论文阅读:NBNet(2021-CVPR)
NBNet(2021-CVPR)
NBNet: Noise Basis Learning for Image Denoising with Subspace Projection
在本文中,我们介绍了 NBNet,一种新的图像去噪框架。与以前的工作不同,我们建议从一个新的角度解决这个具有挑战性的问题:通过图像自适应投影进行降噪。具体来说,我们建议通过学习特征空间中的一组重构基础来训练一个可以分离信号和噪声的网络。随后,可以通过选择信号子空间的相应基并将输入投影到该空间中来实现图像去噪。我们的关键见解是投影可以自然地保持输入信号的局部结构,尤其是对于光线不足或纹理较弱的区域。为此,我们提出了 SSA,这是一个我们设计的非局部注意力模块,用于显式学习基础生成和子空间投影。我们进一步将 SSA 与 NBNet 结合在一起,NBNet 是一种基于端到端图像去噪而设计的 UNet 结构化网络。我们对基准进行评估,包括 SIDD 和 DND,NBNet 在 PSNR 和 SSIM 上实现了最先进的性能,同时显着降低了计算成本。
问题
-
以前提出的方法在弱纹理或高频细节等硬场景中恢复高质量图像仍然具有挑战性。
-
卷积网络通常依赖于局部滤波器对分离噪声和信号的响应。 在低信噪比 (SNR) 的硬场景中,如果没有额外的全局结构信息,局部响应很容易混淆。
-
虽然像BM3D这样的经典方法可以产生合理的去噪结果,具有一定的准确性和鲁棒性,但它们的算法复杂度通常很高,泛化能力有限
网路
image projection
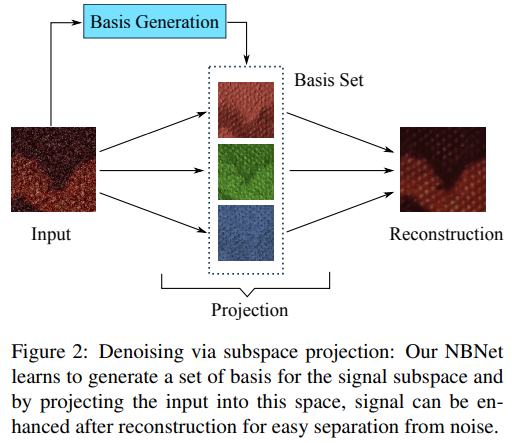
1)基生成:从图像特征图生成子空间基向量;
2)投影:将特征图转换为信号子空间。
