论文阅读:FMEN(2022-CVPR)
FMEN(2022-CVPR)
Fast and Memory-Efficient Network Towards Efficient Image Super-Resolution
摘要
问题
-
在早期阶段,轻量化模型中的显示方案:采用减少宽度和深度、递归神经网络和群卷积来减少模型参数,上述策略会导致精度损失或更多额外开销(例如,触发器)。要么带来较高的计算成本,要么带来较差的性能。
-
轻量化模型中的隐式方案:侧重于充分利用中间特征并增强识别能力,从而降低复杂性并提高总体性能。(LapSRN MemNet CARN IMDN LatticeNet RFDN等)可以看出在这些方法中,特征融合在最近的发展中起着关键作用。虽然理论上是有效的,但由于相关特征在聚合之前一直驻留在内存中,因此它是次优的,与没有特征融合的简单拓扑结构相比,会导致内存消耗成倍增加。
-
RFDN应用了剩余特征蒸馏块,这是IMDB的一个变体,但功能更强大、更灵活。这种特征融合策略存在巨大的内存消耗,这是由于在聚合之前,多个相关特征映射驻留在内存中。此外,如RepVGG所述,融合设计通常会由于引入额外节点(例如,串联、1×1卷积)和频繁的内存访问而降低推理速度。
-
(RCAN、RFA、HAN、SwinIR)中使用的注意力机制已经取得了显著的进展,但由于多分支拓扑、内存中的多个特性以及低效的操作,对于EISR来说效率不够。
网路
Memory Analysis
