write("<html>\r\n");
out.write("<head>\r\n");
out.write("<meta charset=\"UTF-8\">\r\n");
out.write("<title>Insert title here</title>\r\n");
out.write("</head>\r\n");
out.write("<body>\r\n");
out.write(" <form action=\"https://www.baidu.com/\" method=\"get\">\r\n");
out.write(" 用户名:<input type=\"text\" name=\"uname\" placeholder=\"输入手机号\"/><br>\r\n");
out.write(" 密码:<input type=\"password\" /><br>\r\n");
out.write(" 邮箱:<input type=\"email\" /><br>\r\n");
out.write(" \r\n");
out.write(" </form>\r\n");
out.write("</body>\r\n");
out.write("</html>");
} catch (java.lang.Throwable t) {
if (!(t instanceof javax.servlet.jsp.SkipPageException)){
out = _jspx_out;
if (out != null && out.getBufferSize() != 0)
try {
if (response.isCommitted()) {
out.flush();
} else {
out.clearBuffer();
}
} catch (java.io.IOException e) {}
if (_jspx_page_context != null) _jspx_page_context.handlePageException(t);
else throw new ServletException(t);
}
} finally {
_jspxFactory.releasePageContext(_jspx_page_context);
}
}
}
总结:
为什么要使用JSP,JSP和servlet是怎么结合使用的?
通过上边和下边的的代码示例我们发现,其实jsp页面关注的是页面显示数据,servlet层只需关注后台逻辑,比如连接数据库返回数据,然后servlet层可以将数据放到域对象当中,再通过转发或重定向的方式,将数据带到jsp层,jsp通过html+EL+JSTL的方式,将数据
布局到页面数据中,然后tomcat请求时将数据带入到html中以数据流的形式响应给客户端,浏览器根据响应报文解释显示成对应的
网页。
也就是说:虽然JSP看似是html页面,但JSP和Servlet本质都是java,然而以后在项目开发当中,servlet的重心放在业务逻辑处理,
而JSP重心放在响应输出流将数据布局在html页面上。
示例:
浏览器发起请求:http://127.0.0.1:8080/javaEE-05/GetUser?id=1
servlet根据id查询数据库,获取对应id的姓名为"张三",servlet将用户名数据存入request请求域对象,将对象转发给
next.jsp,next.jsp接收请求域对象request中的数据,通过getAttribute方法获取到数据,布局在html元素当中,最终以tomcat
将next.jsp编译为next_jsp.java,通过out.write的形式写入到响应当中。
@WebServlet("/GetUser")
public class GetUser extends HttpServlet {
//浏览器发起请求传一个id过来
//servlet根据id查询数据库获取用户名然后响应显示在页面上
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String id = request.getParameter("id");
//假设我去查了数据库查到此用户的名字是张三
//把查询到的用户名转到jsp上去,让jsp来渲页面
// request.setAttribute("name", "张三");
// request.getRequestDispatcher("next.jsp").forward(request, response);
// response.setContentType("text/html;charset=utf-8");
// PrintWriter pt = response.getWriter();
//
}
}
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%@ include file="daohang.jsp" %>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<%= request.getAttribute("name") %>
</body>
</html>
5.1EL表达式
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<%--
EL:
Expression language表达式语言
作用:
1、主要是让它来代替jsp中一些java脚本元素
比如:
<%!声明%>
<%=表达式%>
<%java代码块%>
有了EL表达式之后的用法:
比如在一些对象当中取值
原来脚本元素的写法:
<%=request.getAttribute("name")%>
EL:的写法
${name}
2、结合jstl来使用,让jsp看起来和html一样
使用:${表达式}
(1)运算
算术运算:
+ - * /(div) %(mod)
逻辑运算:
||(or) &&(and) !(not)
比较运算:
< > == <= >=
空运算: empty
not empty
(2)取值:
主要是从jsp的内置对象当中取值,
内置对象:一些应用、jsp或servlet请求当中已经创建好的对象,
这些对象可以这接拿来用,可以进行取值、存值的操作。
servlet的域对象 jsp内置对象 EL域对象
------- pageContext pageScope
request request requestScope(最常用)
session session sessionScope(最常用)
applicationContext application applicationScope
EL在域对象中取值时:(假设往域对象中存了一个值
比如<%
内置对象名.setAttribute("key", value);
%>
)
两种方式取值:
(1)指定对象名的key取值
${域对象.key}
(2)通过key取值
通过这种方式取值时是有优先级的,先从范围
最小的域对象中取值,如果取到值就不再往下找了。
${key}
--%>
<%--输出5+3的结果在页面上 --%>
${5 + 3 }
<%--el表达式还可以放在标签当中使用 --%>
<h1>${10 div 3 }</h1>
<h2>${5 > 3 and 4 < 2 }</h2>
<h3>${4 <= 2 }</h3>
<%--在jsp内置对象request中存一个值,
通过EL表达式在对应域对象中取值 --%>
<%--
通过脚本元素,使用jsp内置对象存值
--%>
<%
application.setAttribute("name", "王五");
request.setAttribute("name", "张三");
session.setAttribute("name", "李四");
%>
<%--通过EL表达式来获取request对象当中的值 --%>
<%-- ${requestScope.name} --%>
<%--
以下这种方式,是先从request找key值,找到就返回,找不到继续
找session,然后再找application
--%>
${name }
${name }
${name }
<%
int[] arr = {1,2,3,4};
request.setAttribute("arr1", arr);
%>
${ arr1[1]}
</body>
</html>
5.2 jstl
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%--
taglib是标签库指令
prefix前缀,jstl标签前缀的意思
uri的值是标签库地址
--%>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<%--
JSTL:
java server pages tag library,意思为:jsp标签库
为什么要有jstl?
有了它之后可以结合EL表达式,让jsp看起来向html一样,
或者可以认为,让java开发程序员可以像写html一样来实现
页面的布局。
怎么用?
(1)在webapp下的web-inf目录下的lib中添加jstl相关jar包,
add to library
(2)在jsp当中使用taglib指令,来引入jstl标签库
类似于Java当中的import
(3)使用jstl标签+EL表达式来实现页面布局
jstl语法:<c:标签名 属性=值 属性=值 属性=值.....>
内容
</c:标签名>
说明:属性的值可以用EL表达式
内容也可以是EL表达式,也可以是html标签语言
(1)c:if选择标签
如果test值为真,显示标签内容
<c:if test="布尔表达式(可以为EL)">内容</c:if>
注意:没有else
(2) c:choose选择标签,类似于switch
c:when是当条件符合的意思
c:otherwise否则的意思
<c:choose>
<c:when test="布尔值或EL表达式">内容</c:when>
<c:when test="布尔值或EL表达式">内容</c:when>
...
<c:otherwise>内容</c:otherwise>
</c:choose>
注意:choose当中如果有多个when,找到符合条件的标签
就将内容输出,不再执行下边的其他when标签了
(3)c:foreach 是循环、遍历标签
两种使用方式:
foreach的属性:
begin:开始值
end:结束值
var:变量名,类似于java当中for循环定义的int i
step:增量
items:要遍历的对象(数组或集合)
varStatus:变量状态(了解即可)
index:下标
count:当前循环次数
1、普通遍历:
<c:forEach begin="1" end="10" var="x" step="2">
${x }
</c:forEach>
2、遍历数组、集合:类似于增强for循环
(
int[] arr = {1,2,3,4};
for(int x: arr){
syso(x);
}
)
<c:forEach items="${arr }" var="h">
${h }
</c:forEach>
--%>
<%--
if(){
}
--%>
<%
if(5>7){
}
if(3<6){
}
%>
<c:if test="${ 5 > 7}">1111</c:if>
<c:if test="${3 < 6 }">2222</c:if>
<c:if test="true">333</c:if>
<c:choose>
<c:when test="true">5555</c:when>
<c:when test="false">6666</c:when>
</c:choose>
<c:choose>
<c:when test="${4 > 5 }">9999</c:when>
<c:otherwise>88888</c:otherwise>
</c:choose>
<c:if test="${4 == 1 }">
<a href="">删除 </a>
</c:if>
<c:if test="${4 == 4 }">
<a href="">下单 </a>
</c:if>
<c:choose>
<c:when test="${1>2 }">qqqq</c:when>
<c:when test="${2>3 }">www</c:when>
<c:when test="${4>1 }">yyyyyyyyy</c:when>
<c:when test="${6>2 }">uuuuuuuuuuu</c:when>
</c:choose>
<br>
<c:forEach begin="1" end="10" var="x" step="1" varStatus="s">
<b>${s.count }</b>
${x }
</c:forEach>
<br>
<%--在request域对象当中存一个数组 --%>
<%
int[] arr = {1,2,3,4};
session.setAttribute("arr", arr);
%>
<%--通过jstl+El表达式将数组当中的数据放到html内容当中 --%>
<c:forEach items="${arr }" var="h" varStatus="g">
<b>${g.index }</b>
<i>${g.count }</i>
${h }
</c:forEach>
</body>
</html>
JavaEE---项目二实战-博客系统
做项目二准备的工作:
1、数据库mysql
2、JDK(1.8)
3、Tomcat(web应用)
4、相关jar包(mysql、jstl(2个))
5、开发工具(Eclipse、Idea)
6、浏览器
一、数据库准备
库: blog_sys
CREATE DATABASE blog_system CHARACTER SET utf8 COLLATE utf8_general_ci;
表:
user表:
字段:id(唯一、自增)(int)、uname(varchar)、pwd(varchar)、
phone(bigint)、email(varchar)、del_flag(tinyint)
CREATE TABLE `user`(
id INT(11) AUTO_INCREMENT PRIMARY KEY,
uname VARCHAR(20),
pwd VARCHAR(20),
phone BIGINT(20),
email VARCHAR(30),
del_flag TINYINT(2)
)
blog表
字段:id(唯一、自增)(int)、title(varchar)、content(varchar)、
uid(int)、del_flag(tinyint)
CREATE TABLE blog(
id INT(11) AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(30),
content VARCHAR(200),
uid INT(11),
del_flag TINYINT(2)
)
二、创建web项目
1、项目名:BlogSys
tomcat和jdk提前配置好
创建dynamic web project、勾选web.xml
2、将所需的jar包放入webapp目录的web-inf的lib包下,然后选中jar包右键add to build path
3、在项目下使用MVC架构模式,对项目进行分层
先建一个package: com.shuangti.blog
blog下分几层:
controller--控制层(只要是servlet相关)
service---业务逻辑层(内部业务逻辑相关)
dao--主要是数据库相关
entity----实体类层
所有的jsp文件放在webapp目录下
4、实现一个注册功能:
用户发起注册请求,浏览器返回一个注册页面:
http://127.0.0.1:8080/BlogSys2/register
请求由servlet接收并响应(内部通过转发的方式,转发到jsp,然后将jsp响应给浏览器)
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* 注册页跳转
*/
@WebServlet("/register")
public class Register extends HttpServlet {
private static final long serialVersionUID = 1L;
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.getRequestDispatcher("register.jsp").forward(request, response);
}
}
import com.shuangti.blog.dao.UserDao;
import com.shuangti.blog.entity.User;
/*
* Service层主要是保存数据之前
* 做一些业务逻辑处理
*
* */
public class UserService {
public boolean saveUser(User user) {
//todo通过UserDao的insertUser保存用户
UserDao uDao = new UserDao();
return uDao.insertUser(user);
}
}
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import com.shuangti.blog.entity.User;
import com.shuangti.blog.util.JdbcUtils;
public class UserDao {
public boolean insertUser(User user) {
//连接数据库,保存用户
//获得连接
Connection con = JdbcUtils.getCon();
//准备sql
String sql = "insert into user (uname,pwd,phone,email) values(?,?,?,?)";
//执行sql
try {
PreparedStatement ps = con.prepareStatement(sql);
//替换sql当中的占位符?
ps.setString(1, user.getName());
ps.setString(2, user.getPwd());
ps.setLong(3, user.getPhone());
ps.setString(4, user.getEmail());
//执行
int result = ps.executeUpdate();
if(result == 1) {
return true;
}
} catch (SQLException e) {
e.printStackTrace();
}
return false;
}
}
import java.sql.*;
/*
* JDBC工具类
* */
public class JdbcUtils {
// public static final String url = "";
//静态代码块,类加载的时候只执行一次,以后再也不执行了
static {
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/*
* 获得连接
* */
public static Connection getCon() {
String url = "jdbc:mysql://127.0.0.1:3306/blog_system?characterEncoding=utf-8";
String uName = "root";
String pwd = "123456";
Connection con = null;
try {
con = DriverManager.getConnection(url,uName,pwd);
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return con;
}
/*
* 释放资源
* ResultSet
* Statement或PrepareStatement
* Connection
* 释放资源有顺序 ResultSet->Statment或PrepareStatement->Connection
* */
public static void close(Connection con,
Statement stat, PreparedStatement pre,ResultSet ret) {
if(ret != null) {
try {
ret.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(stat != null) {
try {
stat.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(pre != null) {
try {
pre.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if(con != null) {
try {
con.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<form action="saveUser" method="GET">
用户名:<input type="text" name="uname" id="" >
<br>
密码:<input type="password" name="pwd">
<br>
手机号:<input type="text" name="phone">
<br>
邮箱:<input type="text" name="email">
<br>
<input type="submit" value="注册">
</form>
</body>
</html>
5、通过过滤器实现控制登录态:
import java.io.IOException;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
@WebFilter("/*")
public class MyFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
// TODO Auto-generated method stub
}
//过滤相关的功能写在doFilter这个方法里面
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
// TODO 判断当前请求路径是否需要登录
//如果不需要登录,放过此请求,如果需要,让它跳转至登录页
// 哪些不需要登录?login home register saveUser checkUser
//checkUser
HttpServletRequest req = (HttpServletRequest)request;
String urI = req.getRequestURI();
System.out.println("filter======"+req.getRequestURI());
//contains
//"qwertyuuoopp".contains("oo") 为true
//"qwertyuuoopp".contains("qwer") 为true
if(urI.contains("login")
|| urI.contains("home") || urI.contains("register")
|| urI.contains("saveUser") || urI.contains("checkUser")
|| urI.contains("allBlog") || urI.contains(".jpg")) {
//放过此请求,继续到servlet层
chain.doFilter(request, response);
}else {
//其他的请求需要检查一下会话当中是否有user,如果有,请求继续
HttpSession session = req.getSession();
if(session != null && session.getAttribute("user") != null) {
chain.doFilter(request, response);
}else {
//如果没有,跳转至登录页
HttpServletResponse resp = (HttpServletResponse)response;
resp.sendRedirect("login");
}
}
}
@Override
public void destroy() {
// TODO Auto-generated method stub
}
}
第三章 JAVA高级
1.1 java面向对象高级
1.1.1 final 关键字
final是java当中的一个关键字,也是一个修饰符,他可以用来修饰:
(1)变量:
修饰的基本数据类型,一旦赋值不可改变
修饰引用数据类型(什么是引用?引用是一个变量,指向的是一个地址)
final修饰的引用变量,指向的地址不可改变,也就是不能重新指向新的地址
但是需要注意:final修饰的引用指向的地址中对应的数据是可以改变的,具体可以参考下边的第二个示例
(2)方法:final修饰的方法不可以被子类重写
(3) 类:final修饰的类不可以被继承
final一般常用来修饰静态变量
例如public static final String NATION="美国国籍"
举例:
final修饰变量
public class Test01 {
public static void main(String[] args) {
final int a;
a = 10;
a = 20;//此处报错,a被final修饰之后不能重新赋值
}
}
final修饰引用
public class Test01 {
public static void main(String[] args) {
final A qq = new A();
qq.name = "123";
qq.name = "456";//此处编译通过,因为此处并没有改变qq变量的地址,只是改变了qq指向地址的数据
qq = new A();//此处编译报错,new出现就会重新开辟内存空间,此时是把qq变量指向新的内存地址,但是qq被final修饰了,
//final修饰的引用变量不能重新指向新的地址
}
}
final修饰方法:
public class A {
final int b =10;
String name;
public final void test() {
System.out.println("++++++++++=");
}
}
public class B extends A{
//此处编译报错,父类中test方法被final修饰,不能被重写
// public void test() {
// System.out.println("***********");
// }
}
final修饰类
public final class D {
}
//此处编译报错,父类D被final修饰,不能被继承
public class C extends D{
}
1.1.2 抽象类
(1)首先回顾一下什么是类、对象?
类是一个概念,是客观世界不存在的东西
对象是真实存在的
类和对象的关系,将具体共同属性和行为的对象抽象出来的概念统称为类。
从类------>对象的过程叫做实例化,从对象-------->类的过程叫做抽象
(2)什么是抽象类???
从类-------->抽象类的过程,也是一个抽象的过程,其实就是将很多具有共同特征的类进一步抽象为抽象类。
需要注意!!!!:
类------->抽象类只是单向的,不能从抽象类实例化出类,为什么?
仔细思考,类实例化出的对象是真是存在的,那么如果抽象类能实例化,那也就是说类也是真是存在的,这根
类的概念相违背了,所以设计上就不让抽象类实例化了。
(3)抽象类如何定义:
public abstract class 类名{
int a;
//普通方法。可以没有
public void test(){
}
//抽象方法,可以没有,如果有那只能出现在抽象类中
//用abstract修饰的方法就是抽象方法,抽象方法没有方法体
public abstract void test1();
}
总结:
1、抽象类不能被实例化,但是继承它的子类可以实例化
2、抽象类也有构造方法,虽然有构造方法,不是提供给它本身用的,是为了提供给子类使用的
3、抽象类中可以写抽象方法,注意:
如果普通类继承了一个抽象类,必须要重写父类抽象类中的抽象方法,不然编译报错
4、普通类中不可以出现抽象方法,也就是抽象方法一定出现在抽象类当中(后边讲的接口中也会有抽象方法)
6、抽象类也可以继承抽象类,但是肯定也是单继承的
抽象类继承了抽象类,不需要重写它的父抽象类的方法,但是需要记住普通方法必须要重写父类和它的祖宗类的抽象方法
1.1.3 接口
接口同普通类一样是一种类型,使用interface代替class定义
接口中一般只有静态常量和抽象方法(这里说的是一般情况)
注意:不同版本的接口有所区别!!
jdk1.8版本的接口中可以定义静态方法,jdk1.9以后还可以在接口中定义私有方法
(1)接口怎么使用:(通过implements关键字实现接口)
实现接口的类必须要将接口中的抽象方法重写!!
public interface A{
//属性:默认是static final的
int a;
//方法:默认是抽象方法
void test();
}
public class B implements A{
@Override
public void test() {
// TODO Auto-generated method stub
}
}
(2)一个类可以同时实现多个接口
public class C implements F,G,....{
}
(3)接口可以继承接口,而且是多继承的
public interface H extends K,L.....{
}
(4)接口的存在,解决了java开发当中类只能单继承的局限性。
总结-----------普通类、抽象类、接口的区别:
普通类 抽象类 接口
1、成员 属性和方法 属性和方法 属性和方法
2、属性 实例、静态 实例和静态 静态
3、方法 实例、静态方法 普通方法和抽象方法 抽象、default方法、私 有方法(1.9)
4、继承 单继承 单继承 多继承(接口继承接口)
(一个类也可以实现多个接口)
5、 实例化 可以 不可以 不可以
总结:什么情况下使用抽象类和接口呢?
