


An Adaptive Localized Decision Variable Analysis Approach to Large-Scale Multiobjective and Many-Objective Optimization
回顾MOEA/D(3种分解方法即将多目标分解为单目标)
加权求和
这个方法只适合凸问题,通过一组权重向量
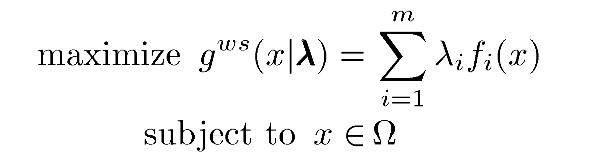
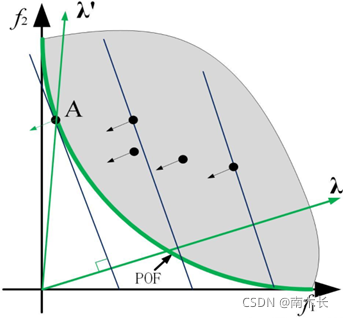
看这个图,先不用管
切比雪夫聚合法
(这里可以通过图像将λ1f1看成计算面积,那么很容易理解λ1f1=λ2*f2)

边界交叉聚合方法-BI Approach(最小化最小值参考点与权重向量上的所求解之间的距离)

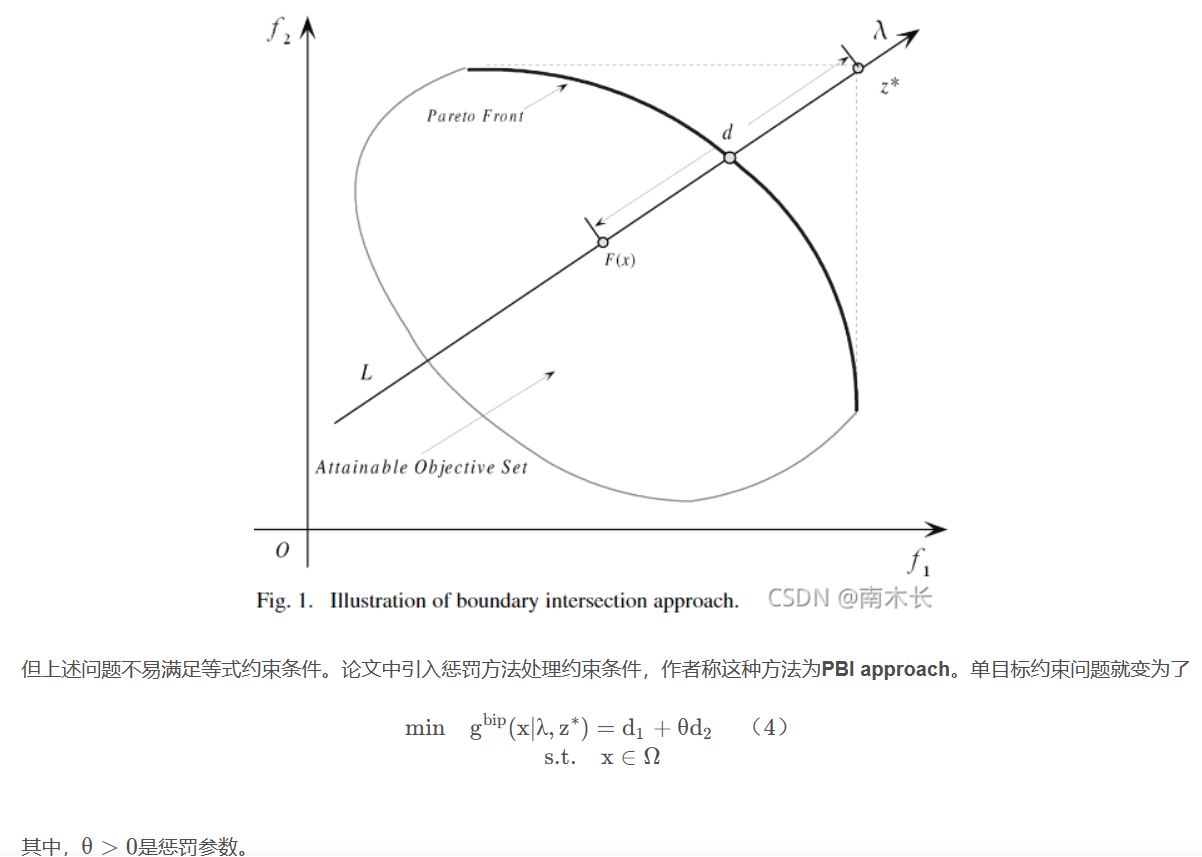
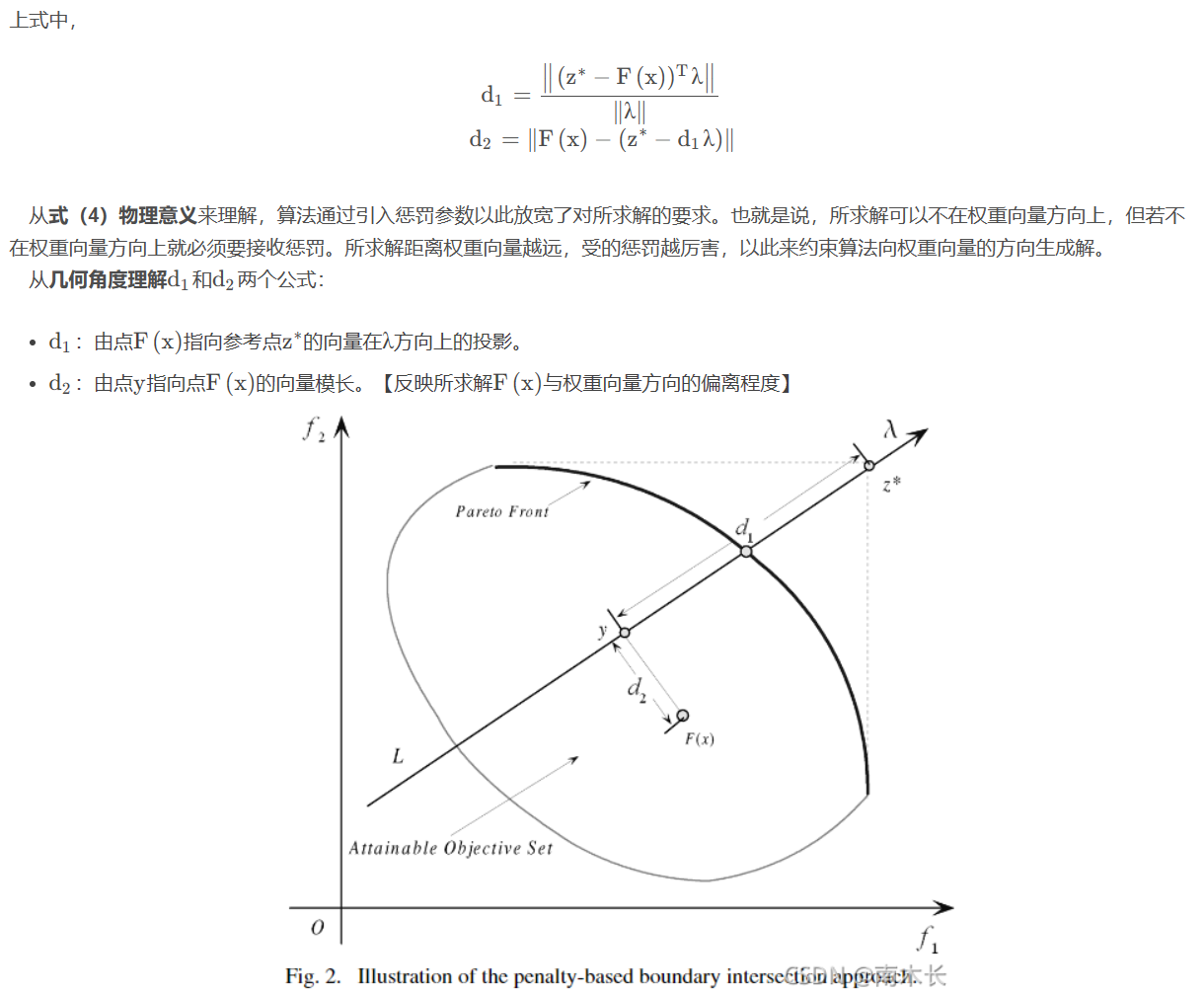
作者的ideal
作者通过实验发现不同目标区域下,变量的控制性能是不一样的,所以MOEA/D的变量分析是假定在优化的进程中变量控股性能是固定不变的,所以作者提出在不同的子区间去探索变量的收敛控制性能然后分组。
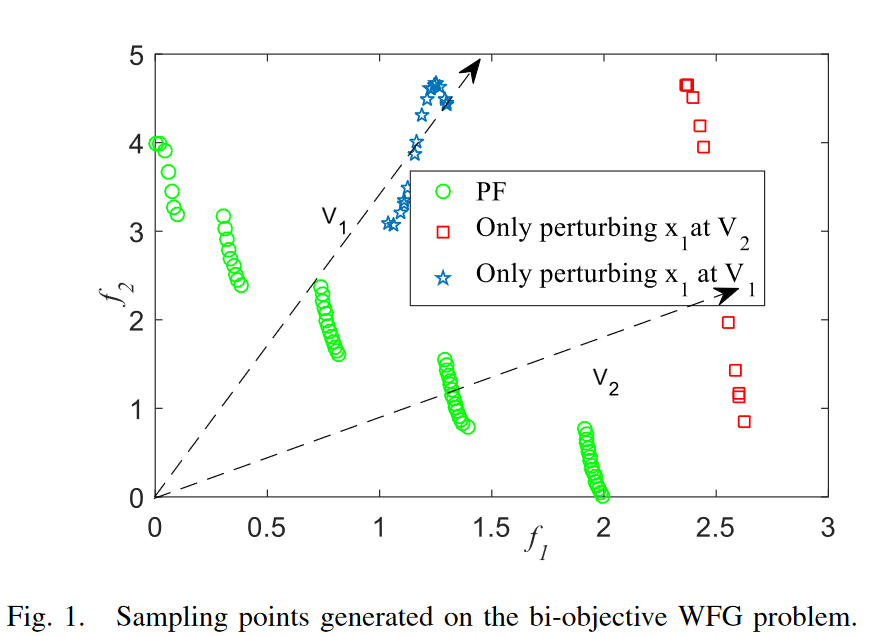