Network Architecture
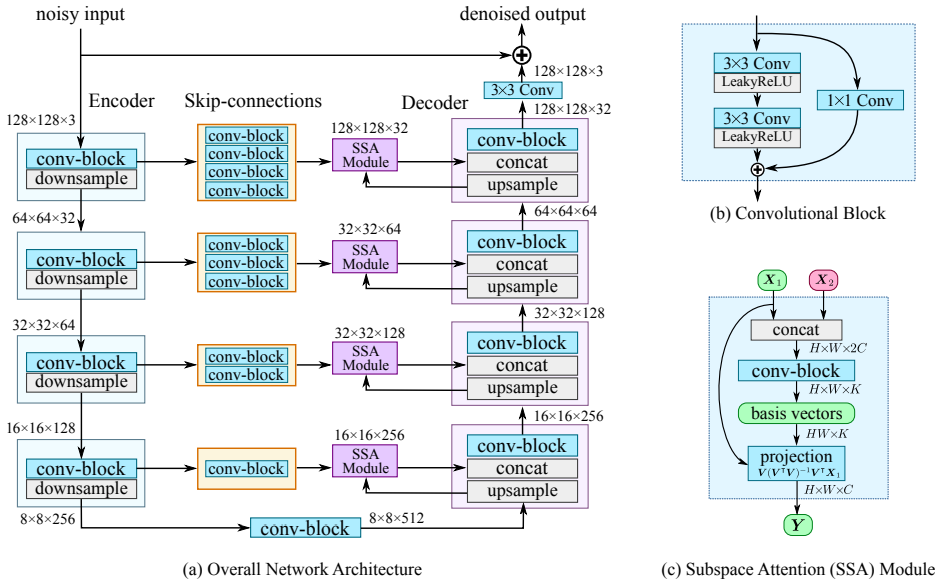
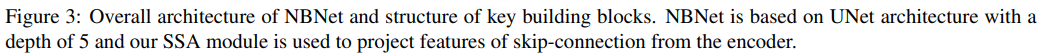
与在每个解码器阶段直接融合低级和高级特征图的传统类 UNet 架构相比,NBNet 的主要区别在于低级特征在融合之前由 SSA 模块投影。
Basis Generation
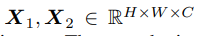
作为来自单个图像的两个特征图。 它们是 CNN 的中间激活,可以位于不同的层但大小相同。
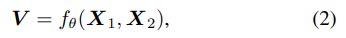
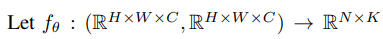
先连接X1和X2为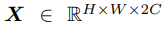
然后通过convolutional block(图3(b)) 输出通道数为K,形状为H×W×K
Projection
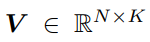
列是 K 维信号子空间的基向量
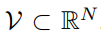
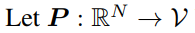
可以通过正交线性投影将图像特征图 X1 投影到 V 上
![]()
P是信号子空间的正交投影矩阵。其中需要归一化项 (V ^T|V )-1,因为基生成过程不能确保基向量彼此正交。
最后,图像特征图 X1 可以在信号子空间中重构为 Y
![]()
投影中的操作是纯线性矩阵操作,并进行了一些适当的整形,这是完全可微的,并且可以在现代神经网络框架中轻松实现。
