强化学习和ADP(上)
1 简介
每一个生物都与其环境相互作用,并利用这些相互作用来改善自身的活动,以生存和增长。我们称基于与环境交互的动作修正为强化学习(RL)。这里有很多类型的学习,包括监督学习,非监督学习等。强化学习是指一个行动者或代理与它的环境相互作用,根据收到的刺激对其行为的响应,并修改其行为或控制政策。
有一类强化学习方法是基于演员(actor)-评论家(critic)结构。其中,行动者组成部分对环境应用一项行动或控制政策,而评论家组成部分则对该行动的价值进行评估。行动者-评论家结构包含两个步骤:评论家对政策进行评价,然后是政策改进。政策评估步骤通过从环境中观察当前行动的结果来执行。
生物体的生存范围通常很狭窄,大多数物种可利用的资源也很贫乏。因此,大多数生物都以最佳方式行动,既能节约资源,又能达到目标。最佳行动可能是基于最低燃料、最低能量、最低风险、最高奖励等等。
由于强化学习涉及修改基于环境响应的控制策略,人们有一种最初的感觉,它应该与自适应控制密切相关,自适应控制是控制系统社区高度重视的一个成功的控制技术家族。
2 动力系统和最优反馈控制
在反馈控制系统的研究和设计中,需要提供设计算法和分析技术,以保证可证明的性能和安全边际,提供这种保证的一种标准方法是使用数学提供的框架和工具,比如马尔可夫决策过程(Markov decision processes,MDP)。
2.1 动力学系统
(1)连续状态空间:利用拉格朗日力学、哈密顿力学等对动力系统进行物理分析时,可以用非线性常微分方(Ordinary differential equations,ODEs)来描述系统。特别普遍的是非线性状态空间形式的ODEs为\(\dot{x}=f(x,u)\),其中状态\(x(t)\in R^n\)并且控制输入\(u(t)\in R^m\)属于连续空间中,许多系统(比如航空航天,汽车工业,机器人等)都可以采用这种形式进行表示。
(2)离散状态空间:除了上述的连续状态空间外,还存在离散状态和动作空间MDP,这些动力学也是连续时间(continuous-time,CT)系统
2.1 离散时间系统的最优控制
有一些标准的方法对非线性连续时间状态空间ODEs进行采样或离散,以获得便于计算机控制的采样数据形式。所得到的系统在离散时间内展开,一般的状态空间形式为\(x_{k+1}=F(x_k,u_k)\),其中\(k\)为离散时间指标。这些系统满足1步马尔可夫性质,因为它们在\(k+1\)时的状态只依赖于之前\(k\)时的状态和输入。
为了便于分析,我们经常考虑一类用仿射状态空间差分方程形式的非线性动力学描述的离散时间系统:
其中状态\(x(t)\in R^n\)并且控制输入\(u(t)\in R^m\)。这种形式方便分析,并且可以推广到一般的抽样数据形式\(x_{k+1}=F(x_k,u_k)\)。
控制策略定义为从状态空间到控制空间的函数\(h(\cdot):R^n \to R^m\),对于每一个状态\(x_k\),策略定义一个控制动作为:
这种映射也被称为反馈控制器。一个例子是线性状态变量反馈\(u_k=h(x_k)=-Kx_k\)。另一个例子是传递函数动态控制器的设计。反馈控制策略的设计可采用多种方法,包括通过Riccati方程求解的最优控制、自适应控制、h-infinity控制、经典频域控制等。
在强化学习的应用中,系统动力学甚至没有考虑,作为环境的一部分,没有显式的动力学模型,如(1),甚至被使用。强化学习在具有未知动力学的复杂系统中获得了相当大的成功,包括Tesauro的西洋双陆棋玩家,以及能够支持带有多个连接拖车的卡车牵引车/拖车的控制器设计。然而,不特别考虑动力学也使它不可能提供明确的稳定性和性能证明,如控制系统社区所要求的接受。
