

1.缓存的简单使用
1.1 不使用缓存实现查询
(1)创建用户表
用户信息表中包含用户ID,用户名,密码等字段



DROP TABLE IF EXISTS `user` CREATE TABLE USER( `id` BIGINT(20) NOT NULL COMMENT '用户ID', `username` VARCHAR(20) NULL DEFAULT '' COMMENT '用户名', `password` VARCHAR(20) NULL DEFAULT '' COMMENT '密码', PRIMARY KEY (`id`) USING BTREE )ENGINE=INNODB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci COMMENT = '用户';
(2)导入MySQL和Mybatis依赖
依赖中主要涵盖mysql、druid以及Mybatis的依赖
<properties> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <spring-boot.version>2.4.5</spring-boot.version> <guava.version>18.0</guava.version> <!--redisson--> <redisson.version>3.16.3</redisson.version> <commons-lang3.version>3.3.2</commons-lang3.version> <fastjson.version>1.2.72</fastjson.version> <joda-time.version>2.6</joda-time.version> <!--mysql相关--> <jdbc.version>8.0.11</jdbc.version> <druid.version>1.2.3</druid.version> <!--Mybatis相关--> <!--<mybatis.version>3.4.6</mybatis.version>--> <mybatis.spring.version>1.3.2</mybatis.spring.version> </properties> <dependencies> <!--basic--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>${guava.version}</version> </dependency> <!--为Redis数据库提供了高级的分布式解决方案,包括分布式锁、同步器、计数器、映射、集合、 BitSet、HyperLogLog等多种数据结构的直接支持 创建Redisson客户端实例,进而使用其丰富的API来实现诸如分布式锁、缓存、消息发布/订阅等功能, 极大地简化了基于Redis的分布式应用开发--> <dependency> <groupId>org.redisson</groupId> <artifactId>redisson</artifactId> <version>${redisson.version}</version> </dependency> <!--redis--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>${commons-lang3.version}</version> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>${fastjson.version}</version> </dependency> <!--Joda-Time是一个流行的日期和时间处理库,它提供了比Java原生的java.util.Date和java.util.Calendar 更强大、易用的时间日期操作功能--> <dependency> <groupId>joda-time</groupId> <artifactId>joda-time</artifactId> <version>${joda-time.version}</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>${jdbc.version}</version> </dependency> <!--阿里开发的高性能Java数据库连接池,为高并发、高性能项目设计 它不仅是个数据库连接池,还包含监控、日志、SQL解析等功能--> <!--高性能:Druid优化了连接的创建和回收策略,减少了资源消耗,提升了数据库访问速度。 监控统计:内置了监控统计功能,可以实时查看连接池状态、SQL执行情况等,有助于诊断和优化数据库访问性能。 安全防护:支持SQL注入防御,通过内置的WallFilter可以防止恶意SQL执行。 扩展性强:提供了丰富的配置选项,易于集成和定制,支持多种数据库类型,包括但不限于MySQL、Oracle、PostgreSQL、SQL Server等。 资源泄露预防:具备连接泄露检测能力,能够自动回收泄露的连接,保证资源的有效利用。--> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>${druid.version}</version> </dependency> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>${mybatis.spring.version}</version> </dependency> <!-- aop--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-aop</artifactId> </dependency> <!--Jackson 对于 application/xml 媒体类型也提供了一个实现:MappingJackson2XmlHttpMessageConverter。 只需要在 pom.xml 中添加如下依赖,即可自动注册:--> <dependency> <groupId>com.fasterxml.jackson.dataformat</groupId> <artifactId>jackson-dataformat-xml</artifactId> </dependency> </dependencies>