如图所示:在V1和V2两个区域内,分别只扰动x1但是得出的结论一个是收敛性相关变量,另外一个是多样性变量。
检测收敛性相关的方法
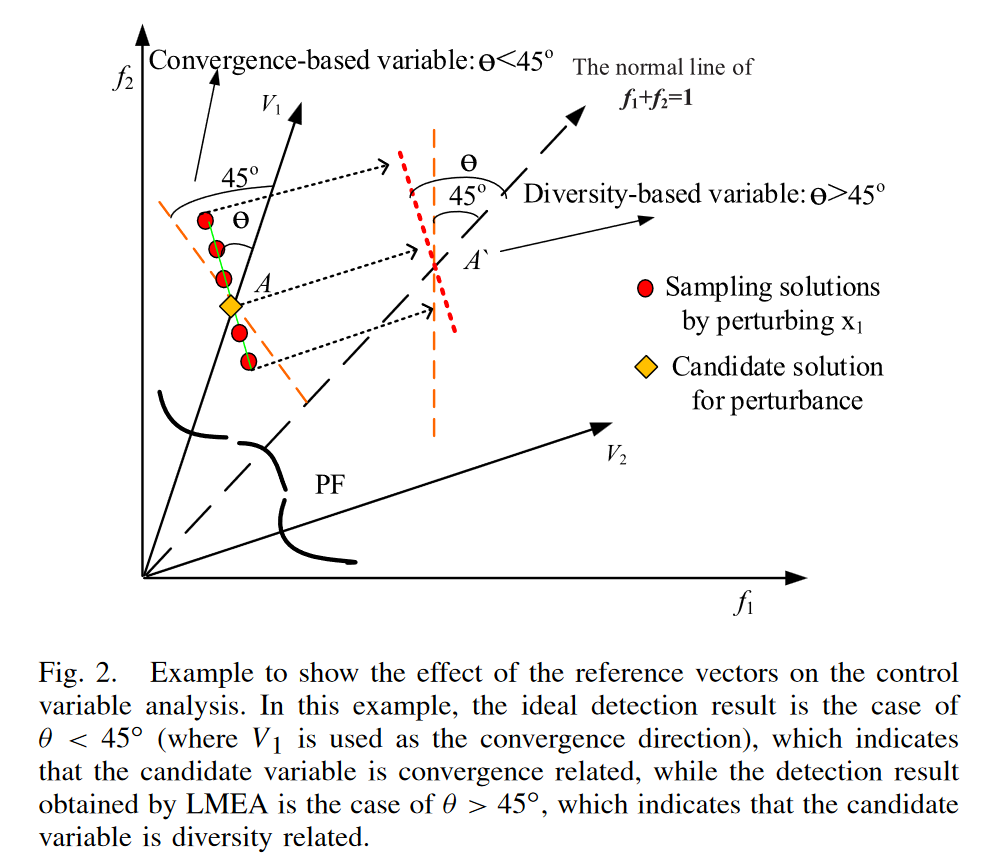
如图所示:在收敛方向V1上,扰动x1得到的解拟合形成的线和v1的夹角小于45°,所以判定为收敛性相关,反之就是多样性相关多一些。
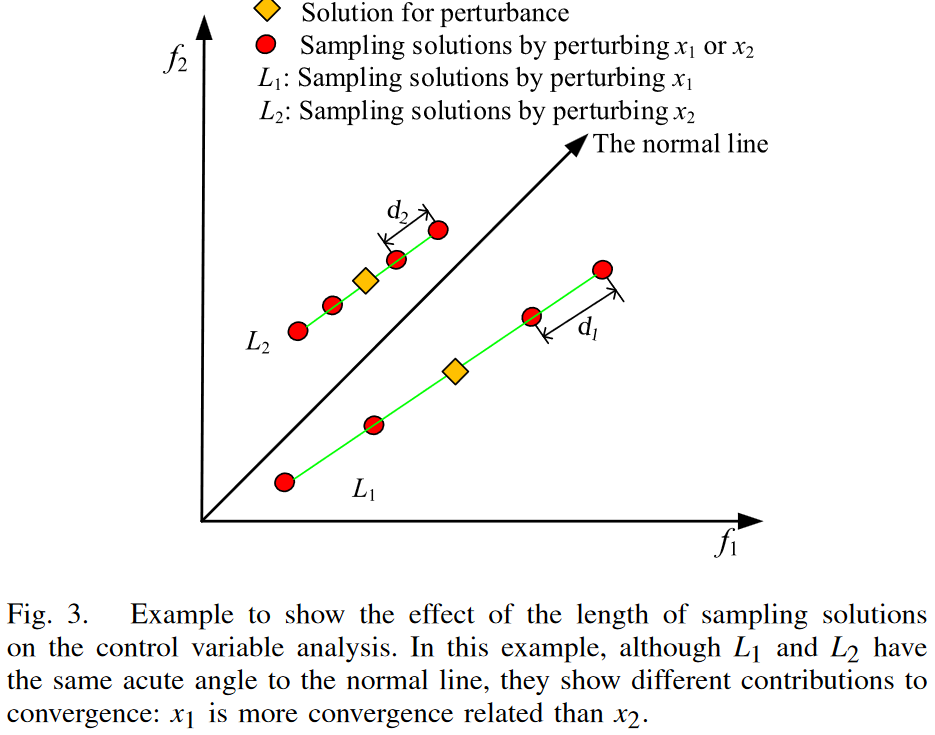
还有一种情形就是即使夹角大小相同反应变量对收敛程度的影响也不太一样。如图所示,在相同的子区域内,x2的收敛强度更强。
作者的做法
在不同的子区域内计算各个变量的收敛强度,然后排序然后分组也就是分成固定的几个subgroup进行优化。
