

Solving Multi-objective Feature Selection Problems in Classification via Problem Reformulation and Duplication Handling
作者思路:减少特征选择的数量和提高分类性能是特征选择的两个主要目标,可以看作是一个多目标优化问题。
作者主要工作:
在多目标特征选择中设计一个方法去处理目标之间的不同偏好个经常出现的重复特征子集。
1.基于特征子集在目标空间的分布和在搜索空间相似度重复处理的方法。将目标空间中与其他解相似度高但是分类性能差的重复解去除。增加种群的多样性。
2.为了更关注分类性能,提出了一种问题重构方法。多目标特征选择问题重新表述为约束多目标优化问题,根据非支配解的分布,对每个解的分类性能进行约束,区别对待具有不同分类性能的解。
3.采用约束处理技术解决了重新表述的约束多目标特征选择问题,优先选择包含更多信息和强相关特征的可行特征子集,有利于提高分类性能。
特征选择是指从原始数据集中选择最相关或最有信息量的特征子集,以用于构建模型或进行分析。其目的是提高模型的性能、降低维度、减少计算成本,并提高对数据的理解。特征选择通常包括以下步骤:
-
特征评估(Feature Evaluation): 首先,需要对每个特征进行评估,了解它们对于解决给定任务的重要性。常用的评估指标包括信息增益、基尼系数、相关系数、方差等。
-
特征排序(Feature Ranking): 根据特征评估的结果,对特征进行排序,确定哪些特征更重要、更相关或更有信息量。
-
特征选择(Feature Selection): 基于特征排序的结果,选择排名较高的特征子集作为最终的特征集合。这可以通过不同的方法来实现,如过滤式方法、包裹式方法和嵌入式方法。
-
过滤式方法(Filter Methods): 这些方法独立于任何具体的学习算法,通常根据特征的统计属性(如方差、相关性)来进行选择。典型的过滤方法包括方差阈值、相关系数、信息增益等。
-
包裹式方法(Wrapper Methods): 这些方法使用特定的学习算法来评估特征的贡献,并根据学习算法的性能来选择特征子集。典型的包裹方法包括递归特征消除(Recursive Feature Elimination, RFE)、前向选择(Forward Selection)和后向消除(Backward Elimination)。
-
嵌入式方法(Embedded Methods): 这些方法将特征选择嵌入到模型的训练过程中,使得特征选择与模型的训练过程相互影响。典型的嵌入方法包括 L1 正则化(Lasso Regression)、决策树和基于模型的特征选择方法。
-
-
评估和验证(Evaluation and Validation): 选定特征后,需要对选择的特征进行评估和验证,确保选择的特征集合在模型训练和测试阶段都能取得好的性能。可以使用交叉验证、留出法或者独立测试集进行验证。
特征选择是数据预处理中非常重要的一步,它可以提高模型的泛化能力、减少过拟合,并且有助于更好地理解数据和模型。在实际应用中,选择合适的特征选择方法和评估指标是至关重要的,需要根据具体的问题和数据特点来进行选择。
SparseEA解决特征选择问题
特征选择可以视作一个稀疏多目标优化问题。一些基于稀疏性的研究在解决多目标特征选择问题上显示出了很好的结果。
求解过程
- 初始化首先评估每个特征与分类器的相关性,并通过锦标赛选择算子选择相关性较高的特征。
- 然后,利用评估的特征相关性来指导后代的繁殖过程。缺点:如果特征数量太多,初始化开销太大。
- 构造特征子集中表现最低的特征的方差的第三个目标,以搜索不可分离的最优特征子集
Proposed Method
- 多目标特征选择问题可以描述如下:
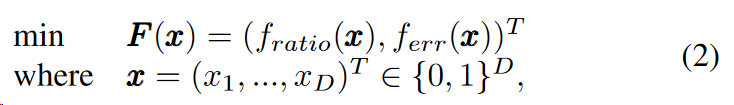
其中D是描述数据集中全部特征数量。
用二进制编码表示特征选择
第一个目标:
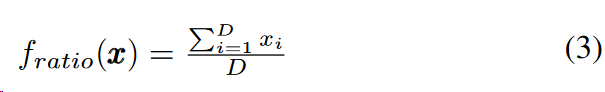
第二个目标:
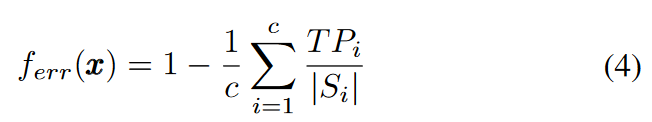
c 表示数据集分类数量。
Algorithm 1: Duplication handling