3 目标导向最优性能
目标导向的最佳行为的概念是通过定义一个性能度量或成本函数来捕获的:
其中\(0<\gamma \le 1\)为折扣因子,\(u_k=h(x_k)\)是控制反馈策略。这被称为代价函数,是从当前时间\(k\)到无限未来的折扣成本之和。折扣率反映了这样一个事实,即我们对未来获得的成本不太关心。函数\(r(x_i,u_i)\)被称为效用,是一步控制成本的度量。这可以根据最低燃料、最低能耗、最低风险等因素进行选择。例如,一个标准形式是二次能量函数\(r(x_k,u_k)=x_k^TQx_k+u_k^TRu_k\)或者更一般的形式:
我们有时用它来说明,并且要求\(Q(x)\)和\(R\)是正定的。
我们假设该系统在某个集合\(\Omega \in R^n\)上是可稳定的,意味着存在一个控制策略\(u_k=h(x_k)\)使得在闭环系统\(x_{k+1}=f(x_k)+g(x_k)h(x_k)\)是渐进稳定的。如果一个控制策略\(u_k=h(x_k)\)是稳定的并且可以计算出有限的代价函数\(V_h(x_k)\),则被称为是可以接受的。
任何可接受的策略\(u_k=h(x_k)\),我们称\(V_h(x_k)\)为损失或者价值。价值较小的策略被认为比其他策略更好。重要的是要注意,给定任何可接受的政策,其价值可以通过评估无限和(3)来确定。在某些情况下,这可以通过明确的计算来完成,或通过使用数字计算机进行模拟,或通过观察闭环系统的轨迹进行实时实际评估。确定控制策略的值或代价的方法是反馈控制理论和强化学习的关键区别之一。
最优控制理论的目标是选择成本最小的策略来获得:
这被称为最优成本,或最优价值。给出了最优控制策略
然而,问题是要最小化的不仅仅是一步成本,而是所有折扣成本的总和。对于一般的非线性系统,这个问题通常是非常困难甚至不可能精确求解的。
注意,在计算智能中,(3)通常被解释为一种奖励,目标是将其最大化。
人们发展了各种方法来简化这个优化问题的求解。下面将要讨论以下问题:
- Bellman最优原理和动态规划
- 策略迭代和价值迭代
- 基于时间差异和ADP的各种形式的强化学习
4 Bellman最优原理和动态规划
对公式(3)进行重写:
可以得到一个等价的差分方程
也就是说,不需要求无穷和(3),只需求解差分方程,即可得到使用当前策略的值。这是一个非线性李雅普诺夫方程(Lyapunov equation)被称为贝尔曼方程(Bellman equation)。
如何利用系统轨迹观测数据在线实时求解Bellman方程?
离散时间(Discrete-time,DT)哈密顿量(Hamiltonian)能够被定义为:
其中\(\bigtriangleup V_k=\gamma V_h(x_{k+1})-V_h(x_k)\) 被称为正向差分算子。哈密顿函数捕获沿系统轨迹的能量含量,反映在期望的最佳性能。贝尔曼方程要求哈密顿量对于与规定的策略相关的值等于零。
最优值可以用Bellman方程表示为:
这个优化问题仍然很难解决。
最优策略具有这样一种特性:无论之前的决策(即控制)是什么,剩下的决策必须构成由这些先前决策产生的状态的最优策略。
对于方程来说,这意味着
这被称为Bellman最优方程,或离散时间Hamilton-Jacobi-Bellman (HJB)方程。那么最优策略是:
使用这些方程确定最优控制器要比使用(10)简单得多,因为它们在最小值参数中包含最优值。由于必须知道(11)中时间\(k+1\)的最优策略来确定时间\(k\)的最优策略,贝尔曼原理给出了一个时间倒推过程来解决最优控制问题。这些本质上都是离线规划方法。