大多数情况下我们项目中都是面向对象和接口开发的,有时候业务上可能需要使用多继承的一些特性,所以大部分情况都是优先选择使用接口。
1.1.4 枚举类
枚举类:如果一个类当中只有静态常量,建议将这种类定义为枚举类
没有枚举类之前定义一个季节类是这样的
注意:该季节类当中只有静态常量
public class Season {
final static String spring = "春天";
final static String summer = "夏天";
final static String autumn = "秋天";
final static String winter = "冬天";
}
有了枚举类之后是这样定义的:
package com.shuangti.high;
/*
* 枚举类是一种特殊的类
* 一般情况下,如果一个类中只用静态常量,最好把这种类定义为枚举类
* 枚举类不能实例化
* 枚举类如何定义
*
* public enum 类名{
* 枚举值1,
* 枚举值2,
* ...
* 枚举值n;
*
* }
* public enum 类名{
* 枚举值1("属性值1","属性值2"...,"属性值n"),
* 枚举值2("属性值1","属性值2"...,"属性值n"),
* ...
* 枚举值n("属性值1","属性值2"...,"属性值n");
*
* private 类型 属性1变量名;
* private 类型 属性2变量名;
* .....
* private 类型 属性n变量名;
*
* //有参构造
* private 当前枚举类的名字(对应n个形参变量){
* this.属性名=形参;
* }
*
* }
*
* 枚举类的使用:
* 1、获取枚举类的枚举值
* 类名.枚举值名
* 2、获取枚举类的属性值
* 类名.枚举值.属性名
* */
public enum SeasonEnum {
SPRING("春天"),
SUMMER("夏天"),
AUTUMN("秋天"),
WINTER("冬天");
//春天、夏天..代表当前枚举类的属性值,既然有属性值,那么该类
//必须要声明一个对应的属性
public String name;
private SeasonEnum(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
}
在开发当中一般枚举类用到最多的场景是用枚举类来实现错误码类:
public enum ErrorEnum {
SERVER_ERR("500","服务内部错误"),
NOT_EXIST("404","资源部存在")
;
public String code;
public String msg;
private ErrorEnum(String code, String msg) {
this.code = code;
this.msg = msg;
}
}
枚举类如何使用呢??
public class Test01 {
public static void main(String[] args) {
System.out.println(Season.spring);
Season s = new Season();
System.out.println(s.spring);
System.out.println(SeasonEnum.SUMMER.name);
// SeasonEnum ss = new SeasonEnum();
System.out.println(ErrorEnum.SERVER_ERR.msg);
}
}
1.1.5 内部类
内部类:可以在普通类定义的类,分为:
实例内部类
静态内部类
局部内部类(定义在方法中的类)
匿名内部类(没有类名的类)
/*
* 内部类:定义在普通类当中的类
* 隐藏细节、增强封装性
* (这一部分知识点了解即可,以后见到别人写的代码知道是个什么东西就可以了)
* 分类:
* 1、实例内部类
* 2、静态内部类
* 3、局部内部类(定义在方法当中的类)
* 局部内部类只能在当前方法中使用
* 4、匿名内部类
* 有时候有些接口的方法想要使用的时候不想
* 单独创建一个java实现类再实例化去调用,
* 这个时候就可以使用匿名内部类的方式
* //匿名内部类
new UnName() {
public void test() {
System.out.println("++++++++++");
}
}.test();
其中
UnName() {
public void test() {
System.out.println("++++++++++");
}
}是一个匿名内部类
*
* */
public class OuterClass {
//属性(变量)
//1、实例变量2、静态变量
//方法
//1、实例方法2、静态方法
//实例内部类
public class InnerClass1{
int a;
public void m1() {
System.out.println("实例内部类的方法");
}
}
//静态内部类
public static class InnerClass2{
int b;
public void m2() {
System.out.println("静态内部类的方法");
}
}
public void method() {
//局部内部类
class InnerClass3{
int c;
public void m3() {
System.out.println("局部内部类的方法");
}
}
InnerClass3 inner3 = new InnerClass3();
inner3.m3();
}
}
内部类的实例化:
public class Test02 {
public static void main(String[] args) {
//实例内部类的实例化
OuterClass out = new OuterClass();
OuterClass.InnerClass1 inner1 = out.new InnerClass1();
//静态内部类实例化
OuterClass.InnerClass2 inner2 = new OuterClass.InnerClass2();
inner2.m2();
UnameImpl u = new UnameImpl();
u.test();
//匿名内部类
new UnName() {
public void test() {
System.out.println("内名内部类");
}
}.test();
}
}
1.2 集合框架:
(1)集合框架主要是由一些接口,一些抽象类和一些实现类组成。所谓框架就是一个类库的集合。
集合框架就是用来表示和操作集合的统一的架构,包含了实现集合的接口和类,存在于java.util包中。
(2)集合存放数据的一个容器
学习集合目标:
掌握集合的数据存储(增删改查)
掌握集合的遍历
了解集合部分底层原理
(3) 集合和数组的比较
1、数组:存放数据,只能放同一种类型、长度是固定的
能存放基本数据类型的数据
2、集合:长度不固定,他可以存放所有的引用数据类型
集合当中存放的基本数据类型字面值的数据会自动变为相应的引用数据类型,比如
List.add(123),123会自动转为Integer类型
集合框架的主要组成部分:
(4)由于接口是不能实例化的,只能通过接口的实现类来使用Collection、List、Set、Map接口及其子接口的方法
1.2.1 单列表顶层接口Collection
(1)掌握Collection的常用方法
Collection中如果不指定泛型,默认存放所有引用数据类型(Object)
add(E e) 往集合中添加元素
remove(Object o) 该集合中删除指定元素的单个实例(如果存在)
size() 返回此集合中的元素数。
contains(Object o) 如果此集合包含指定的元素,则返回 true 。
clear() 从此集合中删除所有元素
isEmpty() 如果此集合不包含元素,则返回 true
toArray() 返回一个包含此集合中所有元素的数组
public static void main(String[] args) {
Collection col = new ArrayList();
//col本质是一个引用,是一个地址,之所以打印出来是一个数组字符串
//因为ArrayList重写toString方法
System.out.println(col);
// List list = new ArrayList();
// 由于改集合未指定泛型,默认存入的数据类型是Object,也就是可以存放任意引用数据类型的数据
col.add(111);
col.add("22");
Dog dog = new Dog();
col.add(dog);
System.out.println(col);
System.out.println(col.size());
// col.remove(dog);
System.out.println(col.size());
System.out.println(col.contains("22"));
// col.clear();
System.out.println(col.size());
}
(2)掌握Collection的遍历方式
常用的三种遍历方式:
2.1可以将集合转为数组,通过数组的方式遍历它
2.2使用迭代器遍历集合
迭代器就是用来遍历集合的
迭代器:
迭代器是一个接口,接口当中有两个抽象方法hasNext() next()
每一个单列集合都具有迭代的能力,也就是每一个单列集合都可以生成一个迭代器对象,
然后可以通过这个迭代器对象对集合进行遍历
步骤:
(1)通过集合对象,调用iterator()方法返回一个迭代器对象
(2)通过迭代器对象的hasNext()和next()方法来遍历集合中的每一个数据
2.3使用增强for循环,foreach
语法:
for(集合或数组当中存放的对应数据类型 变量名 : 数组对象/单列集合){
}
public static void main(String[] args) {
Collection col = new ArrayList();
System.out.println(col);
col.add(111);
col.add("22");
Dog dog = new Dog();
col.add(dog);
//遍历
//2.1 通过集合转数组遍历
Object[] objs = col.toArray();
for(int i = 0; i < objs.length; i++) {
System.out.println(objs[i]);
}
//2.2通过迭代器遍历集合
Iterator it = col.iterator();
while(it.hasNext()){
Object o = it.next();
System.out.println(o);
}
//2.3增强for循环
for(Object o : col) {
System.out.println(o);
}
}
1.2.2 泛型
泛型: 泛指某一种类型,是一个变量,可以用来接收数据类型
如果某一个类、接口、方法加了泛型,在使用的时候不指定类型,默认是Object
如果把泛型指定为某一种,那么它相关的元素类型都为此类型。
(1)泛型可以加在类上
public class 类名<泛型变量> {
}
泛型变量是用来接收数据类型
E element
T type
(2)泛型可以加在方法上(了解)
修饰符列表 <泛型变量> 返回类型 方法名(形参列表){
}
(3)可以加在接口上
(4)泛型通配符?
下限限定:? super 类 :传入的参数必须是对应类或其父类
上限限定:? extends 类 :传入的参数必须是对应类或其子类
泛型加在类上:
public class Example01<E> {
private E name;
public E getName() {
return name;
}
public void setName(E name) {
this.name = name;
}
}
public static void main(String[] args) {
Example01<String> ex = new Example01<String>();
ex.setName("111");
System.out.println(ex.getName());
//不指定类型。所有Object类型都可以接收
Example01 ex2 = new Example01();
ex2.test(111);
}
泛型加在方法上
public class Example02 {
/*
* test方法在定义的时候不确定形参的类型,这个时候可以在方法
* 上加一个泛型
* */
public <H> void test(H h) {
System.out.println("============");
}
}
public static void main(String[] args) {
Example02 ex2 = new Example02();
ex2.test("111");
}
泛型加在接口上(我们用到的List接口就使用了泛型)
public interface List<E> extends Collection<E> {
...
}
泛型通配符?的使用方式
public class Example03 {
public void test(Collection<? super Parent> col) {
System.out.println("下限限定");
}
public void test1(Collection<? extends Parent> col) {
System.out.println("上限限定");
}
}
public class Parent {
}
public class Son extends Parent{
}
public class Daughter extends Parent{
}
public static void main(String[] args) {
Example1 exam = new Example1();
List<Parent> list1 = new ArrayList<Parent>();
List<Son> list2 = new ArrayList<Son>();
List<Daughter> list3 = new ArrayList<Daughter>();
exam.test(list1);
exam.test(list2);//报错,Son是Parent的子类
exam.test(list3);//报错,Daughter是Parent的子类
exam.test(list4);//Object是Parent的父类
exam.test1(list1);
exam.test1(list2);
exam.test1(list3);
}
1.2.3 Collection字接口List集合
List是一个有序列表,有序是指的放入数据的顺序,而不是
list当中的数据又排序
list是有索引的,Collection没有
声明一个list对象常用的方式:
List<String> sList = new ArrayList<String>();
除了继承自Collection中的方法,他还有一些自己独有的方法:
1.get(index)
2.set(index,element)
3.remove(index)
4.add(int index, E element)
遍历:
(1)根据索引去遍历
(2)使用迭代器
(3)增强for循环
public static void main(String[] args) {
//声明了一个字符串列表
List<String> sList = new ArrayList<String>();
sList.add("11");
sList.add(1, "22");
System.out.println(sList.size());
sList.add("33");
//获取指定位置的元素
System.out.println(sList.get(2));
//替换第二个位置的元素为2222
sList.set(1, "2222");
System.out.println(sList.get(1));
//删除第三个元素
sList.remove(2);
// System.out.println(sList.get(2));//报错索引越界
List<Integer> list1 = new ArrayList<Integer>();
list1.add(10);
list1.add(11);
list1.add(12);
list1.add(12);
// list1.add(3, 555);
//1、根据索引遍历
for(int i = 0; i < list1.size(); i++) {
System.out.println(list1.get(i));
}
//2、使用迭代器(很少用)
Iterator<Integer> it = list1.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
//3、增强for循环
for(Integer i : list1) {
System.out.println(i);
}
1.2.3.1 补充
补充:
LinkedList 相比于ArrayList查询效率低,添加删除效率高,
因为他是双向链表
关于常见的数据结构:
栈->先进后出(方法入栈)
队列->先进先出
单链表->
data区->存放数据
指针区->指向下一个节点数据的地址
双向链表->
head指针->上一个节点数据的地址
data->数据区
tail尾->下一个节点的数据的地址
树->根、叶子节点
1.2.4 Collection字接口Set集合
Set集合它也是Collection的子接口
Set和List相比没有索引
Set存入的数据不重复,是无序的
HashSet是Set的实现类
Set<数据类型> set = new HashSet<数据类型>();
方法:有继承自Collection接口的抽象方法,没有自己特定的方法
遍历:
1、迭代器遍历
2、增强for循环
补充:
1、hashCode默认情况下是当前引用数据类型的内存地址的十进制
2、为什么set是不重复的?
其实它是根据存入的引用数据类型的hashCode()和equals()方法
来判定放入的数据是不是同一个
如果set中存放的数据hashCode相同就出现hash冲突的现象
数据会以链表的形式放在set中
set底层是以数组+链表的结构存储数据的,
set在存值的时候,会根据当前数据的hashcode和集合长度计算
set所在数组索引的位置,如果两个数据的hashCode一样,并且
equal为false,会造成hash冲突,如果hash冲突行成的链表长度超过8,JDK8以前链表结构不变
JDK8以后链表会转为树结构
public class User extends Object{
String name;
public int hashCode() {
return 1111;
}
public boolean equals(Object obj) {
User user = (User)obj;
if(this.name.equals(user.name)){
return true;
}else {
return false;
}
}
}
public static void main(String[] args) {
Set<String> set = new HashSet<String>();
set.add("111");
set.add("222");
//同时放入了两次333,但是实际只放入了一个(set元素不重复)
set.add("333");
set.add("333");
set.add("avc");
set.add("ee");
set.add("ddd");
set.add("ggg");
//打印的set中的值顺序和实际放入元素的顺序不一样
//也就是set是无序的
System.out.println(set);
System.out.println("333".hashCode());
System.out.println("333".equals("333"));
//迭代器遍历
Iterator<String> it = set.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
//增强for循环遍历
for(String s : set) {
System.out.println(s);
}
Set<User> set1 = new HashSet<User>();
User user1 = new User();
user1.name = "11";
User user2 = new User();
user2.name = "11";
set1.add(user1);
set1.add(user2);
//打印的结果为1,是因为User类重写了hashCode方法和equals方法
//user1和user2返回的hashCode,
//user1和user2的name相同,equals结果为true
//这时在放入set中时,由于set判断重复的条件判定user1和user2为重复数据,所以只放入了一个user1
//故set1的大小为1
System.out.println(set1.size());
System.out.println("BB".hashCode());
System.out.println("Aa".hashCode());
Set<String> set2 = new HashSet<String>();
set2.add("BB");
set2.add("Aa");
//结果为2,BB和Aa的HashCode相同但是equals为false
System.out.println(set2.size());
}
1.2.5 Map集合
学习目标:
掌握Map中的HashMap实现类的用法,存值、取值及遍历
了解HashMap的底层原理(JDK1.8以前链表+数组,1.8以后数组+链表+红黑树)、HashMap的一些静态常量
1、Map是一个抽象集合接口,是集合中除Collection另一个重要组成部分,它存储数据是通过键值对映射的形式进行存储的。
因此,Map也叫作双列集合。
2、Map下有一些常见的实现类:HashMap、HashTable、TreeMap、LinkedHashMap
3、平常用到最多的是HashMap:
Map<key对应的引用数据类型,value对应的数据类型> map = new HashMap<key对应的引用数据类型,value对应的数据类型>();
//声明了一个可以存放key为String类型、value为String类型的map集合
Map<String, String> map = new HashMap<String, String>();
注意:
(1)Map集合的key不能重复(基于hashCode方法和equals方法)
(2)HashMap的key值、value值可以为null
HashTable的key值、value不能为null
(3)Map中存入的值是无序的
4、Map接口中常用的方法
put(Object,Object)存值
get(Object key)通过键值获取value值
keySet()获取map的所有key值放入set集合
values()获取map所有的value值放入Collection集合
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<Integer, String>();
map.put(1, "111");
map.put(2, "222");
map.put(3, "333");
map.put(4, "444");
map.put(5, "aaa");
map.put(6, "cdf");
map.put(7, "edg");
//通过key来找value
System.out.println(map.get(3));
//获取map中所有的键值
Set<Integer> set = map.keySet();
System.out.println(set);
for(Integer s : set) {
System.out.println(s);
}
//获取map当中所有的value
Collection<String> values = map.values();
System.out.println(values);
System.out.println(map);
Map<String, String> map1 = new HashMap<String,String>();
map1.put("qwr","123");
map1.put("qqq","33");
map1.put("yue","66");
map1.put("yue","77");
map1.put(null, null);
System.out.println(map1);
}
5、Map常用的遍历
1、通过keySet获取所有的key值,然后
通过get方法获取value
2、通过Map.Entry<K,V>遍历(最常用)
public static void main(String[] args) {
Map<String, String> map1 = new HashMap<String,String>();
map1.put("qwr","123");
map1.put("qqq","33");
map1.put("yue","66");
map1.put("yue","77");
map1.put(null, null);
System.out.println(map1);
// System.out.println(key + "==" +value);
//1、通过keySet遍历
Set<String> s1 = map1.keySet();
for(String ss : s1) {
System.out.println(ss + "==" + map1.get(ss));
}
//2、迭代器遍历
Iterator<String> it = s1.iterator();
while(it.hasNext()) {
String key = it.next();
System.out.println(key + "==" + map1.get(key));
}
System.out.println("==============================");
//3、使用Map的Entry对象
//Map.Entry<String, String>把它认为是一个对象,这个对象
//所对应的类型是一个Map.Entry类型,然后这个类型有key、value属性
//他还有相应的get、set方法
Set<Map.Entry<String, String>> entries = map1.entrySet();
for(Map.Entry<String, String> entry : entries) {
System.out.println(entry.getKey() + "==" + entry.getValue());
}
//Hashtable
Map<String, String> map2 = new Hashtable<String, String>();
map2.put("111", "22");
System.out.println(map2);
}
集合大总结:
1、掌握最基本的三种集合的实现类及声明方式
//List集合
List<引用数据类型> list = new ArrayList<引用数据类型>();
//Set集合
Set<引用数据类型> set = new HashSet<引用数据类型>();
//Map集合
Map<key对应的引用数据类型,value对应的数据类型> map = new HashMap<key对应的引用数据类型,value对应的数据类型>();
2、掌握List、Set、Map的区别!!!