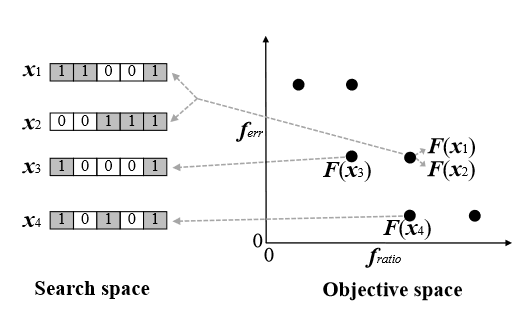
以上图为例参考点
- 计算重复解点和参考点的hamming distance,更偏向于保留距离大的解
- 如果出现一个重复解可能有较大的de和较小的dr,而另一个可能有较小的de和较大的dr。因此,很难决定去除哪个重复解。这个时候就将重复解与其两个参考点Re和Rr的相似度表述为一个新的(最大化)双目标优化问题:
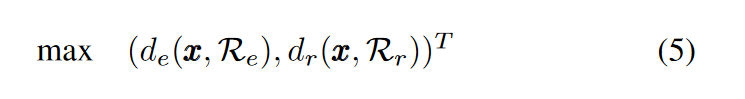
Algorithm 2:Constraint handling
重新表述的约束多目标特征选择问题形式为:
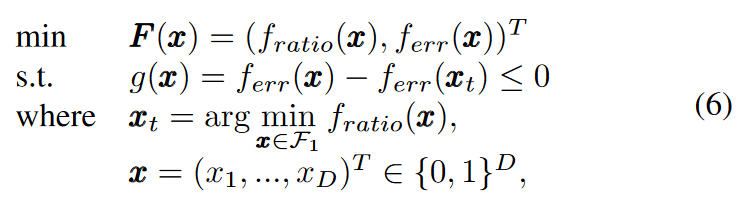
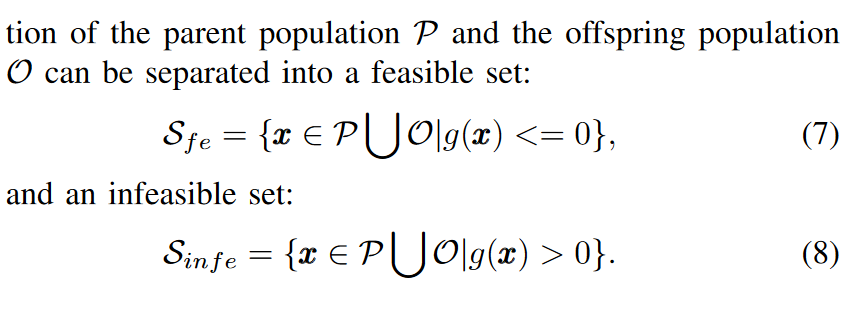

时间复杂度分析
交配选择和后代繁殖的最坏情况时间复杂性分别为O(N)和O(DN),其中N是种群大小,D是数据集中特征的总数。
环境选择操作由四个步骤组成:非显性排序、重复处理、问题重新表述和约束处理。
非支配排序算子的计算复杂度为O(
一代PRDH的总体复杂度以O(


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人