论文阅读:CVF-SID(2022-CVPR)
paper: https://arxiv.org/pdf/2203.13009
code: https://github.com/Reyhanehne/CVF-SID_PyTorch
动机:
在合成噪声图像上学习的去噪模型不能很好的应用在真实场景下,因为真实噪声分布不同于合成AWGN。
难题:
真实有噪声-干净图像对难以获得;模型的鲁棒性不高,仅能在特定的数据集上进行工作;一些方法依赖于假设特定分布。
目标:
采用新颖的自监督框架克服成对图像的不足,并在真实世界取得好的去噪性能。
设计:
提出了一种新的循环多变量函数(CVF),它将其输入分解为多个子分量,并将其输出的组合重新作为输入。利用CVF设计了用于sRGB图像去噪的自监督图像去噪模型(CVF-SID)。在各种自监督训练目标下,CVF-SID可以学习从给定的噪声sRGB输入中分离无噪声图像、信号相关和信号无关噪声。此外,提出自监督数据增强策略,以有效地增加训练样本的数量。
创新:
1)基于循环多变量函数(CVF)的新型自监督图像去噪方法。CVF-SID将给定的真实世界噪声输入分解为干净的图像、信号相关的和信号无关的噪声。
2)对于完全自我监督的CVF-SID,我们提出了各种训练目标和增强策略。
3)CVF-SID方法可以直接在有噪声的sRGB图像上训练,不假设关于未知噪声信号的任何特定分布 。
方法:
CVF
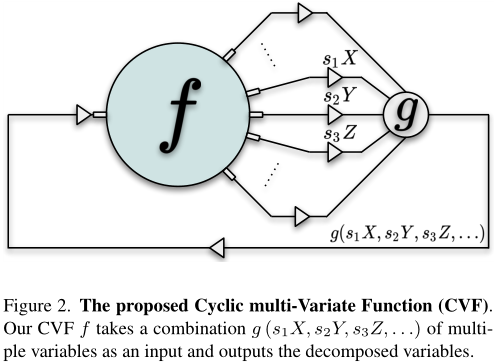