一个节点的内存消耗M由四部分组成:输入特征内存M_input、输出特征内存M_output、之前计算并用于未来节点的保留特征内存M_kept、网络参数内存M_net。总内存M可以表示为:M=M_input+M_output+M_kept+M_net。Mnet太小,因此与特征内存相比可以忽略不计。
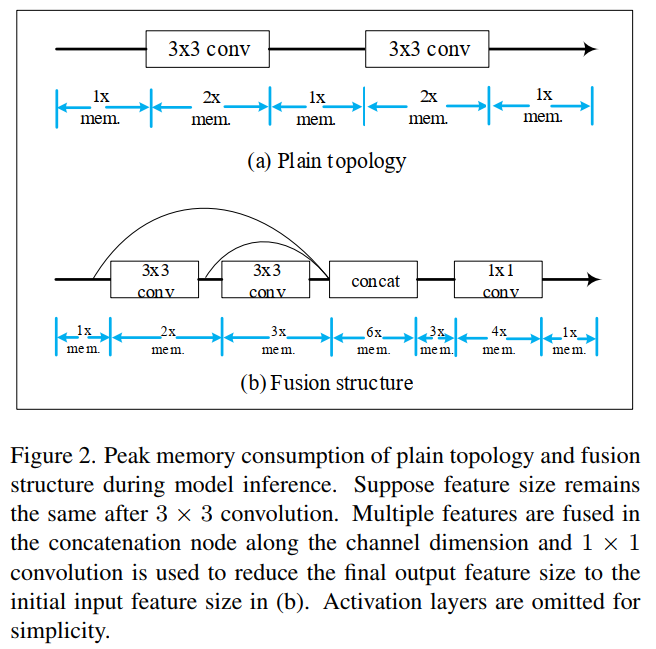
通过图2可以发现,与普通序列拓扑相比,特征融合通常会增加推理过程中的峰值内存消耗。
将顺序网络拓扑应用于EISR并不是一项简单的任务。一种方法是直接采用全序列架构,另一种方法是用可重新参数化的构建块替代常规卷积层,以在训练期间扩展优化空间。然而,与最近的高级融合拓扑相比,两者的性能往往会下降。
ERB
Enhanced Residual Block
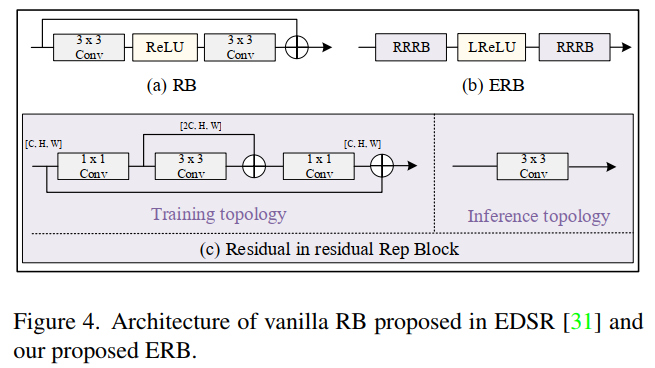
跳跃连接的使用引入了特征图大小 C×H×W 的额外内存消耗,并且由于额外的内存访问成本而降低了推理速度。ERB 由一个 Leaky ReLU 非线性和两个残差结构重参数化块 (RRRB) 组成,其灵感来自 RCAN和 RepVGG。 RRRB 在优化过程中挖掘了复杂结构的潜在能力,同时在推理过程中相当于单个 3×3 卷积。因为3x3卷积的计算密度是1x1和5x5卷积的4倍。结构重参数化的作用是在推理时,将多分支转换成单分支。
HFAB

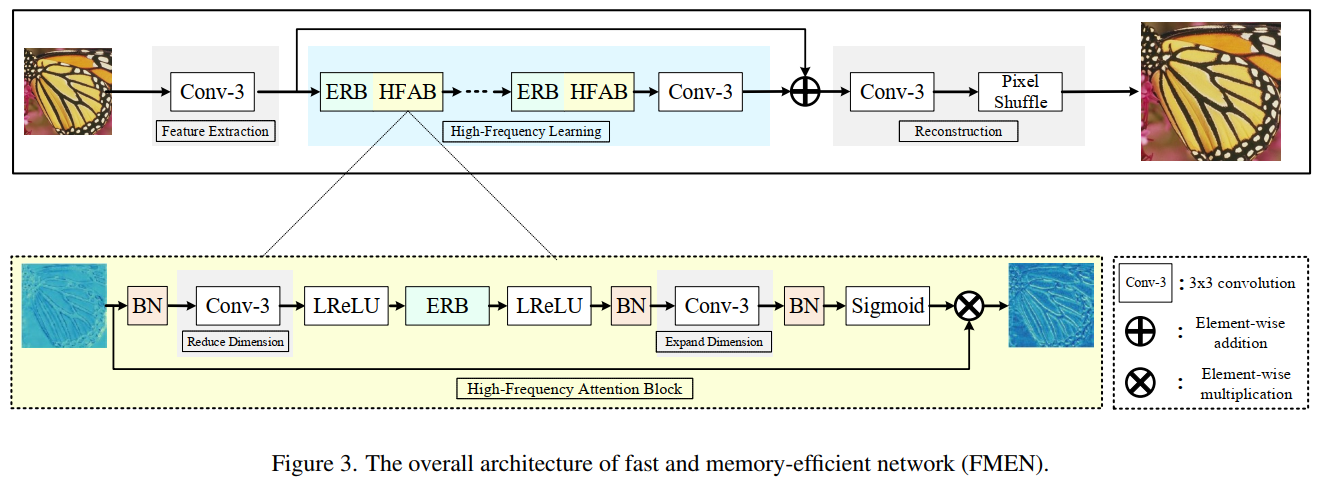
们首先通过 3×3 卷积而不是 1×1 卷积来降低通道维度以提高效率。(因为3x3卷积的计算密度是1的4倍)然后应用 ERB 来捕获本地交互。接下来,通道维度增加到原始级别,并使用 sigmoid 层将值从 0 限制到 1。最后,通过以像素方式乘以注意力图来重新校准输入特征。