(1)List 放入的数据可以重复、有序、有索引
(2)Set放入的数据不能重复(不能重复的机制去了解下)、无序、无索引
(3)Map 是双列集合,键值对的数据存储模型,
key不能重复、存入的数据无序
其中HashMap的key、value可以为空null;HashTable不能为空null
3、了解一些基本的数据结构:栈、队列、链表、树结构
了解set和Map的底层实现原理
1.3 File类
概念:文件和目录路径名的抽象表示形式,在java.io包下
作用:java把电脑中的文件和文件夹(目录)封装为了一个File类,我们可以使用File类对文件和文件夹进行操作
通过将File类及文件或文件夹的路径实例化出文件或文件夹对应的实例对象
File file = new File("D://file01//11.txt");
学习目标:
我们可以使用File类的方法
创建一个文件/文件夹
删除文件/文件夹
获取文件/文件夹
判断文件/文件夹是否存在
对文件夹进行遍历
获取文件的大小
File类是一个与系统无关的类,任何的操作系统都可以使用这个类中的方法
1.3.1 File类中的静态属性
pathSeparator
separator
pathSeparator
(1)与系统相关的路径分隔符字符
系统环境变量的分隔符
(2)windows下是";" Linux下是":"
separator
(1)与系统相关的默认名称 - 分隔符字符,以方便的方式表示为字符串。
文件路径分隔符
比如D:\shuangti02\workspace
windows下是"\" linux是"/"
public static void main(String[] args) {
System.out.println(File.pathSeparator);//windows下输出结果为;
}
public static void main(String[] args) {
System.out.println(File.separator);//windows下输出\
//获取C盘下user文件夹下data文件夹的test.txt文件
//编写文件路径的时候
//后续在通过路径获取文件或者文件夹的时候一定要检查一下分隔符
//和系统是否对应
String path = "C:"+File.separator +"+user+"
+File.separator+"data"+File.separator+"test.txt";
}
1.3.2 File类的构造方法
File类的构造方法
构造方法:实例化对象并给对象赋值的
实例化出来的对象对应磁盘中的文件或文件夹
然后通过此对象就可以对文件、文件夹进行一系列的操作了
File(File parent,String child)
从父抽象路径名和子路径名字符串创建新的 File实例。
File(String pathname)
通过将给定的路径名字符串转换为抽象路径名来创建新的 File实例。
File(String parent,String child)
从父路径名字符串和子路径名字符串创建新的 File实例。
File(URL uri)
通过将给定的 file: URI转换为抽象路径名来创建新的 File实例。
public static void main(String[] args) {
//1、根据文件路径创建一个file对象,此对象就可以相当于11.txt文件了
//其中的\\是对路径分隔符\进行了转义
File file1 = new File("D:\\shuangti02\\file01\\11.txt");
System.out.println(file1.length());
//2、通过父类对象及子文件、文件夹路径来实例化对象
File parent = new File("D:\\shuangti02\\file01");
File child = new File(parent, "11.txt");
//length()方法返回由此抽象路径名表示的文件的长度。
System.out.println(child.length());
//3、通过父路径及子文件、文件夹来实例化对象
File file2 = new File("D:\\shuangti02\\file01","11.txt");
System.out.println(file2.length());
}
1.3.3 File类中常用的方法
getAbsolutePath()获取当前文件实例对象多对应的文件或文件夹的绝对路径
相对路径:
是以当前项目为根路径,为参照
绝对路径:
对应文件或文件夹以盘符(C: D: F:)为根目录所在的全路径地址
getName()获取当前实例对象所对应的文件或文件夹的名字
isDirectory()判断当前实例对象是不是一个文件夹结果为布尔值
isFile()是不是文件,结果布尔值
createNewFile()创建文件,创建的文件所在的文件夹目录必须是存在的,不然报错
mkdir()创建单级目录,也就是一次只能创建一个文件夹
mkdirs()创建多级目录
delete()删除文件或文件夹,永久删除,不进回收站,使用要谨慎
exists()判断文件或文件夹是不是存在
list()获取对象所在的目录下所有的文件及文件夹的名称
listFiles()获取文件对象所在目录下所有的文件及文件夹对象
public static void main(String[] args) throws IOException {
File file = new File("D:\\11.txt");
System.out.println(file.getAbsolutePath());
File file1 = new File("file.txt");
File file2 = new File("test");
System.out.println(file1.getAbsolutePath());
System.out.println(file1.length());
System.out.println(file2.getName());
System.out.println(file1.isDirectory());
System.out.println(file2.isDirectory());
System.out.println(file1.isFile());
//createNewFile
File file3 = new File("D:\\shuangti02\\workspace\\day_5_12\\file03.txt");
file3.createNewFile();
//在day_5_12下创建一个111文件夹并创建一个file04.txt
//mkdir mkdirs
File file4 = new File("111");
file4.mkdir();
//在day_5_12下创建一个222文件夹222下有一个333文件夹
File file5 = new File("D:\\shuangti02\\workspace\\day_5_12\\222\\333");
file5.mkdirs();
//delete
File file6 = new File("111");
file6.delete();
//exists
File file7 = new File("file02.txt");
System.out.println(file7.exists());
File file8 = new File("D:\\shuangti02\\workspace\\day_5_12");
String[] s = file8.list();
for(String ss : s) {
System.out.println(ss);
}
File[] files = file8.listFiles();
//找一下day_5_12是否存在一个222的文件
for(File f : files) {
if(f.getName().equals("222")) {
System.out.println("找到了......");
}
}
}
1.4 IO流
1.4.1 IO流概述
1、流是数据序列的抽象概念。对于一个程序来说,输入流用来读取数据,输出流用来写数据。
文件、网络连接、内部进程间的通信管道、内存都可以被看作是流,也就是程序可以从中读取数据,或向其写入数据。
流提供了一种用统一的方式从各种各样的输入输出设备中读取和写入数据的方法。
如果一个程序支持从文件中读取数据进行处理,那这个程序可以很容易的修改成从网络中读取数据并处理。
2、IO流主要分为两大类(所有的流相关的类都在java.io包下):
输入流(读Read)、输出流(写Write)
所有的输入流都具有读的能力,比如InputStream和FileReader
所有的输出流都具有写的能力,比如OutputStream和FileWriter
也可以分为另外两大类字符流和字节流
字节流:InputStream OutputStream
字符流:Reader Writer
3、IO流按两种分类的主要组成部分(这里只列举常用到的类)
在记忆的时候--怎么记忆??或者怎么区分??
所有Stream结尾的流都是字节流、所有Reader或Writer结尾的都是字符流
第一种按照输入输出流或者读写流来分类:
第二种按照字符流、字节流两大类分类
4、文件在电脑中以二进制存储的?为什么我们能看到英文字母、中文?
当我们打开文件时,电脑会将文件对应的二进制文件按照对应编码格式转为相应的字符,通过电脑的输出设备(显示器)显示在
输出设备上,所以用户看到的并不是硬盘上实际存储的数据。
1.4.2 输入字节流InputStream
字节流可以称为是万能流,所有的文件都是以字节(0101)的形式存在,
所以字节流可以读写任意类型的文件(txt、jpg、Mp3.....)
1、InputStream(抽象类)
下边的抽象方法:
read()一次读取一个字节,方法每执行一次,读取一次。返回的是读到的是每一个字节所对应的十进制,读不到返回-1
read(Byte[] b)一次读取多个字节,返回的是读取到的实际字节的个数,读不到返回-1
close()关闭流
2、如果想用InputStream下的方法,只能通过它的子类(非抽象类)实例化来调用
FileInputStream(文件输入流)
BufferedInputStream(缓冲输入流)
3、FileInputStream
构造方法:
(1)public FileInputStream(String name)
name 是文件所对应的路径
(2) public FileInputStream(File file)
file:通过一个file实例对象构造输入文件字节流
//相当于打开11.txt,将文件指向实例对象in
FileInputStream in = new FileInputStream("D:\\11.txt");
//读取文件当中的数据
//UTF-8编码的文字,中文占三个字节
//GBK占两个字节
//read()一次只读取一个字节,以十进制的形式返回
// System.out.println(in.read());
// System.out.println(in.read());
// System.out.println(in.read());
// System.out.println(in.read());
// System.out.println(in.read());
// System.out.println(in.read());
//通过以下while循环代替上边重复代码
int a = 0;
while((a= in.read()) != -1) {
System.out.println((char)a);
}
// byte b = 97;
// char c = (char)b;
// System.out.println(c);
//
//一次读取多个字节
//read(Byte[] b)返回的是读到几个字节,读不到返回-1
FileInputStream in1 = new FileInputStream("D:\\11.txt");
byte[] b = new byte[3];
System.out.println("======="+ in1.read(b));
System.out.println(in1.read(b));
System.out.println(in1.read(b));
FileInputStream in2 = new FileInputStream("D:\\11.txt");
in2.read();
//文件流读取完毕最好把流关闭,减少资源浪费
in2.close();
System.out.println("关闭之后再读一次===="+ in2.read());
FileInputStream in3 = new FileInputStream(new File("D:\\11.txt"));
}
1.4.3 输出字节流OutputStream
输出字节流OutputStream
1、获取文件输出流可以对文件进行写入操作
主要掌握两个输出流子类:
FileOutputStream文件输出流
BufferedOutputStream文件缓冲流
OutputStream下需要掌握的抽象方法
write(int b)一次写入一个字节
write(byte[] b)一次写入多个字节
flush()将缓冲区的字节刷新到文件当中
主要是缓冲流使用到
close() 关闭流
2、FileOutputStream的构造方法(如果文件路径对应的文件不存在,会创建一个对应类型的空文件)
(1)
public FileOutputStream(String name)
name:文件的路径
写入数据的时候会将原来的内容覆盖掉
(2)
public FileOutputStream(String name, boolean append)
name:文件的路径
append:是否追加内容,如果为true,写入数据时在原有文件中数据后追加数据;为false会覆盖原有数据
public static void main(String[] args) throws IOException {
//打开一个文件流,然后往文件当中写入文字
//这种打开流的方式进行写操作,会将文件当中的数据覆盖掉
FileOutputStream out1 = new FileOutputStream("D:\\11.txt");
//一次写入一个字节
out1.write(103);
//这种方式是通过构造方法中append参数true或false来决定
//是否在原有文件的基础上追加数据
FileOutputStream out2 = new FileOutputStream("D:\\11.txt", true);
out2.write(106);
//一次写入多个字节
byte[] b = new byte[3];
b[0] = 109;
b[1] = 110;
b[2] = 111;
out2.write(b);
// out2.close();
//报错:关闭流之后不能再写入了,其实是close方法将out2指向的内存释放掉了
// out2.write(113);
//如果路径指向的文件不存在,会创建一个对应类型的空文件
FileOutputStream out3 = new FileOutputStream("D:\\666.jpeg");
}
经典案例:通过输入输出字节流实现文件(图片)的复制
public static void main(String[] args) throws IOException {
FileInputStream in = new FileInputStream("D:\\my.jpeg");
FileOutputStream out = new FileOutputStream("D:\\my_copy.jpeg");
int a = 0;
while((a = in.read()) != -1) {
out.write(a);
}
in.close();
out.close();
}
1.4.4 缓冲字节流
缓冲流:在原有字节流的基础之上,为字节流对象创建一个缓冲流对象,来提高数据读写的效率。
类似于生活当中送外卖的例子,外卖小哥在不同时间(时间间隔很小)同一个商家往同一个地点送外卖,
字节流的方式是一笔一笔订单来回送,缓冲流的方式是外卖员一次送多笔订单的方式,可以极大的节省时间。

1、缓冲输入字节流-BufferedInputStream
缓冲字节流
1、缓冲输入字节流
BufferedInputStream
2、缓冲输出字节流
BufferedOutputStream
BufferedInputStream
使用缓冲字节流进行读取操作?
1、需要先创建一个文件输入字节流FileInputStream,指向文件对象
2、通过文件字节流创建一个缓冲输入字节流对象,指向缓冲区
3、从缓冲区读取字节数据
4、关闭资源(所有资源)
以下代码是比较了普通字节流读取文件和缓冲流读取文件的方式,或发现缓冲字节流的方式耗时要远小于普通字节流。
public static void main(String[] args) throws IOException {
FileInputStream file = new FileInputStream("D:\\caicai.jpeg");
BufferedInputStream buffer = new BufferedInputStream(file);
int a;
long start = System.currentTimeMillis();
while((a = buffer.read()) != -1) {
// System.out.println(a);
}
long end = System.currentTimeMillis();
System.out.println("缓冲字节流耗时:" + (end - start));
buffer.close();
file.close();
FileInputStream file1 = new FileInputStream("D:\\caicai.jpeg");
int b;
long start1 = System.currentTimeMillis();
while((b = file1.read()) != -1) {
// System.out.println(b);
}
long end1 = System.currentTimeMillis();
System.out.println("文件字节流耗时:" + (end1 - start1));
}
2、缓冲输出字节流-BufferedOutputStream
通过缓冲输出字节流写入数据
1、通过FileOutputStream创建一个输出字节流对象,指向要写入的文件
2、给字节流对象创建一个缓冲输出字节流对象,将字节流的数据放入缓冲区
3、对缓冲区进行写操作,往文件当中写入数据
4、刷新缓冲区flush
刷新之后,文件流或者缓冲流还可以继续进行写操作
5、关闭资源close
相当于flush然后关闭资源
注意:使用缓冲流进行写操作时,必须要flush或者close,不然数据写不进去
public static void main(String[] args) throws IOException {
FileOutputStream file = new FileOutputStream("D:\\11.txt");
BufferedOutputStream out = new BufferedOutputStream(file);
out.write("埃隆·马斯克本".getBytes());
out.flush();
out.close();
out.write(107);
out.flush();
}
1.4.5 字符输入流-Reader
字符流:
通过字符流一次可以读写一个或多个字符
字符输入流:Reader(抽象类)
read() close()
FileReader(文件字符输入流)
BufferedReader(缓冲字符输入流)
字符输出流:Writer(抽象类)
FileWriter(文件字符输出流)
BufferedWriter(缓冲字符输出流)
FileReader来实现文件读取操作
1、创建字符流对象(构造方法)
2、read()读取一个或多个字符
read()方法是将字符对应的十进制返回
read(char[] c)一次读取指定个数字符,返回实际读取的字符个数
读不到返回-1
3、关闭资源
public static void main(String[] args) throws IOException {
FileReader file = new FileReader("D:\\11.txt");
// System.out.println((char)file.read());
int aa = 0;
while((aa = file.read()) != -1) {
System.out.println((char)aa);
}
file.close();
}
1.4.6 字符输出流-Writer
字符输出流:
一次写入一个或者多个字符到文件当中
FileWriter文件字符输出流
write()写入一个或多个字符
flush()刷新
close()关闭资源
使用FileWriter向文件中写入数据:
1、创建一个文件字符输出流对象
2、write写入一个多个字符
write(int b) b是代表字符对应的整数值
write(String s) s要写入的字符串
3、flush
4、close
注意:字符流本身是使用了缓冲的机制,所以,所有的字符输出流,写操作执行完必须要
flush或者close
public static void main(String[] args) throws IOException {
//true代表是否追加的意思,也可以不写,不写默认覆盖
FileWriter file = new FileWriter("D:\\11.txt",true);
file.write("我在珠穆朗玛");
file.flush();
file.close();
}
1.4.7 缓冲字符输入流-BufferedReader
缓冲字符输入流
BufferedReader
(1)创建一个字符输入流(Reader类型的),指向当前文件
(2)给字符输入流对象创建一个缓冲流对象
(3)通过缓冲流对象对文件进行读操作
(4)关闭资源(所有资源)
public static void main(String[] args) throws IOException {
FileReader file = new FileReader("D:\\11.txt");
BufferedReader buff = new BufferedReader(file);
int a = 0;
while((a = buff.read()) != -1) {
System.out.println((char)a);
}
buff.close();
}
1.4.8 缓冲字符输出流-BufferedWriter
通过缓冲输出字符流写入数据
1、通过FileReader创建一个输出字符流对象,指向要写入的文件
2、给字符流对象创建一个缓冲输出字符流对象,将字符流的数据放入缓冲区
3、对缓冲区进行写操作,往文件当中写入数据
4、刷新缓冲区flush
刷新之后,文件流或者缓冲流还可以继续进行写操作
5、关闭资源close
相当于flush然后关闭资源
注意:使用缓冲流进行写操作时,必须要flush或者close,不然数据写不进去
public static void main(String[] args) throws IOException {
FileWriter file1 = new FileWriter("D:\\11.txt");
BufferedWriter buff = new BufferedWriter(file1);
buff.write("你好你好");
buff.flush();
buff.close();
}
1.4.9 对象流(了解)
1、对象输出流,可以将实现了Serializable接口的类实例化出来的对象保存在文件当中
如果一个类实现Serializable,代表当前类是可序列化的
那么如果这个可序列化的类当中有的属性不想让它被序列化,可以给这个属性加上transient修饰符
2、对象输出流,可以获取保存在文件当中的对象信息
3、静态变量不能被序列化
因为是对对象的序列化,静态变量与类有关,所以静态变量不会被序列化,当序列化对象还原时,静态变量会维持类中原本的样子,而不是存储 时的样子。
补充:以后遇见的类或者接口名中后缀带有able的,那么它的子类或者实现类聚会具有
某种对应的能力
Serializable序列化的能力
Compareable具有比价的能力排序的能力
Closeable具有关闭的能力
Readable读的能力
.......
