
1.多线程基础
前言
说到多线程,很让人头痛,刚开始学习基础的我亦是如此。由于最近还没有接触到多线程的项目,感觉它对我的作用微乎其微;毕业季在即,得知我的一位学长在秋招中斩获二线厂的SP,我就请教了一下他的简历;虽然它是学C++的,但是可借鉴的东西很多。在我仔细阅读他的简历,我发现多线程和语言基础以及计算机网络和操作系统基础都是重中之重,最好还要结合项目来体现。说到多线程的作用,大家可以参考该链接(4条消息) 简述多线程的作用以及什么地方用到多线程_今天明天_007的博客-CSDN博客。
1.线程创建的三种方式
1.1 继承Thread类来创建多线程
实现代码:



package com.ku.juc.createthread; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class KuThread { public static void main(String[] args) { MyThread mt1 = new MyThread("小库"); MyThread mt2 = new MyThread("他"); mt1.start(); mt2.start(); } } class MyThread extends Thread{ static Logger log = LoggerFactory.getLogger(MyThread.class); private String name; public MyThread(String name) { this.name = name; } @Override public void run() { log.info(name+"正在努力学习!"); } }
运行结果:
![]()
代码中的日志可以参考我的另外一篇博客多线程结合自定义logback日志实现简单的工单日志输出 - 求知律己 - 博客园 (cnblogs.com),当然也可以直接使用系统自带的接口来实现简单的日志打印,只需要定义一个像我代码中的静态对象,调用对象方法也可以实现简便的日志打印。
1.2 实现Runnable接口创建多线程
1.2.1实现runnable接口创建多线程
实现代码:
Runnable mt1 = new RunnableThread("小库"); Runnable mt2 = new RunnableThread("他"); Thread t1 = new Thread(mt1); Thread t2 = new Thread(mt2); t1.start(); t2.start(); class RunnableThread implements Runnable{ private String name; static Logger log = LoggerFactory.getLogger(RunnableThread.class); public RunnableThread(String name) { this.name = name; } @Override public void run() { log.info(name+"正在学习中..."); } }
运行结果:
实现Runnable接口创建多线程的源码
public Thread(Runnable target, String name) {
init(null, target, name, 0);
}
上面就是使用Runnable接口创建多线程的源码,其中target是指Runnable接口对象,后面的name就是自定义命名。
1.2.2.使用lambda简化上述多线程创建
Thread t1 = new Thread(() ->{
log.info(Thread.currentThread().getName()+"正在努力学习");
}, "小库");
Thread t2 = new Thread(() ->{
log.info(Thread.currentThread().getName()+"正在努力学习");
}, "他");
t1.start();
t2.start();
运行结果:
![]()
在创建多线程中,我们可以给当前的线程进行命名,并且通过调用Thread.currentThread()方法获取当前线程,再通过Thread.currentThread().getName()方法获取当前线程名。
1.3 实现Callable接口创建多线程
该方法创建多线程不同于上面两种方法,该接口的对象作为FutureTask接口的对象,而FutureTask接口实现了RunnableFuture<V>接口,并进行了扩充,而RunnableFuture接口实现了Runnable接口和Future接口,所以Callable接口可以自定义返回值。以下是FutureTask接口的源码
public FutureTask(Callable<V> callable) { if (callable == null) throw new NullPointerException(); this.callable = callable; this.state = NEW; // ensure visibility of callable }
public class FutureTask<V> implements RunnableFuture<V> {}
public interface RunnableFuture<V> extends Runnable, Future<V> {
/**
* Sets this Future to the result of its computation
* unless it has been cancelled.
*/
void run();
}
代码实现
Callable ct1 = new CallableThread("小库"); Callable ct2 = new CallableThread("他"); FutureTask<Integer> ft1 = new FutureTask<Integer>(ct1); FutureTask<Integer> ft2 = new FutureTask<Integer>(ct2); Thread t1 = new Thread(ft1); Thread t2 = new Thread(ft2); t1.start(); t2.start(); log.info(t1.getName()+"结果为:"+ft1.get()); log.info(t2.getName()+"结果为:"+ft2.get()); //上面是测试类 class CallableThread implements Callable<Integer>{ Logger log = LoggerFactory.getLogger(CallableThread.class); private String name; public CallableThread(String name) { this.name = name; } @Override public Integer call() throws Exception { Integer sum = 0; for (int i = 0; i < 5 ; i++) { sum += i; log.info(this.name +i); } return sum; } }
运行结果