(3)配置文件中配置MySQL以及Mybatis相信息
在配置文件中,编写mysql与Mybatis相关配置(可自行配置)
# 将之前Seckill中的jdbc配置文件的格式拿过来用,如果要拿着用的话,需要配置相应的配置文件和配置类 spring.datasource.url=jdbc:mysql://localhost:3306/test_study?useUnicode=true&characterEncoding=UTF-8&connectTimeout=2000&socketTimeout=5000&serverTimezone=UTC&useSSL=false spring.datasource.username=root spring.datasource.password=root spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver #MyBatis #扫描Mapper接口 mybatis.scanPackages=com.ku.test.cache.mapper #Mapper.xml文件的存放位置相对路径 mybatis.mapper-locations=classpath*:mapper/*.xml #实体类的相对路径 mybatis.type-aliases-package=com.ku.test.cache.entity
(4)定义配置类,配置数据库,Mybatis相关配置
如果需要配置druid,需要自己扩展编写一个JDBC的配置类来配置druid。
如果需要配置Mybatis中的某些配置,也需自己编写一个配置类进行配置
(5)创建用户实体类
/** * serialVersionUID是一个用来表明类版本的私有静态常量,主要用于序列化和反序列化的兼容性控制。 * 当你没有显式地为类定义这个序列化ID时,Java编译器会自动为实现Serializable接口的类生成一个基于类结构的默认serialVersionUID值。 * 但是,自动生成的值在类的结构(比如添加、删除、更改了成员变量)发生变化时,也会改变, * 这可能导致序列化后的对象无法正确反序列化 * * 生成的值通常是负数,这是因为习惯上避免与可能的自动生成的正数冲突,虽然这不是强制要求。 * 可使用IDE手动生成一个,好处在于就算修改了类的接口,也能确保老版本的序列化对象能够被新版本的类正确反序列化 */ public class User implements Serializable { private static final long serialVersionUID = -3004624289691589697L; private Long id; private String username; private String password; public Long getId() { return id; } public void setId(Long id) { this.id = id; } public String getUsername() { return username; } public void setUsername(String username) { this.username = username; } public String getPassword() { return password; } public void setPassword(String password) { this.password = password; } }
(6)创建用户Mapper和对应的Mapper.xml
@Mapper public interface UserMapper { //根据用户名获取用户信息 User getUserByUsername(String username); } <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.ku.test.cache.mapper.UserMapper"> <resultMap id="baseResultMap" type="com.ku.test.cache.entity.User"> <id column="id" property="id" jdbcType="INTEGER"/> <result column="username" property="username" jdbcType="VARCHAR"/> <result column="password" property="password" jdbcType="VARCHAR"/> </resultMap> <sql id="Base_Column_List"> id, username, password </sql> <select id="getUserByUsername" resultMap="baseResultMap"> select <include refid="Base_Column_List" /> from user where username = #{username} </select> </mapper>
(7)用户Service及其ServiceImpl
public interface UserService { User getUserByUsername(String username); } @Service public class UserServiceImpl implements UserService { @Autowired private UserMapper userMapper; @Override public User getUserByUsername(String username) { return userMapper.getUserByUsername(username); } }
(8)用户Controller