这种过程在反馈控制设计中的一个例子是Linear Quadratic Regulator(LQR)问题的Riccati方程设计,它涉及到已知系统动力学的Riccati方程的离线求解(见下文)。DP方法通常需要系统动力学方程的全部知识。也就是说,\(f(x)\),\(g(x)\)必须已知。
4.1 策略迭代、值迭代和不动点方程
与动态规划离线设计相比,我们寻求强化学习方案以实现实时在线学习,最终不需要知道系统动力学\(f(x)\),\(g(x)\)。通过(12)来获取一个新的策略。
这被称为推出算法的一步改进特性。也就是说,步骤(13)已经给了一个改进的策略。这就提出了以下确定最优控制的迭代方法,即策略迭代法
4.1.1 策略迭代算法(Policy Iteration(PI)Algorithm)
- 初始化:选择任何允许的(即稳定)控制策略\(h_0(x_k)\)。
- 策略评估的步骤:使用Bellman方程确定当前策略的价值。
- 策略改进步骤:通过下面的方程确定一个改进策略。
如果该Utility具有特殊形式,且动力方程为(1),则政策改进步骤如下
其中\(\bigtriangledown V(x)=\partial V(x)/ \partial x\)为价值函数的梯度,这里解释为列向量。
注意,PI中的初始政策必须是可接受的,这要求它是稳定的。使用贝尔曼方程(14)评估当前政策的价值,相当于确定所有从状态\(x_k\)开始使用策略\(h_j(x_k)\)的值。这被称为完全备份,并可能涉及大量计算。
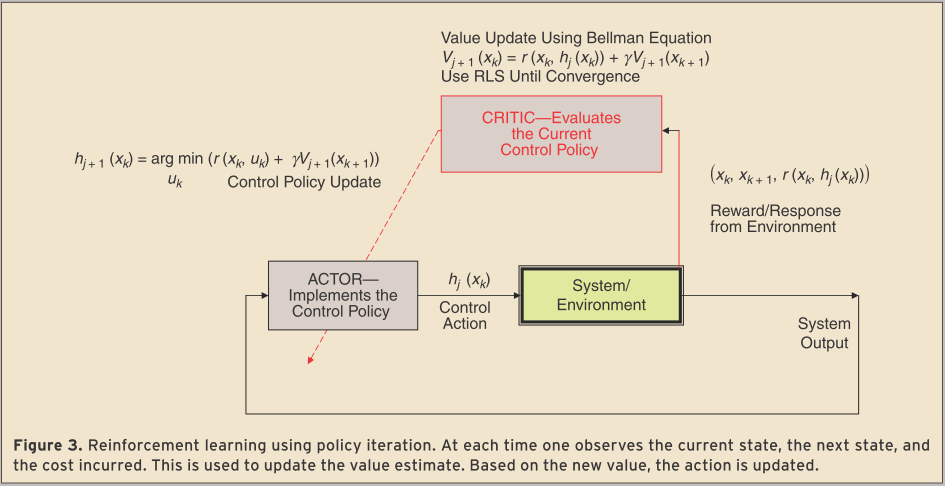
事实上,可以证明Bellman方程是一个不动点方程。也就是说,给定一个容许的策略\(u_k=h(x_k)\),有一个唯一的不动点\(V_h(x_k)\),以及下面的压缩映射:
可以从任何初始值\(V^0(x_k)\)开始迭代,其结果是:\(V^i(x_k)\to V_h(x_k)\),因此可以将策略迭代步骤(14)改为:
其中\(i\)步中的迭代使用相同的策略\(h_j\)直到收敛。当\(i \to \infin\)时,有\(V^i(x) \to V_{j+1}(x)\)。一般选择\(j\)步\(V^0(x_{k+1})=V_j(x_{k+1}))\)。这可以称为迭代策略迭代。值得注意的是,(17)中的每一步要实现(14)中的单个步骤要简单得多。
这就进一步提出了对固定的有限整数\(K\),只对(17)进行\(K\)步迭代的想法,也就是说,只采取K步来评估当前政策的价值。这被称为通用策略迭代(GPI)。在GPI中,在每个策略更新步骤中,只对数值做部分备份。一个极端的情况是取\(K=1\),这就得到了下一个算法,即所谓的价值迭代(Value Iteration)。在这里,只进行了1步的数值备份。
4.1.2 价值迭代算法(Value Iteration(VI)Algorithm)
- 初始化:选择一个控制策略\(h_0(x_k)\),不要求可行性和稳定性。
- 价值更新步骤:使用下面的方程更新价值
- 策略改进步骤:使用下面的方程确定一个改进策略
需要注意的是,现在(18)右边使用的是旧值,而不是PI步骤(14)。已经证明VI在某些情况下是收敛的。请注意,VI不需要一项初步的稳定政策。
需要注意的是,PI在每一步都要求(14)的解,这是一个非线性李雅普诺夫方程。这个解对于一般的非线性系统是困难的。另一方面,VI依赖于(18)的解,它是一个简单的递归方程。
一般来说,不动点方程可用来作为在线强化学习算法的基础,该算法通过观察沿着系统轨迹积累的数据来学习。我们不久将根据这些概念发展强化学习计划。首先,为了明确观点,让我们考虑LQR的情况。
5 DT线性二次调节器(LQR)案例