以下示例通过输入输出对象流实现对象信息的保存和读取
package com.shuangti.test1;
import java.io.Serializable;
public class User implements Serializable{
String name;
transient int age;
public User(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
FileOutputStream file = new FileOutputStream("D:\\666.txt");
ObjectOutputStream objs = new ObjectOutputStream(file);
User user = new User("小明",20);
objs.writeObject(user);
objs.close();
FileInputStream in = new FileInputStream("D:\\666.txt");
ObjectInputStream objs1 = new ObjectInputStream(in);
User user1 = (User)objs1.readObject();
System.out.println(user1.getName());//输出小明
System.out.println(user1.getName());//输出0,因为age被transient修饰符修饰不能被序列化
}
1.5 多线程
1.5.1 概论:
程序:就是放在本地磁盘(ROM)当中的可行性的文件,比如exe、class文件、sh、bat脚本等。
进程:
程序一执行,进入内存(RAM),就变成了进程。程序就可以解释为进入内存的程序。
进程是资源分配的最小单位。
线程:
一个进程可以拥有多个线程,每个线程使用其所属进程的栈空间。进程实现或者完成的各种各样的任务就是线程,线程是由CPU来 统一调度的。线程是CPU调度的最小单位
java在线程、进程当中的体现
-
1、java程序一运行,其实它是开启了两个线程:
一个是main主线程,它来控制所有其他java任务的运行
一个jvm垃圾回收线程(暂时不关注)
-
2、如果没有添加线程的时候,主线程其中一个环节出现问题,后续的任务都会受到影响
-
3、如果主线程中开启了多个线程,其中某个线程出现问题,不影响其他线程的执行包括主线程
1.5.2 创建线程的常用的两种方式(重要!!)
第一种:继承Thread类
-
实例化子类,创建一个线程对象
-
调用start()方法开启线程
public class Thread1 extends Thread{
public void run() {
System.out.println(2/0);
}
}
public static void main(String[] args) {
Thred1 t1 = new Thred1();
t1.start();
//t1线程运行异常,但不影响主线程运行,依然会打印++++++
System.out.println("++++++++++");
}
第二种:实现Runnable接口(最常用)
- 1、目标类实现Runnable接口,重写run方法
-
2、实例化目标类,将实例化的对象放入Thread(使用Thread的有参构造)当中,创建一个线程对象
-
3、线程对象通过start开启线程
这种方式最常用:主要体现在接口具有多继承的特点,避免了普通类单击成的局限性
提高了代码的扩展力,降低耦合度。
public class Run1 implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() +
"===run1==========");
}
}
public static void main(String[] args) {
Run1 r1 = new Run1();
Thread t1 = new Thread(r1);
t1.start();
}
基于以上两种创建方式:使用匿名内部类的方式创建线程
public static void main(String[] args) {
new Thread() {
public void run() {
System.out.println("++++");
}
}.start();
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("===========");
}
}).start();
}
1.5.3 线程的生命周期(重要!!!!)
线程对象创建,start()方法创建线程之后,线程进入就绪状态等待cpu调度,如果线程抢到了cpu的执行权,cpu执行线程,
线程进入运行状态(执行run方法),(运行期间如果线程sleep或者wait进入阻塞状态,sleep线程会在指定时间后再次进入就绪状态
等待cpu调度,wait会等待被通知,进入就绪状态),线程运行结束对象被销毁,线程结束。
1.5.4 Thread类的属性和方法
1、属性
三个静态常量
-
MAX_PRIORITY 线程的最大优先级,为10
-
MIN_PRIORITY 最小优先级,为1
-
NORM_PRIORITY 不设置优先级,默认为5
-
注意:并不是优先级越高,线程就优先执行,只是提高了当前线程获得cpu资源的概率
public static void main(String[] args) throws InterruptedException { System.out.println(Thread.MAX_PRIORITY);//10 System.out.println(Thread.MIN_PRIORITY);//1 System.out.println(Thread.NORM_PRIORITY);//5 }
2、方法
构造方法:
- Thread() 无参构造
-
Thread(String name) 创建线程,并给线程起一个名字
-
Thread(Runnable target)传入一个可执行的目标对象(Runnable接口的实现类对象)来创建一个线程
-
Thread(Runnable target, String name)
传入一个可执行的目标对象(Runnable接口的实现类对象)来创建一个线程,同时给线程起一个名字
3、静态方法
-
static void sleep(long millis )
其中millis 单位是毫秒
休眠:让当前线程放弃cpu资源,(指定时间millis 后)进入就绪状态,等待cpu调度执行
-
static void yield()
礼让: 让出cpu资源,进入就绪状态,和其他线程争夺cpu资源
礼让不一定让成功,有可能礼让的线程还会抢到cpu资源
举例:
1、sleep()
public class Thread2 extends Thread{
public void run() {
System.out.println("Thread2执行开始.....");
for(int i = 0; i <= 100; i++) {
System.out.println("i===="+i);
try {
Thread.sleep(500);//休眠500毫秒
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("Thread2执行结束.....");
}
}
public static void main(String[] args) throws InterruptedException {
Thread2 t2 = new Thread2();
t2.start();
}
2、yield()
public class Thread3 extends Thread{
public void run() {
System.out.println("Thread3的线程名称===="+Thread.currentThread().getName());
for(int i = 0; i <= 100; i++) {
if(i == 10) {
System.out.println("我让一下.......");
Thread.yield();
}
System.out.println("Thread3=====" + i);
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread3 t3 = new Thread3();
t3.start();
}
4、实例方法
实例方法:
getName()获取当前线程的名称
主线程名字就是main
其他线程如果没有设置名称会根据线程开启的顺序设置一个默认的名称
Thread-0 Thread-1......
通过Thread.currentThread().getName()获取线程名称
getPriority()获取线程优先级
优先级可以设置,不设置默认为5
如何给线程设置优先级?setPriority(值) 值1-10
setDaemon(布尔值)设置线程是否为守护线程
isDaemon判断当前线程是不是守护线程
join()插队
如果线程抢到了cpu它会一直执行下去,直到结束,才会让给其它线程
举例:
1、设置优先级
并不是优先级越高,线程就优先执行,只是提高了当前线程获得cpu资源的概率
public class One extends Thread{
public void run() {
System.out.println("我的优先级高.....");
}
}
public static void main(String[] args) {
One one = new One();
one.setPriority(10);
one.start();
System.out.println("主线程......");
}
主线程......
我的优先级高.....
2、守护线程
通过结果发现主线程执行结束,t5线程也随之结束,不会继续执行
public class Thread5 extends Thread{
public void run() {
for(int i = 1; i <= 100; i++) {
System.out.println("我会一直陪着你....." + i);
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread5 t5 = new Thread5();
t5.setDaemon(true);
t5.start();
for(int i = 1; i <= 20; i++) {
System.out.println("主线程执行到了====="+ i);
}
}
运行结果:
主线程执行到了=====1
主线程执行到了=====2
主线程执行到了=====3
主线程执行到了=====4
主线程执行到了=====5
主线程执行到了=====6
主线程执行到了=====7
主线程执行到了=====8
主线程执行到了=====9
主线程执行到了=====10
我会一直陪着你.....1
我会一直陪着你.....2
我会一直陪着你.....3
我会一直陪着你.....4
我会一直陪着你.....5
我会一直陪着你.....6
我会一直陪着你.....7
我会一直陪着你.....8
我会一直陪着你.....9
我会一直陪着你.....10
我会一直陪着你.....11
我会一直陪着你.....12
我会一直陪着你.....13
我会一直陪着你.....14
我会一直陪着你.....15
3、join()插队
通过结果发现,插队的线程插队成功之后会直到执行结束才会让出cpu资源给其他线程
public class Thread6 extends Thread{
public void run() {
for(int i = 1; i <= 100; i++) {
System.out.println("Thread6===="+ i);
}
}
}
public static void main(String[] args) throws InterruptedException {
Thread6 t6 = new Thread6();
t6.start();
for(int i = 1; i <= 20; i++) {
if(i == 10) {
t6.join();
}
System.out.println("主线程执行到了====="+ i);
}
}
执行结果:
主线程执行到了=====1
主线程执行到了=====2
主线程执行到了=====3
主线程执行到了=====4
主线程执行到了=====5
主线程执行到了=====6
主线程执行到了=====7
主线程执行到了=====8
主线程执行到了=====9
我要插队了
Thread6====1
Thread6====2
Thread6====3
Thread6====4
Thread6====5
Thread6====6
Thread6====7
Thread6====8
Thread6====9
Thread6====10
Thread6====11
Thread6====12
Thread6====13
Thread6====14
Thread6====15
Thread6====16
Thread6====17
Thread6====18
Thread6====19
Thread6====20
主线程执行到了=====10
补充:run()和start()的区别!!!(重要)
start()和run()的区别
-
start()会开启一个线程,开辟一个新的栈内存
-
run()是一个普通方法,线程开启,等待cpu调度,cpu执行线程,会调用
相应的线程对应的run方法
举例:
public class One extends Thread{
public void run() {
System.out.println("一组擦黑板.....");
}
}
public class Two extends Thread{
public void run() {
System.out.println("二组拖地......");
}
}
public class Three extends Thread{
public void run() {
System.out.println("三组浇花.....");
}
}
public static void main(String[] args) {
One one = new One();
Two two = new Two();
Three three = new Three();
one.start();
two.start();
three.start();
System.out.println("项目经理在看书......");
}
结果:
一组擦黑板.....
三组浇花.....
项目经理在看书......
二组拖地......
public static void main(String[] args) {
One one = new One();
Two two = new Two();
Three three = new Three();
one.run();
two.run();
three.run();
System.out.println("项目经理在看书......");
}
一组擦黑板.....
二组拖地......
三组浇花.....
项目经理在看书......
通过执行结果对比发现:调用run方法遵循先进后出原则,程序按顺序进行
start方法多个线程顺序随机执行
sleep()和wait()的区别
sleep()和wait()(面试点,课下了解一下)
1、 sleep是线程中的方法,但是wait是Object中的方法。
2、 sleep方法不会释放lock,但是wait会释放,而且会加入到等待队列中。
3、 sleep方法不依赖于同步器synchronized,但是wait需要依赖synchronized关键字。
4、 sleep不需要被唤醒(休眠之后推出阻塞),但是wait需要(不指定时间需要被别人中断)。
1.5.5 多线程线程安全问题
使用synchronized关键字
多个线程在操作同一个目标对象时,会出现线程安全问题
比如抢票机制:线程1抢到cpu,卖出第10张票,还没有进行票数减一操作,然后线程2抢到cpu,线程2也会把第10张票卖出
这样就造成了数据不安全的问题。
为了避免这种线程安全的问题,可以给当前代码块枷锁,或者给一个方法枷锁
锁的是某一个对象,如果是当前对象,可以用this
synchronized(Object){
代码块
}
锁方法:
此处其实本质是也是锁的对象,因为此方法是一个实例方法,实例方法只有
实例化对象才能调用
修饰符列表 synchronized 返回类型 方法名(){
方法体
}
通过synchronized实现火车站买票的例子:
public class Station implements Runnable{
private int ticket = 10;
@Override
public void run() {
while(true) {
System.out.println(Thread.currentThread().getName()+"开始卖票....");
synchronized (this) {
if(ticket > 0) {
System.out.println(Thread.currentThread().getName() +
"得到第"+ ticket + "票");
ticket--;
}else {
System.out.println(Thread.currentThread().getName()+"结束卖票....");
break;
}
}
// boolean flag = sole();
// if(!flag) {
// break;
// }
}
}
public synchronized boolean sole() {
if(ticket > 0) {
System.out.println(Thread.currentThread().getName() +
"得到第"+ ticket + "票");
ticket--;
return true;
}else {
return false;
}
}
}
public static void main(String[] args) {
Station taiAn = new Station();
Thread t1 = new Thread(taiAn,"窗口1");
Thread t2 = new Thread(taiAn,"窗口2");
Thread t3 = new Thread(taiAn,"窗口3");
t1.start();
t2.start();
t3.start();
}
5.1多线程死锁的现象
多个线程互相持有对方的资源,去完成一项任务,陷入死等的状态,这种现象叫做死锁。
模拟了现实生活中真实存在的场景:
一部是一个线程
二部是一个线程
一部在某个时间想要进行软约彩排,需要用翻页笔和投影仪
二部在此时间想要过一下每位同学的PPT,也需要用到翻页笔和投影仪,但是翻页笔和投影仪只有一份
然而一部优先拿到了投影仪,随后二部拿到了翻页笔,之后呢一部想要去拿翻页笔,拿不到了,因为被二部抢到了,这个时候
双方陷入僵局,死等的状态,结果两个部门的任务都没有完成。
public class Run1 implements Runnable{
public String a = "投影仪";
public String b = "翻页笔";
@Override
public void run() {
if(Thread.currentThread().getName().equals("一部")) {
synchronized (a) {
System.out.println("一部拿到了投影仪.....");
synchronized (b) {
System.out.println("一部拿到了翻页笔.....");
System.out.println("软约彩排中.......");
}
}
}else {
synchronized (b) {
System.out.println("二部拿到了翻页笔.......");
synchronized (a) {
System.out.println("二部拿到了投影仪......");
System.out.println("过PPT中........");
}
}
}
}
}
public static void main(String[] args) {
Run1 r1 = new Run1();
Thread t1 = new Thread(r1,"一部");
Thread t2 = new Thread(r1,"二部");
t1.start();
t2.start();
}
课后小练习:龟兔赛跑
public class Run2 implements Runnable{
@Override
public void run() {
for(int i = 1; i <= 10000000; i++) {
if(Thread.currentThread().getName().equals("兔子")) {
if(i % 1000000 == 0) {
try {
Thread.sleep(1);
System.out.println("++++++++++");
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
System.out.println(Thread.currentThread().getName() + "到达终点.......");
}
}
public static void main(String[] args) {
Run2 r2 = new Run2();
Thread t1 = new Thread(r2,"兔子");
Thread t2 = new Thread(r2,"乌龟");
t1.start();
t2.start();
}
第四章 数据库高级
提前准备好库和表
CREATE DATABASE data_07 CHARACTER SET utf8 COLLATE utf8_general_ci;
CREATE TABLE table1(
id INT(11),
name1 VARCHAR(10)
);
CREATE TABLE A(
A_ID INT(11),
A_NAME VARCHAR(10)
);
CREATE TABLE B(
A_ID INT(11),
B_PRICE INT(11)
);
1.1表结构相关
1.1.1修改表名
语法:ALTER TABLE 旧表名 RENAME 新表名;
ALTER TABLE table1 RENAME table2;
1.1.2 修改表字段
语法1:ALTER TABLE 表名 MODIFY [COLUMN] 字段名 新数据类型 新类型长度 新默认值 新注释;
语法2:ALTER TABLE 表名 CHANGE 字段名1 字段名1 新数据类型 新类型长度 新默认值 新注释;
注意:
change和modify的区别?
- 1、modify不能修改栏位名
- 2、change和modify都可修改栏位的属性(类型长度、默认值、注释)
#修改table2中name1字段为varchar(20)
ALTER TABLE table2 MODIFY name1 VARCHAR(20);
#修改table2中id字段名改为id1
#change其实是将原来字段覆盖掉
ALTER TABLE table2 CHANGE id id1 INT(10);
#用change修改table1中name1字段为varhcar(30)
ALTER TABLE table2 CHANGE name1 name1 VARCHAR(30);
1.2.3添加表字段
语法:ALTER TABLE 表名 ADD [COLUMN] 字段名 字段类型 是否可为空 COMMENT '注释' AFTER 指定某字段 ;
其中COLUMN可不加 ,AFTER可以不指定,不指定默认放在最后
#在table2表中id1后添加新栏位age tinyint(4)
ALTER TABLE table2 ADD age TINYINT(4) AFTER id1;
ALTER TABLE table2 ADD age1 TINYINT(4);
1.2.4 删除表字段
**语法: **ALTER TABLE 表名 DROP [COLUMN] 字段名 ;
ALTER TABLE table2 DROP age1;
1.2.5 外连接
左外连接:
SELECT * FROM 表1 LEFT JOIN 表2 ON 表1.栏位名=表2.栏位名
就是以表1数据为准,如果表1中的数据关联(on)不到表2中的数据
最终查询结果集也会包含表1中关联不到的数据,表2中相关字段显示为空
右外连接:
SELECT * FROM 表1 RIGHT JOIN 表2 ON 表1.栏位名=表2.栏位名
就是以表2数据为准,如果表1中的数据关联(on)不到表2中的数据
最终查询结果集也会包含表2中关联不到的数据,表1中相关字段显示为空
SELECT a.*,b.* FROM a LEFT JOIN b ON a.A_ID=b.A_ID;
执行结果:
A_ID A_NAME A_ID B_PRICE B_NAME B_TEACHER
------ ------ ------ ------- ------ -----------
8 aaaa (NULL) (NULL) (NULL) (NULL)
1 apple 1 1000 11 11
3 peach 3 6000 66 11
7 vvv (NULL) (NULL) (NULL) (NULL)
SELECT a.*,b.* FROM a RIGHT JOIN b ON a.A_ID=b.A_ID;
1.2.6 子查询
没有固定的语法结构:
一个查询语句的结果集可以作为另一个sql的条件
具体以下为例:
#IN是存在的意思可以跟多个值
SELECT b.* FROM b WHERE b.A_ID IN (SELECT a.A_ID FROM a );
SELECT b.* FROM b WHERE b.A_ID IN (1,2,3,7,8);
#查询A表中id为B表中最大id的数据
SELECT MAX(id) FROM b;
SELECT * FROM a WHERE a.A_ID = (SELECT MAX(b.A_ID) FROM b);
#查询A表中id大于B表中最大id的数据
SELECT * FROM a WHERE a.A_ID > (SELECT MAX(b.A_ID) FROM b);
in和exists
SELECT b.* FROM b WHERE b.A_ID IN (1,2,3,7,8);
#exists也是存在的意思,了解即可
#EXISTS(SELECT a.A_ID FROM a WHERE a.A_ID = b.A_ID)结果为true或者false
#如果是true前边SELECT b.* FROM b查询到的当前数据显示,
#如果是false不显示
#这条sql是查询b表中所有数据,然后去a表中找符合条件的
#如果找到了,就将b中的数据作为结果输出,找不到就不输出
SELECT b.* FROM b WHERE
EXISTS(SELECT a.A_ID FROM a WHERE a.A_ID = b.A_ID);
1.2.7 多表联合查询
#多表联合查询,将多个表的结果合并
#union union all
#查询a表和b表中所有的id
#union(去重)
SELECT a.A_ID FROM a UNION SELECT b.A_ID FROM b;
#union all(不去重)
SELECT a.A_ID FROM a UNION ALL SELECT b.A_ID FROM b;
1.2.8 索引(非常重要)
-
一个表占的空间为500M,数据块为8KB
在没有索引时
查询表的一条记录需要全表扫描
-
读取的次数:(5001024)/(8x16) = 4000
-
16是Oracle进行全表扫描读取时,一次读取数据块个数的默认值
-
建索引的作用就是减少读磁盘的次数
什么情况下使用索引??