@RestController @RequestMapping("/user") public class UserController { @Autowired private UserService userService; // @ExecuteTime @GetMapping(value = "/getUser") public ResponseMessage<User> getUser(@RequestParam("username") String username){ return ResponseMessageBuilder.build(ResultCode.SUCCESS.getCode(), userService.getUserByUsername(username)); } }
(9)异常类
public class TestException extends RuntimeException { private Integer code; public TestException(String message){ super(message); } public TestException(ResultCode resultCode){ this(resultCode.getCode(), resultCode.getMessage()); } public TestException(Integer code, String message){ super(message); this.code = code; } public Integer getCode() { return code; } public void setCode(Integer code) { this.code = code; } }
(10)异常捕获类
@RestControllerAdvice public class GlobalExceptionHandler { private static final Logger logger = LoggerFactory.getLogger(GlobalExceptionHandler.class); /** * 全局异常处理,统一返回状态码 * @ExceptionHandler(SeckillException.class):针对特定异常类型,进行定制化异常逻辑处理 */ @ExceptionHandler(TestException.class) public ResponseMessage<String> handleSeckillException(TestException e) { logger.error("服务器抛出了异常:{}", e); return ResponseMessageBuilder.build(e.getCode(), e.getMessage()); } /** * 全局异常处理,统一返回状态码 */ @ExceptionHandler(Exception.class) public ResponseMessage<String> handleException(Exception e) { logger.error("服务器抛出了异常:{}", e); return ResponseMessageBuilder.build(ResultCode.SERVER_EXCEPTION.getCode(), e.getMessage()); } }
(11)结果
为了测试有无添加缓存的目标方法执行时间,我定义了一个切面,计算方法执行的时间。
时间计算切面类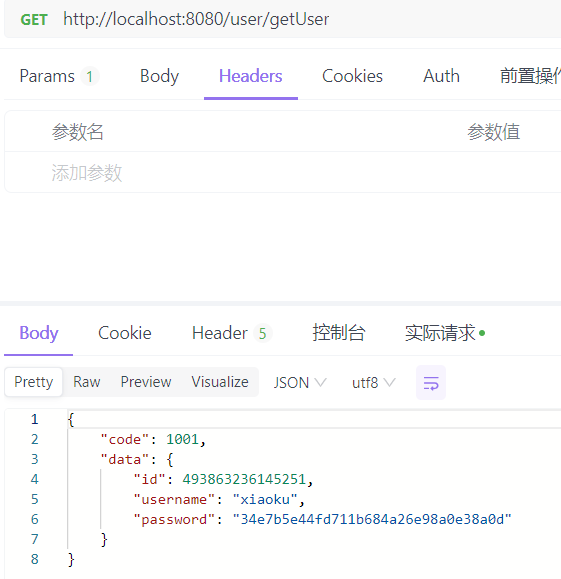

(12)出现的问题
Resolved [org.springframework.web.HttpMediaTypeNotAcceptableException: Could not find acceptable representation] //客户端请求期望响应的媒体类型与服务器响应的媒体类型不一致造成的。 // 在客户端的请求头中的Accept字段是"*/*"表示接收任何类型数据,但我现在不知我的服务器返回类型是什么,只是定义了一个ResponseMessage类实现了序列化 Resolved[org.springframework.http.converter.HttpMessageNotWritableException: No converter for [class com.ku.test.cache.response.ResponseMessage] with preset Content-Type 'null'] //原因:无法将 Java 对象转换为 HTTP 响应。 //Spring 依靠客户端的 Accept Header 来检测它需要响应的媒体类型(Media Type)。 //因此,使用未预注册消息转换器(Message Converter)的 Media Type 将导致 Spring 抛出异常 //解决办法:1)引入com.fasterxml.jackson.dataformat依赖(主要原因) //2)在请求方法上添加produces = MediaType.APPLICATION_JSON_VALUE解决了我的返回类型(验证后可加可不加) //解决方式的原因:找到了 APPLICATION_JSON_VALUE 媒体类型对应的 Message Converter // 实现:MappingJackson2HttpMessageConverter(属于com.fasterxml.jackson.dataformat依赖)。 //进阶:好像可以在代码中设置自己的Java对象并转化为HTTP响应
(13)小结
- 在这次测试中,深知自己动手较少(没有将照猫画虎的技术融入到自己的项目中),需要多思考多去做一些自己项目需要的东西,多去学习一些技术,然后在测试项目中验证后运用于自己项目。
- 要去实践每一种技术以及它的适用场景,明白为什么要用它,可否不使用它,不使用它会怎么样,使用了又会怎么样,是否还有其他技术替换它,最后是对其底层原理的理解。
1.2 缓存概述
Redis是常用的分布式缓存手段之一,除了分布式缓存还有本地缓存。两种缓存策略的目的都是提升数据访问速度以及减轻数据库的压力。
(1)缓存
概述:缓存是将访问量较高的热点数据从传统的关系型数据库中加载到内存中,当用户再次访问热点数据时是从内存中加载,减少了对数据库的访问量,解决了高并发场景下容易造成数据库宕机的问题。