本节的主要目的是表明策略迭代和值迭代的强化学习概念实际上与反馈控制系统中熟悉的思想是一致的。第二个目的是为进一步阐明其意义的一类重要问题,对上述结构给出明确的表达式。
一类重要的离散时间系统可以用线性时不变的状态空间形式来描述:
其中状态\(x(t)\in R^n\)并且控制输入\(u(t)\in R^m\)。控制策略是状态反馈的形式。
控制策略是由一个恒定的反馈增益矩阵\(K\)来确定。给定的策略,代价函数是二次函数的和。
其中效用Utility \(r(x_k,u_k)=x_k^TQx_k+u_k^TRu_k\),加权矩阵\(Q=Q^T \ge 0\),\(R=R^T>0\)
假设\((A,B)\)是稳定的,在闭环系统中存在一个反馈增益矩阵\(K\)有
是渐进稳定的。
5.1 DT LQR的最优控制解
该设计的目标是选择一个状态反馈增益矩阵\(K\),即控制策略,去最小化当前状态\(x_k\)的代价函数\(V_h(x_k)=V_K(x_k)\)。这被称为线性二次调节器(LQR)问题。
在当前状态下,LQR的最优值是二次的,可以表示为:
对于一些矩阵\(P\),这有待确定。因此,LQR的贝尔曼方程为
根据反馈增益,将(20)(21)加入到(25)中可以写成
因为这必须对所有的当前状态\(x_k\)都成立,所以有
这个矩阵方程在\(P\)中是线性的,当\(K\)是固定的时候被称为李雅普诺夫方程。在给定稳定增益举证\(K\)的情况下,解这个方程得到\(P=P^T>0\),以至于使用策略\(K\)的代价可以表示为\(V_K(x_k)=x_k^TPx_k\)。
方程很容易解出LQR。把贝尔曼方程写成
对\(u_k\)求微分可以简单的实现最小化
or
因此最优反馈增益矩阵\(K\)为:
替换到贝尔曼方程(29)并简化可以得到DT HJB方程
这个方程是P的二次方程,被称为黎卡提(Riccati)方程。
为了解决DT LQR最优化控制问题,我们首先要求解Riccati方程(32)得到\(P\),然后通过(24)获取到最优价值\(V^\star(x_k)\)以及通过(31)得到最优策略。
通过(25)(26)(27)来求解Riccati方程是一种离线的求解过程,需要完全知道系统的动力学\((A,B)\)。
5.2 利用策略迭代和价值迭代求解DT LQR问题
对于LQR, Bellman方程(8)写成(25),因此等价于Lyapunov方程(32)。因此,在策略迭代算法中,LQR的策略评估步骤为
策略改进为:
然而,这两个方程的迭代正是Hewer’s算法求解Riccati方程(32)。Hewer证明了它在稳定性和可检测性假设下是收敛的。
在价值迭代算法中,LQR的策略评估步骤为
策略改进同样也是(34)
Lancaster和Rodman[1995]对这两个方程的迭代进行了研究,发现在上述假设下,它收敛于Riccati方程的解。
注意,策略迭代在每一步都涉及到Lyapunov方程(33)的完整解,并且在每一步都需要一个稳定增益\(K_j\)。这在强化学习术语中称为完全备份。另一方面,值迭代在每一步只涉及Lyapunov递归(35),这是非常容易计算的,不需要稳定增益。这被称为强化学习中的部分备份。
强化学习提出了求解Riccati方程的另一种算法,即广义策略迭代(Generalized Policy Iteration,GPI)。在GPI中,每一步都要执行以下操作。
5.3 广义策略迭代算法求解LQR
- 初始化:选择一个控制策略\(K_0\),不要求可行性或者稳定
- 价值迭代过程:在步骤\(j\)中,使用下面的方程更新价值
对于某个有限的\(K\),设置初始条件\(P_j^0=P_j\),\(P_{j+1}=P_j^K\).