结合基生成和子空间投影,构建了所提出的 SSA 模块的结构,如图 3(c) 所示。
Loss
L1 Loss
![]()
创新
-
从子空间投影的新视角分析图像去噪问题。
-
进一步设计了一个简单高效的 SSA 模块来学习可以插入普通 CNN 的子空间投影
-
采用了具有新颖子空间注意模块的 UNet 风格架构。 与前人使用注意模块进行区域或特征选择不同,SSA 旨在学习子空间基础和图像投影
-
与上述所有专注于噪声建模的工作不同,我们的方法研究子空间基生成并通过投影改进降噪。
实验
Datasets:
training dataset includes 432 images from BSD, 400 images from the validation set of ImageNet and 4744 images from the Waterloo Exploration Database. The evaluation test dataset are generated from Set5, LIVE1 and BSD68.
Metrics:
PSNR
Comparison with SOTA


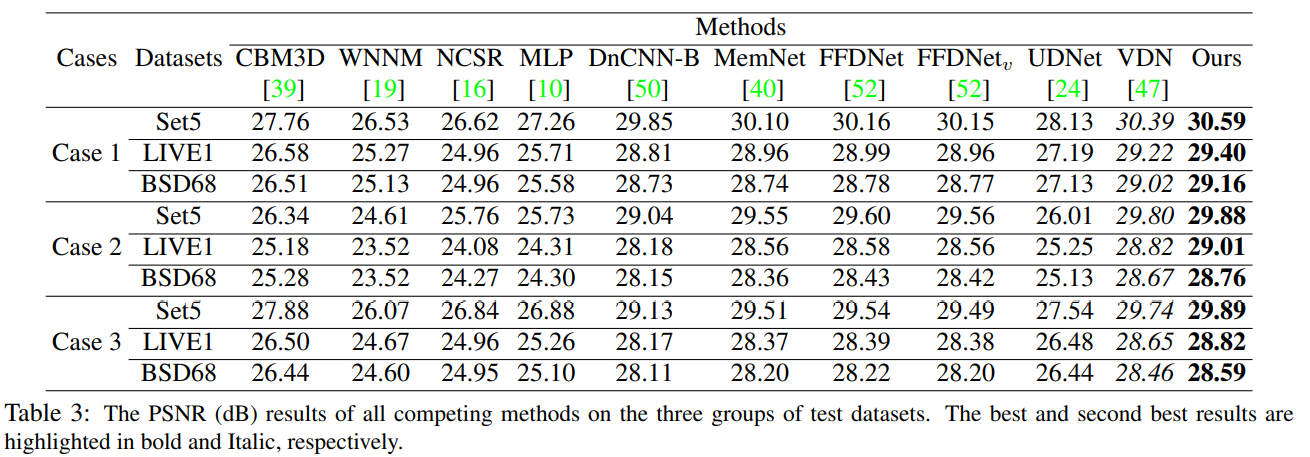
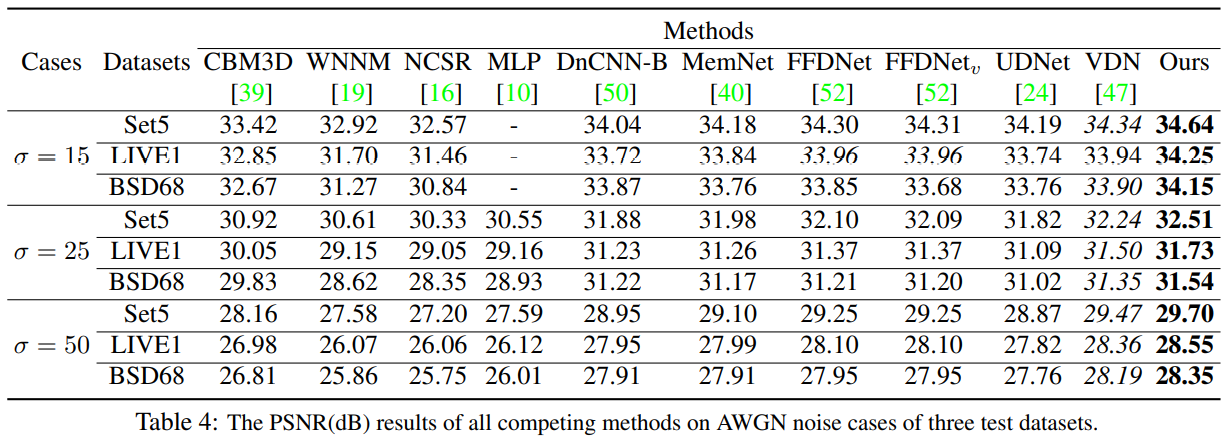
Ablation Study
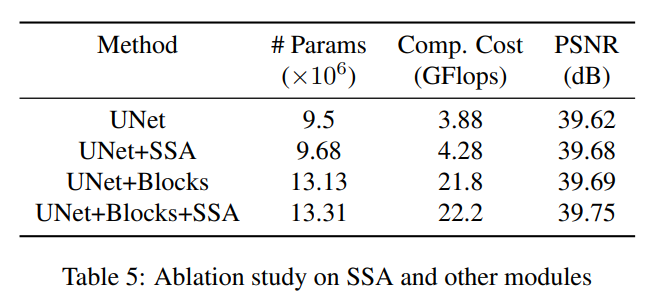
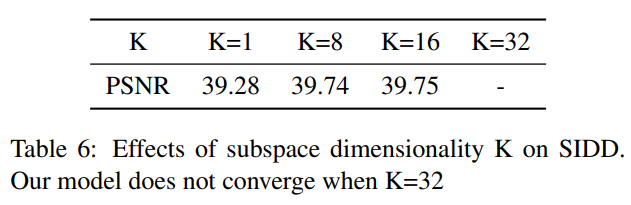