g(X,Y,Z...) to [X,Y,Z,...]
利用CVF的性质,旨在以自我监督的方式学习去噪模型。
CVF-SID
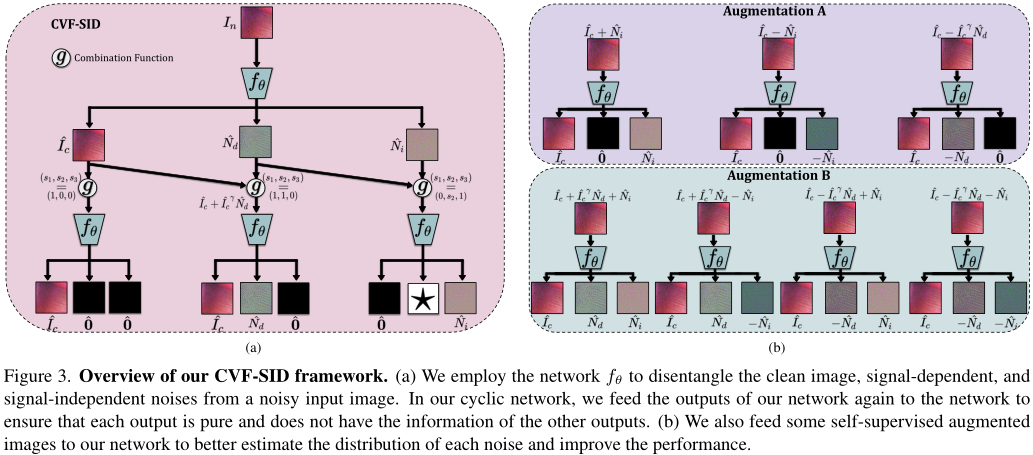
将输入噪声图像In表示为干净图像Ic、信号相关噪声图像Nd和信号无关噪声Ni的函数。将噪声图像分解为干净图像和噪声分量后,利用CVF构建自监督循环。其中,假设Nd和Ni为零均值,并在未知分布下具有空间不变性。并假色(Ic、Nd)、(Ic、Ni)、(Nd、Ni)相互之间独立。
将噪声图像分解:
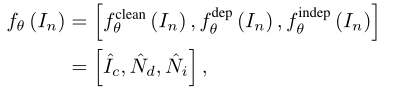
因为不使用有噪声的干净图像对,不能对函数的输出应用直接监督,也不能保证fθ完美地分离这些组件。 所以采用右图这种循环自监督方式对学习目标进行约束。
![]()
s2、s3从{-1,0,1}中选择,合成噪声图像,可以用来做自监督的数据扩充,不需要额外的样本。
网络:
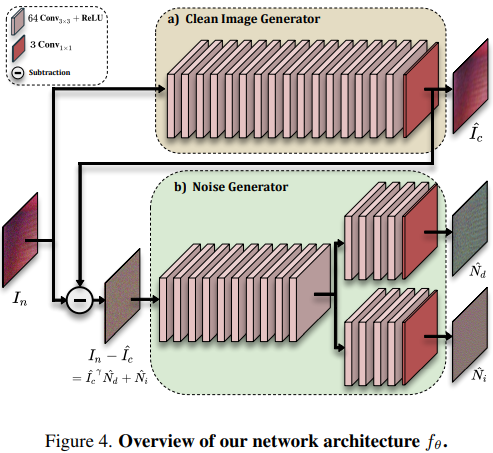
并设计了一系列的Loss来约束网络,详见论文。
实验:
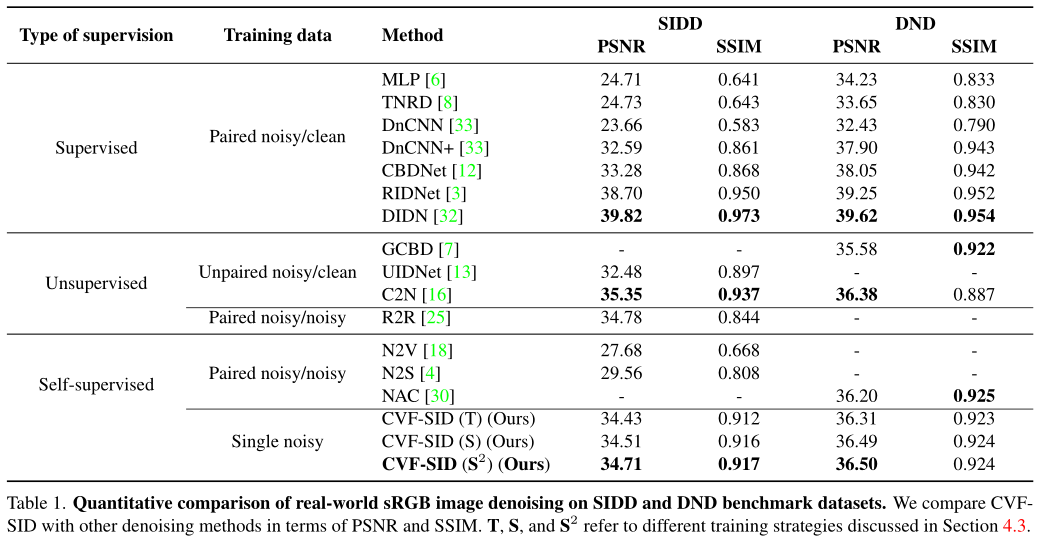
对比实验
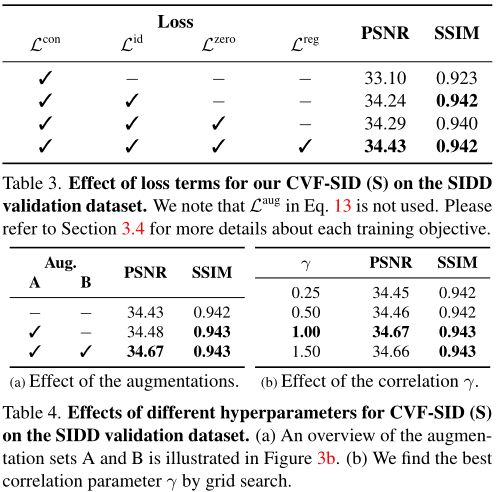
消融实验



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理