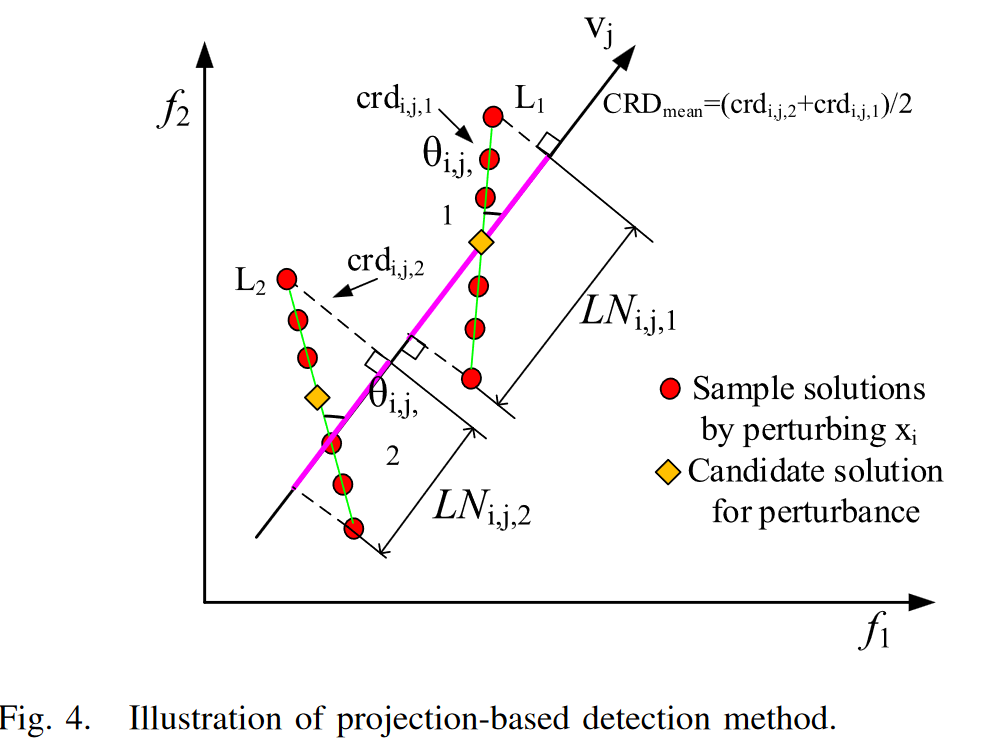
如图所示:在vj方向上扰动不同的xi得到的收敛度也不同,我们可以看出,收敛度越大的量,所形成的夹角越小,在vj上的投影越大。所以我们引入两个计算公式。
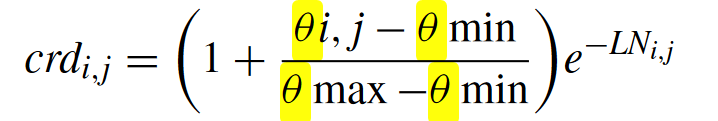
角度计算公式没给出。。。。
其中 θi,j 和 LNi,j 分别是锐角和从拟合线 Li 到向量 vj 方向的投影长度,θmin 和 θmax 分别是迄今为止在当前一代中发现的最小和最大锐角。在这里,较小的 CRD 值表示对收敛性的贡献越大,对多样性的贡献越小。
算法分析



算法三:(这里的N×K应该是小k)