2.线程的基本方法
2.1 线程状态转换
在多线程的方法中start()方法和run()方法是最基础的方法之一,线程的运行可以分为七种状态,执行顺序依次是new、Runnable、Running、Waiting、Blocked、Timed-Wating、Terminated。
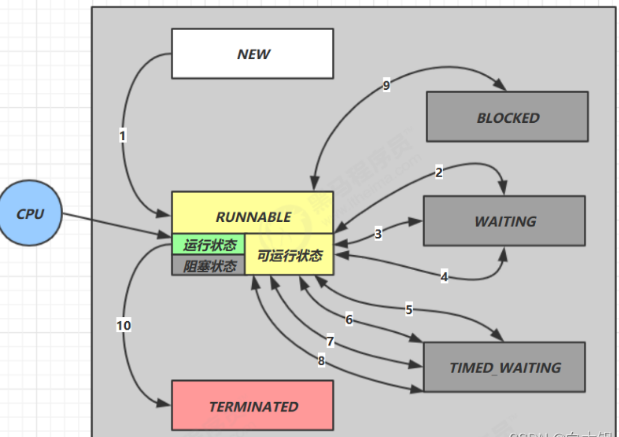
上图中将Runnable与Running合并了,当创建一个线程对象的时候就是new状态、当我们调用start()方法时,线程就从new状态转变为了Runnable状态,调用run()方法之后就从Runnable状态转换为Running状态了,调用sleep()方法就进入了BLOCKED状态,当某线程获得使用synchronized获得锁后调用wait方法或者调用join()方法就进入了Waiting状态,调用wait(long mills)进入了Timed-waiting状态,最后执行完任务就进入了Terminated状态。
2.2 start()和run()方法
当一个线程调用start()方法时,说明该线程已经进入Runnable状态等待CPU的时间片分配,将启动一个新线程。Run()方法相当于普通的方法调用,执行线程中的任务。使用多线程时,使用start()方法启动多线程,但是我们不能直接调用run()方法,以下是直接调用run()方法的代码和结果。
实现代码
public static void main(String[] args) {
Logger log = LoggerFactory.getLogger(TestThread.class);
new Thread(() -> {
log.info(Thread.currentThread().getName());
}, "t1").run();
}
运行结果
![]()
我们预想的结果是打印我们命名为1的线程名,但是结果发现,它虽然执行了run方法的获取该线程名语句,但是它输出的并不是我们命名为1的线程,而是主方法的线程名。
public static void main(String[] args) { Logger log = LoggerFactory.getLogger(TestThread.class); new Thread(() -> { log.info(Thread.currentThread().getName()); }, "t1").start(); }
![]()
当我们使用start()方法启动线程时,会发现它才是我们要的结果,所以我们要认清start()与run()方法的区别,即调用start()方法才会结合run()方法执行该线程的任务,直接调用run()方法是执行主线程的任务。
小结
- start()方法会在新的线程中执行run()方法,run()方法时在当前线程中执行run()方法;
- start()方法会立即返回,不会等待run()方法执行完毕,run()方法会一直执行到结束;
- start()方法只能被调用一次,run()方法可以被多次调用。
2.3 sleep()方法(线程休眠)
sleep()方法即线程休眠方法,当我们调用该方法时,该线程会进入休眠状态,且当我们获得锁后在进入休眠状态,它也不会释放锁。
实现代码
new Thread(() -> { for (int i = 0; i < 10 ; i++) { if (i == 5){ try { log.info(Thread.currentThread().getName()+"-----"+i); Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } log.info(Thread.currentThread().getName()+"-----"+i); } } },"t2").start();
运行结果
![]()
从上图我们,可以发现当我们调用Thread.sleep(2000)方法后,我们的值是过了2s才输出的,Thread.sleep()方法就是休眠方法,其中2000表示2s。
2.4 interrupt()方法(线程中断)
interrupt()方法即线程中断方法,它既可以打断正在运行的线程,也可以打断正在sleep的线程。当它打断运行的线程时不会清空打断的状态,当它打断正在sleep的线程时会清空打断状态。
打断运行线程的代码实现
Logger log = LoggerFactory.getLogger(TestThread.class); Thread t1 = new Thread(() -> { while(true){ Thread current = Thread.currentThread(); boolean interrupted = current.isInterrupted(); if (interrupted){ log.info(Thread.currentThread().getName()+",打断状态:{}",interrupted); break; } } }); t1.start(); Thread.sleep(500); t1.interrupt();
运行结果
![]()
从上述结果我们可以得出答案,当我们给正在运行的线程使用interrupt()方法进行打断的时候,它的打断标记并没有清除,下面我们再来验证下休眠状态进行打断时,会不会清除标记?
打断休眠线程的代码实现
Thread t3 = new Thread(() -> { try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } }); t3.start(); Thread.sleep(1000); t3.interrupt(); log.debug(t3+"打断状态:{}", t3.isInterrupted());
运行结果

从上面运行结果我们可以看出。当我们使用interrupt打断正在睡眠的线程时,它的打断标记会清除。我们可以使用interrupted()方法清除打断状态
2.5 join()方法(线程强制执行)
线程强制执行是指,当有两个线程同时执行,当其中调用join()方法时,另外一个线程得等待它执行完之后才能执行。
代码实现
Thread t5 = new Thread(() -> { log.info(Thread.currentThread().getName()); }, "t5"); Thread t6 = new Thread(() -> { log.info(Thread.currentThread().getName()); }, "t6"); t5.start(); t6.start();
Thread t5 = new Thread(() -> { log.info(Thread.currentThread().getName()); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } }, "t5"); Thread t6 = new Thread(() -> { log.info(Thread.currentThread().getName()); }, "t6"); t5.start(); t5.join(1000); t6.start();
运行结果