(2)本地缓存
概述:数据存储在应用程序运行的同一台服务器的内存中,即数据无需经过网络直接在进程内部完成。
优势:
- 访问速度快:数据存储在本地内存,避免网络延迟,因此速度快;
- 减少网络开销:无需网络即可获取数据,减少系统网络开销;
- 简单易用:相对于分布式系统,设置于管理更加简单
不足:
- 容量有限:受本地服务器内存大小限制,不适合存储大量数据。
- 数据不共享:在分布式系统中,每个实例都有自己的本地缓存,数据不能在不同服务器间共享,可能导致数据不一致。
- 容错性差:如果应用实例宕机,其上的本地缓存数据会丢失。
- 扩展困难:随着应用规模扩大,本地缓存难以水平扩展以应对更高的并发和数据量。
(3)分布式缓存
概述:将数据分散存储在多个服务器之间分布数据,形成一个可以水平扩展的缓存层。这些服务器可以是专门用于缓存的独立系统。分布式缓存需要通过远程网络请求来完成分布式缓存的读写操作,并且分布式缓存主要应用在应用程序集群部署的环境下。
优势:
- 高可用性和可扩展性和高并发:通过在多台服务器之间分布数据,即使某一台服务器发生故障,也不会导致整个缓存服务不可用。同时,可以根据需要增加更多服务器来扩展缓存容量。读110000次/秒,写81000次/秒。
- 数据共享:对于多服务器部署的应用程序,所有服务器可以共享同一份缓存数据,保证了数据的一致性。
- 大容量存储:能够存储更多的数据,适合处理大规模数据缓存需求。
- 丰富的数据结构支持:如Redis这样的分布式缓存系统,支持多种数据结构,便于处理复杂的数据缓存场景。
不足:
- 网络延迟:相比本地缓存,分布式缓存需要通过网络访问,可能会引入额外的延迟。
- 复杂性:配置、维护和监控分布式缓存系统相对复杂,需要额外的运维工作。
- 成本:可能需要额外的硬件资源来部署和维护缓存集群。
- 一致性挑战:在多节点环境中保持数据一致性是一个挑战,需要复杂的分布式协议来管理。
本地缓存更适合那些对访问速度要求极高且数据量不是特别大的应用场景,而分布式缓存则适用于需要高可用性、大容量存储和多服务器数据共享的大型分布式系统。在实际应用中,根据具体需求,开发者可能会选择使用单一类型的缓存或结合两者(例如多级缓存策略),以达到最佳的性能和效率。
(4)多级缓存
多级缓存的请求流程: 本地缓存作为一级缓存,分布式缓存作为二级缓存;当用户获取数据时,先从一级缓存中获取数据,如果一级缓存有数据则返回数据,否则从二级缓存中获取数据。如果二级缓存中有数据则更新一级缓存,然后将数据返回客户端。如果二级缓存没有数据则去数据库查询数据,然后更新二级缓存,接着再更新一级缓存,最后将数据返回给客户端。
1.3 缓存刷新机制
热点数据放入缓存中并不是一直不变的,它是会更新的(刷新,过期,失效)。因此需要设计缓存刷新机制来刷新缓存,保持缓存与数据库的数据一致性。防止缓存击穿。
(1)本地缓存
- 主动刷新:版本号
- 被动刷新:缓存过期
(2)分布式缓存
- 主动刷新:业务数据更新
- 被动刷新:缓存过期
1.4 缓存实现
1.4.1 创建缓存
(1)本地缓存- 导入本地缓存所需依赖;
- 创建一个本地缓存工厂类,定义一个静态泛型方法通过Guava或Caffeine的建造者模式创建缓存实例;
- 定义一个本地缓存接口,定义put()方法和getIfPresent()方法;
- 定义一个具体的本地缓存类,通过本地缓存工厂类创建一个本地缓存实例实现本地缓存接口中的方法。
public class LocalCacheFactory { /* //前面的<K, V>表示未知的类型,表示泛型类型参数列表。声明该方法为泛型方法 后面的Cache<K, V>表示方法的返回类型 */ public static <K, V> Cache <K, V> getGuavaLocalCache(){ /* 建造者模式,允许客户端一步步设置所有配置,通过build创建复杂的对象 构建过程更加清晰,灵活配置各项参数,不需要复杂的构造函数和各种工厂方法 避免构造函数中传递大量可选参数,提高代码的可读性和可维护性 */ /** * * 建造者模式:将一个复杂对象的构建与表示分离,使同样的构造过程产生不同的表示 * 使用场景:当一个类的构造函数参数超过4个时,而这些参数有些事可选,考虑使用建造者模式 * 建造者模式是链式调用的 */ return CacheBuilder.newBuilder() .initialCapacity(15)//初始容量 .concurrencyLevel(5)//并发度:允许5个并发执行 .expireAfterWrite(5, TimeUnit.SECONDS)//缓存过期时间 .build(); } }
public interface LocalCacheService<K, V> { void put(K key, V value); V getIfPresent(Object key); } @Service public class GuavaLocalCacheService<K, V> implements LocalCacheService<K, V> { //基于Guava实现本地缓存 private final Cache<K, V>cache = LocalCacheFactory.getGuavaLocalCache(); @Override public void put(K key, V value) { cache.put(key, value); } @Override /** * 意图明确:此方法的主要目的是查询缓存中是否存在某个键对应的值,如果存在则返回,否则返回null(或在某些情况下是默认值)。 * 这种方法让调用者能够明确知道他们正在尝试获取一个已知存在的缓存项,而不需要处理因为键不存在而导致的异常或默认行为。 * 避免副作用:与直接使用get方法相比,它可以避免潜在的副作用。例如,在Guava的LoadingCache中,直接调用get方法在键不存在时 * 会触发CacheLoader加载数据,这可能涉及数据库查询或其他成本较高的操作。而getIfPresent则不会触发这些操作。 * 性能考量:对于不需要加载缺失值的场景,它可以减少不必要的计算和网络开销,提高效率。 */ public V getIfPresent(Object key) { return cache.getIfPresent(key); } }