line 15-16: 根据CRD升序排序然后分成k = D/20个分组。
在 B 中的每个聚类中,为每个普通参考向量分配的分组变量序列与其聚类中心向量的分组变量序列相同(第 18-22 行)。也就是说每个w对应的一个solution的变量排序分组是和其属于的簇的排序分组是一样的。

ng的挑选规则:(在Wi这个向量下,我默认这T个个体的变量分组以当前Wi分析的为准)



这伪代码有点蠢。
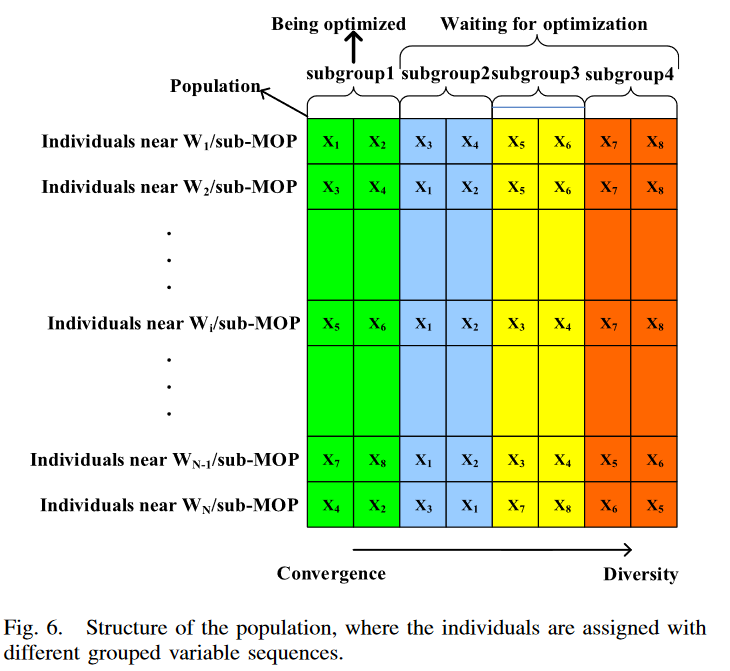
matrix这个样。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)