论文阅读:NAFNet(2022-ECCV)
Simple Baselines for Image Restoration (ECCV2022)
论文:https://arxiv.org/pdf/2204.04676v4.pdf
代码:https://github.com/megvii-research/NAFNet
论文的动机:随着深度学习的发展,模型的复杂度快速上升。是否可以只使用简单的模型,通过较小的复杂度来实现好的效果。
主要思想:作者认为模型复杂度主要包括块间复杂度和块内复杂度。因此通过降低块间复杂度和块内复杂度来构建简单的模型,验证在较低的计算量上能够取得更好的效果。
块间复杂度表示为网络的主要结构,为了降低块间复杂度,采用了简单的Unet为块间结构。论文中提出块间结构不是影响模型效果的关键。
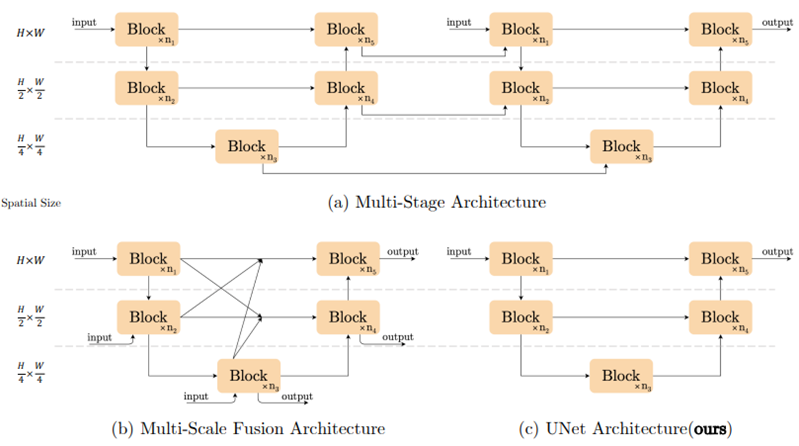
为了降低块内复杂度,主要进行了三处改进:
1)Normalization。采用transformer中经常被使用的LayerNorm。而没有使用BatchNorm,因为小批量可能会带来不稳定的统计数据,不利于对图像细节的恢复。
2)激活层。因为ReLU广泛用于计算机视觉,在SOTA方法中又逐渐被GELU替代。并引入了GLU对GELU进行简化。认为GELU是GLU的一种特殊情况。
GLU:![]()
GELU:![]()
因此提出:GLU可以被视为激活函数的泛化,它可能能够取代非线性激活函数。GLU本身包含非线性,不依赖于σ。为了降低计算量,移除σ提出了一个简单的GLU变体:直接将特征图分为通道维度中的两部分,并将其相乘。
SimpleGate:![]()
对于通道注意模块中的Sigmoid和ReLU:
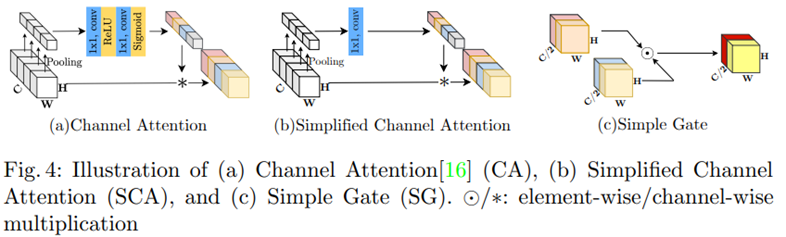
普通的CA:![]()
简化:![]()
因此CA也可视为GLU的一个特例。在保留CA的两个最重要的作用:聚合全局信息和通道信息交互。提出了简化的CA:
![]()
经过简化后,网络中没有非线性激活函数。所以叫NAFNet:非线性无激活网络。但是不影响性能。
3)注意力。SimpleGate操作虽然可以有效减少计算量,但是丢失了channel-wise的操作,因此在attention上,使用了简化的channel attention。
基于以上改进提出了新的baseline:
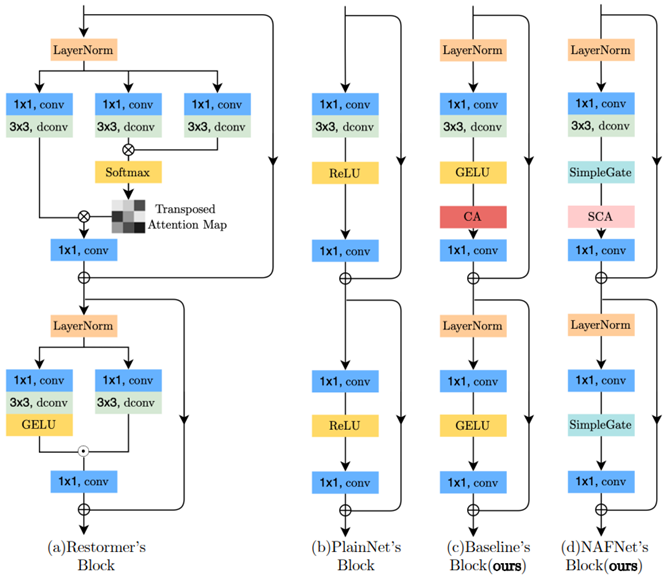
论文值得学习的地方:没有直接拿transformer来用,而是将里面比较成熟的模块和机制引入到conv,在简单的模型上进行改进,既能提高性能,又能有效的降低计算量,并且能通过丰富的尝试来验证各个模块的有效性。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 【杂谈】分布式事务——高大上的无用知识?