(2)分布式缓存
- 导入分布式缓存所需依赖;
- 在配置文件中,对分布式缓存(如Redis)进行配置;
- 创建一个分布式缓存的泛型接口,定义put()方法(包含普通、过期时间),get()方法、delete()方法、hashKey()方法;
- 创建一个分布式缓存的配置类,对@Bean注解标注的方法的Restemplate实例进行key、value的序列化、时间的序列化和反序列化;
- 创建一个分布式缓存的实现类,注入分布式缓存的实例(如Restemplate实例),通过该实例的键值对操作进行put()方法、get()方法,实例的delete()方法,hashKey()方法操作。
public interface DistributeCacheService<K, V> { void put(K key, V value); //两个方法都用于向缓存中插入键值对,但它们在设置键值对过期时间的方式上有所不同 //第一个方法更适合设置相对过期时间(如“过期时间=当前时间+X单位”),而第二个方法适合直接指定一个具体的过期时间点 void put(K key, V value, long timeout, TimeUnit unit);//绝对时间 void put(K key, V value, long expireTime);//时间间隔 <T> T getObject(K key, Class<T>targetClass); V getObject(K key); Boolean delete(K key); Boolean hasKey(K key); } @Service public class RedisCacheService<K, V> implements DistributeCacheService<K, V> { @Autowired private RedisTemplate<K, V> redisTemplate; //redisTemplate.opsForValue()适合处理键值对存储,用于操作Redis中字符串类型(String类型)值的一系列操作 @Override public void put(K key, V value) { if (ObjectUtils.isEmpty(key) || ObjectUtils.isEmpty(value)) return; redisTemplate.opsForValue().set(key, value); } @Override public void put(K key, V value, long timeout, TimeUnit unit) { if (ObjectUtils.isEmpty(key) || ObjectUtils.isEmpty(value)) return; redisTemplate.opsForValue().set(key, value, timeout, unit); } @Override public void put(K key, V value, long expireTime) { if (ObjectUtils.isEmpty(key) || ObjectUtils.isEmpty(value)) return; redisTemplate.opsForValue().set(key, value, expireTime); } @Override public <T> T getObject(K key, Class<T> targetClass) { V value = redisTemplate.opsForValue().get(key); if (ObjectUtils.isEmpty(value)) return null; try{ //将一个JSON格式的字符串(value)转换成指定Java类(targetClass)的对象 return JSON.parseObject((String)value, targetClass); }catch (Exception e){ return null; } } @Override public V getObject(K key) { return redisTemplate.opsForValue().get(key); } @Override public Boolean delete(K key) { if (ObjectUtils.isEmpty(key)) return false; return redisTemplate.delete(key); } @Override public Boolean hasKey(K key) { return redisTemplate.hasKey(key); } }
(3)分布式ID生成
雪花算法可由四部分组成,分别是时间戳、机器ID,数据中心ID,序列号。ID全局唯一、递增、高性能、高可用。
下面这段代码是从一篇博客借鉴来的,博客链接:分布式ID生成工具类-雪花算法_分布式雪花算法工具类-CSDN博客
public class SnowflakeIdWorker { /** * 开始时间截 (2015-01-01) */ private final long twepoch = 1420041600000L; /** * 机器id所占的位数 */ private final long workerIdBits = 5L; /** * 数据标识id所占的位数 */ private final long datacenterIdBits = 5L; /** * 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */ private final long maxWorkerId = -1L ^ (-1L << workerIdBits); /** * 支持的最大数据标识id,结果是31 */ private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); /** * 序列在id中占的位数 */ private final long sequenceBits = 