上述步骤的动机主要来自边缘检测,其中可以使用附近像素的线性组合来检测边缘。卷积带来的感受野非常有限,这意味着只对局部范围依赖进行建模,以确定每个像素的重要性。因此,批量归一化(BN)被注入到顺序层中以引入全局交互,同时有利于 sigmoid 函数的不饱和区域。尽管之前的工作报道了 BN 可能会导致一些意想不到的伪影,但我们凭经验观察到 BN 在限制像素范围多样性方面发挥了作用,这符合高频学习设计,从而有助于提高性能改进。在推理过程中,我们通过将相应的参数合并到相关的卷积层中来去除 HFAB 和 BN 层内 ERB 的跳跃连接。 HFAB 仅包含四个高度优化的算子:3 × 3 卷积、Leaky ReLU 非线性、sigmoid 和元素乘法。 HFAB 避免了复杂的多分支拓扑,因此与 ESA相比,可以确保更快的推理。像素级别的重新缩放功能使 HFAB 在通道级别比 CCA 更强大。
Loss
L1 LOSS
创新
-
为了加快推理速度并减少内存消耗,我们通过高度优化的串行网络操作而不是特征聚合来设计网络主干,并通过注意机制来增强特征表示。
-
考虑到SR的目标是恢复丢失的高频细节(如边缘、纹理),我们提出了一种高频注意块(HFAB),它学习一个特别关注高频区域的注意图。具体而言,我们从本地和全球角度设计了HFAB中的注意分支。我们依次堆叠3×3卷积和Leaky ReLU层等高效算子,以建模局部信号之间的关系。批处理归一化(BN)在训练过程中被注入HFAB以捕获全局上下文,而在推理过程中被合并到卷积中。