表6提供了不同K值的SIDD结果。当基向量K的数目设置为32时,模型不会收敛。在此设置中,由于第一阶段中的通道数也是32,SSA模块不能有效地作为子空间投影,因为K等于全维大小。另一方面,子空间的高维可能会增加模型拟合的难度,从而导致训练的不稳定性。其余实验表明,K的最佳选择为16。如果K等于1,则子空间中保存的信息不足,并导致跳过连接中的重大信息丢失。将K设置为8和16可以获得相当的性能,SSA模块可以创建低维、紧凑或可分类的子空间。因此,可以看到,子空间维数K是一个合理范围内的鲁棒超参数。
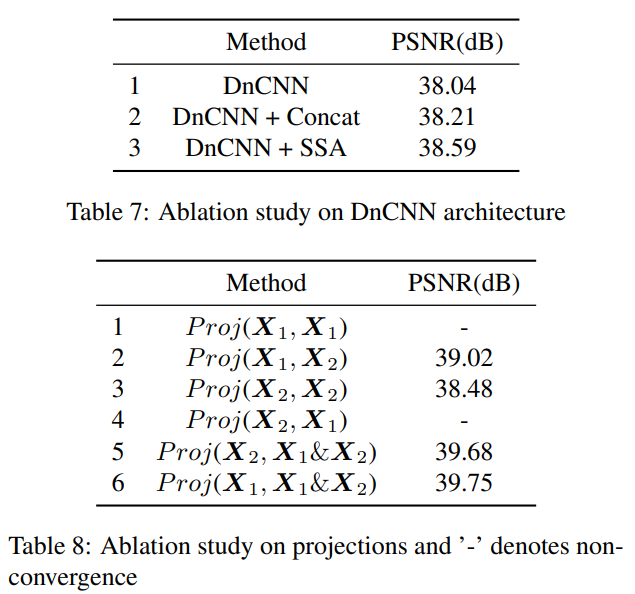
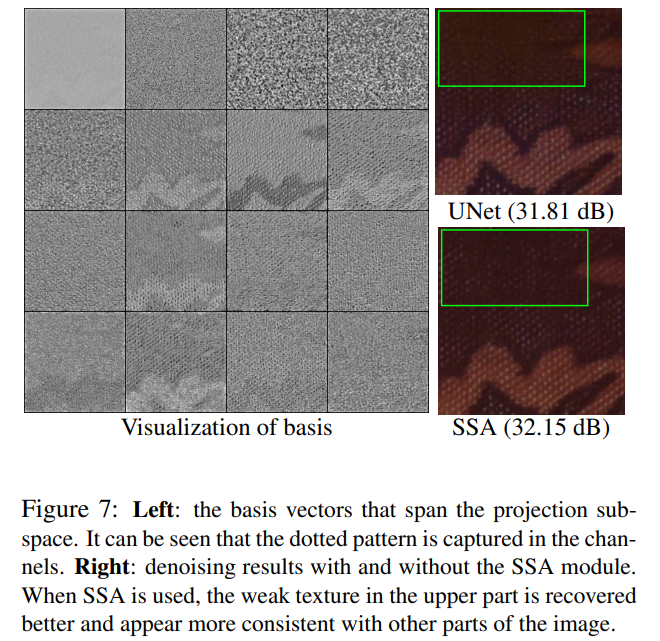
为了深入了解学习到的子空间投影是如何工作的,我们选取一幅样本图像并检查SSA模块生成的子空间。图7绘制了16个基向量以及使用和不使用SSA模块的预测。
如图7左侧所示,16个通道中的许多通道包含均匀分布在整个图像面片上的点图案。因此,可以合理地推测,这种改进应归因于SSA模块创建的非局部相关性:上部的弱纹理由图像其他部分中的类似情况支持,投影通过将基础与全局确定的系数相结合来重建纹理。相反,传统的卷积神经网络依赖于固定值局部滤波器的响应和下采样特征的粗略信息。当滤波器响应不显著且粗糙信息模糊时,例如在弱纹理区域,非局部信息很难改善局部响应
结论与启发
在这项研究中,我们重新审视了图像去噪问题,并提供了亚空间投影的新前景。 所提出的子空间基生成和投影操作可以自然地将全局结构信息引入去噪过程,并实现更好的局部细节保留,而不是依赖复杂的网络架构或精确的图像噪声建模。 我们进一步证明了这种基础生成和投影可以通过 SSA 以端到端的方式学习,并且比添加卷积块产生更好的效率。 我们认为子空间学习是图像去噪以及其他低级视觉任务的一个有前途的方向,值得进一步探索。