- 策略改进过程:使用下面的方程得到改进策略
该算法在每次迭代\(j\)时,对求解Lyapunov方程采取\(K\)步。也就是说,GPI中的值更新步由相同固定增益的递归(35)的K步组成。设置\(K=1\)得到Value Iteration,即(35),而设置\(K=\infin\)(即perform(36)直到收敛)得到Policy Iteration,它求解Lyapunov方程(33)。
6 强化学习,ADP和自适应控制
采用动态规划方法求解最优控制是一个逆时过程。因此,它可以用于离线规划,但不能用于在线学习。这些方法被广泛地称为近似动态规划。这有两个关键因素:时间差(TD)误差和值函数逼近(VFA)。
6.1 时间差分(Temporal Difference,TD)和值函数逼近(Value Function Approximation,VFA)的ADP算法
近似动态规划(ADP)或神经动态规划(NDP)是一种利用沿系统轨迹的测量数据实时在线确定最优控制方案的实用方法。它提供了动态规划问题的实时、正向方法和值函数的逼近方法。
(1)时间差分
时间差(TD)误差:为了将这些概念转化为实时前向在线求解方法,在Bellman方程的基础上定义了一个时变残差方程误差为
我们注意到右边是DT hamiltonian函数。函数\(e_k\)被称为时间差误差。如果贝尔曼方程成立,则该误差等于0。因此对于一个固定的控制策略,对于值函数\(V_h(\cdot)\),即TD方程的最小二乘解,可以再每次\(k\)时求解方程\(e_k=0\)。
这将产生与使用当前策略对应的值的最佳近似值,即与总和(3)的近似值。
TD误差可以被认为是预测性能和观测性能之间的预测误差,以响应应用于系统的一个动作。
求解TD方程相当于在线求解非线性李雅普诺夫方程,不知道系统动力学,只使用沿系统轨迹测量的数据。不幸的是,对于一般的非线性系统,TD方程很难求解。
值函数近似(VFA)。为了给TD方程的求解提供一种实用的方法,我们可以用参数逼近器来逼近值函数\(V_h(\cdot)\)。这被称为近似动态规划(ADP),或者自适应动态规划,都使用了神经网络作为近似器。
(2)值函数近似(VFA)
为了去更好的理解这种方法,用LQR问题作为例子讲述VFA方法。在LQR问题中,我们知道控制策略的值是关于状态的二次函数\(u_k=-Kx_k\),即存在一个矩阵\(P\),替换TD error有:
这个方程在未知参数矩阵\(P\)中是线性的。为了进一步简化TD方程,用克罗内克积(Kronecker product)来表示:
其中\(\otimes\) 是克罗内克积,\(vec(P)\)是矩阵\(P\)中的列向量叠加起来的向量。\(P\)是匀称的,只有\(n(n+1)/2\)个元素,该方程中位置的参数向量是\(\bar{P}\),为\(P\)中的元素。
使用上述结构,可以将TD error重写为:
在LQR的情况下,由\(x_k\)分量中的二次函数提供了值函数\(V_h(x_k)\)的完整基集。在非线性情况下,我们假定值是足够光滑的。然后根据威尔斯特拉斯高阶逼近定理,存在稠密基集\(\{\phi(x)\}\)以致:
其中基向量\(\phi(x)=[\varphi_1(x),\varphi_2(x),....\varphi_L(x) ]\):\(R^n\to R^L\),并且\(\varepsilon_L(x)\)当\(L\)趋近于无穷大时,趋近于0。在威尔斯特拉斯定理中,标准用法取一个多项式基集。在神经网络社区中,还给出了其他各种基集的逼近结果,包括sigmoid型、双曲正切、高斯径向基函数等。其中,标准结果表明,神经网络近似误差\(\varepsilon_L(x)\)是一个紧集上的常数。\(L\)表示隐层神经元的数量。
使用值函数近似(VFA),其中评论家和(如果需要的话)参与者使用函数近似器参数化,CoD(curse of dimensionality)问题得到了缓解。
6.2 ADP在线强化学习最优控制
假设有个近似:
带入贝尔曼TD方程得到
\(e_k=0\)是一个不动点方程,它是一个一致性方程,在每个时间\(k\)都满足对应于当策略\(u=h(x)\)的值\(V_h(\cdot)\)。因此,可以采用求解TD方程的迭代过程,包括策略迭代和值迭代。
(1)在线策略迭代算法
- 初始化:选在一个可允许的控制策略\(h_0(x_k)\).