在上述代码中,我在线程t5中添加了sleep()方法以及join()方法,如果不添加slee()方法不能比较出join()方法的作用,为什么呢?
因为CPU执行效率太快,我们的t6在t5执行之后就马上执行了,就不需要等待,当我们在线程t5中添加Thread.sleep(2000)时,使用join()方法时,t5还没执行完,所以t6必须等待t5执行完1s后才能执行。
2.6 yield()方法(线程让步)
线程让步是指我主动让出我的线程给其他的线程执行。
代码实现
Thread t7 = new Thread(() -> { for (int i = 0; i < 5 ; i++) { try { Thread.sleep(1000); log.info(Thread.currentThread().getName()+ "-------" + i); } catch (InterruptedException e) { e.printStackTrace(); } } }, "t7"); Thread t8 = new Thread(() -> { for (int i = 0; i < 5 ; i++) { try { Thread.sleep(1000); log.info(Thread.currentThread().getName()+ "-------" + i); } catch (InterruptedException e) { e.printStackTrace(); } } }, "t8"); t7.start(); t8.start();
Thread t7 = new Thread(() -> { for (int i = 0; i < 5 ; i++) { try { Thread.sleep(1000); Thread.yield(); log.info(Thread.currentThread().getName()+ "-------" + i); } catch (InterruptedException e) { e.printStackTrace(); } } }, "t7"); Thread t8 = new Thread(() -> { for (int i = 0; i < 5 ; i++) { try { Thread.sleep(1000); log.info(Thread.currentThread().getName()+ "-------" + i); } catch (InterruptedException e) { e.printStackTrace(); } } }, "t8"); t7.start(); t8.start();
运行结果
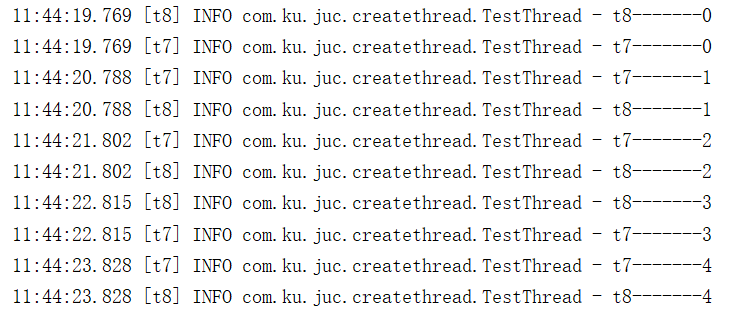

从上面结果我们可以看出没有使用yield()方法的时候几乎都是线程t7先执行,t8后执行,当使用了t7使用了yield()方法后,t8先执行,t7后后执行。
2.7 线程优先级
我们通常可以设置线程的优先级决定哪些线程可能先执行,哪些后执行(并不是一定),线程优先级分为10级,默认所有子线程都一样是5级,最高是10级,最低是1级。
实现代码
Thread t9 = new Thread(() -> { for (int i = 0; i < 5; i++) { log.info(Thread.currentThread().getName()+ "-------" + i); } },"t9"); Thread t10 = new Thread(() -> { for (int i = 0; i < 5; i++) { log.info(Thread.currentThread().getName()+ "-------" + i); } },"t10"); t10.setPriority(8); t9.start(); t10.start();
运行结果

从代码中我设置线程t10的优先级是8级,t9默认是5级,从结果上面可以看出先执行线程t10的情况多一些。
2.8 守护线程(daemon)
说到守护线程,就像父母守护孩子一样默默地付出,我们可以通过线程.setDaemon(true)实现设置某线程为守护线程。该线程会在主线程或子线程执行完后终止执行,不管守护线程中的任务是否执行完,JVM中的垃圾回收线程就是采用的守护线程。
实现代码
log.info("开始运行");
Thread t11 = new Thread(() -> {
try {
log.info("开始运行");
Thread.sleep(1000);
log.info("运行结束");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t11.setDaemon(true);
t11.start();
log.info("运行结束");
运行结果


从上述第二张图可以看出,当我们设置线程t11为守护线程的时候,它在主线程执行完后,不会再继续执行,另外一点请注意一点,那就是必须在t11.start()方法执行之前通过t11.setDaemon(true)来设置线程t11为守护线程,不然会像上面第一张图那样报错。
参考视频和博客链接
视频链接:https://www.bilibili.com/video/BV16J411h7Rd/?p=200&spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=028e67f9275f9317b1416d26055f74d5 博客链接:https://blog.csdn.net/weixin_45735355/article/details/121946452
以上视频是B站黑马程序员的,讲的很细;博客是CSDN上一个博主的,视频里面很多细节都在博客中体现了,也有一些原理还是没有记载全面。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~