论文阅读:Blind2Unblind(2022-CVPR)
题目: Blind2Unblind: Self-Supervised Image Denoising with Visible Blind Spots(CVPR-2022)
paper: https://arxiv.org/abs/2203.06967
code: https://github.com/demonsjin/Blind2Unblind
论文的动机:基于盲点驱动的去噪网络,在输入或网络传输中会遭受到很大的信息损失,缺少这些有价值的信息会显著降低网络的去噪性能。因此需要设计一种模型用来克服盲点驱动的去噪方法中的信息损失。
论文的主要思想:增加一路分支,引入非盲点去噪,从原始噪声图像中学习用来提高盲点网络的去噪性能。
整体网络:
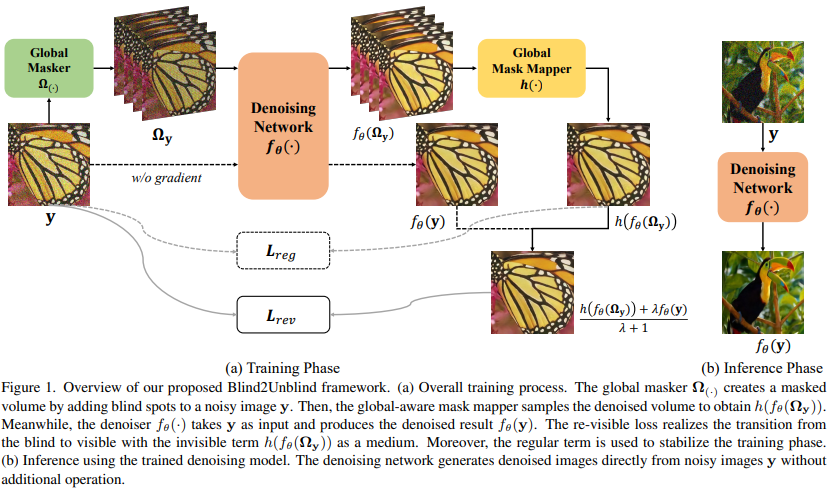
创新点:
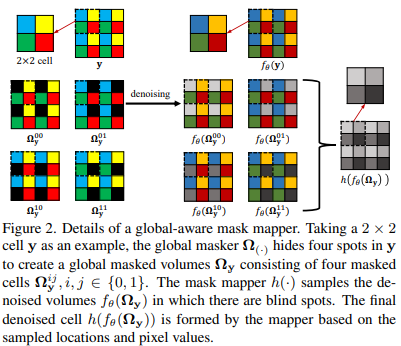
1) 全局感知掩码映射器:
手动掩码方法隐藏了用于训练的部分像素,而目标函数只关注被掩码的区域,导致精度降低和收敛速度慢。全局掩码:将每个有噪声的图像划分为块,并将每个块中的特定像素设置为盲点,这样可以获得一个全局掩码作为输入。然后,带有全局掩码的一批图像传输到去噪网络中。全局映射器在盲点处采样去噪结果,并将它们投影到同一平面上生成去噪图像。该操作加快了训练速度,实现了全局优化,并允许应用可见损失。
2) 基于可见损失的无盲点训练策略:
使用盲点结构进行自监督去噪,然后使用所有信息来提高其性能。纯可见损失仅使用一个可反向传播的变量来优化盲项和可见项,会导致训练不稳定。因此,引入了一个正则项来约束盲项并稳定训练过程。正则化后的可见损失如下:
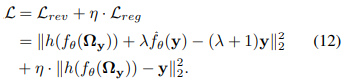
可改进的地方:换用更复杂的Dehaze Noise network。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理