- 策略评估:求\(W_{j+1}\)的最小二乘解
- 策略改进:确定一个改进的策略
如果效用Utility具有特殊形式(4),而动态是(1),那么策略改进步骤如下所示
其中\(\bigtriangledown \phi(x)=\partial \phi(x)/\partial x \in R^{L\times n}\)是激活函数向量的雅可比矩阵。
注意,这是一个标量方程,而未知参数向量\(W_{j+1} \in R^L\)有\(L\)个元素。在时间\(k+1\),我们测量之前的状态\(x_k\),控制\(u_k\),下一个状态\(x_{k+1}\),并计算效用\(r(x_k,h_j(x_k))\)。在随后的时间里,使用相同的策略\(h_j(\cdot)\)重复这一过程,直到至少有\(L\)个方程,在这一点上,我们可以确定LS(least-squares)解决方案\(W_{j+1}\)。人们可以使用批处理LS来实现这一目标。
然而,请注意(46)形式的方程正是用递归最小二乘(RLS)技术求解的方程。因此,可以在线运行RLS直到收敛。重写(46)
其中\(\Phi(k) \equiv (\phi(x_k)-\gamma \phi(x_{k+1}))\)是回归矢量。在PI算法的第\(j\)步,我们将控制策略固定为\(u=h_j(x)\)。然后,在每一个时间\(k\),我们测得数据\((x_k,x_{k+1},r(x_k,h_j(x_k)))\)。然后执行RLS的一个步骤。这样重复几次,直到收敛\(V_{j+1}(x)=W_{j+1}^T \phi(x)\)。
注意,对于RLS收敛,回归向量\(\Phi(k) \equiv (\phi(x_k)-\gamma \phi(x_{k+1}))\)必须持续计算。
作为RLS的替代方法,可以使用梯度下降调优方法,例如
其中\(\alpha>0\)为调节参数,指数\(i\)随时间指数\(k\)的每一增量而增加。一旦值参数收敛,控制策略按(47),(48)更新。然后,重复步骤\(j+1\)。整个过程重复进行,直到收敛到最优控制解,即(11),(12)的近似解。
这提供了一个在线强化学习的人工算法,通过测量沿着系统轨迹的数据,使用策略迭代来解决最优控制问题。同样,基于值迭代的在线强化学习算法也可以得到。
(2)在线价值迭代
- 初始化:选择任何一个控制策略不要求可行性和稳定性\(h_0(x_k)\)
- 价值更新:确定最小二乘解\(W_{j+1}\)
- 策略改进:使用下面的方程确定改进的策略
为了实时解决,可以使用批处理LS、RLS或基于梯度的方法。注意,旧的权重参数在(51)的右边。因此,回归向量现在是\(\phi(x_k)\),这对RLS的收敛一定是持久的激励。
6.3 强化学习和自适应控制
这些强化学习算法的形式如图所示。请注意,它们属于演员评论家结构。请注意评论家中的值更新是通过使用标准自适应控制技术(即RLS)求解(46)或(51)来执行的。然后使用(52)更新控件。
强化学习的重要性在于它提供了一个自适应控制器,收敛到最优控制。间接自适应控制器的设计,首先估计系统参数,然后解决Riccati方程,但这些是笨拙的。强化学习提供在线学习的最优自适应控制器。
注意,这是一个双时间尺度的系统,其中内环的控制动作发生在采样时间,但性能是在一个更长的范围内的外环评估,对应于RLS所需的收敛时间。
值得注意的是,在LQR的情况下,Riccati方程(32)提供了最优控制解。李亚普诺夫方程(27)等价于(45)。动力学(A,B)必须是已知的解李雅普诺夫方程和Riccati方程。因此,这些方程提供了离线规划解决方案。另一方面,不动点沿系统轨迹方程可以在线评估利用强化学习技术通过测量每次数据集\((x_k,x_{k+1},r(x_k,h_j(x_k)))\),由当前状态,下一个状态,以及由此产生的效用。这相当于通过评估非最优控制器的性能来在线学习最优控制。
强化学习实际上是在线求解Riccati方程,并且不知道动力学,通过观察数据\((x_k,x_{k+1},r(x_k,h_j(x_k)))\)在每次沿着系统轨迹。
6.4 第二Actor神经网络的介绍
PI强化学习算法解决了李亚普诺夫方程。在LQR PI的问题中,例如,这意味着Lyapunov(33)方程已被替换为
目标是求取参数\(\bar{P}_{j+1}\),对于这一步,动态\((A,B)\)可以是未知的,因为它们是不需要的。因此,强化学习在线求解每一步的非线性李雅普诺夫方程(Bellman方程),而不知道动力学,只使用沿着系统轨迹观测的数据。
但是,请注意,在LQR的情况下,策略更新是由