需要创建索引的场合
当频繁地使用某个字段作为查询条件
而且返回很小比例的行(一般小于总行数的1%)
如何使用
两个表作连接查询时,大表的连接字段要建立索引
进行多表查询时,主要有嵌套查询、排序合并和散列连接
如果没有索引,一般情况下效率为:散列连接>排序合并>嵌套查询
如果有索引,一般是嵌套查询效率最高
索引类型
- 主键索引(primary key)
- 普通索引(index)
- 唯一索引(unique)
- 组合索引
- 全文索引(fulltext)-不常用
添加主键索引
语法:ALTER TABLE 表名 ADD PRIMARY KEY (栏位名);
ALTER TABLE a ADD PRIMARY KEY(A_ID);
ALTER TABLE a ADD PRIMARY KEY(A_NAME);
添加唯一索引
语法:ALTER TABLE 表名 ADD UNIQUE(栏位名);
ALTER TABLE a ADD UNIQUE(A_NAME);
ALTER TABLE b ADD UNIQUE(B_NAME,B_TEACHER);
添加普通索引
语法:ALTER TABLE 表名 ADD INDEX(栏位名);
ALTER TABLE b ADD INDEX(B_NAME);
ALTER TABLE b ADD INDEX(B_NAME,B_TEACHER);
注意:查询中使用到了索引字段,但不一定使用到了索引,也就是存在索引失效的情况
1.列类型是字符串,查询条件未加引号。
2.使用like时通配符在前
3. 在查询条件中使用OR(要想是索引生效,需要将or中的每个列都加上索引。 )
4.对索引列进行函数运算
5.联合索引ABC问题
Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是index (a,b,c),可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c或c进行查找 。
1.2.9 视图view
视图是一个虚拟表,是sql的查询结果,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据,在使用视图时动态生成。视图的数据变化会影响到基表,基表的数据变化也会影响到视图[insert update delete ] ; 创建视图需要create view 权限,并且对于查询涉及的列有select权限;使用create or replace 或者 alter修改视图,那么还需要改视图的drop权限。
创建视图
语法: CREATE VIEW 视图名(基表查询结果);
查询视图
语法:SELECT * FROM 视图名;
删除视图
语法:DROP VIEW 视图名;
#视图
#create view 视图名(基表查询结果)
#基表的数据改变一定会更新到视图
#视图也可进行修改数据,但是并不一定能成功
#成功了则会改变基表的数据
#什么时候不会成功?
#如果基表的查询结果使用了多行进行函数运算,视图数据就不能修改
CREATE VIEW a_b AS(
SELECT a.A_ID,b.B_PRICE FROM a INNER JOIN b
ON a.A_ID = b.A_ID
);
CREATE VIEW b_1 AS(
SELECT AVG(B_PRICE) FROM b GROUP BY B_NAME
);
#视图查询
SELECT * FROM a_b;
#删除视图
DROP VIEW b_1;
1.2.10 事务
事务是将一组操作组合起来的机制
这一组操作,要么全部成功,要么全部失败
类似于生活中的转账:张三给李四转钱,张三减100,李四加100这是一组事务,要么全部成功,要么全部失败。
1. 事务的四大特性
Atomicity(原子性)
事务全部成功或者全部失败。如果其中有一个操作失败,事务中的所有操作全部回退到操作前的状态
Consistency(一致性)
事务将系统从一个一致的状态迁移到另一个一致状态
Isolation(隔离性)
访问同一资源的各个事务相互独立
Durablity(持久性)
事务一旦提交,永久生效
2、事务的隔离级别及常见的几种现象
1,脏读
脏读是指在一个事务处理过程里读取了另一个未提交的事务中的数据。
当一个事务正在多次修改某个数据,而在这个事务中这多次的修改都还未提交,
这时一个并发的事务来访问该数据,就会造成两个事务得到的数据不一致。例如:用户A向用户B转账100元,
对应SQL命令如下
update account set money=money+100 where name=’B’; (此时A通知B)
update account set money=money - 100 where name=’A’;
当只执行第一条SQL时,A通知B查看账户,B发现确实钱已到账(此时即发生了脏读),而之后无论第二条SQL是否执行,
只要该事务不提交,则所有操作都将回滚,那么当B以后再次查看账户时就会发现钱其实并没有转。
2、不可重复读
不可重复读是指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。
例如事务T1在读取某一数据,而事务T2立马修改了这个数据并且提交事务给数据库,事务T1再次读取该数据就得到了不同的结果,发送了不可重复读。
不可重复读和脏读的区别是,脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。
在某些情况下,不可重复读并不是问题,比如我们多次查询某个数据当然以最后查询得到的结果为主。但在另一些情况下就有可能发生问题,例如对于同一个数据A和B依次查询就可能不同,A和B就可能打起来了……
3、虚读(幻读)
幻读是事务非独立执行时发生的一种现象。例如事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
事务的隔离级别
- ① Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
- ② Repeatable read (可重复读):可避免脏读、不可重复读的发生。
- ③ Read committed (读已提交):可避免脏读的发生。
- ④ Read uncommitted (读未提交):最低级别,任何情况都无法保证。
3、Mysql中的事务
3.1 Mysql如何支持事务?
Mysql中常用的引擎Engine有两种Innodb和MyIsam,其中Innodb引擎才会支持事务
3.2 JDBC中如何控制事务
通常情况下我们使用JDBC连接数据库进行增删改查时,默认是把事务设置为自动提交的。
但是如果我们来实现一个现实生活中转账的例子,张三转账给李四钱的时候,程序中间报错,结果张三的钱减掉了
而李四的钱没有加上,这样就没有保证了事务的原子性。
public static void main(String[] args) {
Connection con = null;
try {
//1、装载驱动
Class.forName("com.mysql.jdbc.Driver");
//2、获得连接
con = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/data_01?characterEncoding=utf-8","root","123456");
//3、处理sql
String sql = "update account set money=money-1000 where name='张三'";
//4、执行sql
PreparedStatement pt = con.prepareStatement(sql);
pt.executeUpdate();
System.out.println(2/0);
String sql1 = "update account set money=money+1000 where name='李四'";
//4、执行sql
PreparedStatement pt1 = con.prepareStatement(sql1);
pt1.executeUpdate();
//5、释放资源
//close();
} catch (Exception e) {
e.printStackTrace();
}
}
那么如何控制避免以上这种问题呢,通过事务来控制!
第一步:关闭数据库自动提交功能
通过Connection的setAutoCommit(false);设置不自动提交
第二步:如果事务某一环节出现问题取消事务:
通过Connection的rollback()设置事务回滚
事务回滚的意思是取消当前事务,将之前准备提交的sql全部取消,当前事务不再做了。
第三步:最后手动提交事务
通过Connection的commit()手动提交
public static void main(String[] args) {
Connection con = null;
try {
//1、装载驱动
Class.forName("com.mysql.jdbc.Driver");
//2、获得连接
con = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/data_01?characterEncoding=utf-8","root","123456");
//设置取消自动提交,前提是数据库支持事务
//mysql数据库Engine设置为innodb才支持事务
con.setAutoCommit(false);
//3、处理sql
String sql = "update account set money=money-1000 where name='张三'";
//4、执行sql
PreparedStatement pt = con.prepareStatement(sql);
pt.executeUpdate();
System.out.println(2/0);
String sql1 = "update account set money=money+1000 where name='李四'";
//4、执行sql
PreparedStatement pt1 = con.prepareStatement(sql1);
pt1.executeUpdate();
//手动提交
con.commit();
//5、释放资源
//close();
} catch (Exception e) {
System.out.println("--------程序异常,事务回滚取消事务-----");
try {
//事务回滚,取消当前事务
con.rollback();
} catch (SQLException e1) {
e1.printStackTrace();
}
}
4、数据库连接池
java当中有很多池的概念:比如字符串常量池、线程池(需要自己去了解一下)、连接池等等
池:就是提前放好的资源,用的时候直接拿过来,用完了再放回去,避免频繁创建造成不必要的开销,节省时间提高效率。
数据库连接的创建比较费时
对于web应用,每个往往都对应于一次SQL操作
每个SQL操作都需要一个连接
如何复用连接?
复用方式
每次获取连接都从池中取一个
释放资源时并不真正关闭连接,而是释放到池中

以下以阿里巴巴的德鲁伊连接池为例:
import java.sql.*;
import com.alibaba.druid.pool.DruidDataSource;
public class Test02 {
public static void main(String[] args) throws SQLException {
DruidDataSource d = new DruidDataSource();
d.setDriverClassName("com.mysql.jdbc.Driver");
d.setUrl("jdbc:mysql://localhost:3306/data_02");
d.setUsername("root");
d.setPassword("123456");
d.setMaxActive(10);//设置数据库连接池最大连接数
Connection connection = d.getConnection();
System.out.println(connection);
PreparedStatement pre = connection.
prepareStatement("update goods set name=5 where id =1");
pre.executeUpdate();
}
}
第五章 Maven
1、Maven的作用
Maven 是一个项目管理工具,可以对 Java 项目进行构建、依赖管理。简单来说,就是构建项目和管理依赖,我们之前的项目都是一直在导jar包,而且会因为jar包的版本问题或者其他问题,增加了我们在jar包的使用难度,这些问题Maven都可以解决。
2、Maven的安装和配置
-
因为Maven是一个基于java的工具,所以我们先安装jdk,这个在之前就已经安装完成了,如果不确定可以查看自己的jdk版本。步骤是打开命令行输入java -version
-
解压Maven安装包,修改配置文件setting.xml
(1)修改本地仓库路径
<localRepository>自己的本地磁盘目录</localRepository>
(2)修改远程仓库
在mirrors下添加阿里云镜像
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
为什么要添加镜像??
如果仓库X可以提供仓库Y存储的所有内容,那么就可以认为X是Y的一个镜像。用过Maven的都知道,国外的中央仓库用起来太慢了,所以选择一个国内的镜像就很有必要,我推荐国内的阿里云镜像。
3、Maven常用命令
mvn clean:表示运行清理操作(会默认把target文件夹中的数据清理)。
mvn clean compile:表示先运行清理之后运行编译,会将代码编译到target文件夹中。
mvn clean test:运行清理和测试。
mvn clean package:运行清理和打包。
mvn clean install:运行清理和安装,会将打好的包安装到本地仓库中,以便其他的项目可以调用。
mvn clean deploy:运行清理和发布(发布到私服上面)。
4、什么是POM
POM( Project Object Model,项目对象模型 ) 定义了项目的基本信息,用于描述项目如何构建,声明项目依赖,等等。
-
代码的第一行是XML头,指定了该xml文档的版本和编码方式。
-
project是所有pom.xml的根元素,它还声明了一些POM相关的命名空间及xsd元素
-
根元素下的第一个子元素modelVersion指定了当前的POM模型的版本,对于Maven3来说,它只能是4.0.0
-
代码中最重要是包含了groupId,artifactId和version了。这三个元素定义了一个项目基本的坐标,在Maven的世界,任何的jar、pom或者jar都是以基于这些基本的坐标进行区分的。
-
groupId定义了项目属于哪个组,随意命名,比如谷歌公司的myapp项目,就取名为 com.google.myapp
-
artifactId定义了当前Maven项目在组中唯一的ID,比如定义hello-world。
-
version指定了项目当前的版本0.0.1-SNAPSHOT,SNAPSHOT意为快照,说明该项目还处于开发中,是不稳定的。
第一个 0 表示大版本号,第二个 0 表示分支版本号,第三个 0 表示小版本号
SNAPSHOT -- 快照版本,ALPHA -- 内侧版本,BETA -- 公测版本,RELEASE -- 稳定版本,GA -- 正式发布 -
name元素生命了一个对于用户更为友好的项目名称,虽然这不是必须的,但还是推荐为每个POM声明name,以方便信息交流
-
Maven的依赖: 坐标
dependencies元素,包括以下子元素:
groupId, artifactId, version
这三个是必须的,以下的那些子元素根据实际情况添加。
在 Maven 中坐标是构件的唯一标识,Maven 坐标的元素包括 groupId、artifactId、version、packaging、classifier。上述5个元素中,groupId、artifactId、version 是必须定义的,packaging 是可选的 ( 默认为 jar )。
groupId:组织标识,一般为:公司网址的反写+项目名
artifactId:项目名称,一般为:项目名-模块名
version:版本号
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.shuangti</groupId>
<artifactId>spring01</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>spring01</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.3.20</version>
</dependency>
</dependencies>
</project>
5、Maven依赖冲突
依赖冲突:若项目中多个 Jar 同时引用了相同的 Jar 时,会产生依赖冲突,但 Maven 采用了两种避免冲突的策略,因此在 Maven 中是不存在依赖冲突的。
短路优先
本项目——>A.jar——>B.jar——>X.jar
本项目——>C.jar——>X.jar
若本项目引用了 A.jar,A.jar 又引用了 B.jar,B.jar 又引用了 X.jar,并且 C.jar 也引用了X.jar。
在此时,Maven 只会引用引用路径最短的Jar。声明优先
若引用路径长度相同时,在pom.xml中谁先被声明,就使用谁。
第六章 Spring框架
1、Spring概述
Spring是一个开源的免费的框架(容器)!
什么是框架?框架就是一个包含接口、抽象类、实现类的类库。
Spring是一个轻量级的、非入侵式的框架!
控制反转(IOC),面向切面编程(AOP) !
支持事务的处理,对框架整合的支持!
=总结一句话: Spring就是一个轻量级的控制反转(IOC)和面向切面编程的框架!
2、SpringBoot
一个快速开发的脚手架。
基于SpringBoot可以快速的开发单个微服务。。约定大于配置!
Spring Cloud:SpringCloud是基于SpringBoot实现的。
因为现在大多数公司都在使用SpringBoot进行快速开发,学习SpringBoot的前提,需要完全掌握Spring及SpringMVC!承上启下的作用!
弊端:发展了太久之后,违背了原来的理念!配置十分繁琐,人称:"配置地狱!“
3、Spring 的本质
Spring的本质就是一个解耦的过程,Spring作为一个中间容器,来解除java中类和类之间的关联关系,降低代码的耦合度。

4、Spring的几大模块

1.Spring Core:Core封装包是框架的最基础部分,提供IOC和依赖注入特性。这里的基础概念是BeanFactory,它提供对Factory模式的经典实现来消除对程序性单例模式的需要,并真正地允许你从程序逻辑中分离出依赖关系和配置。
2.Spring Context:构建于Core封装包基础上的 Context封装包,提供了一种框架式的对象访问方法,有些象JNDI注册器。Context封装包的特性得自于Beans封装包,并添加了对国际化(I18N)的支持(例如资源绑定),事件传播,资源装载的方式和Context的透明创建,比如说通过Servlet容器。
3.Spring DAO:DAO (Data Access Object)提供了JDBC的抽象层,它可消除冗长的JDBC编码和解析数据库厂商特有的错误代码。 并且,JDBC封装包还提供了一种比编程性更好的声明性事务管理方法,不仅仅是实现了特定接口,而且对所有的POJOs(plain old Java objects)都适用。
4.Spring ORM:ORM 封装包提供了常用的“对象/关系”映射APIs的集成层。 其中包括JPA、JDO、Hibernate 和 iBatis 。利用ORM封装包,可以混合使用所有Spring提供的特性进行“对象/关系”映射,如前边提到的简单声明性事务管理。
5.Spring AOP:Spring的 AOP 封装包提供了符合AOP Alliance规范的面向方面的编程实现,让你可以定义,例如方法拦截器(method-interceptors)和切点(pointcuts),从逻辑上讲,从而减弱代码的功能耦合,清晰的被分离开。而且,利用source-level的元数据功能,还可以将各种行为信息合并到你的代码中。
6.Spring Web:Spring中的 Web 包提供了基础的针对Web开发的集成特性,例如多方文件上传,利用Servlet listeners进行IOC容器初始化和针对Web的ApplicationContext。当与WebWork或Struts一起使用Spring时,这个包使Spring可与其他框架结合。
7.Spring Web MVC:Spring中的MVC封装包提供了Web应用的Model-View-Controller(MVC)实现。Spring的MVC框架并不是仅仅提供一种传统的实现,它提供了一种清晰的分离模型,在领域模型代码和Web Form之间。并且,还可以借助Spring框架的其他特性。
5、IOC本质
控制反转loC(Inversion of Control),是一种设计思想,DI(依赖注入)是实现loC的一种方法,也有人认为DI只是loC的另一种说法。没有loC的程序中,我们使用面向对象编程,对象的创建与对象间的依赖关系完全硬编码在程序中,对象的创建由程序自己控制,控制反转后将对象的创建转移给第三方,个人认为所谓控制反转就是:获得依赖对象的方式反转了。
采用XML方式配置Bean的时候,Bean的定义信息是和实现分离的,而采用注解的方式可以把两者合为一体,Bean的定义信息直接以注解的形式定义在实现类中,从而达到了零配置的目的。
控制反转是一种通过描述(XML或注解)并通过第三方去生产或获取特定对象的方式。在Spring中实现控制反转的是loC容器,其实现方法是依赖注入(Dependency Injection,Dl).
SpringCloud是基于SpringBoot实现的。
因为现在大多数公司都在使用SpringBoot进行快速开发,学习SpringBoot的前提,需要完全掌握Spring及SpringMVC!承上启下的作用!
弊端:发展了太久之后,违背了原来的理念!配置十分繁琐,人称:"配置地狱!“
采用XML方式配置Bean的时候,Bean的定义信息是和实现分离的,而采用注解的方式可以把两者合为一体,Bean的定义信息直接以注解的形式定义在实现类中,从而达到了零配置的目的.