-
裁剪了残差块(RB)并引入了增强残差块(ERB),在训练过程中在高维空间中提取特征,并在推理过程中使用结构重参数化技术去除跳跃连接。这种设计能够在不牺牲SR性能的情况下加速网络推理并减少内存消耗。
实验
Datasets:
training dataset:DIV2K and Flickr2K
testing dataset:Set5,Set14,B100,Urban100, and Manga109
Metrics:
SR 结果在转换后的 YCbCr 空间的亮度通道上进行评估PSNR和SSIM
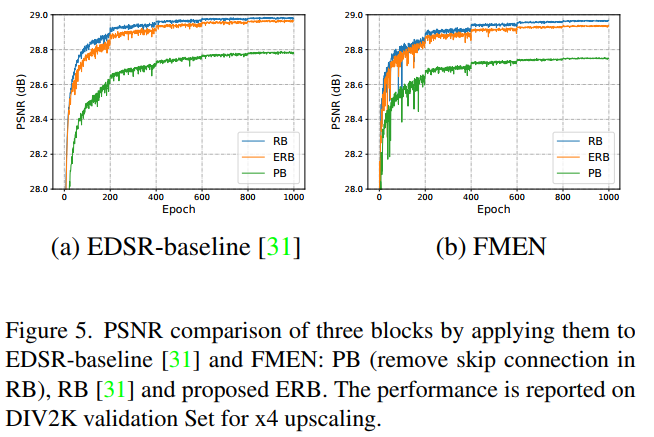
Ablation Study
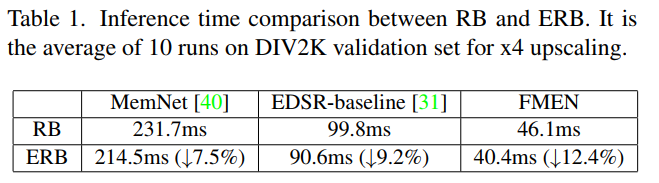

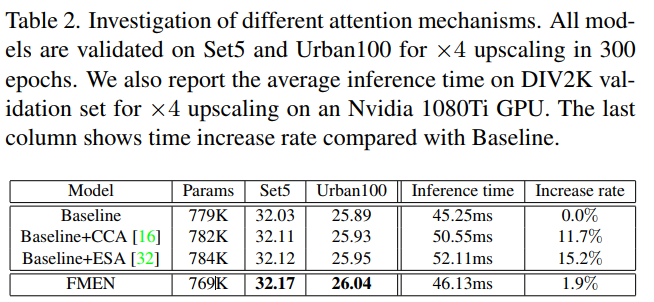
Comparison with SOTA
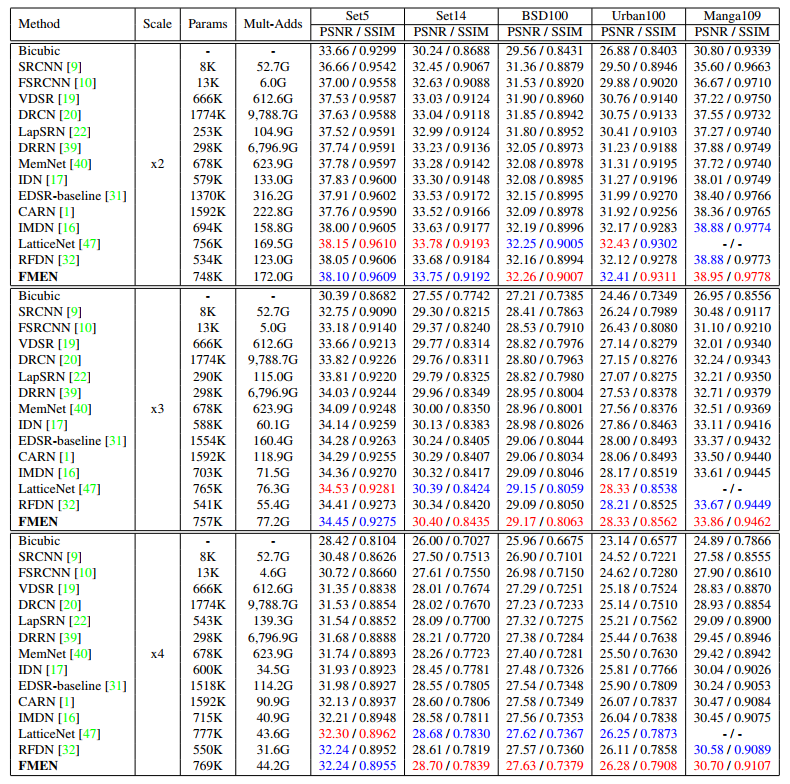
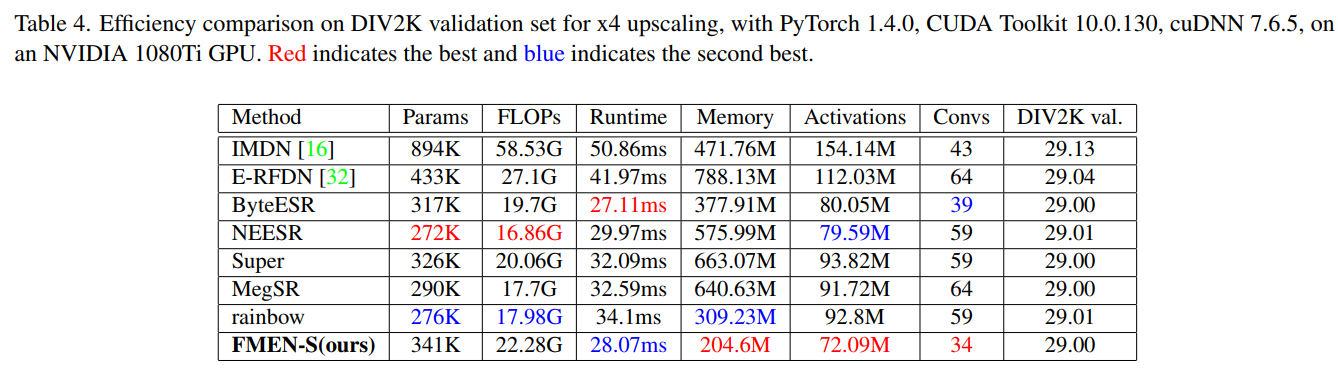
结论与启发
本文中分析了影响当前 EISR 模型的运行时间和内存消耗的因素,并设计了一个具有高效序列算子和注意力机制的快速且内存高效的网络 (FMEN)。 FMEN 主要由两个基本块组成:增强残差块(ERB)和高频注意力块(HFAB)。 ERB 利用了 RB,但对部署更友好。 HFAB 比传统的注意力模块更强大、更轻巧。 我们的方法在运行时间和内存消耗方面获得了显着改善,同时保持了可比的重建性能。