这需要对\((A,B)\)的动力学有充分的了解。进一步注意,实施例(47)在非线性情况下不易实现,因为它隐含在控制中,因为\(x_{k+1}\)依赖于\(h(\cdot)\),并且是非线性激活函数的参数。
这些问题通过为控制策略引入第二个神经网络来解决,称为actor NN。因此,引入一个参与者参数逼近器结构
其中\(\sigma(x):R^n \to R^m\)是激活函数的向量,\(U\)是权值为未知参数的矩阵。
Critic网络的收敛需要依执行(47)或者(52),为了实现这一点,可以使用梯度下降方法来调整actor权重\(U\),例如
\(\gamma\)为调谐参数。调谐指标\(i\)随时间指标\(k\)递增。
引入第二Actor NN完全避免了对状态内部动力学知识的需要)。
在双网络结构中,保持一个神经网络的权值不变,而调整另一个神经网络的权值直到收敛。重复这个过程,直到两个神经网络都收敛。这是一种在线自适应最优控制系统,其值函数参数在线调整,收敛到最优值和最优控制。
在[He and Jagannathan 2007]中给出了同步调整演员和评论家的方法。在此基础上,利用李雅普诺夫能量控制技术,实现了神经网络的同步调谐,保证了闭环系统的稳定性。
7 Q learning and Dual Learning
Werbos[1974, 1989, 1991, 1992]介绍了近似动态规划(ADP)的四种基本方法。他把基于学习标量值函数\(V_h(x_k)\)的强化学习称为启发式动态编程(HDP)。动作依赖HDP (AD HDP),由Watkins[1989]引入为离散态MDP的Q学习,学习所谓的Q函数(也是一个标量),并允许人们在不了解系统动力学的情况下执行强化学习。双启发式编程(DHP)使用在线学习的协态函数\(\lambda_k=\partial V_h(x_k)/\partial x_k\),这是一个n向量梯度,因此携带比值更多的信息。AD DHP基于学习Q函数的梯度。
7.1 Q Learning
不幸的是,在价值函数学习或HDP中,人们需要系统动力学知识(见(48)和(54))。至少,需要输入耦合函数\(g(x_k)\)或\(B\)矩阵。这是因为在执行最小化时(没有控制约束)
必须就控制微分来获得
然而在评估
其中一个要求系统输入矩阵\(g(\cdot)\)。如果使用第二个交流神经网络,那么仍然需要\(g(\cdot)\)调整actor神经网络的权重,按(56)。
为了避免了解任何系统动力学,必须提供一个替代路径,对不经过系统的控制输入取偏导数。Werbos使用了反向传播的概念来实现这一点,使用的是动作依赖的HDP (AD HDP)。Watkins[1989]为离散空间MDP引入了类似的概念,他称之为Q学习。
考虑Bellman方程(8),它允许人们计算使用任何规定的允许策略\(h(\cdot)\)的值。最优控制由(10)或(11)确定。因此,让我们定义与政策\(u=h(x)\)相关的Q(质量)函数为:
注意,Q函数是\(k\)时刻状态\(x_k\)和控制\(u_k\)的函数。它被称为动作值函数。定义最优Q函数为
用\(Q^*\)来表示Bellman最优方程,用非常简单的形式表示
最优控制为:
在没有控制约束的情况下,通过求解得到最小值
与(58)相反,它不需要涉及系统动力学的任何导数。也就是说,假设我们知道每\((x_k,u_k)\)的Q函数,我们不需要找到\(\partial x_{x+1}/\partial u_k\)。
在值函数学习(HDP)中,必须学习并存储所有可能状态\(x_k\)的最优值。相比之下,在Q学习中,必须存储\((x_k,u_k)\)的所有值的最优Q函数,即在每种可能状态下执行的所有可能控制动作的最优Q函数。
7.2 不动点方程的Q函数
我们想采用在线强化技术来学习Q函数。为此,我们必须确定:1、Q的不动点方程使用TD; 2、一个适合Q使用VFA的参数逼近器结构(实际上是Q函数逼近- QFA)。
要确定Q的不动点方程,请注意
因此Q的Bellman方程是
或者
最优Q值满足或
式(67)是Q的不动点方程或Bellman方程。将其与式(8)相比较,现在可以使用上述任何一种在线强化学习方法作为ADP的基础,包括PI和VI。
7.3 Q函数用于LQR情况
为了激励Q函数近似(QFA)选择合适的近似器结构,让我们计算LQR情况下的Q函数。
根据(60)我可以得到LQR
其中\(P\)是规定策略\(K\)的李雅普诺夫方程的解。因此
或者
这是LQR的Q函数。它是\((x_k,u_k)\)的二次元。
使用克罗内克方程写为:
然后不懂带方程(67)可以写为:
其中\(u_k=-Kx_k\),对应(42)
7.4 Q函数的强化学习使用策略或值迭代
以LQR为例子,在一个非线性系统中,假设使用一个参数近似神经网络为:
基于(67)可以写出TD error
现在强化学习方法,包括PI或VI,可以用来在线学习\(\bar{H}=vec(H)\),如上所述。策略迭代如下所示。RLS或梯度下降可用于识别与给定策略\(K\)相关的Q函数,如(46)和(51)中所讨论的。
对于这些方法,策略更新步骤基于
对于LQR的情况,定义
然后通过(74)得出
或者
由于在在线强化学习中发现了二次核矩阵\(H\),因此该步骤不需要系统动力学。注意执行(74)上(71)正好是(54)。
对于一般非线性情况的Critic网络的情况我们可以得到
由于这种神经网络明确地依赖于控制动作\(u\)(动作依赖HDP),其导数可以在不参考系统动力学等进一步细节的情况下计算。为了求解\(u\)以获得一个显式策略\(u_k=h(x_k)\),需要对这个神经网络结构应用隐函数定理。
PI和VI都可以用于Q学习。为说明起见,我们给出
(1)Q learning 策略迭代算法
- 初始化:选择一个可行的控制策略\(h_0(x_k)\)
- 策略评估:求\(W_{j+1}\)的最小二乘解
- 策略改进:求解一个改进的策略
(79)中的最小值由(77)给出,并且可以更明确地计算出为神经网络选择的基激活函数。例如,在LQR的情况下,有(76)。
在政策改进中,第一步指出了一个问题。检查(71),并注意到对于Q学习,一个设置\(u_k=-Kx_k\)和\(K\)当前的政策。这使得\(u_k\)依赖于\(x_k\),意味着用LS技术求解(78)所需的\(\Phi(k)=(\phi(z_k)-\gamma \phi(z_{k+1}))\)上的激发持久性不成立。因此,必须添加一个PE探测噪音,以便\(u_k=-Kx_k+n_k\)。在[Al-Tamimi 2007]中表明,这不会导致Q函数估计的任何偏差。
因此,Q学习可以在不知道任何系统动力学\((A,B)\)的情况下在线有效地求解Riccati方程。
Werbos[1991, 1992]的一些想法对Q很有吸引力。首先,已经找到了一种替代路径,可以在不经过系统动力学的情况下反向传播偏导数\(\partial/\partial u_k\)(比较(58)和(77))。第二,Q函数批判NN(72)现在不仅有状态\(x_k\),而且有控制动作\(u_k\)作为它的输入。这就是\(\partial /\partial u_k\)可以不经过系统进行评估的原因。我们说批评家现在依赖于行动;因此,Werbos将此称为动作依赖HDP (AD HDP)。
7.5 Dual or Gradient Learning
基于该值的HDP强化学习方法可以使用Bellman或不动点方程来确定
基于Q函数的AD HDP强化学习方法可以通过Bellman或不动点方程来确定
它的值和Q函数都是标量,因此学习是在来自环境的相当贫乏的响应刺激的基础上进行评估的,对于具有大量n个状态的系统,收敛速度可能会很慢。
Werbos[1989, 1991, 1992]提出了在costate上使用强化学习技术。
这是一个n向量梯度,因此包含比值更多的信息。他称之为双重启发式编程(DHP)。要做到这一点,必须找到一个不动点方程的余态。这很容易通过微分得到
或者
为规定的政策\(u_k=h(x_k)\)。现在可以使用神经网络结构来近似\(\lambda _k\),并进行强化学习。
不幸的是,任何基于不动点方程的强化学习方案都需要自\(\partial x_{k+1}/\partial x_k=f(x_k),\partial x_{k+1}/\partial u_k=g(x_k)\)以来的全动力学知识。此外,这需要对n向量进行在线RLS实现,这是计算密集型的。
类似地,你可以找到强化学习技术-基于梯度的Q函数\(\lambda_k^x=\partial Q_h(x_k,u_k)/\partial x(k),\lambda _k^u=\partial Q_h(x_k,u_k)/\partial u_k\)。这被称为AD DHP,和DHP有相同的缺陷。
参考:
[1] Adaptive Dynamic Programming: An Introduction.
[2] Reinforcement Learning and Adaptive Dynamic Programming for Feedback Control.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号