控制反转是一种通过描述(XML或注解)并通过第三方去生产或获取特定对象的方式。在Spring中实现控制反转的是loC容器,其实现方法是依赖注入(Dependency Injection,DI).
loC是Spring框架的核心内容,使用多种方式完美的实现了loC,可以使用AMLEo,也可以使用注解,新版本的Spring也可以零配置实现loC.
Spring容器在初始化时先读取配置文件,根据配置文件或元数据创建与组织对象存入容器中,程序使用时再从loc容器中取出需要的对象。
6、IOC实现原理
IOC实现是基于工厂模式和反射机制实现的。
(1) BeanFactory:IOC 容器基本实现,是Spring内部的使用接口,不提供开发人员进行使用·*加载配置文件时候不会创建对象,在获取对象(使用》才去创建对象
(2)AoplicationContext:BeanFactory接口的子接口,提供更多更强大的功能,一般由开发人员进行使用
加载配置文件时候就会把在配置文件对象进行创建
ApplicationContext接口有实现类
超ApplicationContext (org.springframework.contexct)aConfiqurableApplicationContext lorg.springfram
通过以下例子来体会一下:
UserDao和UserService之间耦合度非常高,一旦业务改变,牵一发而动全身。
public class UserDao {
public void test() {
System.out.println("test......");
}
}
public class UserService {
public void m1() {
UserDao ud = new UserDao();
ud.test();
}
}
public class Test01 {
public static void main(String[] args) {
UserService us = new UserService();
us.m1();
}
}
先在通过UserService和UserDao之间加一个工厂类:通过工厂类,如果以后需要对象直接从工厂当中拿就可以了,这样
就把UserDao和UserService做了一个解耦的操作。
public class UserDao {
public void test() {
System.out.println("test......");
}
}
public void m1() {
UserDao ud = Factory.getDao();
ud.test();
}
public class Factory {
public static UserDao getDao() {
return new UserDao();
}
}
public class Test01 {
public static void main(String[] args) {
UserService us = new UserService();
us.m1();
}
}
Spring的本质就是一个工厂类,然后工厂类通过配置文件加反射机制来创建对象的。
反射机制
public static void main(String[] args) throws ClassNotFoundException, InstantiationException, IllegalAccessException {
//获取了类对应的信息,然后根据此信息就可以获取一个此类对应的实例
//这种实现方式就是反射机制
Class clazz = Class.forName("com.shuangti.spring01.User");
User user = (User)clazz.newInstance();
System.out.println(user);
}
那么Spring当中是如何体现反射机制的呢??
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="user" class="com.shuangti.spring01.User" scope="singleton">
</bean>
</beans>
public static void main(String[] args) throws ClassNotFoundException, InstantiationException, IllegalAccessException {
// ApplicationContext是Spring容器,此行代码的意思是加载Spring容器,初始化
// 初始化时给xml配置文件中的bean创建一个实例对象,通过bean元素的类信息然后通过反射机制创建的实例
// BeanFactory bf = new ClassPathXmlApplicationContext("beans.xml");
ApplicationContext bf = new ClassPathXmlApplicationContext("beans.xml");
}
7、依赖注入
依赖注入 (DI) 是一个过程,其实就是在spring容器初始化创建实例对象的同时给对象进行属性的设置。
这个过程基本上是 bean 本身通过使用直接构造方法来控制其依赖项的实例化或位置的逆过程(因此称为控制反转)。
1、什么是Bean?
bean是Spring框架中的概念,通过Spring容器或者工厂创建的对象统称为bean
spring当中创建的bean默认是单例的,当然也可通过scope属性设置为非单例的。
2、Spring配置文件详解
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd">
<!--bean
spring创建的对象统称为bean
User user = new User();
id相当于对象变量名
class值为全限定类名:包名+类名
scope: 两个值
singleton单例(spring默认),此bean只会创建一个实例对象
prototype多例子,每获取一次bean就会new一个新对象
lazy-init:false 默认懒加载,spring容器(工厂)初始化时就会
创建该对象
true 初始化时不会创建对象,在获取对象的时候才会创建
用的时候在创建,不用就不创建了
-->
<bean id="user" class="com.shuangti.spring01.User" scope="singleton" lazy-init="false">
</bean>
</beans>
此xml中配置的bean其实就是相当spring容器一初始化,就帮我们创建了一个user对象,我们后续在使用的时候从容器当中获取就可以了
具体怎么获取呢??以下为例
public static void main(String[] args) {
ApplicationContext bf = new ClassPathXmlApplicationContext("beans.xml");
//getBean对应的是xml当中的id值
User user = (User)bf.getBean("user");
}
8、依赖注入的几种方式
1、Setter注入
bean对应的类当中要实现了get和set方法,setter注入本质是调用了类当中的set方法进行值的注入的
public class Student {
private String name;
private int age;
private User user;
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Student() {
}
public Student(String name, int age, User user) {
this.name = name;
this.age = age;
this.user = user;
}
}
}
<bean id="user1" class="com.shuangti.spring01.User" >
</bean>
<bean id="stu" class="com.shuangti.spring01.Student">
<!-- 1、setter注入
name对应属性名
value对应属性值
-->
<property name="name" value="张三"></property>
<property name="age" value="20"></property>
<!-- 3、bean注入,ref指向对应属性类型的bean的id值 -->
<property name="user" ref="user1"></property>
</bean>
以上配置等价于以下过程:
public static void main(String[] args) {
/*
* 等价于
* <bean id="user1" class="com.shuangti.spring01.User" lazy-init="true"></bean>
* */
User user1 = new User();
/*
* 等价于
* <bean id="stu" class="com.shuangti.spring01.Student"></bean>
* */
Student stu = new Student();
/*
* 等价于
* <property name="name" value="张三"></property>
* */
stu.setName("张三");
/*
* 等价于
* <property name="age" value="20"></property>
* */
stu.setAge(20);
/*
* 等价于
* <property name="user" ref="user1"></property>
* */
stu.setUser(user1);
}
2、构造器注入
构造器本质是调用了类当中的有参构造方法进行值的注入的
<bean id="user2" class="com.shuangti.spring01.User" >
</bean>
<bean id="stu1" class="com.shuangti.spring01.Student">
<!-- 2、构造器注入,调用有参构造方法,进行注入 -->
<!-- 2、index是属性在有参构造方法中的顺序,value是对应的属性的值 -->
<constructor-arg index="0" value="李四"></constructor-arg>
<constructor-arg index="1" value="30"></constructor-arg>
<!-- ref值进行bean的注入,用来指向对应的bean的id值 -->
<constructor-arg index="2" ref="user2"></constructor-arg>
</bean>
public static void main(String[] args) {
/*
* 等价于
* <bean id="user1" class="com.shuangti.spring01.User" lazy-init="true"></bean>
* */
User user1 = new User();
/*
* 等价于
*
<bean id="stu1" class="com.shuangti.spring01.Student">
<constructor-arg index="0" value="李四"></constructor-arg>
<constructor-arg index="1" value="30"></constructor-arg>
<constructor-arg index="2" ref="user2"></constructor-arg>
</bean>
* */
Student stu = new Student("李四",30,user1);
}
3、list、set、map、数组类型的属性值注入
public class Student {
private String name;
private int age;
private User user;
private String[] hobbys;
private Set<String> ad;
private Map<String, String> descibe;
public String[] getHobbys() {
return hobbys;
}
public void setHobbys(String[] hobbys) {
this.hobbys = hobbys;
}
public Set<String> getAd() {
return ad;
}
public void setAd(Set<String> ad) {
this.ad = ad;
}
public Map<String, String> getDescibe() {
return descibe;
}
public void setDescibe(Map<String, String> descibe) {
this.descibe = descibe;
}
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
public String getName() {
return name;
}
public void setName(String name) {
System.out.println("++++++++++");
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Student() {
System.out.println("============");
}
public Student(String name, int age, User user) {
System.out.println("有参构造...........");
this.name = name;
this.age = age;
this.user = user;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + ", user=" + user + ", hobbys=" + Arrays.toString(hobbys)
+ ", ad=" + ad + ", descibe=" + descibe + "]";
}
}
<bean id="user2" class="com.shuangti.spring01.User" ></bean>
<bean id="stu2" class="com.shuangti.spring01.Student">
<property name="name" value="王五"></property>
<property name="age" value="60"></property>
<property name="user" ref="user2"></property>
<property name="hobbys">
<array>
<value>抽烟</value>
<value>喝酒</value>
</array>
</property>
<property name="ad">
<set>
<value>唱歌</value>
<value>跳舞</value>
</set>
</property>
<property name="descibe">
<map>
<entry key="183" value="70"></entry>
<entry key="190" value="90"></entry>
</map>
</property>
</bean>
测试类:
public static void main(String[] args) {
ApplicationContext app = new ClassPathXmlApplicationContext("beans.xml");
Student stu2 = (Student)app.getBean("stu2");
System.out.println(stu2);
}
打印结果:
Student [name=王五, age=60, user=com.shuangti.spring01.User@1e965684, hobbys=[抽烟, 喝酒], ad=[唱歌, 跳舞], descibe={183=70, 190=90}]
4、自动装配(自动注入)
根据指定装配规则(属性名称或者属性类型),Spring自动将匹配的属性值进行注入。
<bean id="student" class="com.shuangti.spring02.entity.Student">
<property name="name" value="张三"></property>
</bean>
<bean id="stuService" class="com.shuangti.spring02.service.StuService" autowire="byName">
</bean>
bean标签中有一个属性autowire
自动注入的意思
它有两个值:byName、byType
--byName是跟具类当中的属性名自动查找spring容器中的bean,如果找到了,会帮我们自动注入到加了此属性的bean当中
--byType是根据属性的类型在spring容器当中查找对应类型的bean,如果找到了并且一个对应类型的(它不会关心bean的id名),
如果只有一个就自动注入成功,如果找到多个,就失败了,报错
--通过注解实现自动注入@Autowired
5、基于注解的Spring开发
1、什么是注解?
(1)注解是代码特殊标记,格式:@注解名称(属性名称=属性值,属性名称=属性值)
比如@Component(value="user") @Service @Controller 等等
(2)使用注解,注解作用在类上面,方法上面,属性上面
(3)使用注解目的:简化xml配置
2、在Spring中使用注解?
方式一:使用配置文件+注解的方式
常用的注解:
bean注解:
@Component(value="user") 可以将此注解加在类上,然后此类就归Spring来管理,相当于在Spring容器当中创建了一个bean
括号和value可不加,不加的话默认bean的名称为类名并且类名的首字母小写
@Controller、@Service @Repository是@Component的衍生注解和@Component是等价的都是加在类上
相当于在spring容器中配置了一个bean
属性注入注解:
@Autowired自动注入加在属性上,相当于配置文件中bean标签的autowire属性
@Value("值")属性值注入,可以注入基本数据类型和字符串值,相当于
小结
我想要将一个类交给spring来管理(创建一个bean)该如何选择注解呢?
@Component所有想要交给spring管理的类都可以用这个
但是如果业务进行了分层,可以用具体的注解(Component的衍生注解)
使用MVC三层架构对项目进行分层的时候:
service层的类就用@Service
dao层就用@Repository
controller层就用@Controller
如果有一些类不知道该属于哪一层,但是我也想让它交给spring管理,统一用@Component注解就可以
使用步骤:
1、在spring配置文件中开启组件扫描,指定扫描哪个包下的类,只有指定的包下的类添加了注解才会生效
2、在相应的包下类添加注解
3、编写测试类
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
https://www.springframework.org/schema/context/spring-context.xsd">
<!--开启组件扫描
base-package属性对应的值是要扫描的包下的所有内容
只有对应的包下的类、方法、属性添加了注解才会生效
-->
<context:component-scan base-package="com.shuangti.spring02"></context:component-scan>
</beans>
在相应的类上添加注解
/*
* 往spring容器当中放入一个user对象
* */
/*
* @Component等价于在spring配置文件中添加了一个
* <bean id="user" class="com.shuangti.spring02.entity.User"></bean>
* */
/*
* 1、@Component在spring容器当中添加的bean默认名称是类名首字母小写
* 2、通过@Component的属性value可以给bean起别名
* */
@Component(value="user1")
//@Scope(value="prototype")
public class User {
public User() {
System.out.println("无参构造......");
}
}
@Component
public class Blog {
@Value("博客内容")
/*
* <property name="content" value="博客内容"></property>
* */
private String content;
@Override
public String toString() {
return "Blog [content=" + content + "]";
}
}
@Service
public class BlogService {
/*
* 自动装配(注入),它也有属性:byName,byType
* 默认是byName
* 相当于:
* <bean id="blogService" class="com.shuangti.spring02.service.BlogService" autowire="byType">
* </bean>
*
* */
@Autowired
private Blog blog;
@Override
public String toString() {
return "BlogService [blog=" + blog + "]";
}
}
public class Test03 {
public static void main(String[] args) {
ApplicationContext app = new ClassPathXmlApplicationContext("bean1.xml");
BlogService bs = (BlogService)app.getBean("blogService");
System.out.println(bs);
}
}
使用完全注解开发(配置类)
步骤:
1、编写配置类
2、添加注解
3、编写测试类
/*
* @Configuration+@ComponentScan
* 代替了springxml配置文件
* @ComponentScan相当于 <context:component-scan base-package="com.shuangti.spring02">
* </context:component-scan>
*
* */
@Configuration
@ComponentScan(basePackages="com.shuangti.spring02.dao")
public class SpringConfig {
}
@Repository
public class UserDao {
}
public class Test04 {
public static void main(String[] args) {
//使用注解类初始化spring容器而不是原来的配置文件了
ApplicationContext app =
new AnnotationConfigApplicationContext(SpringConfig.class);
UserDao ud = (UserDao)app.getBean("userDao");
System.out.println(ud);
}
}
9、AOP
1、概述
Spring 的关键组件之一是 AOP 框架。虽然 Spring IoC 容器不依赖 AOP(这意味着如果您不想使用 AOP,则无需使用 AOP),AOP 补充了 Spring IoC 以提供非常强大的中间件解决方案。
1)让切面功能复用
2)让开发人员专注业务逻辑。提高开发效率
3)实现业务功能和其他非业务功能解耦合。
4)给存在的业务方法,增加功能,不用修改原来的代码
2、实现原理
1、代理模式
它是Spring AOP的底层实现机制
在 Spring Framework 中,AOP 代理是 JDK 动态代理或 CGLIB 代理
2、角色分析
抽象角色:一般会使用抽象类或接口来解决
真实角色:被代理的角色
代理角色:代理真实角色,代理真实角色后会做一些附属操作
客户:访问代理对象的人
3、代理的好处:
可以使真是角色更加纯粹不需要添加一些公共的业务
公共业务交给代理角色,实现业务分工
公共业务发生扩展的时候,方便集中管理
比如随着社会的发展,社会中就出现了各种各样的代理,比如房产中介、婚庆公司、黄牛抢票等等,之所以有这些代理的产生,就是因为
被代理的对象有一些业务不想要自己去完成,或者不是他本身必须要完成的业务,然后被代理对象只需付出一点小小的代价就可以把这些业务交给代理来完成。
那么在Java当中也是存在这种机制,在一些类当中有一些业务并不是它的核心业务比如方法前后添加日志功能,这些非必须业务不需要此类来完成,然后就可以为此类创建一个代理对象,然后Spring框架中AOP就是帮我们解决了这些类似的问题。
静态代理:
代码步骤
(1)实现接口
public interface Rent {
void rent();
}
(2)真实角色
public class Host implements Rent{
public void rent() {
System.out.println("房东出租房子......");
}
}
(3)代理角色
public class Proxy {
private Rent rent;
public Rent getRent() {
return rent;
}
public void setRent(Rent rent) {
this.rent = rent;
}
public void rentPoxy() {
rent.rent();
look();
sign();
money();
}
public void look() {
System.out.println("带租客看房子.....");
}
public void sign() {
System.out.println("签合同.......");
}
public void money() {
System.out.println("收房租.......");
}
}
(4)客户端访问代理
public class Test01 {
public static void main(String[] args) {
Host host = new Host();
Proxy proxy = new Proxy();
proxy.setRent(cm);
proxy.rentPoxy();
}
}
动态代理:
和静态代理的角色一样,只不过动态代理的类是动态生成的,不是我们直接写好的
基于接口的动态代理-JDK代理
目标类要实现同一接口
代理类实现InvocationHandler接口
基于类的代理-Cglib代理
cglib是针对类实现代理,主要是对指定的类生成一个子类,覆盖其中的方法。
通过MethodInterceptor实现
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
public class ProxyHandler implements InvocationHandler {
private Object target;
public void setObj(Object target) {
this.target = target;
}
public Object getProxy() {
return Proxy.newProxyInstance(this.getClass().getClassLoader(),
target.getClass().getInterfaces(), this);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
System.out.println(method.getName());
Object obj = method.invoke(target, args);
return obj;
}
}
public class Test {
public static void main(String[] args) {
ServiceImpl service = new ServiceImpl();
ProxyHandler handler = new ProxyHandler();
handler.setObj(service);
Service host1 = (ServiceImpl)handler.getProxy();
host1.run();
}
}
3、AOP相关的几个术语
-
通知(Advice)包含了需要用于多个应用对象的横切行为,完全听不懂,没关系,通俗一点说就是定义了“什么时候”和“做什么”。
通知的五种分类:
before 前置通知
在方法执行前执行。如果方法出现异常也会执行。
after 后置通知
后置通知在方法执行完毕后执行,如果方法出现异常也会执行。
afterReturning 返回后通知
返回后通知是在方法正常返回后执行,如果方法出现异常不会执行
afterThrowing 抛出异常后通知
抛出异常后通知是在方法抛出异常后执行,不抛异常不执行。
around 环绕通知
环绕通知是在方法前后分别执行,可以控制方法的执行。
- 连接点(Join Point)是程序执行过程中能够应用通知的所有点。
-
切点(Poincut)是定义了在“什么地方”进行切入,哪些连接点会得到通知。显然,切点一定是连接点。
-
切面(Aspect)是通知和切点的结合。通知和切点共同定义了切面的全部内容——是什么,何时,何地完成功能。
-
引入(Introduction)允许我们向现有的类中添加新方法或者属性。
-
织入(Weaving)是把切面应用到目标对象并创建新的代理对象的过程,分为编译期织入、类加载期织入和运行期织入。
4、AOP基于注解实现
pom引入依赖
<!-- https://mvnrepository.com/artifact/org.aspectj/aspectjweaver -->
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.9.9.1</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.3.20</version>
</dependency>
spring配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop https://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="com.shuangti"></context:component-scan>
<aop:aspectj-autoproxy/>
</beans>
定义目标代理类
public interface UserService {
void add();
void delete();
}
@Service
public class UserServiceImpl implements UserService{
@Autowired
private UserDao userDao;
public void add() {
userDao.add();
}
public void delete() {
userDao.delete();
}
}
定义切面:
切点执行表达式:
execution(modifiers-pattern? ret-type-pattern declaring-type-pattern? name-pattern(param-pattern) throws-pattern?)