12L; /** * 机器ID向左移12位 */ private final long workerIdShift = sequenceBits; /** * 数据标识id向左移17位(12+5) */ private final long datacenterIdShift = sequenceBits + workerIdBits; /** * 时间截向左移22位(5+5+12) */ private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits; /** * 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */ private final long sequenceMask = -1L ^ (-1L << sequenceBits); /** * 工作机器ID(0~31) */ private long workerId; /** * 数据中心ID(0~31) */ private long datacenterId; /** * 毫秒内序列(0~4095) */ private long sequence = 0L; /** * 上次生成ID的时间截 */ private long lastTimestamp = -1L; /** * 构造函数 * @param workerId 工作ID (0~31) * @param datacenterId 数据中心ID (0~31) */ public SnowflakeIdWorker(long workerId, long datacenterId) { if (workerId > maxWorkerId || workerId < 0) { throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId)); } if (datacenterId > maxDatacenterId || datacenterId < 0) { throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId)); } this.workerId = workerId; this.datacenterId = datacenterId; } /** * 获得下一个ID (该方法是线程安全的) * @return SnowflakeId */ public synchronized long nextId() { long timestamp = timeGen(); // 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常 if (timestamp < lastTimestamp) { throw new RuntimeException( String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp)); } // 如果是同一时间生成的,则进行毫秒内序列 if (lastTimestamp == timestamp) { sequence = (sequence + 1) & sequenceMask; // 毫秒内序列溢出 if (sequence == 0) { //阻塞到下一个毫秒,获得新的时间戳 timestamp = tilNextMillis(lastTimestamp); } } // 时间戳改变,毫秒内序列重置 else { sequence = 0L; } // 上次生成ID的时间截 lastTimestamp = timestamp; // 移位并通过或运算拼到一起组成64位的ID return ((timestamp - twepoch) << timestampLeftShift) // | (datacenterId << datacenterIdShift) // | (workerId << workerIdShift) // | sequence; } /** * 阻塞到下一个毫秒,直到获得新的时间戳 * @param lastTimestamp 上次生成ID的时间截 * @return 当前时间戳 */ protected long tilNextMillis(long lastTimestamp) { long timestamp = timeGen(); while (timestamp <= lastTimestamp) { timestamp = timeGen(); } return timestamp; } /** * 返回以毫秒为单位的当前时间 * @return 当前时间(毫秒) */ protected long timeGen() { return System.currentTimeMillis(); } public static void main(String[] args) throws InterruptedException { SnowflakeIdWorker idWorker = new SnowflakeIdWorker(0, 0); for (int i = 0; i < 10; i++) { long id = idWorker.nextId(); Thread.sleep(1); System.out.println(id); } } }
(4)密码加密
密码加密是通过shiro框架的加密类生成的密码,将username作为盐值,通过MD5算法进行加密。
public class CommonUtils { //生成密码 public static final String encryptPassword(String username, String password){ return String.valueOf(new SimpleHash("MD5", password, username, 1024)); } }
参考链接:
【416期】面试官:说说什么是本地缓存、分布式缓存以及多级缓存,它们各自的优缺点? | 极客之音 (bmabk.com)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?