修饰符匹配(modifier-pattern?)
返回值匹配(ret-type-pattern)可以为*表示任何返回值,全路径的类名等
类路径匹配(declaring-type-pattern?)
方法名匹配(name-pattern)可以指定方法名 或者 代表所有, set 代表以set开头的所有方法
参数匹配((param-pattern))可以指定具体的参数类型,多个参数间用“,”隔开,各个参数也可以用“”来表示匹配任意类型的参数,如 (String)表示匹配一个String参数的方法;(,String) 表示匹配有两个参数的方法,第一个参数可以是任意类型,而第二个参数是 String类型;可以用(…)表示零个或多个任意参数
异常类型匹配(throws-pattern?)
其中后面跟着“?”的是可选项
//@Aspect将当前类设置为切面
//一个切面包含通知和切点
//@Before-方法执行前 @After-方法执行后
//切点--要切入的方法(表达式)
@Aspect
@Component
public class Cut {
//前置通知
//给UserserviceImpl下的所有方法调用前添加一个打印记录
//execution(表达式)
//表示的是一个切点,这个切点指向的是对应表达式的方法
@Before("execution(* com.shuangti.spring03.service.impl.UserServiceImpl.*(..))")
public void before() {
System.out.println("要切入的方法执行前.......");
}
//后置通知
@After("execution(* com.shuangti.spring03.service.impl.UserServiceImpl.*(..))")
public void after() {
System.out.println("要切入的方法执行后.......");
}
//环绕通知
@Around("execution(* com.shuangti.spring03.service.impl.UserServiceImpl.*(..))")
public void around(ProceedingJoinPoint point){
System.out.println("环绕前......");
try {
point.proceed();
} catch (Throwable e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("环绕后......");
}
}
定义通知
public class Test02 {
public static void main(String[] args) {
//调用Service的add方法 delete方法
ApplicationContext app = new ClassPathXmlApplicationContext("bean.xml");
UserService us = (UserService)app.getBean("userServiceImpl");
us.add();
us.delete();
}
}
第七章 SpringMVC框架
1、什么是MVC
- MVC是模型(Model)、视图(View)、控制器(Controller)的简写,是一种软件设计规范。
- 是将业务逻辑、数据、显示分离的方法来组织代码。
- MVC主要作用是降低了视图与业务逻辑间的双向偶合。
- MVC不是一种设计模式,MVC是一种架构模式。当然不同的MVC存在差异。
Model(模型):数据模型,提供要展示的数据,因此包含数据和行为,可以认为是领域模型或JavaBean组件(包含数据和行为),不过现在一般都分离开来:Value Object(数据Dao) 和 服务层(行为Service)。也就是模型提供了模型数据查询和模型数据的状态更新等功能,包括数据和业务。
View(视图):负责进行模型的展示,一般就是我们见到的用户界面,客户想看到的东西。
Controller(控制器):接收用户请求,委托给模型进行处理(状态改变),处理完毕后把返回的模型数据返回给视图,由视图负责展示。 也就是说控制器做了个调度员的工作。
最典型的MVC就是JSP + servlet + javabean的模式。
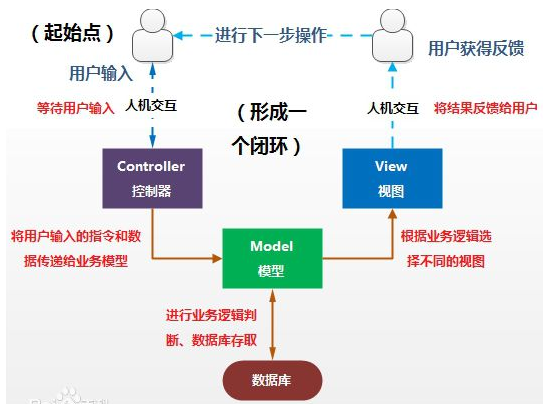
职责分析:
Controller:控制器
- 取得表单数据
- 调用业务逻辑
- 转向指定的页面
Model:模型
- 业务逻辑
- 保存数据的状态
View:视图
- 显示页面
MVC框架要做哪些事情
- 将url映射到java类或java类的方法 .
- 封装用户提交的数据 .
- 处理请求—调用相关的业务处理—封装响应数据 .
- 将响应的数据进行渲染 . jsp / html 等表示层数据 .
说明:
常见的服务器端MVC框架有:Struts、Spring MVC、ASP.NET MVC、Zend Framework、JSF;
常见前端MVC框架:vue、angularjs、react、backbone;
由MVC演化出了另外一些模式如:MVP、MVVM 等等….
我们为什么要学习SpringMVC呢?
Spring MVC的特点:
- 轻量级,简单易学
- 高效 , 基于请求响应的MVC框架
- 与Spring兼容性好,无缝结合
- 约定优于配置
- 功能强大:RESTful、数据验证、格式化、本地化、主题等
- 简洁灵活
Spring的web框架围绕DispatcherServlet [ 调度Servlet ] 设计。
DispatcherServlet的作用是将请求分发到不同的处理器。从Spring 2.5开始,使用Java 5或者以上版本的用户可以采用基于注解形式进行开发,十分简洁;
正因为SpringMVC好 , 简单 , 便捷 , 易学 , 天生和Spring无缝集成(使用SpringIoC和Aop) , 使用约定优于配置 . 能够进行简单的junit测试 . 支持Restful风格 .异常处理 , 本地化 , 国际化 , 数据验证 , 类型转换 , 拦截器 等等……所以我们要学习 .
最重要的一点,用的人多 ,技术问题解决快,使用的公司多 .
2、什么是SpringMVC
Spring MVC是Spring Framework的一部分,是基于Java实现MVC的轻量级Web框架。
2.1 我们为什么要学习SpringMVC呢?
Spring MVC的特点:
- 轻量级,简单易学
- 高效 , 基于请求响应的MVC框架
- 与Spring兼容性好,无缝结合
- 约定优于配置
- 功能强大:RESTful、数据验证、格式化、本地化、主题等
- 简洁灵活
Spring的web框架围绕DispatcherServlet [ 调度Servlet ] 设计。
DispatcherServlet的作用是将请求分发到不同的处理器。从Spring 2.5开始,使用Java 5或者以上版本的用户可以采用基于注解形式进行开发,十分简洁;
正因为SpringMVC好 , 简单 , 便捷 , 易学 , 天生和Spring无缝集成(使用SpringIoC和Aop) , 使用约定优于配置 . 能够进行简单的junit测试 . 支持Restful风格 .异常处理 , 本地化 , 国际化 , 数据验证 , 类型转换 , 拦截器 等等……所以我们要学习 .
最重要的一点,用的人多 ,技术问题解决快,使用的公司多 .
2.2 中心控制器 DispatcherServlet
Spring的web框架围绕DispatcherServlet设计。 DispatcherServlet的作用是将请求分发到不同的处理器。从Spring 2.5开始,使用Java 5或者以上版本的用户可以采用基于注解的controller声明方式。
Spring MVC框架像许多其他MVC框架一样, 以请求为驱动 , 围绕一个中心Servlet分派请求及提供其他功能,DispatcherServlet是一个实际的Servlet (它继承自HttpServlet 基类)。
SpringMVC的原理如下图所示:
当发起请求时被前置的控制器拦截到请求,根据请求参数生成代理请求,找到请求对应的实际控制器,控制器处理请求,创建数据模型,访问数据库,将模型响应给中心控制器,控制器使用模型与视图渲染视图结果,将结果返回给中心控制器,再将结果返回给请求者。
2.3 SpringMVC执行原理

图为SpringMVC的一个较完整的流程图,实线表示SpringMVC框架提供的技术,不需要开发者实现,虚线表示需要开发者实现。
简要分析执行流程
- DispatcherServlet表示前置控制器,是整个SpringMVC的控制中心。用户发出请求,DispatcherServlet接收请求并拦截请求。
我们假设请求的url为 : http://localhost:8080/SpringMVC/hello
如上url拆分成三部分:
SpringMVC部署在服务器上的web站点
hello表示控制器
通过分析,如上url表示为:请求位于服务器localhost:8080上的SpringMVC站点的hello控制器。
- HandlerMapping为处理器映射。DispatcherServlet调用HandlerMapping,HandlerMapping根据请求url查找Handler。
- HandlerExecution表示具体的Handler,其主要作用是根据url查找控制器,如上url被查找控制器为:hello。
- HandlerExecution将解析后的信息传递给DispatcherServlet,如解析控制器映射等。
- HandlerAdapter表示处理器适配器,其按照特定的规则去执行Handler。
- Handler让具体的Controller执行。
- Controller将具体的执行信息返回给HandlerAdapter,如ModelAndView。
- HandlerAdapter将视图逻辑名或模型传递给DispatcherServlet。
- DispatcherServlet调用视图解析器(ViewResolver)来解析HandlerAdapter传递的逻辑视图名。
- 视图解析器将解析的逻辑视图名传给DispatcherServlet。
- DispatcherServlet根据视图解析器解析的视图结果,调用具体的视图。
- 最终视图呈现给用户。
在这里先听一遍原理,不理解没有关系,我们马上来写一个对应的代码实现大家就明白了,如果不明白,那就写10遍,没有笨人,只有懒人!
3、创建第一个SpringMVC项目
第一步:通过Maven使用模板创建一个web项目springMvc01
第二步:在pom.xml文件引入相关的依赖:主要有Spring框架核心库、Spring MVC、servlet , JSTL等
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>4.0.1</version>
</dependency>
<dependency>
<groupId>javax.servlet.jsp.jstl</groupId>
<artifactId>jstl</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>javax.servlet.jsp.jstl</groupId>
<artifactId>jstl-api</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>org.glassfish.web</groupId>
<artifactId>jstl-impl</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.3.20</version>
</dependency>
第三步:配置web.xml
注意点:
- 注意web.xml版本问题,要最新版!
- 注册DispatcherServlet
- 关联SpringMVC的配置文件
- 启动级别为1
- 映射路径为 / 【不要用/*,会404】
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd"
id="WebApp_ID" version="3.1">
<!--1.注册servlet-->
<servlet>
<servlet-name>SpringMVC</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<!--通过初始化参数指定SpringMVC配置文件的位置,进行关联-->
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:springmvc-servlet.xml</param-value>
</init-param>
<!-- 启动顺序,数字越小,启动越早 -->
<load-on-startup>1</load-on-startup>
</servlet>
<!--所有请求都会被springmvc拦截 -->
<servlet-mapping>
<servlet-name>SpringMVC</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
</web-app>
/ 和 /* 的区别:
< url-pattern > / </ url-pattern >不会匹配到.jsp, 只针对我们编写的请求;
即:.jsp 不会进入spring的 DispatcherServlet类 。
< url-pattern > / *</ url-pattern > 会匹配* .jsp,
会出现返回 jsp视图 时再次进入spring的DispatcherServlet 类,导致找不到对应的controller所以报404错。
第四步:添加Spring MVC配置文件
- 让IOC的注解生效
- 静态资源过滤 :HTML . JS . CSS . 图片 , 视频 …..
- MVC的注解驱动
- 配置视图解析器
在resource目录下添加springmvc-servlet.xml配置文件,配置的形式与Spring容器配置基本类似,为了支持基于注解的IOC,设置了自动扫描包的功能,具体配置信息如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:mvc="http://www.springframework.org/schema/mvc"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
https://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/mvc
https://www.springframework.org/schema/mvc/spring-mvc.xsd">
<!-- 自动扫描包,让指定包下的注解生效,由IOC容器统一管理 -->
<context:component-scan base-package=""/>
<!-- 让Spring MVC不处理静态资源 -->
<mvc:default-servlet-handler />
<!--
支持mvc注解驱动
在spring中一般采用@RequestMapping注解来完成映射关系
要想使@RequestMapping注解生效
必须向上下文中注册DefaultAnnotationHandlerMapping
和一个AnnotationMethodHandlerAdapter实例
这两个实例分别在类级别和方法级别处理。
而annotation-driven配置帮助我们自动完成上述两个实例的注入。
-->
<mvc:annotation-driven />
<!-- 视图解析器 -->
<bean class="org.springframework.web.servlet.view.InternalResourceViewResolver"
id="internalResourceViewResolver">
<!-- 前缀 -->
<property name="prefix" value="/WEB-INF/jsp/" />
<!-- 后缀 -->
<property name="suffix" value=".jsp" />
</bean>
</beans>
在视图解析器中我们把所有的视图都存放在/WEB-INF/目录下,这样可以保证视图安全,因为这个目录下的文件,客户端不能直接访问。
第五步:
编写一个Java控制类: com.shuangti.controller.HelloController , 注意编码规范
@Controller
@RequestMapping("/hello")
public class HelloController {
//真实访问地址 : 项目名/HelloController/hello
@RequestMapping("/say")
public String sayHello(Model model){
//向模型中添加属性msg与值,可以在JSP页面中取出并渲染
model.addAttribute("msg","hello,SpringMVC");
//web-inf/jsp/hello.jsp
return "hello";
}
}
- @Controller是为了让Spring IOC容器初始化时自动扫描到;
- @RequestMapping是为了映射请求路径,这里因为类与方法上都有映射所以访问时应该是/HelloController/hello;
- 方法中声明Model类型的参数是为了把Action中的数据带到视图中;
- 方法返回的结果是视图的名称hello,加上配置文件中的前后缀变成WEB-INF/jsp/hello.jsp。
第六步:创建视图层
在WEB-INF/ jsp目录中创建hello.jsp , 视图可以直接取出并展示从Controller带回的信息;
可以通过EL表示取出Model中存放的值,或者对象;
<%@ page contentType="text/html;charset=UTF-8" language="java" %>
<html>
<head>
<title>SpringMVC</title>
</head>
<body>
${msg}
</body>
</html>
第七步:
访问项目路径:
127.0.0.1:8080/springMvc01/hello/say
OK,运行成功!
小结
实现步骤其实非常的简单:
- 新建一个web项目
- 导入相关jar包
- 编写web.xml , 注册DispatcherServlet
- 编写springmvc配置文件
- 接下来就是去创建对应的控制类 , controller
- 最后完善前端视图和controller之间的对应
- 测试运行调试.
使用springMVC必须配置的三大件:
处理器映射器、处理器适配器、视图解析器
通常,我们只需要手动配置视图解析器,而处理器映射器和处理器适配器只需要开启注解驱动即可,而省去了大段的xml配置
4、控制器Controller
- 控制器复杂提供访问应用程序的行为,通常通过接口定义或注解定义两种方法实现。
- 控制器负责解析用户的请求并将其转换为一个模型。
- 在Spring MVC中一个控制器类可以包含多个方法
- 在Spring MVC中,对于Controller的配置方式有很多种
@Controller注解类型用于声明Spring类的实例是一个控制器(在讲IOC时还提到了另外3个注解);
Spring可以使用扫描机制来找到应用程序中所有基于注解的控制器类,为了保证Spring能找到你的控制器,需要在配置文件中声明组件扫描。
<!-- 自动扫描指定的包,下面所有注解类交给IOC容器管理 -->
<context:component-scan base-package="com.shuangti.controller"/>
增加一个DemoController类,使用注解实现;
@Controller
public class DemoController{
//映射访问路径
@RequestMapping("/demo")
public String index(Model model){
//Spring MVC会自动实例化一个Model对象用于向视图中传值
model.addAttribute("msg", "DemoController");
//返回视图位置
return "demo";
}
}
5、SpringMVC几大注解
@RequestMapping
1、语法:
@注解名(属性名=属性值,属性名=属性值....)
如果只有一个属性的时候属性名=可以省略
比如:@RequestMapping("user")
2、作用:
处理request请求的
3、属性:
value
path:path和value是等价的,用法一样
method:请求方式(Get和Post)
4、作用范围:
(1)加在类上,表示一级路径
(2)加在方法上,表示二级路径
注意:一级路径和二级路径构成一个完成的请求短地址
不能重复.
127.0.0.1:8080/springMvc02/user/login
5、
@RequestMapping("user")
@RequestMapping(value="user")
@RequestMapping(path="user")
这三个等价
@RequestMapping(path= {"user1","user2"})配置多个路径
@RequestMapping(value="user",method=RequestMethod.GET)
如果是加在类上,此类中所有的二级路径只能接收Get请求
如果加在方法上,当前方法只能处理Get请求
常用的写法:
1、@RequestMapping("user")
默认是GET请求
2、@RequestMapping(value="user",method=RequestMethod.POST)
控制层两种写法:
@RequestMapping("user")
public class UserController {
/*
* 1、返回值ModelAndView是一个类型,此类型包含
* Model:保存数据
* View:视图,比如jsp
* 2、Model保存的数据,是存在request域当中
*
*
* */
@RequestMapping("login")
public ModelAndView login() {
ModelAndView mv = new ModelAndView();
//放数据,相当于往model中存放
mv.addObject("key1", "key11111");
mv.addObject("key2", "key2222222");
//放入view视图名,对应视图解析器要解析的名称
//视图解析器解析视图名,找到web-inf/jsp/login.jsp
mv.setViewName("login");
return mv;
}
/*
* 这种写法最常用,方法当中的形参Model如果不需要可以不加
*
* */
@RequestMapping("login")
public String login(Model model) {
model.addAttribute("key1","key12345");
model.addAttribute("key2","key28888");
return "login";
}
}
@RequestMapping("user")
public class UserController {
/*
* 这种写法最常用,方法当中的形参Model如果不需要可以不加
*
* */
@RequestMapping("login")
public String login(Model model) {
model.addAttribute("key1","key12345");
model.addAttribute("key2","key28888");
return "login";
}
}
视图层
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Insert title here</title>
</head>
<body>
<!--如何把model当中的数据取出来??
EL表达式${key}
-->
${key1 }<br>
${key2 }
</body>
</html>
@GetMapping
加在方法上等价于@RequestMapping(value="login",method=RequestMethod.GET)
@GetMapping("login")
public String login(Model model) {
model.addAttribute("key1","key12345");
model.addAttribute("key2","key28888");
return "login";
}
@PostMapping
加在方法上等价于@RequestMapping(value="login",method=RequestMethod.POST)
@PostMapping("login")
public String login(Model model) {
model.addAttribute("key1","key12345");
model.addAttribute("key2","key28888");
return "login";
}
@RequestParam
1、作用:把请求中指定名称的参数给控制器中的形参赋值
2、适用范围:加在方法的形参前面使用
3、属性:
name:用来指定将请求当中的哪个参数给到对应的形参,如果不指定默认和形参变量名保持一致
required:false/true 请求当中的对应参数是否必传,false非必传,true必传
注意:
参数前可以不加次注解,但是必须要形参名和实际请求传入的参数名保持一致,否则无法接收到请求传参
@RequestMapping("save")
public String save(@RequestParam String uname, @RequestParam(name="password") int pwd) {
System.out.println("注册.........");
System.out.println("uname===" + uname);
System.out.println("pwd===" + pwd);
//Service-Dao-jdbc
return "home";
}
@ResponseBody
不走视图解析器,直接将数据返回
如果返回类型是String直接就以字符串的形式返回
如果是对象,将对象转为Json再返回
注意:此注解可以加在类上,如果加在类上,此控制层所有的二级路径都不会放回视图
如果加在方法上,当前方法不会返回视图,直接以json或字符串数据返回
@ResponseBody
public String getUser() {
return "user11111111111";
}
@RequestMapping("test")
@ResponseBody
public Map<String, String> test(){
Map<String, String> map = new HashMap<String, String>();
map.put("key", "111");
return map;
}
@RestController
等价于@Controller+@ResponseBody只能加在控制层的类上
第八章 Spring Boot
1、概述
springBoot核心功能
1、独立运行Spring项目
Spring boot 可以以jar包形式独立运行,运行一个Spring Boot项目只需要通过java -jar xx.jar来运行。
2、内嵌servlet容器
Spring Boot可以选择内嵌Tomcat、jetty或者Undertow,这样我们无须以war包形式部署项目。
3、提供starter简化Maven配置
spring提供了一系列的start pom来简化Maven的依赖加载,例如,当你使用了spring-boot-starter-web,会自动加入如图5-1所示的依赖包。
4、自动装配Spring
SpringBoot会根据在类路径中的jar包,类、为jar包里面的类自动配置Bean,这样会极大地减少我们要使用的配置。当然,SpringBoot只考虑大多数的开发场景,并不是所有的场景,若在实际开发中我们需要配置Bean,而SpringBoot灭有提供支持,则可以自定义自动配置。
5、准生产的应用监控
SpringBoot提供基于http ssh telnet对运行时的项目进行监控。
6、无代码生产和xml配置
SpringBoot优缺点
优点:
1、快速构建项目。
2、对主流开发框架的无配置集成。
3、项目可独立运行,无须外部依赖Servlet容器。
4、提供运行时的应用监控。
5、极大的提高了开发、部署效率。
6、与云计算的天然集成。
缺点:
1、如果你不认同spring框架,也许这就是缺点。
2、SpringBoot特性
3、创建独立的Spring项目
4、内置Tomcat和Jetty容器
5、提供一个starter POMs来简化Maven配置
6、提供了一系列大型项目中常见的非功能性特性,如安全、指标,健康检测、外部配置等
7、完全没有代码生成和xml配置文件
2、创建Spring Boot项目
两种方式
第一种方式:使用官网模板创建maven项目,然后导入idea

第二种方式:使用Idea创建

2.1 项目结构

2.2 创建一个web项目
配置pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.0</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.shuangti</groupId>
<artifactId>springboot02</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springboot02</name>
<description>springboot02</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
3、SpringBoot 核心体系
3.1 启动器
在导入的starter之后,SpringBoot主要帮我们完成了两件事情:
- 相关组件的自动导入
- 相关组件的自动配置
这两件事情统一称为SpringBoot的自动配置
比如:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.0</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
3.2 核心注解
@SpringBootApplication
public class Springboot01Application {
public static void main(String[] args) {
SpringApplication.run(Springboot01Application.class, args);
}
}
@SpringBootApplication
1、@SpringBootApplication是springboot的核心注解
它等价于@SpringBootConfiguration
@EnableAutoConfiguration
@ComponentScan三个注解
2、@ComponentScan默认扫描当前启动类所在的包及子包,会将
这些包下的所有组件(@Service @Controller....)实例化对象交给spring容器
所以启动类的位置会影响到组件注解是否生效,尽量按默认的位置不要动
3、@SpringBootConfiguration配置类,代替spring配置文件,统一管理bean
4、 @EnableAutoConfiguration
可以将当前项目中相关的依赖(maven依赖)交给spring来管理
3.3 配置文件
核心配置文件application.properties
配置文件中配置都是以key=value的形式来定义的
#定义当前项目应用的上下文路径
server.servlet.context-path=/boot1
#定义项目的端口
server.port=8089
4、SpringBoot整合Mybatis
1、Mybatis简介
MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
2、Mybatis整合
准备sql:
CREATE DATABASE data_10 CHARACTER SET utf8 COLLATE utf8_general_ci;
USE data_10;
CREATE TABLE `user`(
id INT(11) PRIMARY KEY AUTO_INCREMENT,
uname VARCHAR(20),
pwd INT(11)
);
CREATE TABLE student(
id INT(11) PRIMARY KEY AUTO_INCREMENT,
stu_name VARCHAR(20),
age INT(11)
);
第一步:创建springboot项目
pom.xml引入相关依赖mybatis、mysql
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.0</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.shuangti</groupId>
<artifactId>springboot02</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springboot02</name>
<description>springboot02</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.37</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
第二步:修改配置文件
#定义当前项目应用的上下文路径
server.servlet.context-path=/boot2
#定义项目的端口
server.port=8082
#数据库数据源配置
#datasource是一个接口,可以获取数据库的Connection。是标准化的,取得连接的一种方式。
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/data_10?useUnicode=true&useSSL=false&characterEncoding=utf8
spring.datasource.username=root
spring.datasource.password=123456
#mybatis映射文件路径配置
#当期配置代表,寻找resources下的mapper文件夹下的所有以Mapper后缀名结尾的xml文件
mybatis.mapper-locations=classpath:mapper/*Mapper.xml
#打印sql执行日志,可以在控制台上看到sql的执行信息
mybatis.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
第三步:修改启动类
/*@MapperScan
* 作用:指定要变成实现类的接口所在的包,然后包下面的所有接口在编译之后都会生成相应的实现类
* 添加位置:是在Springboot启动类上面添加
*/
@MapperScan("com.shuangti.boot.mapper")
@SpringBootApplication
public class Springboot01Application {
public static void main(String[] args) {
SpringApplication.run(Springboot01Application.class, args);
}
}
第四步:给项目分层controller、dao、service、entity

controller用来编写接口请求,处理请求响应,调用service处理业务
service用来处理连接数据库前的业务流程
dao用来处理数据库连接,映射xml文件
第五步:
1、编写dao层接口
public interface UserDao {
int insertUser(int pwd, String uname);
}
2、编写dao层接口映射文件xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace属性的值是对应dao层接口的全限定类名-->
<mapper namespace="com.shuangti.boot.dao.UserDao">
<!--二级标签insert
id属性:
值对应的是dao层接口的方法名,要严格一致,不然报错
parameterType属性,对应接口中形参的类型,一般不需要加
insert标签当中的内容必须是insert语句
-->
<!--mybatis占位符用来获取dao层接口中方法的传参
第一种:${参数名}
相当于jdbc中的statement,存在sql注入安全隐患
相当于拼接sql
第二种:#{参数}
相当于jdbc中preparestatement,不存在sql注入
相当于使用占位符?形式
开发当中使用#,不要用$
-->
<insert id="insertUser">
insert into user(uname,pwd)
value(#{uname},#{pwd})
</insert>
</mapper>
3、编写service层调用dao层
@Service
public class UserService {
@Autowired
private UserDao userDao;
public int saveUser(String uname,int pwd){
return userDao.insertUser(pwd,uname);
}
}
4、编写controller层实现请求接收响应
/*@RestController
* 等价于@Controller+@ResponseBody
* 在类上添加次注解,那么此类中所有的请求都不走视图解析器,所有
* 请求的响应是一个json或者字符串
* */
@RestController
@RequestMapping("user")
public class UserController {
@Autowired
private UserService userService;
/*@RequestParam用来匹配接口请求中传入的参数并赋值给形参变量
* 次注解可以不加,不加必须请求传参和方法形参参数名必须保持一致
* */
@RequestMapping("save")
public String save(@RequestParam String uname, int pwd){
int ret = userService.saveUser(uname,pwd);
if(ret == 1){
return "success";
}else {
return "failed";
}
}
}
5、启动项目
访问:
127.0.0.1:8082/boot2/user/save
响应结果:success

3、Mybatis实现增删改查
定义实体类User
package com.shuangti.demo.entity;
public class User {
private int id;
private String uname;
private int pwd;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getUname() {
return uname;
}
public void setUname(String uname) {
this.uname = uname;
}
public int getPwd() {
return pwd;
}
public void setPwd(int pwd) {
this.pwd = pwd;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", uname='" + uname + '\'' +
", pwd=" + pwd +
'}';
}
}
创建数据库表
create table `user`(
id int(11) primary key auto_increment,
uname varchar(20),
pwd int(11)
);
(1)insert
定义dao层接口方法:
public interface UserDao {
int insertUser(String uname, int pwd);
}
编写xml映射文件UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.shuangti.demo.dao.UserDao">
<insert id="insertUser">
insert into user(uname, pwd)
values(#{uname},#{pwd})
</insert>
</mapper>
(2)delete
定义dao层方法
public interface UserDao {
int delteUser(int id);
}
编写xml映射文件UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.shuangti.demo.dao.UserDao">
<delete id="delteUser">
delete from user where id = #{id}
</delete>
</mapper>
(3)update
定义dao层方法
public interface UserDao {
int updateUser(int id, String uname, int pwd);
}
编写xml映射文件UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.shuangti.demo.dao.UserDao">
<update id="updateUser">
update user set uname=#{uname}, pwd=#{pwd}
where id=#{id}
</update>
</mapper>
(4)select
4.1 根据id查询,结果为单条记录(结果只有一行数据或者没有)
定义dao层方法
public interface UserDao {
User queryUser(int id);
}
编写xml映射文件UserMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--
resultType属性:
期望从这条语句中返回结果的类全限定名或别名。
-->
<mapper namespace="com.shuangti.demo.dao.UserDao">
<select id="queryUser" resultType="com.shuangti.demo.entity.User">
select * from user
where id = #{id}
</select>
</mapper>
4.2 查询结果为多条记录
定义dao层方法
public interface UserDao {
List<User> queryAll();
}
编写xml映射文件UserMapper.xml
<!--
resultType属性:
方法定义的返回的是集合,那应该设置为集合包含的类型,而不是集合本身的类型。
resultType 和 resultMap 之间只能同时使用一个。
-->
<select id="queryAll" resultType="com.shuangti.demo.entity.User">
select * from user
</select>
4.3 自定义xml结果集映射
如果数据库中的表字段和java中定义的实体类字段不一致,这时候,Mybatis自动映射会失败,
那么我们可以通过自定义结果集映射将数据库的字段和java 实体类的属性进行绑定
public interface UserDao {
List<User> queryUsers();
}
编写xml映射文件UserMapper.xml
<!--自定义结果集映射
有时候数据库的字段和实体类entity层的类中的属性对应不起来
我们就需要通过自定义的方式,让数据库的栏位和实体类中的属性建立关联关系
-->
<resultMap id="userMap" type="com.shuangti.demo.entity.User">
<!--property代表实体类当中的属性名
column代表数据库当中的栏位名
如果不加,默认按属性名自动匹配栏位名
注意:
resultType和resultMap只能用一个
-->
<id property="id" column="id"/>
<result property="uname" column="u_name"/>
</resultMap>
<!--resultMap的值为自定义结果集的id -->
<select id="queryAll" resultMap="userMap">
select * from user
</select>
4.4 使用if,生成动态SQL
如果传入的参数过多,并且不能保证每个参数都作为查询条件的时候,可以通过参数判断来决定最终的SQL
定义dao层方法
public interface UserDao {
//根据条件动态查询结果集
//根据方法形参在调用时具体由实参来决定sql的查询条件
List<User> queryByType(String uname, int pwd);
}
编写xml映射文件UserMapper.xml
<select id="queryByType" resultMap="userMap">
select * from user
where
1= 1
<if test="uname != null and uname != ''">
and uname=#{uname}
</if>
<if test="pwd != -1">
and pwd =#{pwd}
</if>
</select>
4.5 dao层传参为对象
如果dao层的方法形参数量过多时,可以定义一个引用数据类型的形参,Mybatis会自动将参数与对象中的属性进行绑定
定义dao层方法
public interface UserDao {
List<User> queryAll(User user);
}
编写xml映射文件UserMapper.xml
<!--根据传入的引用数据类型自动绑定参数
parameterType属性:
将会传入这条语句的参数的类全限定名或别名。这个属性是可选的,
因为 MyBatis 可以通过类型处理器(TypeHandler)推断出具体传入语句的参数,
默认值为未设置(unset)。
-->
<select id="queryAll" resultType="com.shuangti.demo.entity.User"
parameterType="com.shuangti.demo.entity.User">
select * from user
where
1= 1
<if test="uname != null">
and u_name=#{uname}
</if>
<if test="pwd != -1">
and pwd =#{pwd}
</if>
</select>
4、Json
概述:
- JSON(JavaScript Object Notation,JS对象标记)是一种轻量级的数据交换格式,目前使用特别广泛。
- 采用完全独立于编程语言的文本格式来存储和表示数据。
- 简洁和清晰的层次结构使得JSON成为理想的数据交换语言。
- 易于阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
在javaScript语言中,一切都是对象。因此,任何javaScript支持的类型都可以通过json来表示,例如字符串、数字、对象、数组等。看看他的要求和语法格式:
- 对象表示为键值对,数据由逗号分隔
- 花括号保存对象
- 方括号保存数组
JSON键值对是用来保存javaScript对象的一种方式,和javaScript对象的写法也大同小异,键值对组合中的键名写在前面并用双引号””包裹,使用冒号:分割,然后紧接着值:
{"name": "qiulina"}
{"age": "3"}
{"sex": "女"}
很对人搞不清楚JSON和javaScript对象的关系,甚至连谁是谁都不清楚。其实,可以这么理解:
- JSON是javaScript对象的字符串表达法,它使用文本表示一个JS对象的信息,本质是一个字符串。
var obj = {name: "qiulina", age: "3", sex: "女"};//这是一个对象,注意键名也是可以使用引号包裹的
var json = {"name":"qiulina","age":"3","sex":"女"};//这是一个JSON字符串,本质是一个字符串
JSON和javaScript对象互转
- 要实现从JSON字符串转换为javaScript对象,使用JSON.parse()方法:
var obj = JSON.parse({"name":"qiulina","age":"3","sex":"女"});
//结果是 {name: "qiulina", age: "3", sex: "女"}
- 要实现从javaScript对象转换为JSON字符串,使用JSON.stringify()方法:
var json = JSON.stringify({name: "qiulina", age: "3", sex: "女"});
//结果是 {"name":"qiulina","age":"3","sex":"女"}
代码测试,新建一个json.html页面
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title></title>
<!--
json是一种数据格式,是js对象
语法:
(1)定义一个json对象
var json = {key1:value1,key2:value2,.....keyn:valuen};
其中key只能为字符串
value可以为数字、字符串、数组、对象(json)
(2)json遍历
for(var key in json){
}
其中key为json当中第一层的每一个key值
-->
<script type="text/javascript">
var json1 = {"张三":10,"李四":20};
// JSON.stringify可以将json对象转为字符串
console.log("json1==="+JSON.stringify(json1))
var json2 = {"王五":"男"};
var arr1 = [1,2,3,4];
var json3 = {"key1": [1,2,3,4]};
var json4 = {"key2":{"key11": 11}};
var json5 = {"key3": json2};
var json6 ={"key1": {"key11":{"key111":1}}};
var json7 ={"key1": {"key11":{"key111":[1,2,3]}}};
for(var x in json1){
console.log(x);//取key
console.log(json1[x]);//取value
}
console.log("=====================")
for(var y in json4){
console.log(y)
// console.log(json4[y])
for(var z in json4[y]){
console.log(z)
console.log(json4[y][z])
}
}
</script>
</head>
<body>
</body>
</html>
Spring Boot当中使用json
在pom当中引入alibaba的fastjson相关依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.6</version>
</dependency>
编写控制层实现返回json格式的字符串
@RestController
@RequestMapping("user")
//@CrossOrigin
public class UserController {
@Autowired
private UserService userService;
/*
* 将json字符串直接给到客户端
* */
@RequestMapping("getJson")
public String getJson(){
//{}
JSONObject json = new JSONObject();
json.put("pageNo",1);
json.put("pageSize",20);
//{"pageNo":1,"pageSize":20}
//{}
JSONObject json1 = new JSONObject();
json1.put("苹果","20");
json1.put("香蕉","30");
//{"苹果":20,"香蕉":30}
//{"pageNo":1,"pageSize":20,"goods_list":{"苹果":20,"香蕉":30}}
json.put("goods_list",json1);
// List<User> list = userService.uList(null, -1);
List<User> userList = new ArrayList<>();
User user = new User();
user.setPwd(1);
user.setUname("111");
userList.add(user);
JSONArray jsonArray = JSONArray.of(userList);
//{"pageNo":1,"pageSize":20,"goods_list":{"苹果":20,"香蕉":30}
// "user_list":[{"id":1},{"uname": "11"}]}
json.put("user_list",jsonArray);
return json.toJSONString();
}
/*
* 返回的user对象会转为key-value json格式的字符串数据给到客户端
* */
@RequestMapping("getUser")
public User getUser(int id){
return userService.get(id);
}
/*
* List<User>会转为json数组给到客户端
* */
@RequestMapping("all")
public List<User> all(){
return userService.uList(null, -1);
}
}
展示其中一个请求结果




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)